纽约大学深度学习PyTorch课程笔记(自用)Week5
纽约大学深度学习PyTorch课程笔记Week5
- Week 5
-
- 5.1 优化工具1
-
- 5.1.1 梯度下降
- 5.1.2 随机梯度下降
-
- 小批次处理
- 5.1.3 动量
-
- 直观
- 实用指南
- 为什么动量有用?
-
- 加速
- 噪声平滑
- 5.2 优化方法
-
- 5.2.1 自适应优化算法
-
- 均方根优化(RMSprop)
- 带动量学习率自适应 (ADAM)
- 实用建议
- 5.2.2 归一化层
-
- 归一化操作
- 为什么归一化有效?
- 5.2.3 优化的死亡
-
- MRI重建
- 加速MRI
- 压缩感知
- 谁需要优化?
- 5.3 了解卷积和自动微分引擎
-
- 5.3.1 了解 1 维的卷积
- 5.3.2 Pytorch 中核的维度与输出的宽度
-
- 一维卷积
- 二维卷积
- 5.3.3 自动梯度如何运作?
-
- 从基础到更刺激的
- 5.3.4 自定梯度
Week 5
5.1 优化工具1
5.1.1 梯度下降
我们以所有方法中最基本,最差的(原因后文叙述)的梯度下降法来开始我们对优化方法的学习。
问题:
min w f ( w ) \min_w f(w) wminf(w)
迭代式:
w k + 1 = w k − γ k ∇ f ( w k ) w_{k+1} = w_k - \gamma_k \nabla f(w_k) wk+1=wk−γk∇f(wk)
其中,
- w k + 1 w_{k+1} wk+1 是第 k k k次迭代后的更新值,
- w k w_k wk 是第 k k k次迭代前的初始值,
- γ k \gamma_k γk 是步长,
- ∇ f ( w k ) \nabla f(w_k) ∇f(wk)是 f f f的梯度。
这里假设函数 f f f 是连续且可导的。 我们的目标是找到优化方程的最低点(谷)。但是,实际到最低谷的方法是未知的。 我们只能局部地看, 因此梯度的负方向就是我们知道的最好的信息。 向那个方法移动一小步将向最小值靠近。我们每移动一小步便重新计算梯度并且再向其相反方向移动一小步,直到我们到达最低谷。因此本质上来讲,梯度下降法所作的一切就是沿着下降地最急剧的方向(负梯度)。
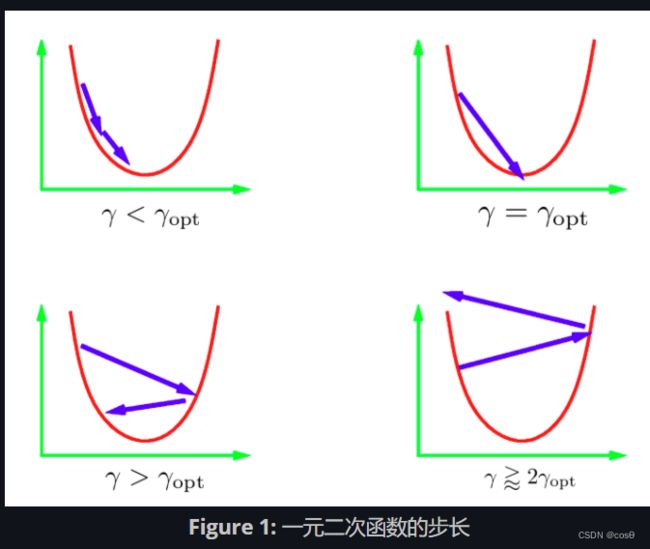
迭代更新式中的参数 γ \gamma γ 叫做步长/学习率。总的来说,我们不知道最佳的步长值; 所以我们必须尝试不同的值。 标准的方式是尝试一串呈对数比例的值然后使用最好的值。 这里可能会出现一些不同的情况。 上面这张图描绘了一元二次函数的情况。 如果学习率太小,那么我们将稳定地向最小值前进。 但是,这可能会比理想状态更费时。想得到一个步长值可以直接得到最小值是非常困难的(或者不可能的)。 一个比较理想的想法是得到一个比理想步长稍大一点的步长。 实际中,这样收敛最快。但是如果我们使用过大的学习率,那么将会迭代至离最小值很远导致不收敛。 在实际中,我们想使用稍小于不收敛的学习率。
5.1.2 随机梯度下降
在随机梯度下降中,我们用梯度向量的随机估计替换实际的梯度向量。 专门针对神经网络,随机估计是指单个数据点(单个实例)的损耗梯度。
令 f i f_i fi表示 第 i i i个实例的网络损失。
f i ( w ) = l ( x i , y i , w ) f_i(w) = l(x_i, y_i, w) fi(w)=l(xi,yi,w)
最终我们想最小化的函数是 f f f,表示所有实例的总损失。
min w f ( w ) = 1 n ∑ i n f i ( w ) \min_w f(w) = \frac{1}{n}\sum_i^n f_i(w) wminf(w)=n1i∑nfi(w)
在SGD中,我们根据 f i f_i fi 上的梯度(而不是总损失 f f f上的梯度)更新权重。
w k + 1 = w k − γ k ∇ f i ( w k ) (i随机选择统一) \begin{aligned} w_{k+1} &= w_k - \gamma_k \nabla f_i(w_k) & \quad\text{(i随机选择统一)} \end{aligned} wk+1=wk−γk∇fi(wk)(i随机选择统一)
如果 i i i 是随机选择的, 那么 f i f_i fi 是一个有噪声但无偏的 f f f的估计量, E \mathbb{E} E为expectation,其表达式为:
E [ ∇ f i ( w k ) ] = ∇ f ( w k ) \mathbb{E}[\nabla f_i(w_k)] = \nabla f(w_k) E[∇fi(wk)]=∇f(wk)
结果,SGD的预期第 k k k步与完全梯度下降的第 k k k步相同:
E [ w k + 1 ] = w k − γ k E [ ∇ f i ( w k ) ] = w k − γ k ∇ f ( w k ) \mathbb{E}[w_{k+1}] = w_k - \gamma_k \mathbb{E}[\nabla f_i(w_k)] = w_k - \gamma_k \nabla f(w_k) E[wk+1]=wk−γkE[∇fi(wk)]=wk−γk∇f(wk)
因此,任何SGD更新都与预期的批次更新相同。 但是,SGD不仅具有噪声的更快的梯度下降。 除了更快之外,SGD还可以比全批次梯度下降获得更好的结果。 SGD中的噪声可以帮助我们避免浅的局部最小值,并找到更好的(较深)最小值。 这种现象称为 退火.

总的来说,随机梯度下降的优点如下:
-
跨实例有很多冗余信息,SGD可以防止很多此类冗余计算。
-
在初期,与梯度中的信息相比,噪声较小。 因此,SGD的一步和GD的一步实际上一样好 .
-
退火:SGD更新中的噪声可阻止收敛到坏的(浅)局部最小值。
-
随机梯度下降计算的成本大大降低(因为您无需遍历所有数据点)。

小批次处理
在小批次处理中,我们考虑多个随机选择的实例上的损失,而不是仅计算一个实例上的损失。 这样可以减少步进更新中的噪声。
w k + 1 = w k − γ k 1 ∣ B i ∣ ∑ j ∈ B i ∇ f j ( w k ) w_{k+1} = w_k - \gamma_k \frac{1}{|B_i|} \sum_{j \in B_i}\nabla f_j(w_k) wk+1=wk−γk∣Bi∣1j∈Bi∑∇fj(wk)
根据Yann,mini-batch的大小通常是等于数据集中类的数量。
通常,我们可以通过使用小批处理而不是单个实例来更好地利用我们的硬件。 例如,当我们使用单实例训练时,GPU使用率很低。 分布式网络训练技术将大型微型批处理在群集的机器之间进行分割,然后汇总生成的梯度。 Facebook最近使用分布式训练在一个小时内对ImageNet数据上的网络进行了训练。
重要的是要注意,梯度下降绝对不能用于全尺寸批次。 如果您想以完整的批次大小进行训练,请使用一种称为LBFGS的优化技术。 PyTorch和SciPy都提供了该技术的实现。
5.1.3 动量
在动量中, 我们有两个迭代( p p p 和 w w w),而不仅仅是一个。 更新式如下:
p k + 1 = β k ^ p k + ∇ f i ( w k ) w k + 1 = w k − γ k p k + 1 \begin{aligned} p_{k+1} &= \hat{\beta_k}p_k + \nabla f_i(w_k) \\ w_{k+1} &= w_k - \gamma_kp_{k+1} \\ \end{aligned} pk+1wk+1=βk^pk+∇fi(wk)=wk−γkpk+1
p p p称作 SGD 动量。在每个更新步骤中,我们将动量的旧值减去系数 β \beta β(0到1之间的值),然后将其添加到动量的旧值。 可以将 p p p视为梯度的平均值。 最后,我们向新动量 p p p的方向移动 w w w。
替代形式:随机重球法
w k + 1 = w k − γ k ∇ f i ( w k ) + β k ( w k − w k − 1 ) 0 ≤ β < 1 \begin{aligned} w_{k+1} &= w_k - \gamma_k\nabla f_i(w_k) + \beta_k(w_k - w_{k-1}) & 0 \leq \beta < 1 \end{aligned} wk+1=wk−γk∇fi(wk)+βk(wk−wk−1)0≤β<1
该形式在数学上与先前的形式等价。 在这里,下一步是上一步的方向 ( w k − w k − 1 ) (w_k-w_ {k-1}) (wk−wk−1)和新的负梯度的组合。
直观
SGD动量类似于物理学中的动量概念。优化过程就像一个沉重的球滚下山坡,动量使球保持与已经移动的方向相同的方向,梯度可以认为是沿其他方向推动球的力。

source: distill.pub
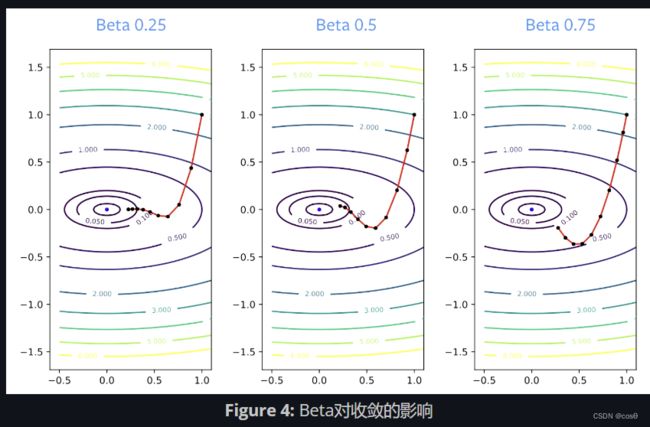
动量并没有使行进方向发生巨大变化(如左图所示),而是产生了适度的变化。 动量可减轻仅使用SGD时常见的振荡。
β \beta β参数称为阻尼因子。 β \beta β必须大于零,因为如果它等于零,那么你只是在进行梯度下降; 它也必须小于1,否则一切都会崩溃。 β \beta β的值较小会导致方向更改更快。 对于较大的值,转向需要更长的时间。
实用指南
动量必须总是与随机梯度下降一起使用,效果比纯SGD好。 β \beta β = 0.9或者0.99 基本上效果会很好。
当增加动量参数时。通常需要减小步长参数以保持收敛。 如果 β \beta β从0.9变为0.99,则学习率必须降低10倍。
为什么动量有用?
加速
以下是涅斯捷罗夫动量的更新规则。
p k + 1 = β k ^ p k + ∇ f i ( w k ) w k + 1 = w k − γ k ( ∇ f i ( w k ) + β k ^ p k + 1 ) p_{k+1} = \hat{\beta_k}p_k + \nabla f_i(w_k) \\ w_{k+1} = w_k - \gamma_k(\nabla f_i(w_k) +\hat{\beta_k}p_{k+1}) pk+1=βk^pk+∇fi(wk)wk+1=wk−γk(∇fi(wk)+βk^pk+1)
使用涅斯捷罗夫动量,如果你非常仔细地选择常数,则可以加快收敛速度。但这仅适用于凸问题,不适用于神经网络。
许多人说,正常的动量也是一种加速的方法。 但实际上,它仅对二次方加速。 此外,由于SGD带有噪音,加速不适用于SGD,因此不适用于SGD。 因此,尽管Momentum SGD有一些加速作用,但仅凭它并不能很好地解释该技术的高性能。

在这片文章里用伪代码的形式阐述了SGD,momentum,RMSprop以及ADAM方法
噪声平滑
可能一个更实际和更可能动量效果很好的原因是噪声平滑。
动量平均梯度。 这是我们用于每个步骤更新的渐变的平均值。
从理论上讲,为了使SGD能够正常工作,我们应该对所有步骤进行平均。
w ˉ k = 1 K ∑ k = 1 K w k \bar w_k = \frac{1}{K} \sum_{k=1}^K w_k wˉk=K1k=1∑Kwk
SGD+动量的优点在于,不再需要进行平均。 动量为优化过程增加了平滑度,从而使每次更新都很好地接近了解决方案。 使用SGD,你需要平均一堆更新,然后朝这个方向前进一步。
加速和噪声平滑都有助于提高动量性能。
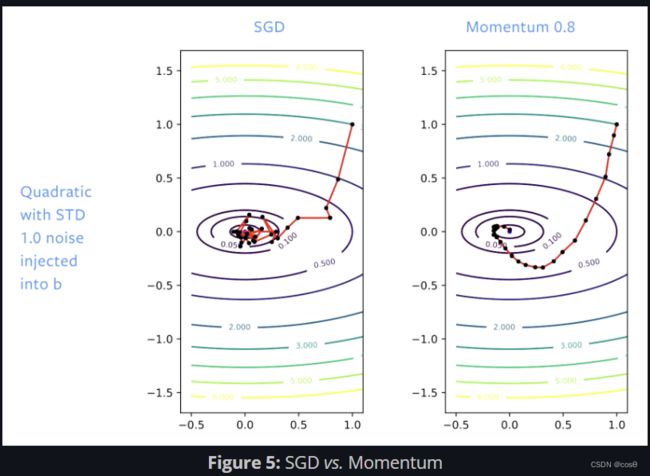
使用SGD,我们最初在解决方案方面取得了良好的进展,但是当我们到达函数最低区域(谷底)时,我们会在此反弹。 如果我们调整学习率,我们的反弹速度将会变慢。 有了动量,我们就使步伐变得平稳,以至于没有反弹发生。
5.2 优化方法
5.2.1 自适应优化算法
具有动量的随机梯度下降法(SGD)是当前针对许多ML问题的最先进的优化方法。但是还有其他一些方法,这些方法通常统称为自适应优化方法。这些方法近年来不断创新,而且这些方法对于一些条件不足的问题(特别是SGD不适用的情况下)特别有用。
在随机梯度下降法的公式中,网络中的每个权重均使用相同的学习率(全局 γ \gamma γ)进行更新。与此不同的是,对于自适应的方法,我们针对每个权重分别调整学习率。为了达到这个目的,我们使用从梯度获得的关于每个权重的信息。
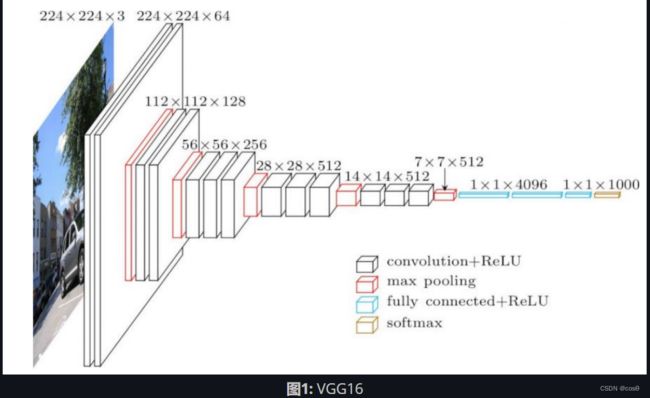
在实践中经常使用的网络在其不同部分具有不同的结构。例如,CNN的前几层部分可能神经图像比较大但是通道不是很多,而在网络的后期,我们可能得到小的神经图像,但是卷积的核具有大量的通道。这两种操作非常不同,因此,对于网络的前面部分而言效果很好的学习率可能对网络的后部分效果不好。这意味着逐层自适应去调整学习率可能会很有效果。

网络最后部分的权重(下图1中的4096)直接决定了网络的输出,换言之对输出有非常大的影响。因此,我们需要为这些权重降低学习率。相反,较早层的单个权重将对输出产生较小的影响,尤其是在网络权重值是随机初始化的时候。
均方根优化(RMSprop)
均方根优化(RMSprop)的关键思想是通过均方根对梯度进行归一化。
在下面的等式中,对梯度进行平方意味着对梯度向量的每个元素分别进行平方。
v t + 1 = α v t + ( 1 − α ) ∇ f i ( w t ) 2 w t + 1 = w t − γ ∇ f i ( w t ) v t + 1 + ϵ \begin{aligned} v_{t+1} &= {\alpha}v_t + (1 - \alpha) \nabla f_i(w_t)^2 \\ w_{t+1} &= w_t - \gamma \frac {\nabla f_i(w_t)}{ \sqrt{v_{t+1}} + \epsilon} \end{aligned} vt+1wt+1=αvt+(1−α)∇fi(wt)2=wt−γvt+1+ϵ∇fi(wt)
其中 γ \gamma γ是整体学习率, ϵ \epsilon ϵ 是接近于machine ϵ \epsilon ϵ的一个非常小的值(大约介于 1 0 − 7 10 ^{-7} 10−7至 1 0 − 8 10^{-8} 10−8之间)(这是为了避免除以零而报错), v t + 1 v_{t + 1} vt+1是梯度的二阶矩估计。

我们通过指数移动平均值(这是计算随时间变化的数量平均值的标准方法)来更新嘈杂(noisy)的 v v v值。我们需要对新值提供更大的权重,因为它们会提供更多信息。这里的方法以指数形式降低旧值的权重。 计算 v v v的时候旧的值在每个步骤中都乘上 α \alpha α来指数降低权重,该 α \alpha α常数在0到1之间变化。这会让旧值递减,直到它们对梯度二阶矩的指数移动平均值贡献非常低为止。
这个方法会不断计算梯度二阶矩的指数移动平均值,因为是非中心的二阶矩,因此我们不用在计算的时候减去梯度的均值。梯度的二阶矩用来对梯度进行逐个归一,这意味着梯度的每个元素都将除以二阶矩的平方根。如果梯度的期望值较小,则此过程类似于将梯度除以标准差。
在分母中使用小的 ϵ \epsilon ϵ不会导致大的偏移,因为当 v v v非常小时,意味着整个梯度也非常小。
带动量学习率自适应 (ADAM)
ADAM,或称带动量学习率自适应(RMSprop加动量),是一种更常用的方法。动量更新将基于指数移动平均值,而当我们处理 β \beta β时,我们不需要更改学习率。就像在RMSprop中一样,我们在这里取平方梯度的指数移动平均值。
m t + 1 = β m t + ( 1 − β ) ∇ f i ( w t ) v t + 1 = α v t + ( 1 − α ) ∇ f i ( w t ) 2 w t + 1 = w t − γ m t v t + 1 + ϵ \begin{aligned} m_{t+1} &= {\beta}m_t + (1 - \beta) \nabla f_i(w_t) \\ v_{t+1} &= {\alpha}v_t + (1 - \alpha) \nabla f_i(w_t)^2 \\ w_{t+1} &= w_t - \gamma \frac {m_{t}}{ \sqrt{v_{t+1}} + \epsilon} \end{aligned} mt+1vt+1wt+1=βmt+(1−β)∇fi(wt)=αvt+(1−α)∇fi(wt)2=wt−γvt+1+ϵmt
其中 m t + 1 m_{t+1} mt+1是动量的指数移动平均值。
这里没有加上用于在早期迭代期间保持移动平均值无偏的偏差校正。

实用建议
在训练神经网络时,SGD通常在训练过程开始时梯度会传播错方向,而RMSprop会朝正确的方向走。但是,RMSprop就像SGD一样会受到噪声的影响,因此一旦接近局部最小化时,RMSprop就会在最佳位置附近反复变化。就像我们为SGD增加动力一样,加上动力时候ADAM也有类似的效果改进。这是对解决方案的一个很好的估计,因此相对于RMSprop,通常建议使用ADAM。
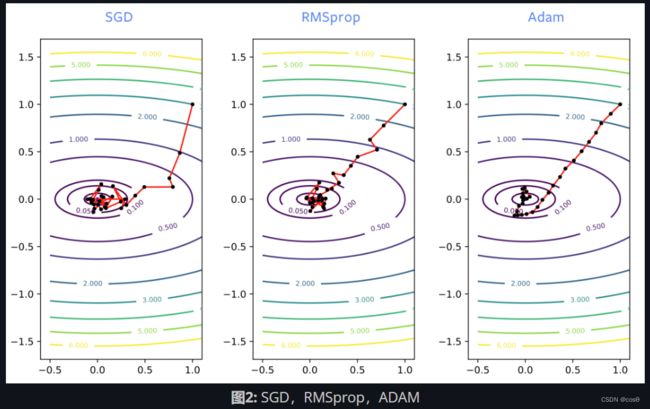
ADAM对于训练某些使用语言模型的网络是必需的。为了优化神经网络,通常首选带动量的SGD或ADAM。但是,ADAM的理论在论文中知之甚少,它也有几个缺点:
- 可以证明,在非常简单的测试问题上,该方法无法收敛。
- ADAM已知会产生泛化错误。如果对神经网络进行了训练,并且使其对训练数据的损失为零,那么它将不会对之前从未见过的其他数据点产生零损失。与使用SGD时相比,特别是在图像问题上,泛化误差更为常见。其中原因可能包括它找到的是最接近的局部最小值,ADAM或其结构中的噪声较小,等等。
- 使用ADAM,我们需要维护3个缓冲区,而SGD需要2个缓冲区。除非我们训练一个大小为几GB的模型,否则这并不重要。而在模型很大这种情况下,这些缓冲区可能无法容纳在内存中。
- 需要调试2个动量参数而不是1。
5.2.2 归一化层
归一化层不是改善优化算法,而是改善网络结构本身。它们是现有层之间的附加层。目的是提高优化和泛化性能。
在神经网络中,我们通常将线性运算与非线性运算交替出现。非线性运算也称为激活函数,例如ReLU。我们可以将归一化层放置在线性层之前或激活函数之后。最常见的做法是将它们放在线性层和激活函数之间,如下图所示。
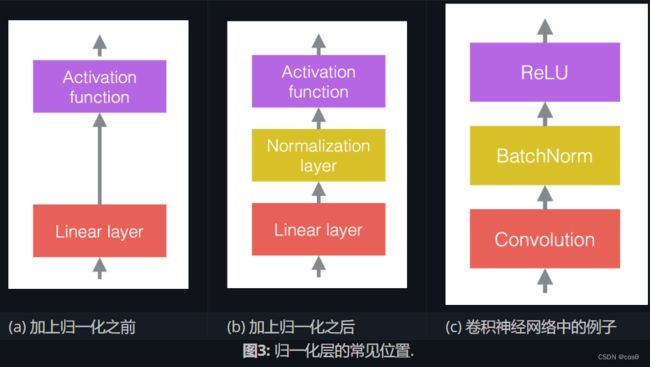
在图3(c)中,卷积是线性层,然后是批处理归一化,然后是ReLU。
值得注意的是,归一化层会影响经过的数据,但是它们不会改变网络的功能,因为在适当配置权重的情况下,未归一化的网络仍可以提供与归一化网络相同的输出。
归一化操作
这是归一化的通用运算:
y = a σ ( x − μ ) + b y = \frac{a}{\sigma}(x - \mu) + b y=σa(x−μ)+b
其中 x x x是输入向量, y y y是输出向量, μ \mu μ是 x x x均值的估计, σ \sigma σ是 x x x的标准差(std)的估计, a a a是可学习的比例因子, b b b是可学习的偏差项,使得数据可以具有非零的均值。

如果没有可学习的参数 a a a和 b b b,则输出向量 y y y的分布将具有固定的均值0和标准差1。比例因子 a a a和偏差项 b b b维持网络的表示能力,即,输出值仍可以在任何特定范围内。请注意, a a a和 b b b不会逆转规范化,因为它们是可学习的参数,并且比 μ \mu μ和 σ \sigma σ稳定得多。
基于如何选择样本进行归一化,有几种方法可以对输入向量进行归一化。图4列出了4种不同的归一化方法,假设一个批量的 N N N个图片,高度为 H H H宽度为 W W W,并且有 C C C个通道:
- 批量归一化:规范化仅应用于输入的一个通道。这是最先提出的也是最著名的方法。请阅读如何训练ResNet7:批量归一化以获取更多信息。
- 层归一化:在所有通道的一张图像中应用归一化。
- 实例归一化:仅对一幅图像和一个通道应用标准化。
- 组归一化:归一化应用于一个图像,但跨多个通道。例如,通道0至9是一个组,然后通道10至19是另一个组,依此类推。实际上,组的大小几乎总是32。这是Aaron Defazio推荐的方法,因为它在实践中具有良好的性能,并且与SGD不冲突。
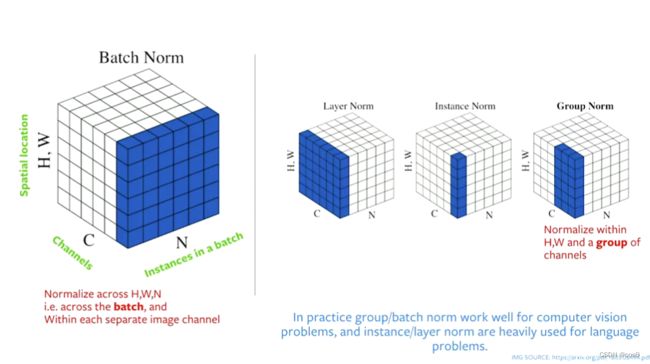
实际应用中,批量归一化和组归一化适用于计算机视觉问题,而层规范和实例规范则广泛用于语言问题。
为什么归一化有效?

重要的是通过均值和标准差的计算以及归一化的应用来进行反向传播:否则,网络训练会有所不同。反向传播计算相当困难且容易出错,但是PyTorch能够为我们自动计算,这非常有帮助。下面列出了PyTorch中的两个归一化层类:
torch.nn.BatchNorm2d(num_features, ...)
torch.nn.GroupNorm(num_groups, num_channels, ...)
批量归一化是最早开发的方法,并且是最广为人知的方法。但是,Aaron Defazio建议改为使用组归一化。它更稳定,理论上更简单,并且通常效果更好。组大小32是一个很好的默认值。
请注意,对于批归一化和实例归一化,使用的均值/标准差在训练后是固定的,而不是每次评估网络时都重新计算,这是因为需要多个训练样本来进行归一化。对于组规范和分层规范而言,这不是必需的,因为它们的归一化仅针对一个训练样本。
5.2.3 优化的死亡
有时,我们可以闯入一个我们一无所知的领域,并改善他们当前实现事物的方式。一个例子是在磁共振成像(MRI)领域中使用深层神经网络来加速MRI图像重建。
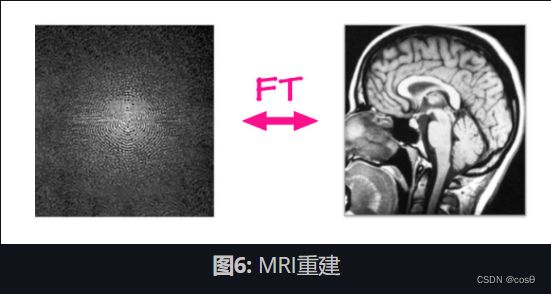
MRI重建
在传统的MRI重建问题中,原始数据是从MRI机器上获取的,并使用简单的框架/算法从中重建图像。 MRI机器一次(每隔几毫秒)捕获二维傅立叶域中的数据,一次一行或一列。该原始输入由一个频率和一个相位通道组成,该值表示具有特定频率和相位的正弦波的大小。简而言之,可以将其视为具有真实和虚构通道的复杂值图像。如果我们在此输入上应用傅立叶逆变换,即将所有这些正弦波按其值加权后相加,就可以得到原始的解剖图像。
当前存在从傅里叶域到图像域的线性映射,并且无论图像有多大,它都是非常高效的,实际上要花费毫秒。但是问题是,我们可以更快地做到吗?
加速MRI
加速MRI是需要解决的新问题,所谓加速是指使MRI重建过程更快。我们希望更快地运行机器,并且仍然能够产生相同质量的图像。我们可以做到这一点的一种方法,并且到目前为止,最成功的方法是不捕获MRI扫描中的所有列。我们可以随机跳过一些列,尽管在实践中捕获中间列很有用,因为它们在整个图像中包含很多信息,但是在它们之外,我们只是随机捕获。问题在于我们不能再使用线性映射来重建图像。图7中最右边的图像显示了应用于子采样傅立叶空间的线性映射的输出。显然,这种方法不会给我们带来非常有用的输出,并且还有做一些更加智能化的提升空间。

压缩感知
长期以来,理论数学上最大的突破之一是压缩感测。 Candes等人的论文显示,从理论上讲,我们可以从二次采样的傅立叶域图像中获得完美的重构。 换句话说,当我们试图重建的信号是稀疏的或稀疏的结构时,则可以通过较少的测量来完美地重建它。但是,要使此方法有效,有一些实际的要求-我们不需要随机采样,而是需要不连贯地采样-尽管实际上,人们最终只是随机采样。另外,对整列或半列进行采样需要花费相同的时间,因此在实践中我们也对整列进行采样。
另一个条件是我们需要在图像中具有“稀疏度”,稀疏度意味着图像中存在很多零或黑色像素。如果我们进行波长分解,则可以稀疏地表示原始输入,但是即使分解也可以使我们得到近似稀疏的图像,而不是精确稀疏的图像。因此,如图8所示,这种方法给我们提供了很好但不是完美的重建。但是,如果输入在波长域中非常稀疏,那么我们肯定会获得完美的图像。

压缩感测基于优化理论。我们获得此重构的方法是解决一个最小优化问题,该问题具有一个附加的正则项:
x ^ = arg min x 1 2 ∥ M ( F ( x ) ) − y ∥ 2 + λ T V ( x ) \hat{x} = \arg\min_x \frac{1}{2} \Vert M (\mathcal{F}(x)) - y \Vert^2 + \lambda TV(x) x^=argxmin21∥M(F(x))−y∥2+λTV(x)
其中 M M M是将未采样条目归零的掩码函数, F \mathcal{F} F是傅里叶变换, y y y是观察到的傅里叶域数据, λ \lambda λ是正则化惩罚强度,并且 V V V是正则化函数。
必须针对MRI扫描中的每个时间步长或每个“切片”解决优化问题,这通常需要比扫描本身更长的时间。这给了我们找到更好的东西的另一个理由。
谁需要优化?
为什么不使用大型神经网络直接生成所需的解决方案,而不是在每个步骤都解决一点优化问题?我们的希望是,我们可以训练出足够复杂的神经网络,使其本质上一步解决优化问题,并产生与在每个时间步解决优化问题所获得的解决方案一样好的输出。
x ^ = B ( y ) \hat{x} = B(y) x^=B(y)
其中 B B B是我们的深度学习模型,而 y y y是观察到的傅立叶域数据。
15年前,这种方法很困难-但是如今,这种方法更容易实现。图9显示了针对该问题的深度学习方法的结果,我们可以看到输出比压缩感测方法好得多,并且看起来与实际扫描非常相似。
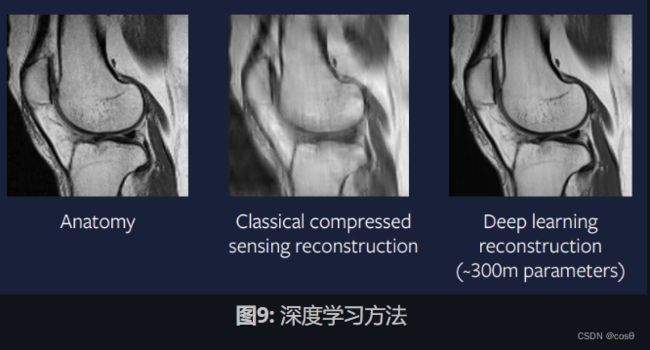
用于生成此重构的模型使用ADAM优化器,组规范归一化层和基于U-Net的卷积神经网络。这种方法非常接近于实际应用,并且希望在几年后的临床实践中会看到这些加速的MRI扫描。
5.3 了解卷积和自动微分引擎
5.3.1 了解 1 维的卷积
这里我们要讨论卷积,因为我们想探索卷积的稀疏性、平稳性与组合性。
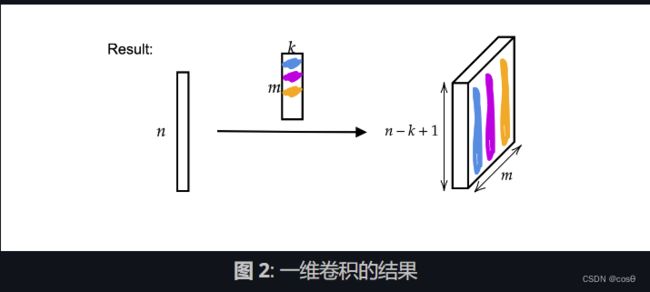
我们使用的不是上周的 A A A矩阵,而是将其宽度改变为核的大小 k k k。因此,矩阵的每一列都是一个核。我们可以将核堆叠并滑动来使用(见图 1)。 如此我们会得到 m m m个高度为 n − k + 1 n-k+1 n−k+1 的层。

输出是 m m m(厚度) 个尺寸为 n − k + 1 n−k+1 n−k+1 的向量。
一个单独的输入向量可以视作一个单声道信号。
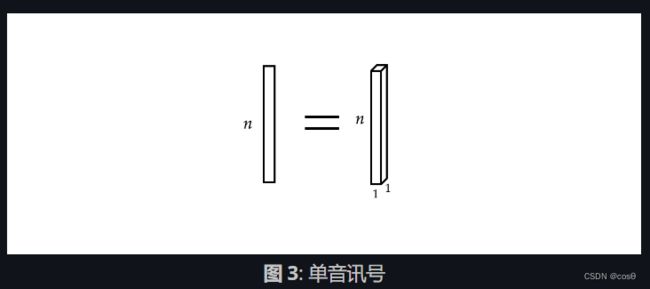
现在,输入 x x x是一个映射:
x : Ω → R c x:\Omega\rightarrow\mathbb{R}^{c} x:Ω→Rc
其中 Ω = { 1 , 2 , 3 , ⋯ } ⊂ N 1 \Omega = \lbrace 1, 2, 3, \cdots \rbrace \subset \mathbb{N}^1 Ω={1,2,3,⋯}⊂N1(因为这是个一维信号;它的定义域是一维的)且此情况中通道数 c c c是 1。 当 c = 2 c=2 c=2 这就成为了立体声的信号。
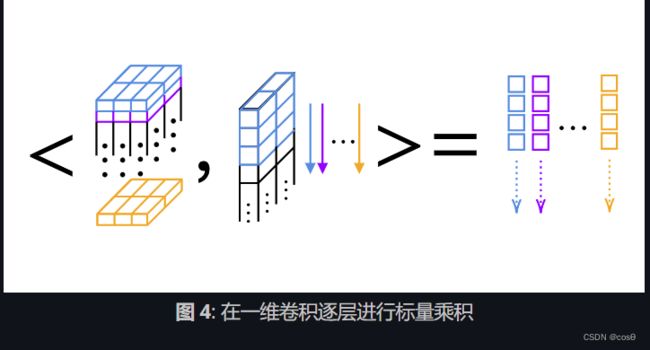
对于一维的卷积,我们可以逐个核计算标量乘积(如图 4)。
手写笔记理解:
5.3.2 Pytorch 中核的维度与输出的宽度
技巧:我们可以在 Ipython 中使用 问号 来取得函数的文件。例如:
Init signature:
nn.Conv1d(
in_channels, # number of channels in the input image
out_channels, # number of channels produced by the convolution
kernel_size, # size of the convolving kernel
stride=1, # stride of the convolution
padding=0, # zero-padding added to both sides of the input
dilation=1, # spacing between kernel elements
groups=1, # nb of blocked connections from input to output
bias=True, # if `True`, adds a learnable bias to the output
padding_mode='zeros', # accepted values `zeros` and `circular`
)
一维卷积
我们用大小为 3,步幅1的一维卷积使通道数量从 2 个(立体声信号)变为 16 个(16 个核)。于是我们有 16 个厚度为 2 长度为 3 的核(有多少output channel就表明卷积层有多少个kernel)。假设输入信号是一个大小为1 通道数为 2 个且有 64个样本的批次。生成的输出层会有 1 个信号,具有16个通道与且长度为62 (=64-3+1)。并且,如果我们输出偏置的大小,会是 16 因为我们每个权重都有一个偏置。
conv = nn.Conv1d(2, 16, 3) # 2 channels (stereo signal), 16 kernels of size 3
conv.weight.size() # output: torch.Size([16, 2, 3]),有16个权重,每个权重厚度为2,长度为3
conv.bias.size() # output: torch.Size([16])
x = torch.rand(1, 2, 64) # batch of size 1, 2 channels, 64 samples
conv(x).size() # output: torch.Size([1, 16, 62])
conv = nn.Conv1d(2, 16, 5) # 2 channels, 16 kernels of size 5
conv(x).size() # output: torch.Size([1, 16, 60])
二维卷积
首先我们定义输入信号有一个样本,20个通道(假设我们使用的是高光谱影像)高64宽128。二维的卷积有 20个来自输入的通道,与 16 16 16个 3 × 5 3\times5 3×5 大小的卷积核。卷积之后,输出的信号有一个样本, 16 16 16个通道,高 62 ( = 64 − 3 + 1 ) 62 (=64-3+1) 62(=64−3+1) 且宽 124 ( = 128 − 5 + 1 ) 124(=128-5+1) 124(=128−5+1)。
x = torch.rand(1, 20, 64, 128) # 1 sample, 20 channels, height 64, and width 128
conv = nn.Conv2d(20, 16, (3, 5)) # 20 channels, 16 kernels, kernel size is 3 x 5
conv.weight.size() # output: torch.Size([16, 20, 3, 5])
conv(x).size() # output: torch.Size([1, 16, 62, 124])
如果我们想输出相同的维度,可以采用填充。以上方的代码为基础,我们可以于卷积函数添加新的参数:stride=1 和 padding=(1, 2),表示 y y y 方向填充 1(上下都分别填充一个), x x x 方向填充 2。如此,输出的信号就与输入信号有相同尺寸。储存二维卷积使用的卷积核共需要 4 4 4 个维度。
# 20 channels, 16 kernels of size 3 x 5, stride is 1, padding of 1 and 2
conv = nn.Conv2d(20, 16, (3, 5), 1, (1, 2))
conv(x).size() # output: torch.Size([1, 16, 64, 128])
5.3.3 自动梯度如何运作?
在这个部份,我们将使用 torch 来记录所有在张量上进行的运算,以计算偏导数。
- 建立一个 2 × 2 2\times2 2×2 且能累积梯度的张量 x \boldsymbol{x} x;
- 从 x \boldsymbol{x} x 的所有元素减去2,取得 y \boldsymbol{y} y;(若我们印出 y.grad_fn 会得到
代表 y y y 是从减法的模组 x − 2 \boldsymbol{x}-2 x−2 产生。我们也可以用 y.grad_fn.next_functions[0][0].variable 导出原始的张量。) - 再度进行运算: z = y × y × 3 \boldsymbol{z} = y \times y\times 3 z=y×y×3
- 计算 z \boldsymbol{z} z的均值。
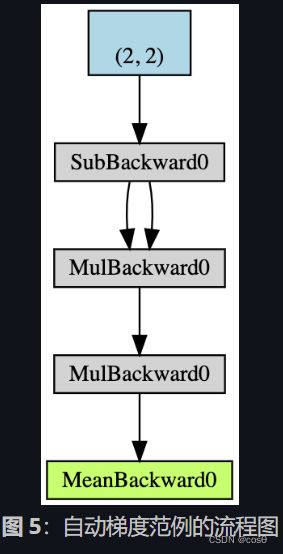
反向传播用于计算梯度。在这个例子里,反向传播的过程可视为计算梯度 d a d x \frac{d\boldsymbol{a}}{d\boldsymbol{x}} dxda 。如果手算 d a d x \frac{d\boldsymbol{a}}{d\boldsymbol{x}} dxda为验证,我们会发现执行a.backward() 给我们的值等同于我们自己计算的x.grad。
这里是手动进行反向传播的过程:
a = 1 4 ( z 1 + z 2 + z 3 + z 4 ) z i = 3 y i 2 = 3 ( x i − 2 ) 2 d a d x i = 1 4 × 3 × 2 ( x i − 2 ) = 3 2 x i − 3 x = ( 1 2 3 4 ) ( d a d x i ) ⊤ = ( 1.5 − 3 3 − 3 4.5 − 3 6 − 3 ) = ( − 1.5 0 1.5 3 ) \begin{aligned} a &= \frac{1}{4} (z_1 + z_2 + z_3 + z_4) \\ z_i &= 3y_i^2 = 3(x_i-2)^2 \\ \frac{da}{dx_i} &= \frac{1}{4}\times3\times2(x_i-2) = \frac{3}{2}x_i-3 \\ x &= \begin{pmatrix} 1&2\\3&4\end{pmatrix} \\ \left(\frac{da}{dx_i}\right)^\top &= \begin{pmatrix} 1.5-3&3-3\\[2mm]4.5-3&6-3\end{pmatrix}=\begin{pmatrix} -1.5&0\\[2mm]1.5&3\end{pmatrix} \end{aligned} azidxidax(dxida)⊤=41(z1+z2+z3+z4)=3yi2=3(xi−2)2=41×3×2(xi−2)=23xi−3=(1324)=(1.5−34.5−33−36−3)=(−1.51.503)
在 PyTorch 中,偏导数总是有与原数据相同的形状(因此使用转置保证可以与原数据形状相同)。不过雅可比矩阵其实应该是转置的( ( ( d a d x i ) ⊤ ) ⊤ ((\frac{da}{dx_i})^\top)^\top ((dxida)⊤)⊤即 d a d x i \frac{da}{dx_i} dxida)。
从基础到更刺激的
考虑我们有 1 × 3 1\times3 1×3的向量 x x x,指定 y y y 为 x x x的两倍并持续加倍直到范数不小于 1000。由于我们给 x x x的随机性,我们不能直接知道这个过程终止前经过多少次迭代。
x = torch.randn(3, requires_grad=True)
y = x * 2
i = 0
while y.data.norm() < 1000:
y = y * 2
i += 1
然而,靠着梯度就能简单的推测出来
gradients = torch.FloatTensor([0.1, 1.0, 0.0001])
y.backward(gradients)
print(x.grad)
tensor([1.0240e+02, 1.0240e+03, 1.0240e-01])
print(i)
9#因为前面先对x乘了一个2,再进入的循环,所以实际是2^(1+9) = 1024
在推断的时候,我们可以如下地使用 requires_grad=True 来标记想要记录梯度的张量。如果我们省去 x x x 或 w w w 的 requires_grad=True,将造成执行时错误,由于没有梯度积累于 x x x 或 w w w。
# Both x and w that allows gradient accumulation
x = torch.arange(1., n + 1, requires_grad=True)
w = torch.ones(n, requires_grad=True)
z = w @ x
z.backward()
print(x.grad, w.grad, sep='\n')
我们也可利用with torch.no_grad()来避免梯度积累:
x = torch.arange(1., n + 1)
w = torch.ones(n, requires_grad=True)
# All torch tensors will not have gradient accumulation
with torch.no_grad():
z = w @ x
try:
z.backward() # PyTorch will throw an error here, since z has no grad accum.
except RuntimeError as e:
print('RuntimeError!!! >:[')
print(e)
5.3.4 自定梯度
此外,除了基础的数值运算,我们可以自定义模组、函数,并将其加入神经网络的图中。Jupyter Notebook 在这里。
为此,我们要继承 torch.autograd.Function 并覆盖 forward() 和 backward() 函数。举例而言,假如我们想训练网络,我们就必须取得前向传播,了解输入对输出的偏导数,如此我们才能在代码中的任何部份使用这个模组。接者,藉由反向传播(链式法则),我们可以在一连串的运算中的任何部份插入这个模组,因为我们知道了输入对输出的偏导数。
在这个案例,有三个 自定模组 在 notebook 中,分别是 add,split 和 max。例如自定的加法模组:
# Custom addition module
class MyAdd(torch.autograd.Function):
@staticmethod
def forward(ctx, x1, x2):
# ctx is a context where we can save
# computations for backward.
ctx.save_for_backward(x1, x2)
return x1 + x2
@staticmethod
def backward(ctx, grad_output):
x1, x2 = ctx.saved_tensors
grad_x1 = grad_output * torch.ones_like(x1)
grad_x2 = grad_output * torch.ones_like(x2)
# need to return grads in order
# of inputs to forward (excluding ctx)
return grad_x1, grad_x2
如果要将两数相加并输出,我们必须像这样覆盖 forward 函数。当我们进行反向传播,梯度会复制到两边,所以我们以复制来重写 backward 函数。
至于 split 和 max,参阅 notebook,看看我们如何覆盖 forward、backward 函数。当我们从一个东西 分割,计算梯度时要相加。对 argmax,因为它选择了最大值的索引,那个有着最大值的索引的梯度就是 1 而其他是 0。记住,根据不同的自定模组,我们必须覆盖其前向传播与反向传播计算。