【含课程pdf & 测验答案】吴恩达-机器学习公开课 学习笔记 Week10 Large Scale Machine Learning
吴恩达-机器学习公开课 学习笔记 Week10 Large Scale Machine Learning
- 10 Large Scale Machine Learning 课程内容
-
- 10-1 Gradient Descent with Large Datasets
-
- Learning With Large Datasets
- Stochastic Gradient Descent
- Mini-Batch Gradient Descent
- Stochastic Gradient Descent Convergence
- 10-2 Advanced Topics
-
- Online Learning
- Map Reduce and Data Parallelism
- 测验 Large Scale Machine Learning
- 课程链接
- 课件
10 Large Scale Machine Learning 课程内容
此文为Week10 中Large Scale Machine Learning的部分。
10-1 Gradient Descent with Large Datasets
Learning With Large Datasets
得到一个高效的机器学习系统的最好的方式之一是用一个低偏差的学习算法,然后用很多数据来训练它。
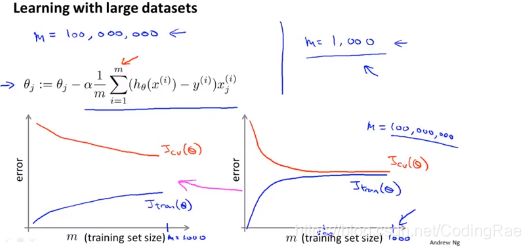
在大规模的机器学习中,我们喜欢找到合理的计算量的方法,或高效率的计算量的方法来处理大的数据集。
Stochastic Gradient Descent
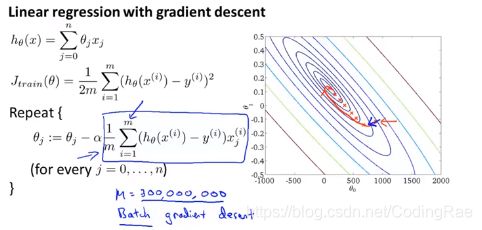
对于很多机器学习算法,包括线性回归、逻辑回归、神经网络等等算法的实现都是通过得出某个代价函数,或者某个最优化的目标来实现的。然后使用梯度下降这样的方法来求得代价函数的最小值。当我们的训练集较大时,梯度下降算法则显得计算量非常大。一种跟普通梯度下降不同的方法,随机梯度下降(stochastic gradient descent) 用这种方法我们可以将算法运用到较大训练集的情况中。
梯度下降算法,在内层循环中你需要用这个式子反复更新参数θ的值。这种梯度下降算法也被称为批量梯度下降(batch gradient descent) ,“批量”就表示我们需要每次都考虑所有的训练样本。
随机梯度下降在每一步迭代中不用考虑全部的训练样本,只需要考虑一个训练样本。
随机梯度下降法的第一步是将所有数据打乱。我说的随机打乱的意思是将所有m个训练样本重新排列,这就是标准的数据预处理过程。
随机梯度下降的第二步是关键:在i等于1到m中进行循环,也就是对所有m个训练样本进行遍历,然后是关于某个单一的训练样本(x(i),y(i))来对参数进行更新。
随机梯度下降的做法实际上就是扫描所有的训练样本。

批量梯度下降的收敛过程会倾向于一条近似的直线,一直找到全局最小值。在随机梯度下降中,每一次迭代都会更快,以某个比较随机、迂回的路径在朝全局最小值逼近。实际上随机梯度下降是在某个靠近全局最小值的区域内徘徊,而不是直接逼近全局最小值并停留在那点。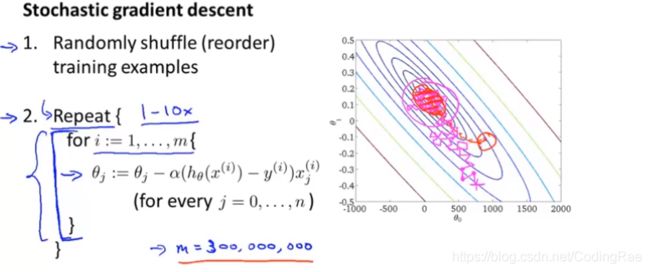
Mini-Batch Gradient Descent
随机梯度下降的另一个变体, 即小批量梯度下降, 他们有时甚至比随机梯度下降更快一点。

在仅仅看了前10个数据, 我们就可以开始取得进展,可以改进参数theta,而不是一定要把整个训练集扫描一遍。 然后 我们可以看下十个数据, 再修改一些参数, 等等。所以, 这就是为什么小批量梯度下降比批量梯度下降更快。

那么, 如何比较小批量梯度下降与随机梯度下降呢?为什么我们要一次看 b 个数据, 而不是每次只看一个数据作为随机梯度下降?
答案是因为***矢量化***。特别是小批量梯度下降可能优于随机梯度下降, 只要你能较好地实行矢量化。用适当的矢量化计算其导数项, 有时可以部分地使用好的数值代数库, 并将 b 个数据的梯度j计算,并行执行。而在随机梯度下降中,如果你一次看的只是一个数据, 那么, 你知道, 一次只是看一个数据,是没有太多的并行化的。至少并行化比较少。
这个算法, 在某种意义上,是有点介于随机梯度下降和批量梯度下降之间。所以我们选择 b 的值, 如果你使用一个好的矢量计算, 有时它可以比随机梯度下降更快, 也比批量梯度下降快。
Stochastic Gradient Descent Convergence
之前批量梯度下降的算法,我们确定梯度下降已经收敛的一个标准方法是画出最优化的代价函数关于迭代次数的变化。但当你的训练集非常大的时候,你不希望老是定时地暂停算法来计算一遍这个求和,因为这个求和计算需要考虑整个的训练集。
而随机梯度下降的算法是你每次只考虑一个样本然后就立刻进步一点点,不需要在算法当中时不时地扫描一遍全部的训练集来计算整个训练集的代价函数。对于随机梯度下降算法,为了检查算法是否收敛:每1000次迭代运算中,我们对最后1000个样本的cost值求平均然后画出来,通过观察这些画出来的图,我们就能检查出随机梯度下降是否在收敛。

- 红色的曲线代表随机梯度下降使用一个更小的学习速率。使用一个更小的学习速率,最终的振荡就会更小。
- 增大平均的训练样本数,得到的关于学习算法表现的反馈就显得有一些“延迟”
- 代价函数就没有在减小,也就是说算法没有很好地学习。用更大量的样本进行平均 ,需要调整学习速率或者改变特征变量或者改变其他的什么。
- 实际上是在上升,这是一个很明显的信号,告诉你算法正在发散。用一个更小一点的学习速率α。
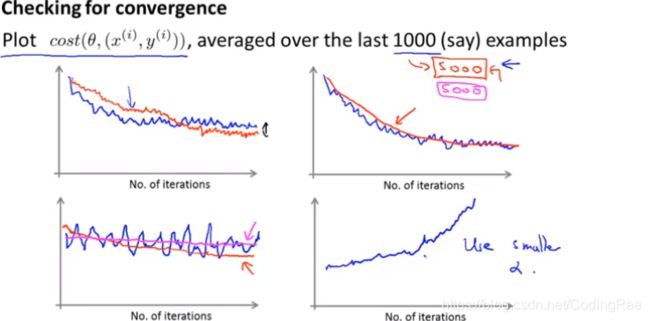
最终得到的参数,实际上只是接近全局最小值,而不是真正的全局最小值。在大多数随机梯度下降法的典型应用中,学习速率α一般是保持不变的。
如果你想让随机梯度下降确实收敛到全局最小值,你可以随时间的变化减小学习速率α的值。一种典型的方法来设置α的值是让α等于某个常数1 除以 迭代次数加某个常数2, 迭代次数指的是你运行随机梯度下降的迭代次数。
最后会把问题落实到把时间花在确定常数1和常数2上,这让算法显得更繁琐。
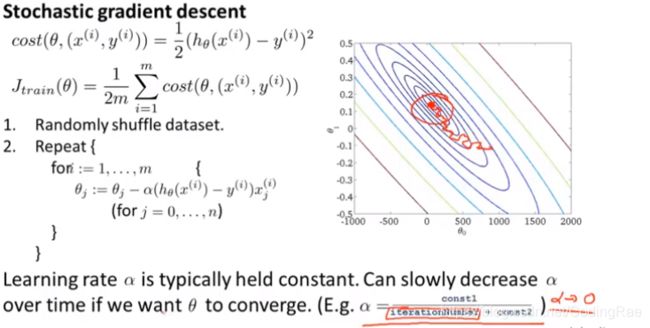
小批量梯度下降近似地监测出随机梯度下降算法在最优化代价函数中的表现。这种方法不需要定时地扫描整个训练集来算出整个样本集的代价函数,而是只需要每次对最后1000个或者多少个样本,求一下平均值。应用这种方法,你既可以保证随机梯度下降法正在正常运转和收敛,也可以用它来调整学习速率α的大小。
10-2 Advanced Topics
Online Learning
在线学习机制:可以模型化问题。在拥有连续一波数据或连续的数据流涌进来,而我们又需要一个算法来从中学习的时候来模型化问题。
假定你有一个提供运输服务的公司,用户们来向你询问把包裹从A地 运到B地的服务,然后你的网站开出运输包裹的服务价格。假定我们想要一个学习算法来帮助我们优化我们想给用户开出的价格,

如果你的用户群变化了,那么参数θ的变化与更新,会逐渐调适到你最新的用户群所应该体现出来的参数。
当一个用户键入一个搜索命令,我们会想要找到一个合适的十部不同手机的列表来提供给用户,这个返回的列表是对类似这样的用户搜索条目最佳的回应。

实际上,如果你有 一个协作过滤系统,可以给你更多的特征,这些特征可以整合到逻辑回归的分类器从而可以尝试着预测对于你可能推荐给用户的不同产品的点击率。可以使用一个在线学习算法来连续的学习从这些用户不断产生的数据中来学习。
我们所使用的这个算法与随机梯度下降算法非常类似,唯一的区别的是我们不会使用一个固定的数据集,我们会做的是获取一个用户样本,从那个样本中学习,然后丢弃那个样本并继续下去。而且如果你对某一种应用有一个连续的数据流,这样的算法可能会非常值得考虑。 在线学习的一个优点就是如果你有一个变化的用户群,又或者你在尝试预测的事情在缓慢变化,就像你的用户的品味在缓慢变化,这个在线学习算法可以慢慢地调试你所学习到的假设,将其调节更新到最新的用户行为。
Map Reduce and Data Parallelism
有些机器学习问太大以至于不可能只在一台计算机上运行。进行大规模机器学习的另一种方法称为映射约减 (map reduce) 方法,相比于随机梯度下降方法,映射化简方法能够处理更大规模的问题。
我们有一些训练样本,如果我们希望使用4台计算机并行的运行机器学习算法,那么我们将训练样本等分尽量均匀地分成4份。
然后,我们将这4个训练样本的子集送给4台不同的计算机,每一台计算机对四分之一的 训练数据进行求和运算。
最后,这4个求和结果被送到一台中心计算服务器负责对结果进行汇总。
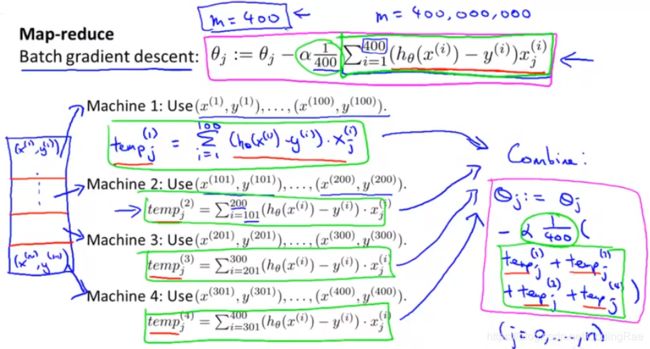
如果没有网络延时也不考虑通过网络来回传输数据所消耗的时间,那么你可能可以得到4倍的加速。
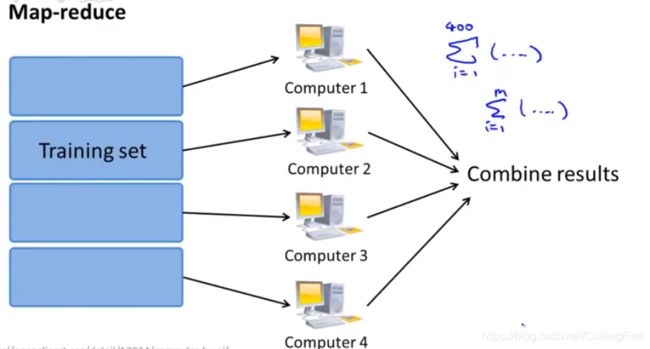
如果你打算将映射化简技术用于加速某个机器学习算法,那么你需要问自己一个很关键的问题,你的机器学习算法是否可以表示为训练样本的某种求和。因此,只要算法的主要计算部分可以表示为训练样本的求和,那么你可以考虑使用映射化简技术来将你的算法扩展到非常大规模的数据上。
更广义的来说,通过将机器学习算法表示为求和的形式,或者是训练数据的函数求和形式,你就可以运用映射化简技术来将算法并行化,这样就可以处理大规模数据了。

在多台计算机上实现并行计算也许是一个计算机集群,也许是一个数据中心中的多台计算机。但实际上,有时即使我们只有一台计算机也可以运用这种技术。如果你有一个很大的训练样本,那么你可以使用一台四核的计算机,即使在这样一台计算机上你依然可以 将训练样本分成几份,不需要担心网络延时问题,因为所有的通讯所有的来回数据传输都发生在一台计算机上。
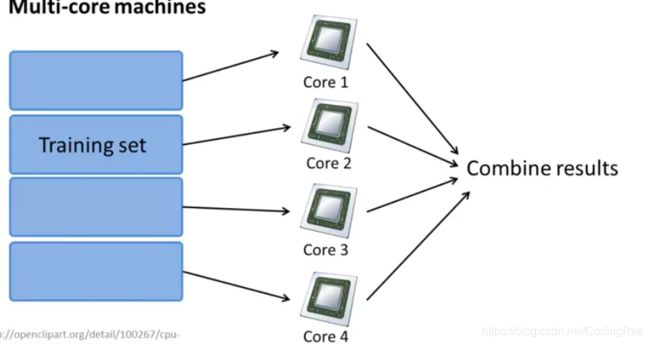
如果你有一台多核计算机并且使用了某个线性代数函数库,有时你只需要按照标准的矢量化方式实现机器学习算法,而不用管多核并行的问题。
测验 Large Scale Machine Learning





课程链接
https://www.coursera.org/learn/machine-learning/home/week/10
课件
课件链接