图像几何变换时为何要用到插值算法?_图像超分辨率技术-简介
这篇是我之前的课程报告,格式传上来乱了,有时间我会调整,我先把pdf版本放在最前面,建议直接看pdf。
一、 定义与分类
超分辨率复原技术的基本思想是釆用信号处理的方法,在改善图像质量的同时,重建成像系统截止频率之外的信息,从而在不改变硬件设备的前提下,获取高于成像系统分辨率的图像。超分辨率复原的概念广义上讲包含3种情况:
1)单幅图像分辨率放大
2)从多帧连续图像中重建超分辨率单帧图像;
3)视频序列的超分辨率重建。
单幅图像放大主要利用对髙分辨率图像的先验知识和以混叠形式存在的高频信息进行复原。
后两种情况除了利用先验知识和单幅图像信息外,还可以应用相邻图像之间的互补信息进行超分辨率重建,得到比任何一幅低分辨率(LR, Low Resolution)观测图像分辨率都高的高分辨率(HR, High Resolution)阁像。核心思想是用时间带宽换取空间分辨率。简单来讲,是在无法得到一张超高分辨率的图像时,多拍几张图像,然后利用连续多帧低分辨率图像中不同而又相似的信息,并结合有关先验知识,将这一系列低分辨率的图像组成一张高分辨的图像。
降质退化模型:
低分辨率图像在成像的过程中受到很多退化因素的影响,运动变换、成像模糊和降采样是其中最主要的三个因素。整个过程可以通过使下图的线性变换模型来表征。

上述退化模型可以由以下线性变换表示;
L=DBFH+N
式中,L表示观测图像,H表示输入的高分辨率图像,F表示运动变换矩阵,通常由运动、平移等因素造成,B表示模糊作用矩阵,通常由环境或成像系统本身引起,D表示降采样矩阵,通常由成像系统的分辨率决定,N表示加性噪声,通常来自于成像环境或成像过程。
超分辨率效果评价:
超分辨率的效果除了用人眼进行主管判断之外,寻找能够量化其效果的衡量指标也非常重要。主要可以参考ECCV2018 workshop PIRM2018感知超分辨率图像重建挑战赛的几项评价指标。
1. MSE和PSNR
MSE均方误差(Mean Squared Error)
PSNR(PeakSignal to Noise Ratio)峰值信噪比,单位是dB,数值越大表示失真越小。
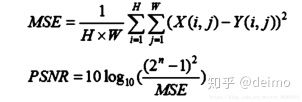
PSNR是最普遍和使用最为广泛的一种图像客观评价指标,然而它是基于对应像素点间的误差,并未考虑到人眼的视觉特性。因为人眼对空间频率较低的对比差异敏感度较高,对亮度对比差异的敏感度较色度高,人眼对一个区域的感知结果会受到其周围邻近区域的影响,因而经常出现评价结果与人的主观感觉不一致的情况。
1. SSIM(structural similarity)结构相似;
结构相似性SSIM从亮度、对比度和结构这三个方面来评估两幅图像的相似性,是一种衡量两幅图像相似度的指标。SSIM使用的两张图像中,一张为未经压缩的无失真图像,另一张为失真后的图像。
给定两个图像x和y, 两张图像的结构相似性可按照以下方式求出:

结构相似性理论认为,自然图像具有极高的结构性,表现在图像的像素间存在着很强的相关性,尤其是在空间相似的情况下。这些相关性在视觉场景中携带着关于物体结构的重要信息。假设人类视觉系统(HSV)主要从可视区域内获取结构信息。所以通过探测结构信息是否改变来感知图像失真的近似信息。
作为结构相似性理论的实现,结构相似度指数从图像组成的角度将结构信息定义为独立于亮度、对比度的,反映场景中物体结构的属性,并将失真建模为亮度、对比度和结构三个不同因素的组合。用均值作为亮度的估计,标准差作为对比度的估计,协方差作为结构相似程度的度量。
大多数的基于误差敏感度(error sensitivity)的质量评估方法(如MSE,PSNR)使用线性变换来分解图像信号,这不会涉及到相关性。SSIM意在找到更加直接的方法来比较失真图像和参考图像的结构。
2. 除PSNR和SSIM外还有一些评价指标:
FID(Frechet Inception Distance)度量生成样本和真实数据集之间的Frechet距离。同样距离越低越好
IS,即Inception Score,用过Inception v3模型度量图片分数,可用来算单张图片的分值,越高越好。
二、 超分辨率重建的方法
基于重建的方法
基于重建的方法通过对低分辨率观测图像的获取过程进行建模,利用正则化方法构造高分辨率图像的先验约束,由LR观测阁像估计HR图像,最终将图像超分辨率复原问题就转变为对一个约束条件下的代价函数最优化问题。这类方法可以很方便地结合先验知识,并将图像上釆样这一病态问题转化为良态问题,通常能够取得优于非模型化算法的结果。正则化约束项通常为人为定义的关于HR阁像的平滑约束项,用这种约束项作为HR图像的先验知识。
在采用正则化方法构造约束条件时,往往利用的是图像的局部平滑特征、边缘特征、像素值的非负性以及能量有限性等先验知识。求解最优化问题时,通常 采用一些迭代算法求解,如梯度下降法、共轭梯度法等。
现有的研究已表明,当图像放大系数较大时,基于正则化重建中的平滑项会导致重建图像过于平滑。
实际获取的低分辨率图像可以认为是原始高分辨率场景经过一定的成像过程得到的,而成像过程中引入了模糊、噪声、降采样等降质过程。超分辨率复原过程是要通过信号处理的方法,求解成像过程的逆过程,重建原始的高分辨率 图像。早期的超分辨率复原算法大多是基于这一思想而提出的,因而被统称为基于重建的方法。这些方法具体又可分为频域方法和空域方法两类。
1. 频域方法:
1984年,Tsai和Huang开初了由低分辨率图像序列复原单幅高分辨率图像的工作,给出了基于频域的复原方法。
u R Y Tsai, T S Huang. Multiple frame image restoration and registration, AdvancesinComputerVision and Image Processing. Greenwich, CT: JAI Press Inc. 1984: 317-339.
图像序列被模型化为同一幅场景经整体平移后欠采样的结果,欠采样过程在频域表现为频谱混叠。设F为多帧观测图像傅里叶变换 的逐行排列,A:为H标高分辨率图像傅里叶变换的逐行排列,则观测模型可表示为:Y=AX
其中A为系数矩阵,包含了各帧之间时域平移所对应的频域相位变化关系,若观测图像与各帧矩阵图像间的平移关系己知,则可以求出Y和X,再求解上述方程组即可得到目标高分辨率图像x的傅里叶变换,并通过反变换求解x。
3. 空域方法
1. 非均匀插值方法
非均匀插值方法是最直观的一种超分辨率复原方法。该方法将运动估 计、非均匀插值、去模糊3个过程依次执行,首先利用估计所得的相对运动信息, 通过插值方法得到高分辨率图像,然后用传统的图像恢复方法去除模糊和噪声。
非均匀插值方法计算复杂度低,易于实用化,但是该算法的观测模型只适用 于所有低分辨率图像的模糊和噪声特征都相同的情况。此外,由于恢复时忽略了
插值过程引入的误差,因此无法保证整个复原算法能够得到最优的效果。
2. 迭代反投影方法

迭代反投影方法是一类研究较早的空域超分辨率复原方法,其复原过程为:首先给定一个高分辨率图橡的初始估计
和降质模型并据此产生一组模拟的低分辨率图像序列:
进而通过反投影算子
将模拟低分辨串图像
与观测低分辨率图像
的误差进行反投影,并通过多次迭代不断更新超分辨复原的估计图像.其迭代反投影过程为:
式中y表示实际的低分辨率观测图像:,t为迭代次数,
为第t次迭代所得的高分辨率估计围像
经降质模型A后获得的模拟低分辨率估计图像:
为反投影算子.将此式不断迭代下去,H到某种依赖于y和
的误差准则达到最小。 在IBP算法中,反投影算子
按比例对高分辨率估计图像
进行惩罚,该算子的选择是算法的关键,其典型取值是可以看作是一种额外的约束条件,表示解的性质。
迭代反投影算法的算法直观,简单,较易实现,但是由于超分辨率复复原问题具有一定的病态性.没有唯一的解,因此要得到合适的
,难度很大.而且IBP 方法也难以有效利用关于图像的先验知识。
3. 凸集投影方法POCS
在这种理论屮,超分辨率解空间中的解有多个限制条件,每个限制条件定义为向量空间中的凸集合。这些限制条件一般是图像的一些比较理想的性质,如正定、能量 有界、数据可靠和平滑等。超分辨率复原问题的解空间是这些凸集的限制集的交空间。
在计算上,POCS采用重复修正的方法,其基本过程如图所示。

首先建立高分辨率图像的初始估计图像(通常采用双线性插值的方法),然后从高分辨率估计图像上的某一点开始,将图像当前估计值投影到凸形集合上,判断当前估计图像是否满足所有的凸形约束,若不满足,则将其残差反投影到高分辨率估计图像上对其进行修正。通过多次迭代,使得最后的解落在图像解空间与约束凸集的交集内。 一般来说,投影到交集上的点不是唯一的,因此最终结果往往和初始值的选取有关。
凸集投影法的原理直观简单,能够将各种灵活的空域观测模型、一般的运动模型以及降质模型综合在其屮,运动及观测模型的复杂度对POCS方法的性能几乎没有影响。更重要的是,它具有很强的利用先验知识的能力。一般来说,确定包含理想解特点的限制集比较容易实现,但可能施加的其他限制条件如正定性、光滑性以及能量有界性则难以用惩罚函数来表示。
凸集投影法的解通常不是唯一的,其解空间定义为所有凸集约束的交集,因而对初始值具有较强的依赖性。投影过程需要的运算量较大,这在一定程度上限制了POCS方法的应用。
4. 随机正则化方法-最大后验概率(MAP)方法
最大后验概率(MAP)方法是统计方法的典型代表,它把超分辨率复原问题 看成一个统计估计问题,在已知低分辨率图像序列的前提下,使出现高分辨率图像的后验概率达到最大。
根据MAP估计器,加性噪声、低分辨率观测图像和理想高分辨率图像都可 以假设为随机信号。未知高分辨率图像z的MAP估计可以通过如下过程获得: 在给定观测图像序列少的条件下,使理想图像的条件概率密度函数达到最大。根据贝叶斯原理,图像的最优估计问题可以表示为:
取对数并舍弃与求解过程无关的常数项后可得:
要求最优解,首先要确定先验概率P(z)和条件概率P(y/z)。条件概率项通常采用高斯模型,先验概率应具有以下特点:
①是一个局部平滑函数;
②具有边缘保持能力;
③是一个凸函数。
各种最大后验概率估计算法的差别主要在于先验模型的选择,其中典型的是Huber-Markov模型及其改进形式。
目前,MAP图像超分辨率复原己经成为广泛接受的算法,是最灵活、最有 前景的算法之一。其优点主要表现在以下几方面:
①该框架能够充分考虑先验知识,这对求解超分辨率复原的病态问题,提 高算法的复原效果是非常有益的;
②以_作为先验知识的模型可以提供十分方便、直观和符合实际的成像 模型;
③在MAP框架内可以实现运动估计和超分辨率复原的同时求解。
基于学习的方法
该类方法的基本思想是通过学习过程获得先验知识,取代基于正则化方法中人为定义的平滑约束项。具体来说,是利用不同图像在高频细节上的相似性,通过学习算法获得高分辨率与低分辨率图像之间关系,以指导高分辨率图像的重建。
基于学习的超分辨率复原算法被公认为是一种非常有前途的方法。研究结果表明,基于学习的方法对于特定图像如文本、人脸等,已取得了较好的效果,尤其是在放大倍数较高的时候。
2017年Google 提出的一项技术。他们可以通过机器学习来消除视频图像中的马赛克。有一定限制,以下图为例,它训练的神经网络是针对人脸图像的,如果输入的马赛克图像不是人脸,就无法还原。


1. 基于邻域嵌入的超分辨率方法NE(Neighbor Embedding)
u Hong Chang, Dit-Yan Yeung, YiminXiong.Super-Resolution through Neighbor Embedding. CVPR (1) 2004: 275-282
这篇论文提出了一种解决单图像超分辨率问题的新方法。给定低分辨率图像作为输入,使用一组训练示例恢复其高分辨率对应物。这种方法受到最近的流形学习方法的启发,特别是局部线性嵌入(LLE)。

LLE的思想是:一个流形在很小的局部邻域上可以近似看成欧式的,是局部线性的。那么在小的局部邻域上,一个点就可以用它周围的点在最小二乘意义下最优的线性表示

NE算法将所有图像表示为有重叠区域的小块。目标高分不仅与输入低分有关(决定了重建的准确度),还应保留目标高分图像中邻近patch之间的内部联系(决定了重建的高分图像的局部兼容性和平滑程序)。为此需要保证:
1) 重建高分图像的每个patch都与多个训练集的patch转换有关
2) 输入低分图像patch间的局部关系在重建的高分图像中被保留
3) 重建高分图像的邻近patch被重叠区域所约束,以此提高局部兼容与平滑度。
这种方法基于这样的假设:低分和高分图像中的patchs在两个不同的特征空间中形成了相似几何结构的流形。这种假设是有效的,因为只要嵌入是等距的,结果就稳定,不依赖于分辨率。
NE方法的具体步骤:
1. 降质:
对训练图像降质(比如目标SR是LR的N倍大,则把训练图像缩小N倍)得到LR training images;
2. 分块
把LR和LR training images分成大小为s*s ,重叠区域宽为overlap的重叠图像块(image pitch),SR training images则是Ns*Ns大的重叠图像块(image pitch),其中低分图像中的每一块对应SR training images中每一块;
3. 特征提取
计算LR和LR training images各像素点的一阶梯度和二阶梯度,用一个特征向量代表一个图像块,特征向量的集合分别为XT,XS。对于SR training images,只需要每个pitch内每个像素减去块内所有像素值的平均值,这里为什么减去均值的原因是,超分辨率的本质是要找回由于图像降质过程丢失的高频细节信息,高频细节信息是由低分辨率图像中的中频信息所决定,而不是整个低分辨率图像。减去它的均值其实是中频信息。SR training pitch同样是用一个向量表示,集合记为YS;
4. NE
对每低分图像中的patch:
1) 找到训练集的K近邻Nq:(欧氏距离)
2) 计算Nq的重建权重,使得重建误差最小。(是一个受约束的最小二乘问题)
局部重建误差:

约束项:
;不属于K近邻点的训练集特征点权重为0;
假设:
则可得近邻点集Nq中的每个特征点的权重:

这些权重的集合是一个q×p的矩阵(共有p个patch):W= [wqp]Nt×Ns
3) 用K近邻点的高分特征和重建权重计算重建高分图像的嵌入点.
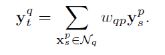
5. 图像重建
现在已知
,只要把
中的特征向量恢复到图像即可。按顺序把
中的每个向量代表的图像块恢复到原来的位置,重叠区域值为相邻image pitch在该区域的平均值表示,最后加上LR每个图像块的中频信息,即SR每个图像块像素值减去平均值,即可求出目标SR。
实验结果:
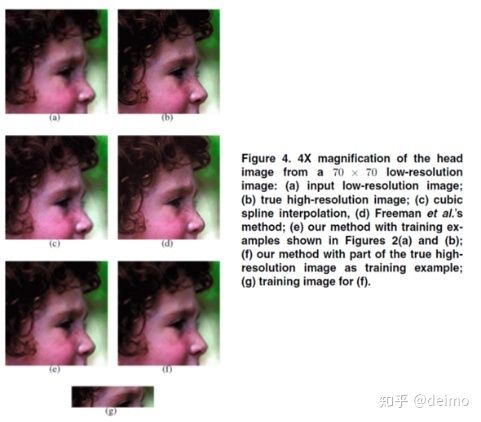
这篇论文的实验分为两种情形:
第一种:训练集是一组与原图像无关的图像
第二种:训练集是低分辨率图像的高分辨率原图的一小部分。此时由于训练集非常小,每个patch通过旋转到不同的方向(0◦,90◦,180◦和270◦)被表示为八个不同的特征向量,并获得各自的镜像。
得到的结果如下图所示
基于深度学习
基于深度学习的图像超分辨率技术的重建流程主要包括以下几个步骤:
(1) 特征提取:首先对输入的低分辨率图像进行去噪、上采样等预处理,然后将处理后的图像送入神经网络,拟合图像中的非线性特征,提取代表图像细节的高频信息;
(2) 设计网络结构及损失函数:组合卷积神经网络及多个残差块,搭建网络模型,并根据先验知识设计损失函数;
(3) 训练模型:确定优化器及学习参数,使用反向传播算法更新网络参数,通过最小化损失函数提升模型的学习能力;’
(4) 验证模型:根据训练后的模型在验证集上的表现,对现有网络模型做出评估,并据此对模型做出相应的调整。
1. SRCNN
u Learning a Deep Convolutional Network for Image Super-Resolution, ECCV2014)
SRCNN是深度学习用在超分辨率重建上的开山之作。SRCNN的网络结构非常简单,仅仅用了三个卷积层.
这篇文章将SR过程主要分为三个阶段:首先使用双三次(bicubic)插值将低分辨率图像放大成目标尺寸,接着通过三层卷积网络拟合非线性映射,最后输出高分辨率图像结果。
1. 图像块的提取和特征表(Patch extraction and representation)
这个阶段主要是对LR进行特征提取,并将其特征表征为一些feature maps。
可表征为“卷积层(c*f1*f1卷积核)+RELU”
2. 特征的非线性映射(Non-linear mapping)
这个阶段主要是将第一阶段提取的特征映射至HR所需的feature maps。
可表征为“全连接层+RELU”,而全连接层又可表征为卷积核为1x1的卷积层,因此,本层最终形式为“卷积层(n1*1*1卷积核)+RELU”
3. HR重建(Reconstruction)
这个阶段是将第二阶段映射后的特征恢复为HR图像。再做一次卷积进行重构,类似于传统方法的平均处理。
可直接表征为“卷积层(n2*f3*f3)”

三个卷积层使用的卷积核的大小分为为9x9,,1x1和5x5,前两个的输出特征个数分别为64和32。前两层的激活函数都是 ReLU,第三层只是线性卷积运算,未使用激活函数。
用Timofte数据集(包含91幅图像)和ImageNet大数据集进行训练。使用均方误差(Mean Squared Error, MSE)作为损失函数,有利于获得较高的PSNR。
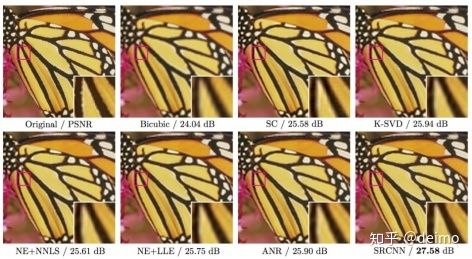
4. FSRCNN
u Accelerating the Super-Resolution Convolutional Neural Network, ECCV2016)
FSRCNN与SRCNN都是香港中文大学Dong Chao, Xiaoou Tang等人的工作。FSRCNN是对之前SRCNN的改进,主要在三个方面:一是在最后使用了一个反卷积层放大尺寸,因此可以直接将原始的低分辨率图像输入到网络中,而不是像之前SRCNN那样需要先通过bicubic方法放大尺寸。二是改变特征维数,使用更小的卷积核和使用更多的映射层。三是可以共享其中的映射层,如果需要训练不同上采样倍率的模型,只需要微调最后的反卷积层。
由于FSRCNN不需要在网络外部进行放大图片尺寸的操作,同时通过添加收缩层和扩张层,将一个大层用一些小层来代替,因此FSRCNN与SRCNN相比有较大的速度提升。FSRCNN在训练时也可以只fine-tuning最后的反卷积层,因此训练速度也更快。FSRCNN与SCRNN的结构对比如下图所示。

FSRCNN可以分为五个部分:
特征提取:SRCNN中针对的是插值后的低分辨率图像,选取的核大小为9×9,这里直接是对原始的低分辨率图像进行操作,因此可以选小一点,设置为5×5。
收缩:通过应用1×1的卷积核进行降维,减少网络的参数,降低计算复杂度。
非线性映射:感受野大,能够表现的更好。SRCNN中,采用的是5×5的卷积核,但是5×5的卷积核计算量会比较大。用两个串联的3×3的卷积核可以替代一个5×5的卷积核,同时两个串联的小卷积核需要的参数3×3×2=18比一个大卷积核5×5=25的参数要小。FSRCNN网络中通过m个核大小为3×3的卷积层进行串联。
扩张:论文发现低维度的特征带来的重建效果不是太好,因此应用1×1的卷积核进行扩维,相当于收缩的逆过程。
反卷积层:可以堪称是卷积层的逆操作,如果步长为n,那么尺寸放大n倍,实现了上采样的操作。
FSRCNN中激活函数采用PReLU,损失函数仍然是均方误差。对CNN来说,Set91并不足够去训练大的网络结构,FSRCNN提出general-100 + Set91充当训练集。并且进行数据增强,1)缩小尺寸为原来的0.9, 0.8, 0.7和0.6。2)旋转 90°,180°和270°,因此获得了数据量的提升。
5. ESPCN
u Real-Time Single Image and Video Super-Resolution Using an Efficient Sub-Pixel Convolutional Neural Network, CVPR2016
论文在这篇论文中介绍到,类似SRCNN的方法,由于需要将低分辨率图像通过上采样插值得到与高分辨率图像相同大小的尺寸,再输入到网络中,这意味着要在较高的分辨率上进行卷积操作,从而增加了计算复杂度。这篇论文提出了一种直接在低分辨率图像尺寸上提取特征,计算得到高分辨率图像的高效方法。ESPCN网络结构如下图所示。

ESPCN的核心概念是亚像素卷积层(sub-pixel convolutional layer)。网络的输入是原始低分辨率图像,通过三个卷积层以后,得到通道数为 r^2 的与输入图像大小一样的特征图像。再将特征图像每个像素的 r^2 个通道重新排列成一个
的区域,对应高分辨率图像中一个
大小的子块,从而大小为
的特征图像被重新排列成
的高分辨率图像。理解的亚像素卷积层包含两个过程,一个普通的卷积层和后面的排列像素的步骤。是说,最后一层卷积层输出的特征个数需要设置成固定值,即放大倍数r的平方,这样总的像素个数就与要得到的高分辨率图像一致,将像素进行重新排列就能得到高分辨率图。在ESPCN网络中,图像尺寸放大过程的插值函数被隐含地包含在前面的卷积层中,可以自动学习到。由于卷积运算都是在低分辨率图像尺寸大小上进行,因此效率会较高。
训练时,可以将输入的训练数据标签,预处理成重新排列操作前的格式,比如将21×21的单通道图,预处理成9个通道,7×7的图,这样在训练时,就不需要做重新排列的操作。另外,ESPCN激活函数采用tanh替代了ReLU。损失函数为均方误差。
6. VDSR
u Accurate Image Super-Resolution Using Very Deep Convolutional Networks, CVPR2016
VDSR是第一个将全局残差引入SR的方法,使得训练速度明显加快,在PSNR以及SSIM评价指标上有了很大的提升。正如在VDSR论文中论文提到,输入的低分辨率图像和输出的高分辨率图像在很大程度上是相似的,也是指低分辨率图像携带的低频信息与高分辨率图像的低频信息相近,训练时带上这部分会多花费大量的时间,实际上只需要学习高分辨率图像和低分辨率图像之间的高频部分残差即可。残差网络结构的思想特别适合用来解决超分辨率问题,可以说影响了之后的深度学习超分辨率方法。VDSR是最直接明显的学习残差的结构,其网络结构如下图所示。

VDSR将插值后得到的变成目标尺寸的低分辨率图像作为网络的输入,再将这个图像与网络学到的残差相加得到最终的网络的输出。VDSR主要有4点贡献。1.加深了网络结构(20层),使得越深的网络层拥有更大的感受野。文章选取3×3的卷积核,深度为D的网络拥有(2D+1)×(2D+1)的感受野。2.采用残差学习,残差图像比较稀疏,大部分值都为0或者比较小,因此收敛速度快。VDSR还应用了自适应梯度裁剪(Adjustable Gradient Clipping),将梯度限制在某一范围,也能够加快收敛过程。3.VDSR在每次卷积前都对图像进行补0操作,这样保证了所有的特征图和最终的输出图像在尺寸上都保持一致,解决了图像通过逐步卷积会越来越小的问题。文中说实验证明补0操作对边界像素的预测结果也能够得到提升。4.VDSR将不同倍数的图像混合在一起训练,这样训练出来的一个模型就可以解决不同倍数的超分辨率问题。
7. SRGAN(SRResNet)
u Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network, CVPR2017
在这篇文章中,将生成对抗网络(Generative Adversarial Network, GAN)用在了解决超分辨率问题上。文章提到,训练网络时用均方差作为损失函数,虽然能够获得很高的峰值信噪比,但是恢复出来的图像通常会丢失高频细节,使人不能有好的视觉感受。SRGAN利用感知损失(perceptual loss)和对抗损失(adversarial loss)来提升恢复出的图片的真实感。感知损失是利用卷积神经网络提取出的特征,通过比较生成图片经过卷积神经网络后的特征和目标图片经过卷积神经网络后的特征的差别,使生成图片和目标图片在语义和风格上更相似。
SRGAN的工作是: G网通过低分辨率的图像生成高分辨率图像,由D网判断拿到的图像是由G网生成的,还是数据库中的原图像。当G网能成功骗过D网的时候,那就可以通过这个GAN完成超分辨率了。
文章中,用均方误差优化SRResNet(SRGAN的生成网络部分),能够得到具有很高的峰值信噪比的结果。在训练好的VGG模型的高层特征上计算感知损失来优化SRGAN,并结合SRGAN的判别网络,能够得到峰值信噪比虽然不是最高,但是具有逼真视觉效果的结果。SRGAN网络结构如下图所示。

在生成网络部分(SRResNet)部分包含多个残差块,每个残差块中包含两个3×3的卷积层,卷积层后接批规范化层(batch normalization, BN)和PReLU作为激活函数,两个2×亚像素卷积层(sub-pixel convolution layers)被用来增大特征尺寸。在判别网络部分包含8个卷积层,随着网络层数加深,特征个数不断增加,特征尺寸不断减小,选取激活函数为LeakyReLU,最终通过两个全连接层和最终的sigmoid激活函数得到预测为自然图像的概率。SRGAN的损失函数为:

其中内容损失可以是基于均方误差的损失的损失函数:

也可以是基于训练好的以ReLU为激活函数的VGG模型的损失函数:

i和j表示VGG19网络中第i个最大池化层(maxpooling)后的第j个卷积层得到的特征。对抗损失为:

文章中的实验结果表明,用基于均方误差的损失函数训练的SRResNet,得到了结果具有很高的峰值信噪比,但是会丢失一些高频部分细节,图像比较平滑。而SRGAN得到的结果则有更好的视觉效果。其中,又对内容损失分别设置成基于均方误差、基于VGG模型低层特征和基于VGG模型高层特征三种情况作了比较,在基于均方误差的时候表现最差,基于VGG模型高层特征比基于VGG模型低层特征的内容损失能生成更好的纹理细节。
8. EDSR
u Enhanced Deep Residual Networks for Single Image Super-Resolution, CVPRW2017
EDSR是NTIRE2017超分辨率挑战赛上获得冠军的方案。如论文中所说,EDSR最有意义的模型性能提升是去除掉了SRResNet多余的模块,从而可以扩大模型的尺寸来提升结果质量。主要使用了增强的ResNet,移除了batchnorm,使用了L1 loss训练.EDSR的网络结构如下图所示。
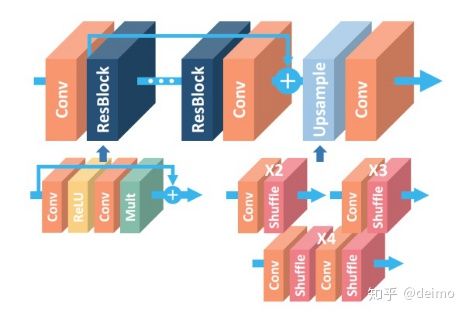
可以看到,EDSR在结构上与SRResNet相比,是把批规范化处理(batch normalization, BN)操作给去掉了。文章中说,原始的ResNet最一开始是被提出来解决高层的计算机视觉问题,比如分类和检测,直接把ResNet的结构应用到像超分辨率这样的低层计算机视觉问题,显然不是最优的。由于批规范化层消耗了与它前面的卷积层相同大小的内存,在去掉这一步操作后,相同的计算资源下,EDSR就可以堆叠更多的网络层或者使每层提取更多的特征,从而得到更好的性能表现。EDSR用L1范数样式的损失函数来优化网络模型。在训练时先训练低倍数的上采样模型,接着用训练低倍数上采样模型得到的参数来初始化高倍数的上采样模型,这样能减少高倍数上采样模型的训练时间,同时训练结果也更好。
这篇文章还提出了一个能同时不同上采样倍数的网络结构MDSR,如下图。

MDSR的中间部分还是和EDSR一样,只是在网络前面添加了不同的预训练好的模型来减少不同倍数的输入图片的差异。在网络最后,不同倍数上采样的结构平行排列来获得不同倍数的输出结果。
从文章给出的结果可以看到,EDSR能够得到很好的结果。增大模型参数数量以后,结果又有了进一步的提升。
9. CARN
u Fast, Accurate, and Lightweight Super-Resolution with Cascading Residual Network(ECCV 2018)
CADN是NTIRE2018超分辨率挑战赛上获得冠军的方案。

CADN具有以下三个特征:
1) 全局和局部级联连接。
2) 中间特征是级联的,且被组合在1×1大小的卷积块中
3) 使多级表示和快捷连接,让信息传递更高效
然而,多级表示的优势被限制在了每个本地级联模块内部,比如在快捷连接上的1×1卷积这样的乘法操作可能会阻碍信息的传递,所以认为性能会下降也在情理之中。这个论文在模型分析也介绍了
为了提升CARN的效率,论文提出了一种残差-E模块:将普通的Residual Block中conv换成了group conv。论文在这里提出了使用group conv而是不是 depthwise convolution,因为作者认为 group conv比 depthwise convolution可以更好的调整模型的有效性。

10. DRCN
u Deeply-Recursive Convolutional Network for Image Super-Resolution, CVPR2016
DRCN与VDSR都是来自首尔国立大学计算机视觉实验室的工作,两篇论文都发表在CVPR2016上,两种方法的结果非常接近。DRCN第一次将递归神经网络(Recursive Neural Network)结构应用在超分辨率处理中。同时,利用残差学习的思想(文中的跳跃连接(Skip-Connection)),加深了网络结构(16个递归),增加了网络感受野,提升了性能。DRCN网络结构如下图所示。

DRCN输入的是插值后的图像,分为三个模块,第一个是Embedding network,相当于特征提取,第二个是Inference network, 相当于特征的非线性映射,第三个是Reconstruction network,即从特征图像恢复最后的重建结果。其中的Inference network是一个递归网络,即数据循环地通过该层多次。将这个循环进行展开,等效于使用同一组参数的多个串联的卷积层,如下图所示。

其中的H1到HD是D个共享参数的卷积层。DRCN将每一层的卷积结果都通过同一个Reconstruction Net得到一个重建结果,从而共得到D个重建结果,再把它们加权平均得到最终的输出。另外,受到ResNet的启发,DRCN通过skip connection将输入图像与H_d的输出相加后再作为Reconstruction Net的输入,相当于使Inference Net去学习高分辨率图像与低分辨率图像的差,即恢复图像的高频部分。
11. RED
u Image Restoration Using Convolutional Auto-encoders with Symmetric Skip Connections, NIPS2016
这篇文章提出了由对称的卷积层-反卷积层构成的网络结构,作为一个编码-解码框架,可以学习由低质图像到原始图像端到端的映射。网络结构如下图所示。

RED网络的结构是对称的,每个卷积层都有对应的反卷积层。卷积层用来获取图像的抽象内容,反卷积层用来放大特征尺寸并且恢复图像细节。卷积层将输入图像尺寸减小后,再通过反卷积层上采样变大,使得输入输出的尺寸一样。每一组镜像对应的卷积层和反卷积层有着跳线连接结构,将两部分具有同样尺寸的特征(要输入卷积层的特征和对应的反卷积层输出的特征)做相加操作(ResNet那样的操作)后再输入到下一个反卷积层,操作过程如下图所示。

这样的结构能够让反向传播信号能够直接传递到底层,解决了梯度消失问题,同时能将卷积层的细节传递给反卷积层,能够恢复出更干净的图片。可以看到,网络中有一条线是将输入的图像连接到后面与最后的一层反卷积层的输出相加,也是VDSR中用到的方式,因此RED中间的卷积层和反卷积层学习的特征是目标图像和低质图像之间的残差。RED的网络深度为30层,损失函数用的均方误差。
12. DRRN
u Image Super-Resolution via Deep Recursive Residual Network, CVPR2017
DRRN的论文应该是受到了ResNet、VDSR和DRCN的启发,采用了更深的网络结构来获取性能的提升。论文也在文中用图片示例比较了DRRN与上述三个网络的区别,比较示例图如下所示。

DRRN中的每个残差单元都共同拥有一个相同的输入,即递归块中的第一个卷积层的输出。每个残差单元都包含2个卷积层。在一个递归块内,每个残差单元内对应位置相同的卷积层参数都共享(图中DRRN的浅绿色块或浅红色块)。论文列出了ResNet、VDSR、DRCN和DRRN四者的主要策略。ResNet是链模式的局部残差学习。VDSR是全局残差学习。DRCN是全局残差学习+单权重的递归学习+多目标优化。DRRN是多路径模式的局部残差学习+全局残差学习+多权重的递归学习。
文章中比较了不同的递归块和残差单元数量的实验结果,最终选用的是1个递归块和25个残差单元,深度为52层的网络结构。总之,DRRN是通过对之前已有的ResNet等结构进行调整,采取更深的网络结构得到结果的提升。
13. SRDenseNet
u Image Super-Resolution Using Dense Skip Connections, ICCV2017
DenseNet是CVPR2017的best papaer获奖论文。DenseNet在稠密块(dense block)中将每一层的特征都输入给之后的所有层,使所有层的特征都串联(concatenate)起来,而不是像ResNet那样直接相加。这样的结构给整个网络带来了减轻梯度消失问题、加强特征传播、支持特征复用、减少参数数量的优点。一个稠密块的结构如下图所示。

SRDenseNet将稠密块结构应用到了超分辨率问题上,取得了不错的效果。网络结构如下图所示。

SRDenseNet可以分成四个部分。首先是用一个卷积层学习低层的特征,接着用多个稠密块学习高层的特征,然后通过几个反卷积层学到上采样滤波器参数,最后通过一个卷积层生成高分辨率输出。
文章中针对用于最后重建的输入内容不同,设计了三种结构并做了比较。一是反卷积层只输入最顶层稠密块的输出。二是添加了一个跳跃连接,将最底层卷积层的输出特征和最顶层稠密块的输出特征串联起来,再输入反卷积层。三是添加了稠密跳跃连接,是把稠密块看成一个整体,第一个卷积层的输出以及每个稠密块的输出,都输入给在之后的所有稠密块,像是把在反卷积层之前的整个网络也设计成像稠密块那样的结构。由于这样做,所有的特征都串联起来,这样直接输入反卷积层会产生巨大的计算开销,因此添加了一个核大小为1×1的卷积层来减小特征数量,这个卷积层被称为瓶颈层。最后的结论是越复杂的越好。文章中分析的是,受益于低层特征和高层特征的结合,超分辨率重建的性能得到了提升。像第三种结构把所有深度层的特征都串联起来,得到了最佳的结果,说明不同深度层的特征之间包含的信息是互补的。
14. FALSR
u Fast, Accurate and Lightweight Super-Resolution with Neural Architecture Search.
这篇论文基于弹性搜索(宏观+微观)在超分辨率问题上取得了非常好的结果。这种架构搜索在相当的 FLOPS 下生成了多个模型,结果完胜 ECCV 2018 明星模型 CARN。
论文最主要的贡献可以总结为以下四点:
1) 发布了几种快速、准确和轻量级的超分辨率架构和模型,它们与最近的当前最优方法效果相当;
2) 通过在 cell 粒度上结合宏观和微观空间来提升弹性搜索能力;
3) 将超分辨率建模为受限多目标优化问题,并应用混合型控制器来平衡探索(exploration)和利用(exploitation)。
4) 生成高质量模型,其可在单次运行中满足给定约束条件下的各种要求。
三、 超分辨率技术的问题:
1. 图像配准
图像配准对于多帧SR重建的成功至关重要,其中融合了HR图像的互补空间采样。图像配准是一个众所周知的不适定的基本图像处理问题。在SR设置中问题更加困难,其中观察是具有大的混叠伪像的低分辨率图像。随着观察的分辨率下降,标准图像配准算法的性能降低,导致更多的配准误差。这些配准误差会引起的非常严重的伪像。传统的SR重建通常将图像配准视为与HR图像估计不同的过程。因此,恢复的HR图像质量在很大程度上取决于前一步骤的图像配准精度。
目前有的配准方法主要采用贝叶斯方法通过边缘化未知高分辨率图像来估计配准和模糊参数或将HR图像估计与图像配准相关联的随机方法。但是局部运动估计的测量不足使得这些算法容易出错。另一种有希望的SR重建方法是非参数方法,它试图绕过显式运动估计。然而这些方法多有计算量大,匹配率低的问题。并且受到运动模型的限制。
15. 计算效率
限制SR重建的实际应用的另一个难点是由于大量未知数而导致的密集计算,这需要昂贵的矩阵操作。实际应用总是要求SR重建的效率以具有实用性,例如,在视频场景中,人们期望SR重建是实时的。
目前的算法大多数只能有效地处理简单的运动模型,远非真实复杂视频场景中的应用。对计算性能的要求也使得超分辨率重建难以在可移动设备上进行实现。
16. 算法的稳健性和可迁移性
目前的超分辨率重建技术多争对某一特定类型的图片,没有一个通过的模型可以胜任所有类型图像的超分辨率工作。同时由于运动误差、不准确的模糊模型、噪声、运动物体、运动模糊等,传统的SR技术容易受到异常值的影响。这些不准确的模型误差不能像高斯噪声一样被视为具有l2重建残差的通常假设。SR的稳健性是令人感兴趣的,因为不能完美地估计图像劣化模型参数,并且对异常值的敏感性可能导致视觉上令人不安的伪像,这在许多应用中(例如视频标准转换)是不可容忍的。
17. 评价标准缺失
和许多图像任务一样,超分辨率重建的效果很难进行客观的量化。这其实限制了深度学习在超分辨率领域内的应用。因为深度学习的实质其实是损失函数的优化,没有客观有效的评价指标,意味着损失函数难以选取。现存的评价指标如MSE和PSNR,有时甚至会出现评价结果与人眼完全相反的情况。如果能找到一个普适的评价指标,也许超分辨率重建的效果会有跨越式的增长。
四、 实验:
我用目前比较成熟也比较具有代表性的NE方法对一副图像进行了超分辨率复原。采用的原图和降采样图像分为如下:

原图

降采样图
采用的matlab代码见附录。采用的训练集为set5-image_SRF_3,只有5组图像。生成的超分辨率复原图像如下:

可以看到,由于算法比较简单,数据集也很小,超分辨复原的效果非常一般。
五、 Reference:
[1]https://blog.csdn.net/weixin_37583170/article/details/78978482
[2]https://blog.csdn.net/ch07013224/article/details/80324312
[3]https://blog.csdn.net/wenwenbalala/article/details/53033448
[4]http://www.sohu.com/a/157790222_465975
[5]https://blog.csdn.net/shenziheng1/article/details/72818588/
六、 附录
NE算法代码:
%——————————————————————————————————————————————————————————