Keras深度神经网络入门
参考书籍和博客进行的实验总结,如发现错误,请大家斧正,谢谢阅读!
目录
一、初步了解Keras框架
二、上手Keras(这里是以Python版TensorFlow作为后端堆栈的开发深度学习模型)
1、输入数据
2、神经元
3、激活函数
4、模型
5、层
6、损失函数
7、优化器
8、评价指标
9、配置模型
10、训练模型
11、模型评估
一、初步了解Keras框架
1、搭建神经网络
1)明确输入层,隐含层,输出层隐含各自的层数及其神经元数量。
2)明确各层对应需要使用的激活函数。
3)明确1)和2)之后就可以开始搭建模型,模型有多少层,1)中已经明确了,然后决定选用哪种类型的层去搭建这个模型即可。(这里主要用全连接层)。
4)对上面搭建好的模型进行编译,其中编译一般需用到三个参数,损失函数,优化器,和评价指标的选择,Keras中有特有的语句实现,就直接引用即可。
from keras.model import Sequential
from keras.layers import Dense,Activation
import numpy as np
#准备数据,例:假设随机创建1000组数据作为训练集,500组数据作为测试集,并且设置其标签。这里标签只有两类
train_data,test_data=np.random.random((1000,3)),np.random.random((500,3))
labels = np.random.randint(2,size=(1000,1))
#搭建神经网络
model=Sequential()
model.add(Dense(5,input_dim=3,activation=”relu”))
model.add(Dense(4,activation=”relu”))
model.add(Dense(1,activation=”sigmoid”))
#训练模型与预测
modle.comlipe(optimizer='adam',loss='binary_arossentropy',metrics=['accuracy'])
model.fit(train_data,labels,batch_size=32,epochs=10)
predictions = model.predict(test_data)二、上手Keras(这里是以Python版TensorFlow作为后端堆栈的开发深度学习模型)
1、输入数据
深度学习模型只接受数值数据,如果数据集中出现分类数据如性别(男,女),此时需要将其转换成独热编码变量,即可表示男为0,女为1。反之亦可。
图像数据也同样是需要转换成n维张量(这里把张量理解成简单的n维矩阵即可),不过本文不是从图像的深度学习模型展开,这里就是解释一下模型需要输入的数据类型而已。
2、神经元
神经元是从上一层中的一个或多个神经元接受一个或多个数据。
3、激活函数
这里激活函数就提醒一点,如果激活函数是一个线性函数(基本上不激活),则该函数的导数为0。为什么导数为0就不可以呢?因为使用方向传播算法进行训练有助于想神经网络提供有关错误分类信息的反馈,从而帮助神经元通过使用激活函数的倒数来调整其权重的。如果该导数为0,则神经网络失去了这种学习能力。所以,简单起见,激活函数必须是非线性的(至少在所有隐含层中)。
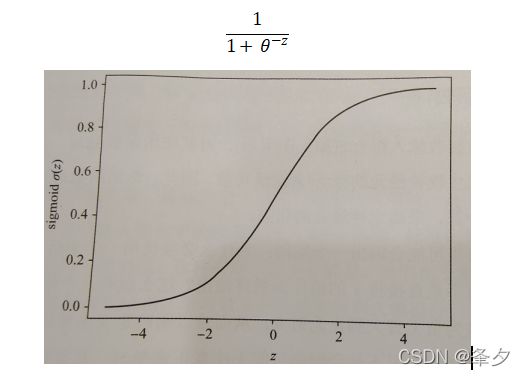
常见的激活函数有sigmoid函数和ReLU函数
Sigmoid函数定义为:
ReLU函数(Rectified Linear Unit,修正线性单元)
该函数看起来像线性函数,但是ReLU函数确实是一种非线性函数(这里不展开说明),而且它作为激活函数非常有效。当z为负时,直接输出0作为结果,从而不激活神经元。
ReLU函数还有带泄露的ReLU,带参数的ReLU和ELU函数;还有Swish函数,GELU函数等激活函数这里不展开写,可能会后续单独更一篇关于激活函数的文章。
4、模型
深度神经网络的整体结构是通过使用Keras中的对象构建的。这提供了一种通过逐层添加神经网络层来构建堆栈的简便方法。最简便的方法就是使用序列模型sequential model。
例如,创建一个简单的序列模型,有一个层,层后面紧接激活函数(ReLU),而且该层有10个神经元,从5个神经元处接受输入。
from keras.model import Sequential
from keras.layers import Dense,Activation
#创建一个简单的序列模型,该层有十个神经元,从15个神经元处接受输入,并由ReLU激活函数激活
model=Sequential()
model.add(Dense(10,input_dim=15))
model.add(Activation('relu'))5、层
深度神经网络中的“层”可定义为一组神经元或一个分层网络结构中的逻辑上分离的组。
1、核心层
全连接层(稠密层)
将本层中的每个神经元与前一层中的每个神经元两两连接。例如,如果第1层有3个神经元而第2层有2个神经元(则第2层是全连接层),即第1层与第2层之间的连接总数就是6。
用Keras实现代码具体如下:
Keras.layers.Dense(units,activation=None,use_bias=True,......)
可自行百度查询所有默认参数,通常,一般只需要用到单元数量(units)和激活类型(activation)等参数,其余参数可能在处理某些特定应用案例时时很重要。
实例应用:
假设有1个隐含层和输出层的神经网络,第一层有5个神经元,预期输入有10个特征,最后一层是输出,它只有一个神经元。
代码如下:
2、Dropout层,嵌入层,卷积层,递归层,归一化层...等。以后可能会更新吧。。。。。
6、损失函数
损失函数是帮助神经网络了解它是否正确方向上学习的度量标准。它可直观类比成考试中获得的分数。其目的主要是度量相对于目标的损失。损失越小越好,如果它通过一些参数的更新重复练习以改进后的模型并使损失变小,则其改变是帮助到神经网络正确地学习的,反之,改变则是没有意义和帮助的。
常见的损失函数在Keras框架中对应的函数如下(以下列出的函数是用于回归用例的场景下的,即最终预测的会是连续数字):
1)均方差
keras.losses.mean_squared_error(y,y_pred)
2)平均绝对误差
keras.losses.mean_absolute_error(y,y_pred)
3)平均绝对百分比误差MAPE
keras.losses.mean_absolute_percentage_error(y,y_pred)
4)均方对数误差 MSLE
keras.losses.mean_squared_logarithmic_error(y,y_pred)
7、优化器
优化器函数是一种数学算法,它使用微积分中的导数,偏导数和链式法则,通过对神经元的权重进行微小的改变来了解神经网络的损失函数将发生变化的程度。
其实就是利用优化器函数(算法)对其权重参数进行小的改变,然后达到降低损失函数来改进最终的预测结果。
Keras中可用的优化算法
1、随机梯度下降(SGD)
该算法的权重更新公式,用一下简单方式表达:权重(new)=权重-学习率*损失
假设学习率=0.01,则Keras中的表达为:
keras.optimizers.SGD(lr=0.01,momentum=0.0,decay=0.0,nesterov=False)
2、Adam(目前深度学习中最热门,应用最广泛的优化器)
它本身定义了损失梯度动量和方差,并利用组合效应来更新权重参数。其也可简化公式表达:权重 = 权重-(动量和方差组合)
keras.optimizers.Adam(lr=0.001,beta_1=0.9,beta_2=0.999,epsilon=None,decay=0.0,amsgrad=False)其中beta_1和beta_2分别用于计算动量和方差。一般默认值是很有效的,可以应用于大多数场景了。
对于大多数应用案例来说,Adam优化器已经足够用了,初学者主要还是搞懂Adam优化器的使用。
8、评价指标
可以引用keras中的评价指标,一些可用的评价指标如下:
二元准确率: keras.metrics.binary_accuracy
分类准确率: keras.metrics.catogrical_accuracy
稀疏分类准确率: keras.metrics.sparse_categorical_accuracy
当然,也可以自定义模型的评价指标函数。
9、配置模型
上面的一些讲解最终就是为搭建模型铺垫的,接下来就是检验上面学习成果了。将前面的所有组件编排组合起来就是一个搭建好的网络了。设计完神经网络后,用Keras提供complie命令进行编译。
实例:下面就搭建一个神经网络,其中具有两个隐含层,两个隐含层中的神经元个数分别为32,16,并均有一个ReLU的激活函数,最终的输出是基于Sigmoid激活函数的二分类数值输出。使用的是Adam优化器编译,并用二元交叉熵作为损失函数,准确度作为验证的评价指标。
代码如下:
from keras.model import Sequential
from keras.layers import Dense,Activation
model=Sequential()
model.add(Dense(32,input_dim=15,activation=”relu”))
model.add(Dense(16,activation=”relu”))
model.add(Dense(1,activation=”sigmoid”))
modle.comlipe(optimizer=’Adam’,loss=’binary_arossentropy’,metrics=[‘accuracy’])10、训练模型
Keras提供了一个fit函数用于根据给定的训练数据训练模型对象,例:
'''x_train,y_train为训练集
batch_size=64 为模型每次批量接收和处理32个样本
epochs=3 为历元数为5
x_val,y_val为验证集'''
model.fit(x_train,y_train,batch_size=32,epochs=5,validation_data=(x_val,y_val))
11、模型评估
evaluate(x=None,y=None,batch_size=None,verbose=1,sample_weight=None,steps=None)
#x为测试数据,y为测试标签
print(model.evaluate(x_test,y_test))
#模型预测
pred=model.predict(x_test)
参考文献:
「印」乔.穆拉伊尔(Jojo Moolayil)著 敖富江 周云彦 杜静 译