深度学习(8)——权重衰退
前言
上一章讲了过拟合的概念,过拟合实际上就是用过于复杂的模型来训练结构比较简单的数据。会出现训练出来的模型在训练数据上的误差非常低,但是在测试数据或者验证数据上的误差非常高的情况,这就使得这个模型变得毫无意义。出现过拟合现象的原因有很多,还有当训练数据很少的情况下,模型对于小样本数据的拟合还是很容易的,但是一旦碰到新的数据,模型可能就认不出它了,就会导致测试误差很大。
我们可以通过减少神经网络的神经元个数,也就是让权重的数量少一点来使得模型不那么复杂来解决过拟合。
我们也可以通过让权重的取值范围小一点来解决,这可以使得我们的模型波动没有那么大,也可以有效的降低模型复杂度,使得模型不会过拟合,那么这个方法就是权重衰退。
权重衰退原理
本文不会介绍特别多的原理,只是简单介绍。
在之前的博客中的所有深度学习算法实际上都是通过对损失函数作梯度下降来求得最优的权重值,那么我们要使得权重值的范围缩小,那么就要在梯度下降上做点处理了。
简单回顾一下:损失函数简写 L(w,b)
随机梯度下降后使得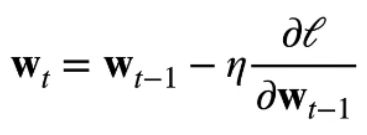
然后我们对损失函数做一些改变,给他加上一个L2正则式子
这里的λ是一个超参数,用来限制w最终取值范围的。对这个新的损失函数求导就会变成这样:
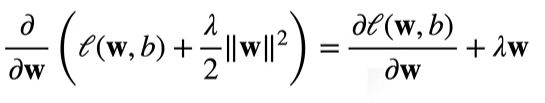
代入权重值更新的公式中: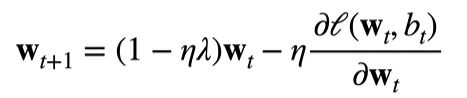
可以看到和原来的权重更新的公式相比,第二项一样,第一项多减了ηλWt,这就使得权重值范围缩小了。这个ηλ通常小于1。
例子
检验一下权重衰退能不能解决过拟合的问题。
导包
%matplotlib inline
import torch
from torch import nn
from d2l import torch as d2l
人工数据集生成
生成一个这样的数据集:
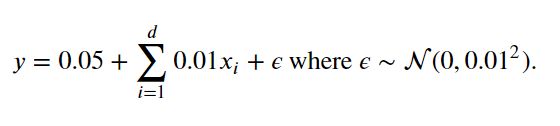
这个数据集的训练数据20个,权重有200个,相当于输入层200个神经元,这个模型十分复杂,而且训练数据非常小,这对于数据的过拟合非常有利。
n_train, n_test, num_inputs, batch_size = 20, 100, 200, 5
true_w, true_b = torch.ones((num_inputs, 1)) * 0.01, 0.05
train_data = d2l.synthetic_data(true_w, true_b, n_train)
train_iter = d2l.load_array(train_data, batch_size)
test_data = d2l.synthetic_data(true_w, true_b, n_test)
test_iter = d2l.load_array(test_data, batch_size, is_train=False)
初始化模型参数
w取正态分布,b取0.
def init_params():
w = torch.normal(0, 1, size=(num_inputs, 1), requires_grad=True)
b = torch.zeros(1, requires_grad=True)
return [w, b]
定义L2惩罚函数
这个就是定义损失函数后面加出来的那项的。
def l2_penalty(w):
return torch.sum(w.pow(2)) / 2
就是一个L2正则表达式,除2方便求导
训练模型
这个lambda x就是一种函数简写,相当于X是传入net函数的参数。
def train(lambd):
w, b = init_params()
net, loss = lambda X: d2l.linreg(X, w, b), d2l.squared_loss
num_epochs, lr = 100, 0.003
animator = d2l.Animator(xlabel='epochs', ylabel='loss', yscale='log',
xlim=[5, num_epochs], legend=['train', 'test'])
for epoch in range(num_epochs):
for X, y in train_iter:
# 增加了L2范数惩罚项,
# 广播机制使l2_penalty(w)成为一个长度为batch_size的向量
l = loss(net(X), y) + lambd * l2_penalty(w)
l.sum().backward()
d2l.sgd([w, b], lr, batch_size)
if (epoch + 1) % 5 == 0:
animator.add(epoch + 1, (d2l.evaluate_loss(net, train_iter, loss),
d2l.evaluate_loss(net, test_iter, loss)))
print('w的L2范数是:', torch.norm(w).item())
效果
λ=0时,等同没有权重衰退情况

过拟合明显吧,这模型对测试数据完全没用。
λ=3

有效果了吧。
简洁实现权重衰退
这里的重点是在SGD这个方法里定义了weight_decay,这就是让输入lambda的,我们的框架还是挺全能的吧,但了解一下原理也没坏处,知道一下这个参数干嘛用的,该怎么设置最优。
def train_concise(wd):
net = nn.Sequential(nn.Linear(num_inputs, 1))
for param in net.parameters():
param.data.normal_()
loss = nn.MSELoss(reduction='none')
num_epochs, lr = 100, 0.003
# 偏置参数没有衰减
trainer = torch.optim.SGD([
{"params":net[0].weight,'weight_decay': wd},
{"params":net[0].bias}], lr=lr)
animator = d2l.Animator(xlabel='epochs', ylabel='loss', yscale='log',
xlim=[5, num_epochs], legend=['train', 'test'])
for epoch in range(num_epochs):
for X, y in train_iter:
trainer.zero_grad()
l = loss(net(X), y)
l.sum().backward()
trainer.step()
if (epoch + 1) % 5 == 0:
animator.add(epoch + 1,
(d2l.evaluate_loss(net, train_iter, loss),
d2l.evaluate_loss(net, test_iter, loss)))
print('w的L2范数:', net[0].weight.norm().item())
这里结果和上面一样,不展示了。
小结
权重衰退可以有效的解决过拟合的情况,相比于减小模型复杂度,权重衰退的方法比较好实现的。