【TensorRT】将 PyTorch 转化为可部署的 TensorRT
文章目录
-
- 一、什么是 ONNX
- 二、PyTorch 转 ONNX
- 三、什么是 TensorRT
- 四、ONNX 转 TensorRT
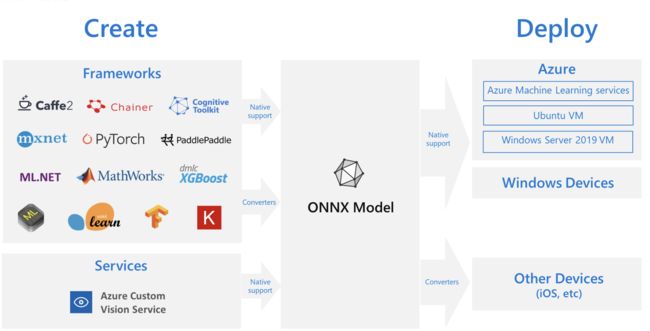
在深度学习模型落地的过程中,会面临将模型部署到边端设备的问题,模型训练使用不同的框架,则推理的时候也需要使用相同的框架,但不同类型的平台,调优和实现起来非常困难,因为每个平台都有不同的功能和特性。如果需要在该平台上运行多种框架,则会增加复杂性,所以 ONNX 便派上了用场。可以通过将不同框架训练的模型转换成通用的 ONNX 模型,再进而转换成各个平台支持的格式,就可以实现简化部署。
一、什么是 ONNX
ONNX 是 Open Neural Network Exchange 的简称,也叫开放神经网络交换,是一个用于表示深度学习模型的标准,可使模型在不同框架直接转换。
ONNX 是迈向开放式生态系统的第一步,使得开发人员不局限于某种特定的开发工具,为模型提供了开源格式。
ONNX 目前支持的框架有:Caffe2、PyTorch、TensorFlow、MXNet、TensorRT、CNTK 等
ONNX 通常来说就是一个中介,是一种手段,在把模型转换成 ONNX 之后,再转换成可部署的形式,如 TensorRT。
典型的结构转换路线:
- Pytorch → ONNX → TensorRT
- Pytorch → ONNX → TVM
- TF → ONNX → NCNN
二、PyTorch 转 ONNX
import onnxruntime
import torch
torch.onnx.export(
model,
(img_list, ),
'tmp.onnx',
input_names=['input.1'],
output_names=['output'],
export_params=True,
keep_initializers_as_inputs=False,
verbose=show,
opset_version=opset_version,
dynamic_axes=dynamic_axes))
# onnx 模型简化:
python3 -m onnxsim tmp.onnx tmp_simplify.onnx
三、什么是 TensorRT
TensorRT 是由英伟达公司推出的一款用于高性能深度学习模型推理的软件开发工具包,可以把经过优化后的深度学习模型构建成推理引擎部署在实际的生产环境中。用于对嵌入式平台、自动驾驶等平台的推理加速。
TensorRT 是采用 C++ 语言编写的高性能推理框架,可以在所有平台上提供 C++语言的实现,TensorRT 推理应用程序与英伟达的 GPU 结合可以提供最大的吞吐量和较低的延迟速度。
为什么需要 TensorRT:
- 模型包括训练和推理两个阶段,训练的时候包含了前向传播和反向传播,推理只包含前向传播,所以预测时候的速度更重要。
- 现在大多数的深度学习网络模型结构复杂并且参数量巨大,需要使用多个高性能的 GPU 分布式训练才能获得全局最优的结果,这使得深度学习方法很难应用中在实际的生产环境中
- 为了降低生产成本,在实际应用中,模型通常都会部署在嵌入式开发板上,或者使用单个 GPU 甚至是嵌入式平台,其算力相对较低,对于结构复杂且参数量巨大的网络模型较难获取实时的推理速度
- 模型训练时采用的框架会不同,不同机器的性能会存在差异,导致推理速度变慢,无法满足高实时性。如果在使用深度学习方法时,部署应用的机器的深度学习环境要与网络模型训练时的环境相同,这增加了深度学习方法部署的复杂性。
- 而 TensorRT 就是推理优化器,把 ONNX 模型转换为 TensorRT 之后,就可以在相关边端部署了。
TensorRT 的优势:
- 与许多轻量级的深度学习网络模型相比,TensorRT 不仅可以大幅提高网络的推理速度,而且只损失些许的精度。
- 同时,使用 TensorRT 优化后的网络模型的部署不再需要与训练时相同的环境。
- 使用 TensorRT 优化之后的网络推理速度有了较大的提高。
TensorRT 的优化方法: TensorRT 有多种优化方法,最主要的是前两种:
-
1、层间融合或张量融合:
TensorRT通过对层间的横向或纵向合并(合并后的结构称为CBR,意指 convolution, bias, and ReLU layers are fused to form a single layer),使得层的数量大大减少。横向合并可以把卷积、偏置和激活层合并成一个 CBR 结构,只占用一个 CUDA 核心。纵向合并可以把结构相同,但是权值不同的层合并成一个更宽的层,也只占用一个CUDA核心。合并之后的计算图)的层次更少了,占用的CUDA核心数也少了,因此整个模型结构会更小,更快,更高效。
-
2、数据精度校准:
大部分深度学习框架在训练神经网络时网络中的张量都是 32 位浮点数的精度(Full 32-bit precision,FP32),一旦网络训练完成,在部署推理的过程中由于不需要反向传播,完全可以适当降低数据精度,比如降为 FP16 或 INT8 的精度。更低的数据精度将会使得内存占用和延迟更低,模型体积更小。
-
3、Kernel Auto-Tuning:
网络模型在推理计算时,是调用 GPU 的 CUDA 进行计算的,TensorRT 可以真的不同的算法、不同的模型结构、不同的 GPU 平台等,进行 CUDA 调整,以保证当前模型在特定平台上以最优的性能计算。
假设在 3090 和 T4 上要分别部署,则需要分别在这两个平台上进行 TensorRT 的转换,然后在对应的平台上使用,而不能在相同同的平台上转换,在不同的平台上使用。
-
4、Dynamic Tensor Memory:
在每个 tensor 使用期间,TensorRT 会为其指定显存,避免显存重复申请,减少内存占用和提高重复使用效率
四、ONNX 转 TensorRT
def convert_tensorrt_engine(onnx_fn, trt_fn, max_batch_size, fp16=True, int8_calibrator=None, workspace=2_000_000_000):
network_creation_flag = 1 << (int)(trt.NetworkDefinitionCreationFlag.EXPLICIT_BATCH)
with trt.Builder(TRT_LOGGER) as builder,
builder.create_network(network_creation_flag) as network,
trt.OnnxParser(network, TRT_LOGGER) as parser:
builder.max_workspace_size = workspace
builder.max_batch_size = max_batch_size
builder.fp16_mode = fp16
if int8_calibrator:
builder.int8_mode = True
builder.int8_calibrator = int8_calibrator
with open(onnx_fn, "rb") as f:
if not parser.parse(f.read()):
print("got {} errors: ".format(parser.num_errors))
for i in range(parser.num_errors):
e = parser.get_error(i)
print(e.code(), e.desc(), e.node())
return
else:
print("parse successful")
print("inputs: ", network.num_inputs)
# inputs = [network.get_input(i) for i in range(network.num_inputs)]
# opt_profiles = create_optimization_profiles(builder, inputs)
# add_profiles(config, inputs, opt_profiles)
for i in range(network.num_inputs):
print(i, network.get_input(i).name, network.get_input(i).shape)
print("outputs: ", network.num_outputs)
for i in range(network.num_outputs):
output = network.get_output(i)
print(i, output.name, output.shape)
engine = builder.build_cuda_engine(network)
with open(trt_fn, "wb") as f:
f.write(engine.serialize())
print("done")