如何快速实现根因分析/业务大盘
Ideas Worth Spreading
写在前面的话
特别感谢
感谢在最早开发鱼骨图带领我前进的技术负责人-佳哥(总监)。他一丝不苟的技术态度、严密的逻辑和高要求(这里大家都懂的),让我成长。这里是他在语雀的博客,其中有一篇是关于技术体系建设之路-可观测,正是有他的指引和思路,才有了本文的可能。
背景介绍
本人前端开发,贴代码的话,代码太多了,如感兴趣,可私聊,本文共三千字,阅读需要时间5分钟。
本文首发于掘金,是真实开发场景的“小结晶”,以文章为契机,将过程和尤其是设计和思考点,分享出来,既是思考又是反思,同时也把在酝酿场景化大盘(这里先这样称呼)类似产品分享出来。
首先
本文是一系列图表讲解的第二篇,第一篇讲到了前端性能调优的实际案例-小白都看的懂,主要是讲解到了通过时序图和散点图进行前端性能优化,今天本篇文章将从另外一个角度,特别是业务数据域性能指标结合的实践的角度,和大家一起认识一些新的图表。
其次
以技术人的角度,剖析技术同学应该关注的几种图表,尤其是对于图表中必须展示业务的思路,希望能抛砖引玉,哪怕能对企业技术架构、cto或者cio以及研发产品测试的同学有一丁点的启发,我将无比自豪。
- 如果感觉本文还不错,欢迎
点赞、关注、收藏、私信 - 如果感觉本文非常糟糕,欢迎
私信 - 如果对
可观测性非常感兴趣,欢迎私信。
正文
为什么不建议研发只做性能大盘
数据孤岛,数字倍感冰冷
单纯的性能指标是冰冷的,堪比hr要求给出裁员名单下午走完流程的通知,否则也不会出现业务不佳研发买单的情况了。
技术服务于业务,但大抵几个性能指标构成的大盘,扛不起业务的大旗,但是投资业务大盘就不一样了,说文绉绉点叫做能直接关联业务指标,直白点叫做money,不论是toB还是toC,都可能会有各自关注的业务指标点。
ToB企业的性能大盘--服务效率为王
大部分ToB企业在乎的是为企业提供高质量的服务:解决客户痛点是购买的动力,持续不断深化才有复购的契机。从企业自身来讲,上面两个动作一般决定权在于决策或者管理者,不论是研发决策者还是公司管理层,更多希望一个好用的工具,不仅能够提供全面性而非局部深入的性能指标的汇总,更重要的凸显业务痛点。
ToC企业的性能大盘--流量访问制胜
大部分ToC企业更在乎流量,不同层级业务之间的流量曲线和性能指标存在天然的某种关系,但性能大盘中技术投入的高性能往往不一定是流量多的环节,如果没有流量地图,高性能的投入只能是凭架构师经验能力想当然。
性能大盘投入产出入不敷出
不论是什么企业,想要单纯依靠性能大盘就能解决业务痛点或者解锁流量瓶颈,虽然不完全等同于“妄想”,但现实成本花费多大精力与背后产生多大效果(ROI)不言而喻。
业绩支撑数据难以令人信服
单纯的业务大盘往往令人一头雾水,最简单的突破点便是前端报错了,根本来不会上报到业务系统,或者后台某个节点挂掉又起来了,先不说影响用户体验,最重要的是根本无法与业务转化挂钩,更不要说指明当前技术架构的薄弱点了。
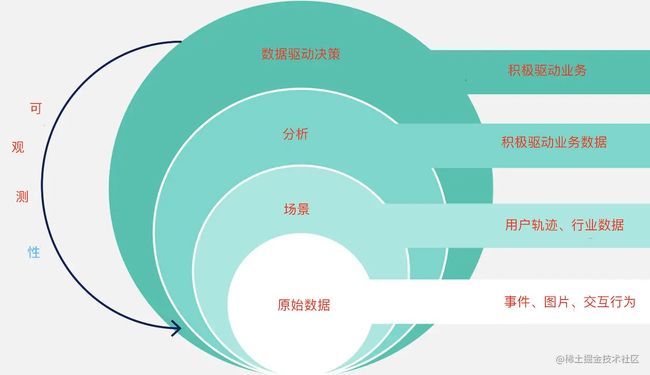
可观测性数据还不错,能和业务结合起来吗?
将可观测性数据按照场景去理解,按照商业场景方式进行归类,处理并分层,会带来积极的"化学效果",按照这种方式使用可观测性数据,能更好的驱动业务,做出更符合商业的技术选型和商业决策。 这种做法,能更适应数字化转型或it技术决策的导向。
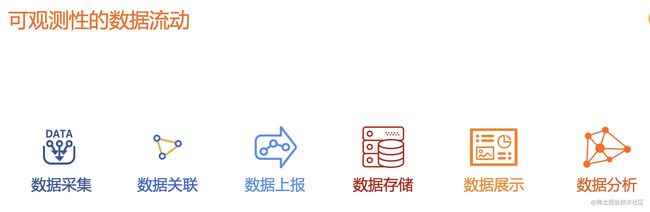
如何结合,有没有现实的思路
如何结合?本文结合工作实际场景,给出一份既是产品思路更是技术设计的答案。
拓扑图为啥不是业务数据和性能的突破口
常见的拓扑图可能有应用拓扑,Gartner曾给出的“超大型”服务应用拓扑如下。

虽然真实服务调用可能没有上图那么复杂,架构拓扑到底能说明什么呢?(上图摘自10 companies that paved the way for developing microservices)
架构拓扑
系统架构性能的瓶颈可能来自系统的架构,通过架构拓扑的绘制,能够反应当前架构的一个状态。举个简单例子:

图表说明
上面这个图表demo,其中每个节点代表一个服务这几个服务分别是:
ruoyi08-system,web server和java后端逻辑mysql08,数据库服务ruoyi-08-gateway,网关服务redis08,缓存服务ruoyi-08-auth,auth服务
这个非常简单的demo图,能很简单的反映出5个服务之间的调用关系。(如果对这个感兴趣,也可以查看我写过的文章:如何快速搭建全链路平台,展示服务拓扑以分析性能?)
而且,每个节点都有一定的大小尺寸,尺寸大小可以用性能指标来填充,常见的性能指标可以是:
“请求数”“P50响应时间”“P75响应时间”“P99响应时间”错误率
注:图表摘自观测云公开demo
核心场景(接口)的可视化
现实中的应用拓扑虽然比这个复杂,但即便是这个简单的拓扑也不能很好的反应业务指标,以电商网站为例,无法看到重要业务场景,比如登录或者支付的实际点击人数,或者错误率。
所以也有类似同学(也就是我)将服务节点换成了接口节点,如下图所示。
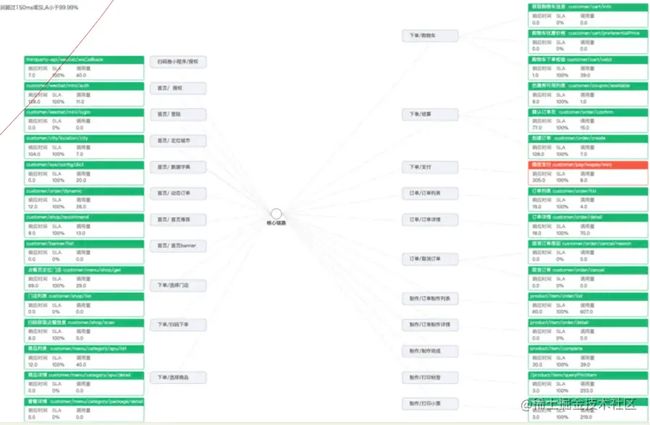
图表说明
图中分别是把接口按照调用先后的顺序进行排列,每个接口分别展示的内容是:
响应时间SLA调用量
这在一定程度上满足了接口层级的场景监听,但实际中可能更多的需要体现接口调用的先后关系,同时也要能更生动的可视化展示接口调用量的情况,而不是冰冷的数字,尤其是调用量的大小关系,于是我想到了漏斗图
漏斗图分析业务数据很不错?
为什么想到漏斗图?
漏斗图一般适用于具有规范性、周期长、环节多的流程分析,通过漏斗图比较各环节的数据,能够直观地对比问题。另外漏斗图还适用于网站业务流程分析,展示用户从进入网站到实现购买(用户旅程)的最终转化率,及每个步骤的转化率。
举一个实际的demo
举一个常见的电商网站的例子,见下图:
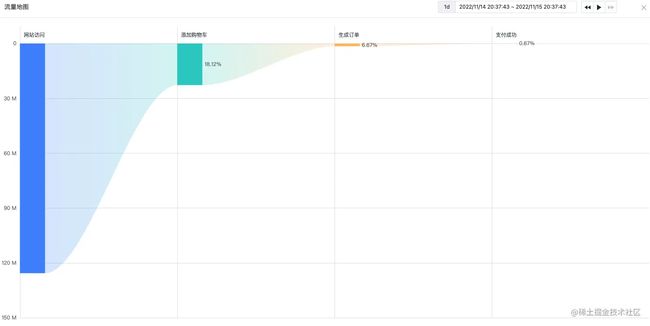
这里有四层:
- 某商品的访问人数
- 添加到购物车的人数
- 生成订单的数量
- 支付成功的数量
我们能看到每层的流量和先后关系,这就比较直观了。可是错误率等去了哪里,又该如何设置?
性能指标去哪里了?如何将漏斗图用做根因分析
但这里出现了比较严重的问题,就是我看不到性能指标,而且作为研发的负责人,一旦某个服务不可用,在这个图上是看不到的,而且突发情况,更要定位故障,做根因分析,这种漏斗图完全无法达到。
鱼骨图做根因分析还不错,能不能试一试?
在管理统计学上,学过鱼骨图,它通常用于拆解问题归因,所以也有人把它叫做因果图。
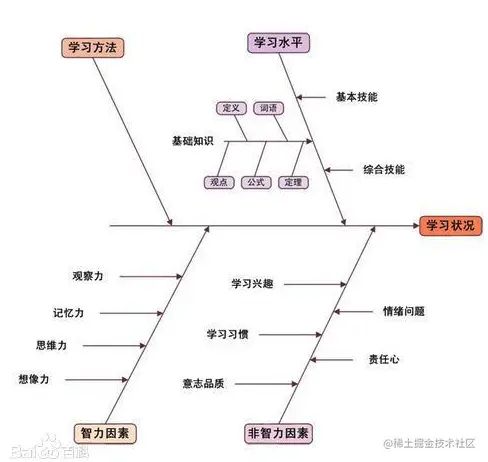
鱼骨图的构成
一般会用鱼骨上长出鱼刺,上面按照一定方式列出一些因素,有助于说明各个原因是如何影响,以及最终结果。 这里我找了一张百度百科中有关鱼骨图的图片,供大家参考:
这是百度百科中的图片,单纯看百度百科的例子,太理论了,很难和实际的技术场景联系起来。这时我会自己的亲身经历多举个栗子。
鱼骨图的真实例子
2020年当时我在一家创业公司做技术中台,主要服务于研发做系统稳定性建设,当时的痛点是想把系统稳定性和业务数据结合起来。
鱼骨图的idea 萌芽了
虽然听上去要做的事情很简单,切入点大家都接触过,就是扫码点餐或者点外卖的场景:从进入小程序到餐送到桌上或者配送成功。
拆解鱼骨图流程
整体的大概流程如下:
扫码点餐 --> 进入首页 --> 选择门店 -->商品列表 --> 购物车-->结算支付-->订单-->制作-->配送
熬夜 画图 写代码 喝红牛 开会 画图 写代码
有了Idea就得好好找资源设计开发上线,经过几十瓶红牛,终于上线了一个版本。
有关这次开发的过程,可以查看我的文章:记一次APM的开发经历)
经过两周的调研、设计、研发,终于收获了如下大盘,里面的每一条线都是我这个前端同学敲代码敲出来的。
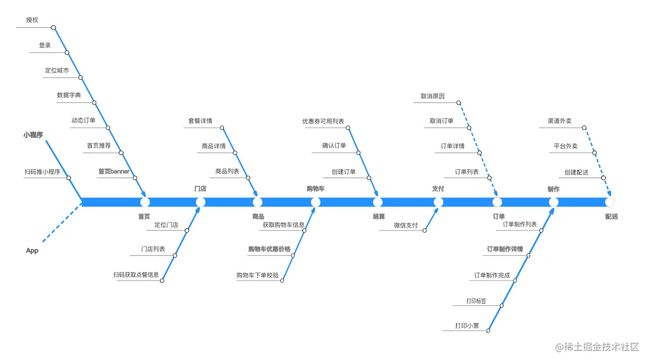
鱼骨图说明
图中是一个很具象化的场景,基本一眼就能看出来,是大家可能都接触过的扫码点餐或者点外卖的场景,图中从进入小程序到的配送成功(餐送到桌上)。而且图中的每个节点都有
- 调用量
- 错误率
- SLA
性能指标和业务数据基本雏形
这样一个基本的性能指标和业务数据的可视化图表的雏形就出来了。
为了完善,还针对节点设置阈值,不同的节点出现某个性能指标(比如错误率)达到某种情况(比如突增),就触发动作(比如告警)。
我以为一张鱼骨图就够了
为啥不是通用模板
然而,每个研发部门,或者每个业务线都需要有类似的业务场景模型出来,一变多或者举一反三的通用模型在这里就成了摆在我面前的场景。
bpmn可能不错,但是总不能寄希望每个业务场景按照bpmn那种耗时费力的情况下操作吧,而且关联也是一个很大的问题。但低代码可能是一条思路。
低代码如何实现的demo
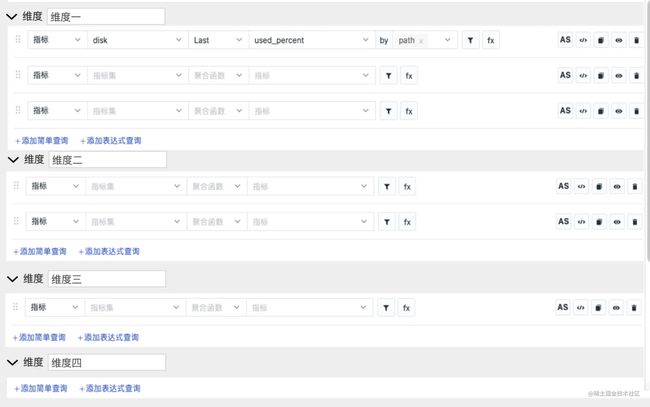
此处特别感谢观测云产品经理Rinck(因为以前的所在技术中台,产品都是魏总和团队成员)
节点说明
每个维度对应一根鱼骨,每一条查询语句对应一根鱼刺,每个维度下面最多有5条查询语句,每条语句返回一个值。
交互说明
hover到鱼刺(鱼骨)时,tooltip显示查询结果
表单说明
第一个表单项目
指标日志基础对象自定义对象应用性能用户访问安全巡检网络
第二个表单项目
第二个表单项目是第一个表单的子集,可能 是
指标集日志来源具体基础对象自定义对象应用性能对应的服务名用户访问对应的页面、会话、性能指标等
第三个表单项目 聚合函数
表达式操作符说明
下拉框中操作符包含
- “=”
- “!=”
- “>=”
- “<=”
- “>”
- “<”
举个例子,比如想看首页页面的访问量

举个例子,比如想看某个城市点击购物车按钮的次数

鱼骨图可视化冲击力不够怎么办?
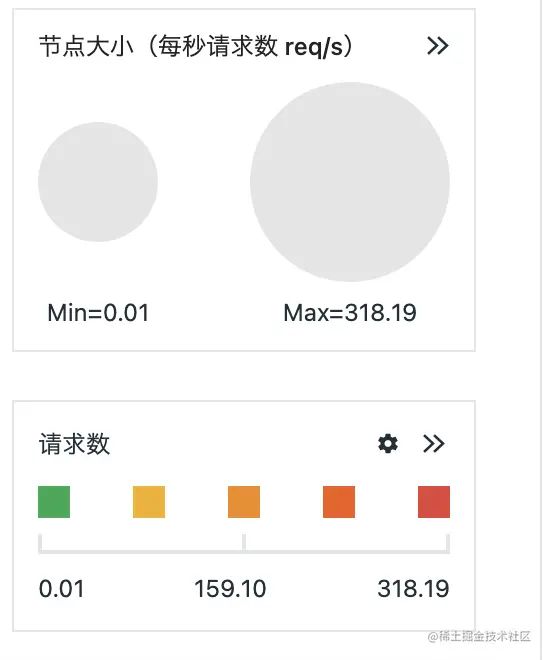
比如鱼骨图中单个节点之间的请求次数,不能很好的通过可视化的角度展示出来。
这里我们想到了每个节点其实是可以设置尺寸的,同时针对不同的量(错误率、流量、点击情况、或者事件、页面访问次数)可以设置成不同的颜色。
开发设计总结
本文基本以亲身开发设计经历,具备以下功能:
- 有丰富的受众:常见系统
架构师、CTO、研发、产品、测试 - 有强大的数据来源:
性能数据、用户数据、业务数据、基础设施数据、日志 - 有丰富的场景:
作战大盘、根因分析、系统大盘
本文结合可视化的图表,提供了一种思路,快速实现了业务数据和性能指标的结合。整体来看这个产品,能够快速实现业务数据、用户访问、应用性能、指标的快速可观测,帮助CIO、CTO、产品经理、研发、测试快速实现多种数据的可观测。
参考链接
漏斗图
拓扑图
场景仪表板