pandas 数据合并 pd.join() pd.merge() pd.crosstab() pd.concat()
文章目录
-
-
- pd.join()
- pd.merge()
-
- pd.merge(left, right, how='inner', left_on=None, right_on=None...)形式
-
- 按照一列进行合并
- how 指定合并方式
- suffixes 为重复列名自定义后缀
- 按照二列进行合并
- left_on right_on
- left_index right_index
- df1.merge(df2...)的形式
-
- 内连接
- 外连接
- 左连接
- 右连接
- pd.crosstab()
- pd.concat()
-
-
- 2张表竖着合并 默认是外连接
- 2张表横着合并
- 2张表竖着合并 内连接
- 2张表竖着合并 按照指定的列索引
- 2张表竖着合并 重新设定key
-
-
pd.join()
默认情况下是把行索引相同的数据合并到一起
会求笛卡尔集
import pandas as pd
import numpy as np
df1 = pd.DataFrame(np.ones((2, 4)), index=["A", "A"], columns=list("abcd"))
df2 = pd.DataFrame(np.zeros((3, 3)), index=["A", "B", "C"], columns=list("xyz"))
print(df1)
print("*" * 20)
print(df2)
print("*" * 20)
print(df1.join(df2))
print("*" * 20)
print(df2.join(df1))

pd.merge()
这里将给出两大类merge方式 即pd.merge()和df1.merge(df2)
如果不指定合并方式how,默认的合并方式为inner ,那么就会求笛卡尔集
pd.merge(left, right, how=‘inner’, left_on=None, right_on=None…)形式
按照一列进行合并
按照指定的列把数据按照一定的方式合并到一起
import pandas as pd
import numpy as np
df1 = pd.DataFrame({'id':[1,10,1024],'name':['po','alisa','Michael'],'sex':['male','female','male']})
df2 = pd.DataFrame({'id':[1,10,1025],'name':['softpo','alisa','Michael'],'age':[20,30,40]})
display(df1,df2)

只按照id这一列进行合并,但是df1 df2还都有相同的列name,所以结果中出现了name_x,name_y来区分两列
on指定按照哪一列进行合并
会求笛卡尔集
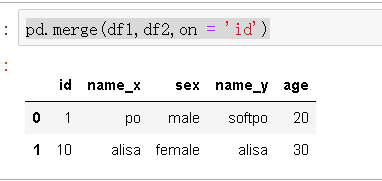
how 指定合并方式

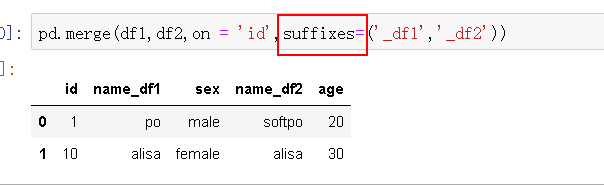
suffixes 为重复列名自定义后缀
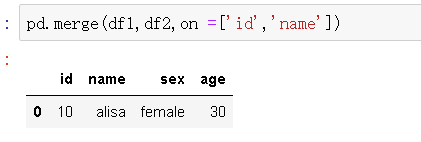
按照二列进行合并
on指定按照哪一列进行合并
left_on right_on
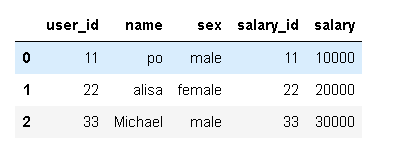
假设数据库有2张表,user 和user的薪水,现在要将这两张表合并到一块
df1 = pd.DataFrame({'user_id':[11,22,33],'name':['po','alisa','Michael'],'sex':['male','female','male']})
df2 = pd.DataFrame({'salary_id':[11,22,33],'salary':[10000,20000,30000]})
display(df1,df2)

会求笛卡尔集
pd.merge(df1,df2,left_on='user_id',right_on='salary_id')
left_index right_index
按照行索引进行合并
import pandas as pd
import numpy as np
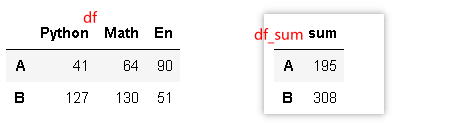
df = pd.DataFrame(np.random.randint(0,150,size = (2,3)),columns=['Python','Math','En'],index = list('AB'))
df
df_sum = pd.DataFrame(df.sum(axis = 1),columns=['sum'])
df_sum
pd.merge(df,df_sum,left_index=True,right_index=True)
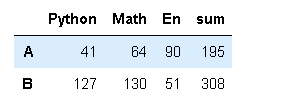
df1.merge(df2…)的形式
内连接
import pandas as pd
import numpy as np
df1 = pd.DataFrame(np.ones((2, 4)), index=["A", "B"], columns=list("abcd"))
df3 = pd.DataFrame(np.arange(9).reshape(3, 3), columns=list("fax"))
print(df1)
print("*" * 20)
print(df3)
print("*" * 20)
# on="a" 按照a这一列进行合并
print(df1.merge(df3, on="a")) # 第一种写法
# df1.merge(df3, on="a") # 第二种写法
# 以上的这两种写法等价
# 但是使用join()方法时不等价

外连接
import pandas as pd
import numpy as np
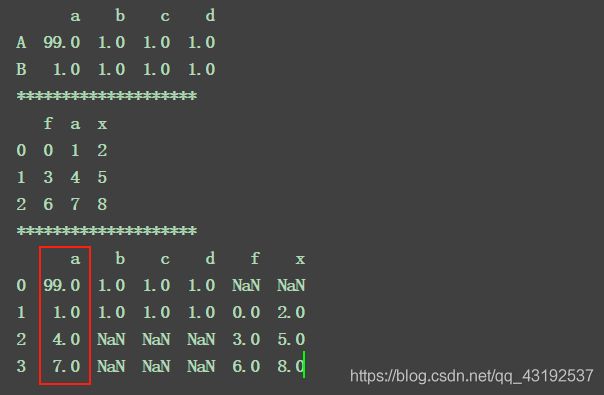
df1 = pd.DataFrame(np.ones((2, 4)), index=["A", "B"], columns=list("abcd"))
df3 = pd.DataFrame(np.arange(9).reshape(3, 3), columns=list("fax"))
df1.loc["A", "a"] = 99
print(df1)
print("*" * 20)
print(df3)
print("*" * 20)
# on是按照哪一列进行合并 how合并方式
print(df1.merge(df3, on="a", how="outer"))
左连接
import pandas as pd
import numpy as np
df1 = pd.DataFrame(np.ones((2, 4)), index=["A", "B"], columns=list("abcd"))
df3 = pd.DataFrame(np.arange(9).reshape(3, 3), columns=list("fax"))
df1.loc['A','a'] = 99
print(df1)
print("*" * 20)
print(df3)
print("*" * 20)
# on是按照哪一列进行合并 how合并方式
print(df1.merge(df3, on="a", how="left"))

右连接
import pandas as pd
import numpy as np
df1 = pd.DataFrame(np.ones((2, 4)), index=["A", "B"], columns=list("abcd"))
df3 = pd.DataFrame(np.arange(9).reshape(3, 3), columns=list("fax"))
df1.loc['A','a'] = 99
print(df1)
print("*" * 20)
print(df3)
print("*" * 20)
print(df1.merge(df3, on="a", how="right"))

pd.crosstab()
数据下载链接
现有2张数据库表,user.csv 和 product.csv,统计一下每个人买的所有物品的数目

# -*- codeing = utf-8 -*-
import pandas as pd
from sklearn.decomposition import PCA
# 读取2张表的数据
user = pd.read_csv('data/user.csv')
product = pd.read_csv('data/product.csv')
# 合并2张表到一张表
# _mg = pd.merge(user, product, on=['user_id', 'user_id']) # 合并数据方法1
_mg = user.merge(product, on='user_id') # 合并数据方法2
# 交叉表
# 行:是user_id 列:是把product_name这一列中的每一个字段进行去重统计后的
cro = pd.crosstab(_mg['user_name'], _mg['product_name'])
print(cro)
输出
product_name 华为A 华为b 小米A 小米B 苹果a
user_name
A1 1 1 1 0 1
A2 0 1 1 0 1
A3 3 0 0 0 0
A4 0 0 0 1 0
pd.concat()
df1 = DataFrame(np.random.randint(0,150,size = (5,3)),columns=['Python','Math','En'],index = list('ABCDE'))
df2 = DataFrame(np.random.randint(0,150,size = (5,3)),columns=['Python','Math','En'],index=list('HIJKL'))
display(df1,df2)

-
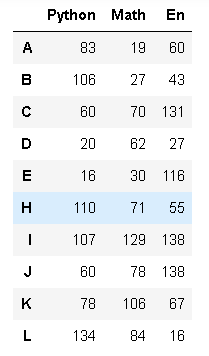
2张表竖着合并 默认是外连接
不管是横着,还是竖着合并,行 列 索引都可以重复
pd.concat([df1,df2])
-
2张表横着合并
不管是横着,还是竖着合并,行 列 索引都可以重复
df4 = pd.concat([df1,df2],axis = 1)
display(df4)

-
2张表竖着合并 内连接
df5 = DataFrame(np.random.randint(0,150,size = (5,3)),columns=['Python','Math','Java'],index = list('ABCGH'))
display(df1, df5)
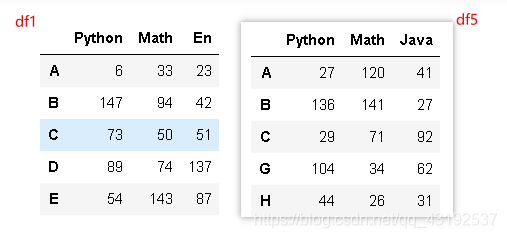
pd.concat([df1,df5],join = 'inner')
-
2张表竖着合并 按照指定的列索引
pd.concat([df1,df5],join_axes=[df1.columns])

-
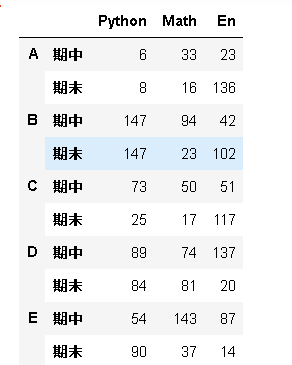
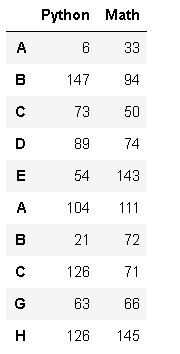
2张表竖着合并 重新设定key
假设df1是老王的期中测试,df6是期末测试的成绩

df7 = pd.concat([df1,df6],keys = ['期中','期末'])
display(df7)

df7.unstack(level=0).stack()