《机器学习实战》之十——利用K-均值聚类算法对未标注数据分组
K-均值目录
-
- 一、前言
- 二、K-均值聚类算法
- 三、使用后处理来提高聚类性能
- 四、二分K-均值算法
- 五、示例:对地图上的点进行聚类
- 六、总结
- 参考资料
一、前言
聚类是一种无监督的学习,它将相似的对象归到同一簇中。它有点像全自动分了。聚类方法几乎可以应用到所有对象,簇内的对象越相似,聚类的效果越好。本章要学习一种称为K-均值(K-means)聚类的算法。之所以称之为K-均值是因为它可以发现k个不同的簇,且每个簇的中心采用簇中所含值的均值进行计算而成。
聚类与分类的最大不同在于,分类的目标事先已知,而聚类则不一样。因为其产生的结果与分类相同,而只是类别没有预先定义,聚类有时也被称为无监督分类(umsupervised classification)
聚类分析试图将相似对象归入同一簇,将部相似的对象归到不同的簇。相似这一概念取决于所选择的相似度计算方法。到底使用哪种相似度计算方法取决于具体的应用。
二、K-均值聚类算法
K-均值是发现给定数据集的k个簇的算法。簇个数k是用户给定的,每个簇通过其质心(centroid),即簇中所有点的中心来描述。
K-均值算法的工作流程是这样的。首先,随机确定k个初始点作为质心。然后将数据集中的每个点分配到一个簇中,具体来讲,为每个点找距其最近的质心,并将其分配给该质心所对应的簇。这一步完成之后,每个簇的质心更新为该簇所有点的平均值。
思想: 以空间中k个中心点进行聚类,对最靠近他们的对象归类,通过迭代的方法,逐次更新各聚类中心
描述:
| 1. 适当选择C个类的初始中心 |
| 2. 在第K此迭代中,对任意一个样本,求其到C各中心的距离,将该样本归到距离最短的中心所在的类 |
| 3. 利用均值等方法更新该类的中心值 |
| 4. 对于所有的C个聚类中心,如果利用(2)(3)的迭代法更新后,值保持不变,则迭代结束,否则继续迭代 |
上面提到的“最近”质心的说法,意味着需要进行某种距离计算。读者可以使用所喜欢的任意距离度量方法。数据集上k-均值算法的性能会受到所选距离计算方法的影响。这里我们采用的是欧式距离:
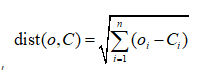
话不多说,先看一下数据。新建一个kMeans.py的文件,写入如下代码:
import numpy as np
import matplotlib
import matplotlib.pyplot as plt
"""
函数说明:载入数据
Parameter:
filename:文件名
Return:
dataMat:数据集
"""
def loadDataSet(filename):
dataMat = []
fr = open(filename)
for line in fr.readlines():
curLine = line.strip().split('\t') # 按 Tab键 分割成 列表
fltLine = list(map(float, curLine)) # 每行数据映射为一个浮点型的值
dataMat.append(fltLine)
return dataMat
"""
函数说明:加载数据
Parameters:
fileName:文件名
Returns:
无
"""
def plotDataSet(fileName):
dataMat = loadDataSet(fileName) #加载数据集
n = len(dataMat) #样本个数
xcord = []
ycord = []
for i in range(n):
xcord.append(dataMat[i][0])
ycord.append(dataMat[i][1])
fig = plt.figure()
ax = fig.add_subplot(111)
ax.scatter(xcord, ycord, s=20, c='blue', alpha=0.5)
plt.title('DataSet')
plt.xlabel('X')
plt.show()
运行结果如下:
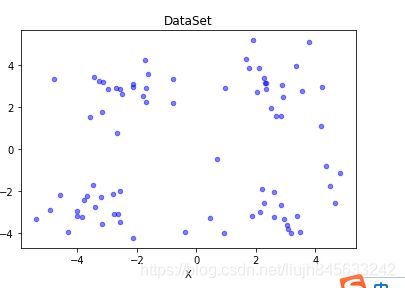
从上图可以看到数据应该是可以分为4个簇比较合适,因此接下来就需要我们编写kMeans聚类函数的代码,打开kMeans.py的文件,继续写入如下代码:
"""
函数说明:计算欧几里得距离
Parameter:
vecA:向量A
vecB:向量B
Return:
两向量的欧式距离
"""
def distEclud(vecA, vecB):
return np.sqrt(np.sum(np.power(vecA - vecB, 2)))
"""
函数说明:为给定数据集构建一个包含k个随机质心的集合
Parameter:
dataSet:数据集
k:质心个数
Return:
k个随机质心
"""
def randCent(dataSet, k):
n = np.shape(dataSet)[1] # 样本特征维度
centroids = np.mat(np.zeros((k,n))) # 初始化 k个 质心
for j in range(n): #循环遍历样本特征
minJ = min(dataSet[:,j]) # 每个样本特征最小值
rangeJ = float(max(dataSet[:,j]) - minJ) #每种样本特征的取值范围
# 在每种样本的最大值和最小值间随机生成K个样本特征值
centroids[:,j] = np.mat(minJ + rangeJ * np.random.rand(k,1))
return centroids
"""
函数说明:k-mean聚类算法
Parameter:
dataSet:数据集
distMeas:距离计算函数
createCent:随机生成质心
Return:
质心、样本的分配结果
"""
def kMeans(dataSet, k, distMeas=distEclud, createCent=randCent):
m = np.shape(dataSet)[0] # 样本个数
clusterAssment = np.mat(np.zeros((m, 2))) # 簇分配结果矩阵,第一列记录簇索引值 第二列存储误差
centroids = createCent(dataSet, k) # 初始聚类中心
clusterChanged = True # 设置质心是否发生变化
while clusterChanged:
clusterChanged = False
for i in range(m): #循环每个样本
minDist = np.inf; minIndex = -1 #初始化距离变量 以及 最近的中心索引
for j in range(k): #循环k个质心
distJI = distMeas(centroids[j,:], dataSet[i,:]) #计算样本和每个质心的距离
if distJI < minDist: #选择距离最小的质心的索引
minDist = distJI; minIndex = j
if clusterAssment[i,0] != minIndex: clusterChanged = True
clusterAssment[i,:] = minIndex, minDist**2 #保存所属索引和距离的平方
print(centroids)
for cent in range(k):
ptsInClust = dataSet[np.nonzero(clusterAssment[:,0].A == cent)[0]] # 数组过滤 得到各个中心所属的样本
centroids[cent,:] = np.mean(ptsInClust, axis=0) # 按列求平均 得到新的中心
return centroids, clusterAssment
"""
函数说明:绘制聚类结果图
Parameters:
datMat:数据集
clusterAlg:采用的聚类算法
numClust:要聚的类别数
Returns:
无
"""
def showResult(datMat, clusterAlg=kMeans, numClust=4):
myCentroids, clustAssing = clusterAlg(datMat, numClust)
fig = plt.figure()
rect = [0.1,0.1,0.8,0.8] #figure的百分比,从figure 10%的位置开始绘制, 宽高是figure的80%
scatterMarkers = ['s', 'o', '^', '8', 'p','d', 'v', 'h', '>', '<'] #散点标记的列表
ax1 = fig.add_axes(rect, label='ax1', frameon=True) #新建区域ax1,并获得绘制的句柄
ax1.set_title("Clusters Result")
for i in range(numClust):
CurrCluster = datMat[np.nonzero(clustAssing[:,0]==i)[0],:] #将样本属于第i个类别的放在 CurrCluster中
markerStyle = scatterMarkers[i % len(scatterMarkers)] #第i个类别簇使用的散点标记符号
ax1.scatter(CurrCluster[:,0].flatten().A[0], CurrCluster[:,1].flatten().A[0],marker=markerStyle, s=90) #绘制第i个簇类
#绘制最终的质心
ax1.scatter(myCentroids[:,0].flatten().A[0], myCentroids[:,1].flatten().A[0], marker='+', s=300)
plt.show()
def kMeansTest():
dataMat = np.mat(loadDataSet('testSet.txt'))
# myCentroids, clustAssing = kMeans(dataMat, 4)
showResult(dataMat)
if __name__ == '__main__':
kMeansTest()
运行结果如下:
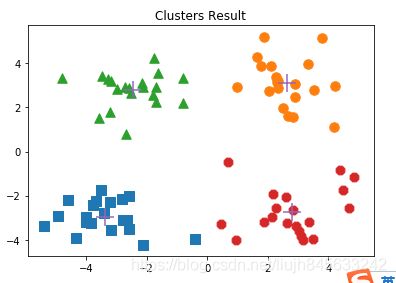
其中这里编写了计算距离的函数distEclud(),采用了欧式距离。还编写了随机选择质心的函数randCent(),聚类算法采用kMeans,按照(计算质心——分配——重新计算)反复迭代,直到所有的数据点的簇分配结果不再改变为止。
到目前为止,关于聚类的一切进展都很顺利,但事情并不总是如此。接下来会讨论KMeans算法可能出现的问题及其解决办法。
三、使用后处理来提高聚类性能
前面提到,在K-均值聚类中簇的数目k是一个用户预先定义的参数,那么用户如何才能知道k的选择是否正确呢?如何才能知道生成的簇比较好呢?在包含簇分配结果的矩阵ClusteAssment中保存着每个点的误差,即该点到簇质心的距离平方值。下面讨论利用该误差来评价聚类质量的方法。
先看下面的一张图的聚类结果,这是一个包含三个簇的数据集上运行kmeans算法之后的结果,但是点的簇分配结果值没有那么准确。kMeans算法收敛但聚类效果较差的原因是,kMeans算法收敛到了局部最小值,而非全局最小值(局部最小值指结果还可以但并非最好结果,全局最小值是可能的最好结果。)
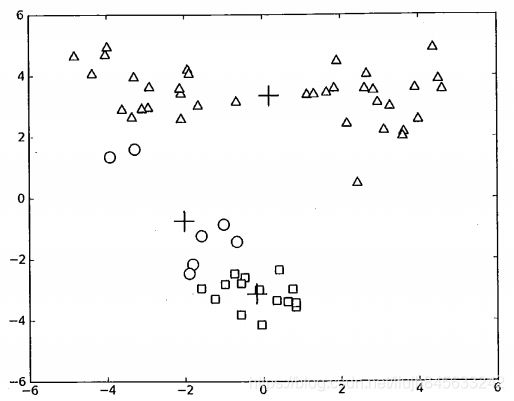
一种用于度量聚类效果的指标是SSE(Sum of Squared Error,误差平方和),对应ClusterAssment第二列的值之和。SSE值越小表示数据点越接近它们的质心,聚类效果也越好。因为对误差取了平方,因此更加重视那些远离中心的点。一种肯定可以降低SSE值的方法是增加簇的个数,但这违背了聚类的目标。聚类的目标是在保持簇数目不变的情况下提高簇的质量。
对于上图中问题的改进,我们可以对生成的簇进行后处理,一种方法是将具有最大SSE值的簇划分成两个簇。具体实现时可以将最大簇包含的点过滤出来并在这些点上运行KMeans算法,其中的k设为2.
为了保持簇总数不变,可以将某两个簇进行合并。从图中很明显可以看出,应将图下部的两个出错的簇质心进行合并。可以很容易对二维数据上的聚类进行可视化,但是如果遇到40维的数据应该如何去做?
有两种可以量化的办法:合并最近的质心,或者合并两个使得SSE增幅最小的质心。第一种思路通过计算所有质心之间的距离,然后合并距离最近的两个点来实现。第二种方法需要合并两个簇然后计算总SSE值。必须在所有可能的两个簇上重复上述处理过程,直到找到合并最佳的两个簇为止。接下来将讨论利用上述簇划分技术得到更好的聚类结果的方法。
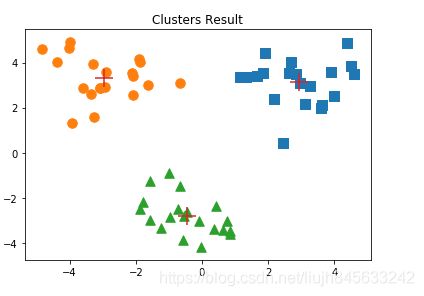
四、二分K-均值算法
为了克服k-均值算法收敛于局部最小值的问题,有人提出了另一个称为二分K-均值(bisecting K-means)的算法。该算法首先将所有点作为一个簇,然后将该簇一分为二。之后选择其中一个簇继续进行划分,选择哪一个簇进行划分取决于对其划分是否可以最大程度降低SSE值。上述基于SSE的划分过程不断重复,直到得到用户指定的簇数目为止。
打开kMeans.py文件,写入如下代码:
"""
函数说明:二分K均值算法
Parameters:
dataSet:数据集
k:待分类别数
distMeas:距离计算
Returns:
centList:质心列表
clusterAssment:样本分配结果
"""
def biKmeans(dataSet, k, distMeas=distEclud):
m = np.shape(dataSet)[0] #样本个数
clusterAssment = np.mat(np.zeros((m,2))) #初始化样本分配结果
centroid0 = np.mean(dataSet, axis=0).tolist()[0] #创建第一个初始质心
centList = [centroid0] #初始化质心列表
for j in range(m): #计算初始误差
clusterAssment[j, 1] = distMeas(np.mat(centroid0), dataSet[j,:])**2
while (len(centList) < k): #未达到指定质心数,就继续迭代
lowestSSE = np.inf #初始化最小SSE
for i in range(len(centList)): #对于质心列表中的每个质心
#get data points currently in cluster i
ptsInCurrCluster = dataSet[np.nonzero(clusterAssment[:,0].A==i)[0], :]
centroidMat, splitClustAss = kMeans(ptsInCurrCluster, 2, distMeas) #对此质心内的样本点进行二分类
# 该样本中心 二分类之后的 误差平方和 SSE
sseSplit = sum(splitClustAss[:,1])
# 其他未划分数据集的误差平方和 SSE
sseNotSplit = sum(clusterAssment[np.nonzero(clusterAssment[:,0].A!=i)[0],1])
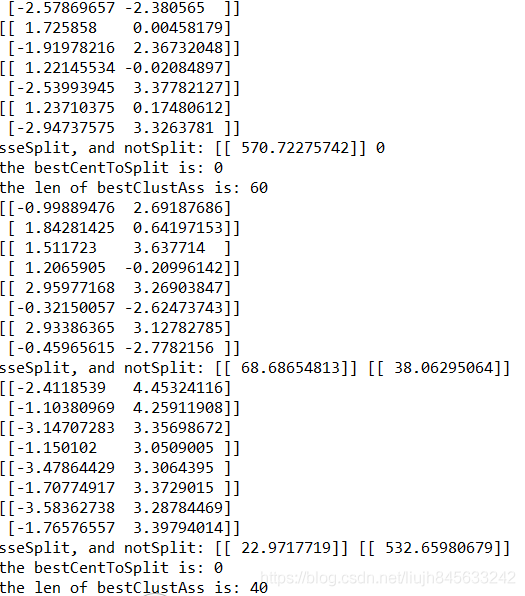
print("sseSplit, and notSplit:", sseSplit,sseNotSplit)
# 划分后的误差和没有进行划分的数据集的误差之和为本次误差
if(sseSplit + sseNotSplit) < lowestSSE:
bestCentToSplit = i # 记录应该被划分的中心的索引
bestNewCents = centroidMat #最好的新划分出来的中心
bestClustAss = splitClustAss.copy()
lowestSSE = sseSplit + sseNotSplit # 更新总的误差平方和
bestClustAss[np.nonzero(bestClustAss[:,0].A == 1)[0],0] = len(centList) #???
bestClustAss[np.nonzero(bestClustAss[:,0].A == 0)[0],0] = bestCentToSplit
print("the bestCentToSplit is:", bestCentToSplit)
print("the len of bestClustAss is:", len(bestClustAss))
# 将最应该被划分的中心 替换为 划分后的 两个 中心(一个替换,另一个 append在最后添加)
centList[bestCentToSplit] = bestNewCents[0,:].tolist()[0] #替换
centList.append(bestNewCents[1,:].tolist()[0]) #添加
#更新样本分配结果
clusterAssment[np.nonzero(clusterAssment[:,0].A == bestCentToSplit)[0],:] = bestClustAss
return np.mat(centList), clusterAssment
def biKmeansTest():
dataMat = np.mat(loadDataSet('testSet2.txt'))
# myCentroids, clustAssing = kMeans(dataMat, 3)
showResult(dataMat, clusterAlg=biKmeans, numClust=3)
if __name__ == '__main__':
# plotDataSet('testSet.txt')
# kMeansTest()
biKmeansTest()
运行结果如下图所示:
五、示例:对地图上的点进行聚类
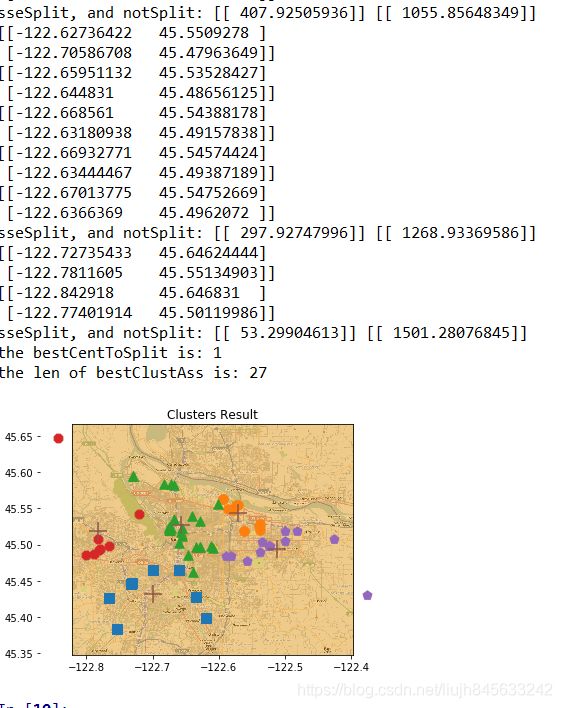
假如有一种情况:你的朋友Drew希望你带他去城里庆祝他的生日。由于其他一些朋友也会过来,所以需要你提供一个大家都可行的计划。Drew给了你一些他希望去的地址。这个地址列表很长,有70个位置。书上提供了一个yahoo API来获取地址的经度和纬度的方法,但是API的地址已经失效。我们可以直接将文件places.txt中的数据进行聚类,该文件的第3列和第4列存放的分别是对应的经度和纬度。
也就是说,一晚上要去70个地方,你要决定一个将这些地方进行聚类的最佳策略,这样就可以安排交通工具抵达这些簇的质心,然后步行到每个簇内地址。
打开kMeans.py文件,写入如下代码:
"""
函数说明:球面距离计算函数
Parameters:
vecA:地址向量A
vecB:地址向量B
Returns:
两点间的距离
"""
def distSLC(vecA, vecB): #Spherical Law of Cosines
a = np.sin(vecA[0,1]*np.pi/180) * np.sin(vecB[0,1]*np.pi/180)
b = np.cos(vecA[0,1]*np.pi/180) * np.cos(vecB[0,1]*np.pi/180) * np.cos(np.pi*(vecB[0,0]-vecA[0,0])/180)
return np.arccos(a+b)*6371.0
"""
函数说明:聚类并绘制结果图
Parameters:
numClust:簇个数
Returns:
无
"""
def clusterClubs(numClust=5):
datList = []
for line in open('places.txt').readlines():
lineArr = line.split('\t')
datList.append([float(lineArr[4]), float(lineArr[3])])
datMat = np.mat(datList)
myCentroids, clustAssing = biKmeans(datMat, numClust, distMeas=distSLC)
fig = plt.figure()
rect = [0.1,0.1,0.8,0.8]
scatterMarkers = ['s', 'o', '^', '8', 'p','d', 'v', 'h', '>', '<'] #散点标记的列表
axprops = dict(xticks=[], yticks=[])
ax0 = fig.add_axes(rect, label='ax0', **axprops)
imgP = plt.imread('Portland.png') #读入Portland.png
ax0.imshow(imgP)
ax1 = fig.add_axes(rect, label='ax1', frameon=False) #新建区域ax1,并获得绘制的句柄
ax1.set_title("Clusters Result")
for i in range(numClust):
ptsCurrCluster = datMat[np.nonzero(clustAssing[:,0]==i)[0],:] #将样本属于第i个类别的放在 CurrCluster中
markerStyle = scatterMarkers[i % len(scatterMarkers)] #第i个类别簇使用的散点标记符号
ax1.scatter(ptsCurrCluster[:,0].flatten().A[0], ptsCurrCluster[:,1].flatten().A[0],marker=markerStyle, s=90) #绘制第i个簇类
#绘制最终的质心
ax1.scatter(myCentroids[:,0].flatten().A[0], myCentroids[:,1].flatten().A[0], marker='+', s=300)
plt.show()
if __name__ == '__main__':
# plotDataSet('testSet.txt')
# kMeansTest()
# biKmeansTest()
clusterClubs(numClust=5)
运行结果如下所示:
六、总结
- 聚类是一种无监督的学习方法。所谓无监督学习是指事先并不知道要寻找的内容,即没有目标变量。聚类将数据点归到多个簇中,其中相似数据点处于同一簇,而不同相似数据点处于不同簇中。聚类中可以使用多种不同的方法来计算相似度。
- k-均值聚类的优点是容易实现,缺点是可能收敛到局部最小值,在大规模数据集上收敛较慢。适用于数据类型,数值型数据
- 二分k-均值算法首先将所有点作为一个簇,然后使用k-均值算法(k=2)对其划分。下一次迭代时,选择最大误差的簇进行划分。该过程重复直到k个簇创建成功为止。二分k-均值的聚类效果要好于k-均值算法。
参考资料
- add_axes()——python绘图 https://blog.csdn.net/qq_41011336/article/details/83017101
- 博客: https://blog.csdn.net/xiaoxiaowenqiang/article/details/78076896
- 博客: https://blog.csdn.net/gamer_gyt/article/details/51244850
- scikit-learn学习之K-means聚类算法与 Mini Batch K-Means算法 https://blog.csdn.net/gamer_gyt/article/details/51244850
- 《机器学习实战》第十章 利用k-均值聚类算法对未标注的数据分组
- scikit官方网址 http://scikit-learn.org/dev/modules/clustering.html#clustering