torch笔记——初级RNNCell和RNN构建
目录
一:NLP背景与RNN
1、顺序与循环
2、权重共享
3、维度说明
4、几点说明
二:代码说明(利用RNNCell)实现
1、数据准备
2、定义RNNCell
三:定义训练循环
四:利用RNN实现
1、代码
一:NLP背景与RNN
1、顺序与循环
语言,天气预报,音乐等数据不像图像分类一样是分裂的。他们都是有着前后顺序与相关性。目的是通过输入前几天的天气数据可以分析出未来的天气情况。输入一串文本可以识别出他的转义意思(翻译)
2、权重共享
RNN的核心思想就是权重共享,即当前的输出是由以前输入的值来影响的。可以把RNNCell的一条路径看作一个线性层(Line)。
【循环神经网络】5分钟搞懂RNN,3D动画深入浅出_哔哩哔哩_bilibili
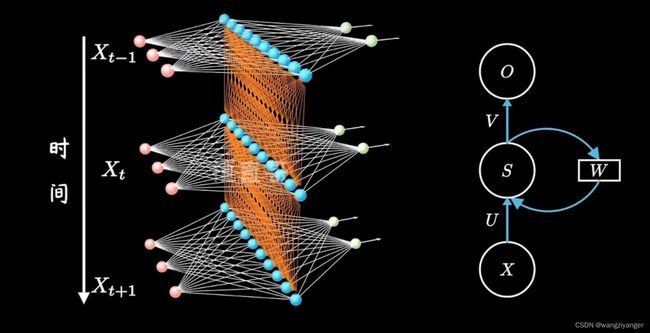
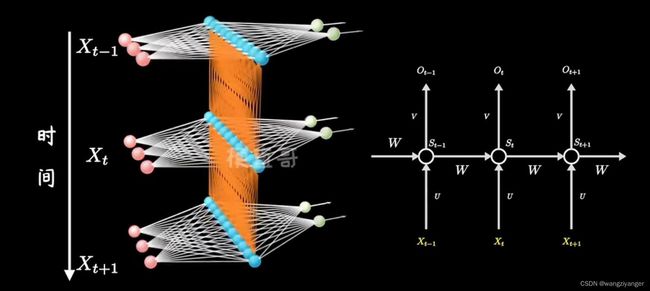
RNNCell的内部构造如下图所示。其中whh表示负责输入是上一时刻输出w权重(h = hidden)。wih表示负责输入时input的w值(i= input)。两个线性层的融合(相加)再利用tanh函数作为激活函数进行输出。注意输出有两条路径,输出层和隐藏层。
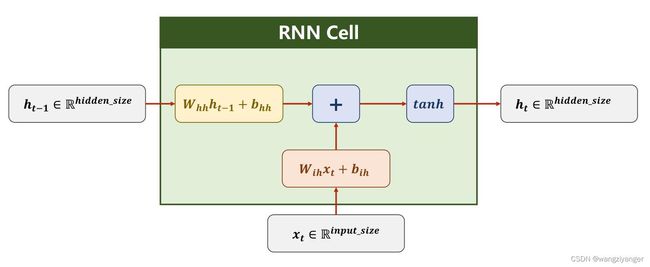
3、维度说明
input = (num, batchsize, inputsize),如后面的hello (5, 1, 4)
- num:一句话几个输入字符
- batchsize:同时分析几句话(如果是[[nihao],[hello]]同时进行分析输入,则batchsize=2)
- inputsize:将词典编码分成几维度——(在onehot编码方式中表示有几个无重复的字母)
hiddensize是你想得到的结果维度如(1,4)
| 0.2 | 0.3 | 0.4 | 0.1 |
| h的概率 | e的概率 | l的概率 | o的概率 |
4、几点说明
训练过程中注意大小循环的设置、对于交叉熵函数torch.nn.CrossEntropyLoss(),输入input是浮点型,label要是Long形。因为它适用于多分类问题。label表示的是onehot的编码,最多64bit。只能是long要注意、反向传播,梯度清零和更新要在大循环中进行,因为小循环中要进行梯度共享。
二:代码说明(利用RNNCell)实现
1、数据准备
import torch
#准备数据
char = ['h', 'e', 'l', '0']
hello = [0, 1, 2, 2, 3]
ohlol = [3, 0, 2, 3, 2]
char_onehot = [[1, 0, 0, 0],
[0, 1, 0, 0],
[0, 0, 1, 0],
[0, 0, 0, 1]]
input = [char_onehot[i] for i in hello]
input_hello = torch.Tensor(input).view(5, 1, 4)
print(input_hello)
ohlol = torch.LongTensor(ohlol).view(-1, 1)
print(ohlol)
要注意先定义词典、把单词按照先后顺序,以出现的位置形成列表、再对char进行编码。然后利用
input = [char_onehot[i] for i in hello]
把输入数据遍历出来。再将label(注意前文说过的Long形)和input张量化。
2、定义RNNCell
#定义RNNCELL
'''要输入输入维度,隐藏层维度,输入数据'''
class RNNCell(torch.nn.Module):
def __init__(self):
super(RNNCell, self).__init__()
self.rnn = torch.nn.RNNCell(input_size=4, hidden_size=4)
def forward(self, x, y):
hidden = self.rnn(x,y)
return hidden
def hidden_zero(self):
hidden = torch.zeros(1, 4)
return hidden
model = RNNCell() #实例化
MSE = torch.nn.CrossEntropyLoss()
opt = torch.optim.Adam(model.parameters(), lr=0.1)注意每一次大循环中都要设置hidden清零。对于hidden0,是一种先验概率,如果不需要可以设成0
三:定义训练循环
大循环(epoch)负责总的训练次数,负责做梯度更新和反向传播,因为RNN中要权重共享, 不能在一句话中更改权重。还可以输出本轮错误率,***最重要的是hidden的先验重置 小循环(input,index)负责按照顺序对一句话”hello"进行顺序训练
#定义训练循环(大循环+小循环)
'''
大循环(epoch)负责总的训练次数,负责做梯度更新和反向传播,因为RNN中要权重共享,
不能在一句话中更改权重。还可以输出本轮错误率,***最重要的是hidden的先验重置
小循环(input,index)负责按照顺序对一句话”hello"进行顺序训练
'''
for epoch in range (15):
loss = 0
hidden = model.hidden_zero()
print('本轮预测结果是:', end = '--')
for input, index in zip(input_hello, ohlol):
hidden = model(input, hidden)
loss += MSE(hidden, index)#这里要注意CrossEntropyloss的前是float形,index要求long形,因为
#它是处理多分类问题,所以index是要独热编码,long满足这个条件
#它的输入大小可以不同
a, b = torch.max(hidden, -1)
print(char[b.item()],end='')
opt.zero_grad()
loss.backward()
opt.step()
print("损失为", loss.item() )四:利用RNN实现
1、代码
import torch
import numpy
import matplotlib as mat
#准备数据集
char_input = ['h', 'l', 'e', 'o']
char_onehot = [[1, 0, 0, 0],
[0, 1, 0, 0],
[0, 0, 1, 0],
[0, 0, 0, 1]]
hello = [0, 2, 1, 1, 3]
ohlol = [3, 0, 1, 3, 1]
input = [char_onehot[i] for i in hello]
input = torch.Tensor(input).view(5, 1, 4)
ohlol = torch.LongTensor(ohlol)#记得crossentropyloss的label要求long形
#定义RNN
class RNN (torch.nn.Module):
def __init__(self):
super(RNN, self).__init__()
self.rnn = torch.nn.RNN(input_size=4,hidden_size=4)
def forward(self,x,y):
output, hidden = self.rnn(x,y)#记得rnn输出的顺序是,output,hidden
return output, hidden
model = RNN()
MSE = torch.nn.CrossEntropyLoss()
opt = torch.optim.Adam(model.parameters(),lr=0.1)
#adam在RNN中的效果会更好
#定义循环
for epoch in range(15):
output, hidden = model(input, torch.zeros(1, 1, 4))
#hidden是三维的(hidden_num,同时处理的语句数,输入维度(字典的字数))
output = output.view(-1, 4)
#处理loss的时候只能处理2维,而RNN输出的是(5,1,4)
_, id = torch.max(output,dim=1)
str = [char_input[i] for i in id.numpy()]#将张量变成list读取
print(str)
loss = MSE(output, ohlol)
opt.zero_grad()
loss.backward()
opt.step()
2、 注意
维度转换、交叉熵的输入形(output,hidden),变量名称设定尽量不要有重复