DeepLab系列: v1、v2、v3、v3+
DeepLab v1
paper: Semantic Image Segmentation with Deep Convolutional Nets and Fully Connected CRFs
DCNN用于语义分割时面临的两个问题
- 池化和下采样造成的输出信号分辨率降低
- 空间不敏感性
作者的解决方法
- 引入空洞卷积
- 引入全连接条件随机场
针对第一个问题,作者提出“空洞卷积”,空洞卷积可以在不增加参数的情况下增大卷积核的感受野。同时去掉后几层的池化层避免池化造成的空间信息的损失。
第二个问题是分类网络本身具有的空间平移不变特性造成的,这同时限制了DCNN空间维度的准确性。为了解决这个问题,作者引入了条件随机场(Conditional Random Field, CRF),CRF在传统图像处理主要用于平滑处理,在这里目的是为了恢复局部信息,而不是进一步平滑图像,因此作者引入了全连接CRF,简单来讲就是每个像素点作为节点,像素与像素间的关系作为边,即构成了一个条件随机场。通过二元势函数描述像素点与像素点之间的关系,鼓励相似像素分配相同的标签,而相差较大的像素分配不同标签,而这个“距离”的定义与颜色值和实际相对距离有关。所以这样CRF能够使图片在分割的边界处获得比较好的效果。
DeepLab v2
paper: DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs
v2相比于v1主要做了两点改进
- 受SPP的启发,提出了Atrous Spatial Pyramid Pooling,ASPP模块
- backbone由VGG-16换成ResNet
ASPP的结构如下
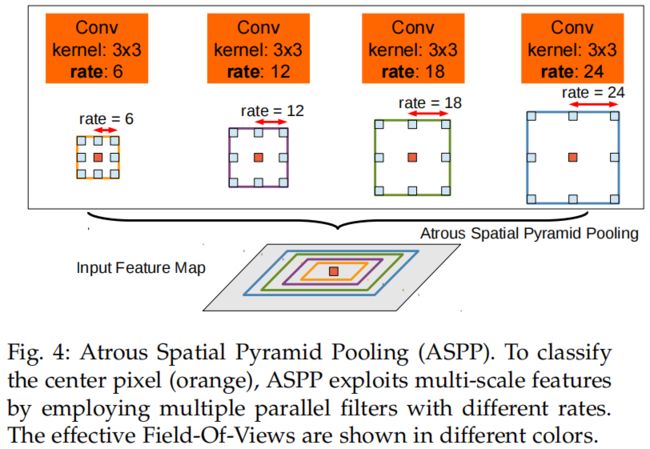
通过并行不同膨胀率的空洞卷积获得不同大小的感受野,从而同时捕获不同尺度目标的信息,即让模型同时看清大物体和小物体。
DeepLab v3
paper: Rethinking Atrous Convolution for Semantic Image Segmentation
v3相比于v2,主要有两点改进
- 进一步优化ASPP的结构
- 去掉了CRF
ASPP的改进,主要有三点
- 引入BN
- 调整各个分支膨胀率
- 引入全局信息
作者通过实验发现在ASPP中引入BN层可以提升性能。同时发现随着膨胀率的增加,有效的特征权重数量会变少,比如考虑一个极端情况,对于65x65的feature map,膨胀率为63x63的3x3卷积会退化成一个1x1卷积,即这个3x3卷积只有中间的权重是有效的。为了解决这个问题,作者将全局信息引入到ASPP中,增加了一个全局平均池化分支,GAP后经过一个1x1卷积然后再双线性插值还原回原本的分辨率。同时调整各个分支的膨胀率,ASPP中包含1个1x1卷积和3个3x3的膨胀卷积,当output_stride=16时,3x3卷积的膨胀率分别为6、12、18,将这5个分支的输出沿通道维度拼接后,经过一个1x1卷积得到ASPP模块的最终输出。
ASPP的结构如下图所示
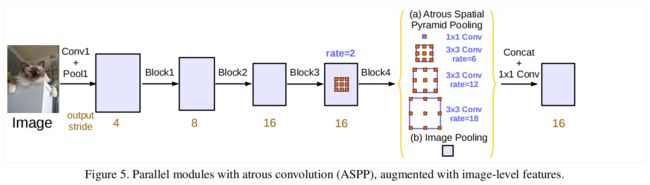
实现细节解析
下面以MMSegmentation中的deeplab v3实现为例,介绍一下具体实现细节
假设batch_size=4,输入shape为(4, 3, 480, 480)。backbone采用ResNet-50,output_stride=8
Backbone
- 原始的ResNet-50中4个stage的strides=(1, 2, 2, 2),不采用膨胀卷积即dilations=(1, 1, 1, 1),而在FCN中4个stage的strides=(1, 2, 1, 1),dilations=(1, 1, 2, 4)。
- 另外有一个contract_dilation=True的设置,即当空洞>1时,压缩第一个卷积层。这里在第三个和第四个stage的第一个bottleneck中将膨胀率减半,即第三个stage的第一个bottleneck中不采用膨胀卷积,第四个stage的第一个bottleneck中dilation=4/2=2。
- 另外这里采用的是ResNetV1c,即stem中的7x7卷积替换成了3个3x3卷积。
- 最后,注意一下padding,在原始实现中除了stem中7x7卷积的padding=3,其它所有padding=1。在FCN中因为用了膨胀卷积,后两个stage的stride=1,为了保持输入输出分辨率一直,padding=dilation。
- 假设batch_size=4,模型输入shape=(4, 3, 480, 480),则backbone四个stage的输出分别为(4, 256, 120, 120)、(4, 512, 60, 60)、(4, 1024, 60, 60)、(4, 2048, 60, 60)。
ASPP Head
- 取ResNet第四个stage的输出(4, 2048, 60, 60)作为aspp head的输入。首先经过全局平均池化得到(4, 2048, 1, 1),然后经过1x1卷积得到(4, 512, 1, 1),最后通过bilinear插值再上采样回去,得到该分支的输出(4, 512, 60, 60)。
- 然后1x1分支和3个3x3膨胀卷积分支的输出维度都为(4, 512, 60, 60),注意这里output_stride=8,相比于上面介绍中的16,这里的膨胀率也要加倍分别为12、24、36。
- 将5个分支的输出拼接得到(4, 2560, 60, 60),然后经过3x3卷积得到(4, 512, 60, 60)。
- 采用dropout,dropout_ratio=0.1。
- 最后经过1x1卷积得到模型的输出(4, num_classes, 60, 60),这里num_classes包括背景类。
Loss
- 模型输出(4, num_classes, 60, 60)经过双线性插值resize成原始输入大小,得到(4, num_classes, 480, 480)。
- 采用交叉熵损失函数。
Auxiliary Head
- 这里auxiliary head采用的是fcn head
- 取ResNet第三个stage的输出(4, 1024, 60, 60),经过Conv2d(1024, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)一个conv-bn-relu得到(4, 256, 60, 60)。
- 采用dropout,dropout_ratio=0.1。
- 经过Conv2d(256, num_classes, kernel_size=(1, 1), stride=(1, 1))得到模型的最终输出(4, num_classes, 60, 60)得到该分支的输出。
ASPP Head代码解析
class ASPPModule(nn.ModuleList):
"""Atrous Spatial Pyramid Pooling (ASPP) Module.
Args:
dilations (tuple[int]): Dilation rate of each layer.
in_channels (int): Input channels.
channels (int): Channels after modules, before conv_seg.
conv_cfg (dict|None): Config of conv layers.
norm_cfg (dict|None): Config of norm layers.
act_cfg (dict): Config of activation layers.
"""
def __init__(self, dilations, in_channels, channels, conv_cfg, norm_cfg,
act_cfg):
super(ASPPModule, self).__init__()
self.dilations = dilations
self.in_channels = in_channels
self.channels = channels
self.conv_cfg = conv_cfg
self.norm_cfg = norm_cfg
self.act_cfg = act_cfg
for dilation in dilations:
self.append(
ConvModule(
self.in_channels,
self.channels,
1 if dilation == 1 else 3,
dilation=dilation,
padding=0 if dilation == 1 else dilation,
conv_cfg=self.conv_cfg,
norm_cfg=self.norm_cfg,
act_cfg=self.act_cfg))
def forward(self, x):
"""Forward function."""
aspp_outs = []
for aspp_module in self:
aspp_outs.append(aspp_module(x))
return aspp_outs
class ASPPHead(BaseDecodeHead):
"""Rethinking Atrous Convolution for Semantic Image Segmentation.
This head is the implementation of `DeepLabV3
`_.
Args:
dilations (tuple[int]): Dilation rates for ASPP module.
Default: (1, 6, 12, 18).
"""
def __init__(self, dilations=(1, 6, 12, 18), **kwargs):
super(ASPPHead, self).__init__(**kwargs)
assert isinstance(dilations, (list, tuple))
self.dilations = dilations
self.image_pool = nn.Sequential(
nn.AdaptiveAvgPool2d(1),
ConvModule(
self.in_channels,
self.channels,
1,
conv_cfg=self.conv_cfg,
norm_cfg=self.norm_cfg,
act_cfg=self.act_cfg))
self.aspp_modules = ASPPModule(
dilations,
self.in_channels,
self.channels,
conv_cfg=self.conv_cfg,
norm_cfg=self.norm_cfg,
act_cfg=self.act_cfg)
self.bottleneck = ConvModule(
(len(dilations) + 1) * self.channels,
self.channels,
3,
padding=1,
conv_cfg=self.conv_cfg,
norm_cfg=self.norm_cfg,
act_cfg=self.act_cfg)
def _forward_feature(self, inputs):
"""Forward function for feature maps before classifying each pixel with
``self.cls_seg`` fc.
Args:
inputs (list[Tensor]): List of multi-level img features.
Returns:
feats (Tensor): A tensor of shape (batch_size, self.channels,
H, W) which is feature map for last layer of decoder head.
"""
x = self._transform_inputs(inputs) # (4,2048,60,60)
aspp_outs = [
resize(
self.image_pool(x),
size=x.size()[2:],
mode='bilinear',
align_corners=self.align_corners)
]
# (4,2048,60,60)->(4,2048,1,1)->(4,512,1,1)->(4,512,60,60)
aspp_outs.extend(self.aspp_modules(x)) # [(4,512,60,60),(4,512,60,60),(4,512,60,60),(4,512,60,60),(4,512,60,60)]
aspp_outs = torch.cat(aspp_outs, dim=1) # (4,2560,60,60)
feats = self.bottleneck(aspp_outs) # (4,512,60,60)
return feats
def forward(self, inputs):
"""Forward function."""
output = self._forward_feature(inputs) # (4,512,60,60)
output = self.cls_seg(output) # (4,2,60,60)
return output
ASPP Head的完整结构
(decode_head): ASPPHead(
input_transform=None, ignore_index=255, align_corners=False
(loss_decode): CrossEntropyLoss(avg_non_ignore=False)
(conv_seg): Conv2d(512, 2, kernel_size=(1, 1), stride=(1, 1))
(dropout): Dropout2d(p=0.1, inplace=False)
(image_pool): Sequential(
(0): AdaptiveAvgPool2d(output_size=1)
(1): ConvModule(
(conv): Conv2d(2048, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): _BatchNormXd(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(activate): ReLU(inplace=True)
)
)
(aspp_modules): ASPPModule(
(0): ConvModule(
(conv): Conv2d(2048, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): _BatchNormXd(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(activate): ReLU(inplace=True)
)
(1): ConvModule(
(conv): Conv2d(2048, 512, kernel_size=(3, 3), stride=(1, 1), padding=(12, 12), dilation=(12, 12), bias=False)
(bn): _BatchNormXd(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(activate): ReLU(inplace=True)
)
(2): ConvModule(
(conv): Conv2d(2048, 512, kernel_size=(3, 3), stride=(1, 1), padding=(24, 24), dilation=(24, 24), bias=False)
(bn): _BatchNormXd(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(activate): ReLU(inplace=True)
)
(3): ConvModule(
(conv): Conv2d(2048, 512, kernel_size=(3, 3), stride=(1, 1), padding=(36, 36), dilation=(36, 36), bias=False)
(bn): _BatchNormXd(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(activate): ReLU(inplace=True)
)
)
(bottleneck): ConvModule(
(conv): Conv2d(2560, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): _BatchNormXd(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(activate): ReLU(inplace=True)
)
)
DeepLab v3+
paper: Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation
v3+主要有两点创新
- 将SPP和encoder-decoder结构结合起来
- 在ASPP模块和decoder模块中引入深度可分离卷积
为了在多个尺度上获取上下文信息,DeepLab v3并行应用了几个不同膨胀率的空洞卷积即ASPP,而PSPNet在不同的网格尺度上进行池化。即使最后一层特征图上编码了丰富的语义信息,但由于backbone中池化或stride>1的卷积操作导致物体边界细节信息的损失。这可以通过应用空洞卷积提取更密集的特征图来缓解,但是,考虑到目前复杂的网络设计和有限的GPU资源,输出output_stride=8或是4的大特征图对计算资源的要求太高。比如以ResNet-101为例,如果要输出output_stride=16的特征图,最后3个residual blocks共9层需要膨胀卷积,如果output_stride=8,则26个residual blocks共78层需要膨胀卷积,因此对于这种结构的模型提取更密集的输出特征非常消耗计算资源。
另一方面,encoder-decoder结构的计算非常快,因为不需要膨胀卷积输出大分辨率的特征图,在encoder阶段不断减小输出特征图的分辨率提取更丰富的语义信息,在decoder阶段逐步增大输出特征图的分辨率恢复物体边界的细节信息。
因此作者提出结合这两种方法的优点,通过引入多尺度上下文信息来丰富encoder-decoder结构中的编码模块。提出的新模型结构如下图(c)所示
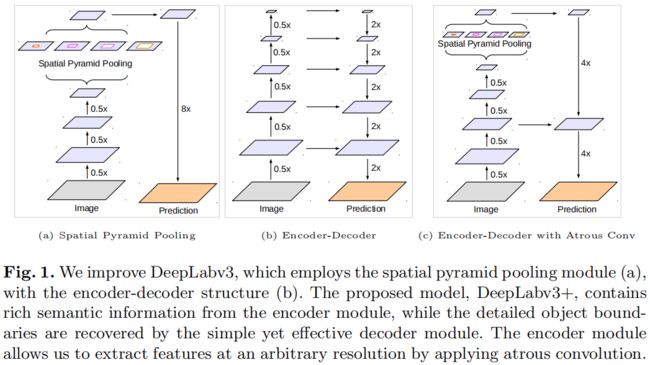
此外,受到深度可分离卷积的启发,作者还引入了Xception模型,并在ASPP模块和decoder阶段使用了空洞可分离卷积,获得了精度和速度上的提升。
方法介绍
Atrous convolution & Depthwise separable convolution
atrous depthwise convolution如下所示

DeepLab v3 as encoder
作者使用deeplab v3中logits前的最后一个feature map作为新提出的encoder-decoder结构中编码模块的输出。encoder的输出包含256个通道和丰富的语义信息。
Proposed decoder
在deeplab v3中,aspp的输出特征output_stride=16,然后通过双线性插值上采样16倍恢复原始输入大小,这里的插值上采样也可以看作是decoder模块,但是这种简单的decoder可能没法很好的恢复细节信息,因此作者提出了一个简单且更有效的decoder module,如下图所示
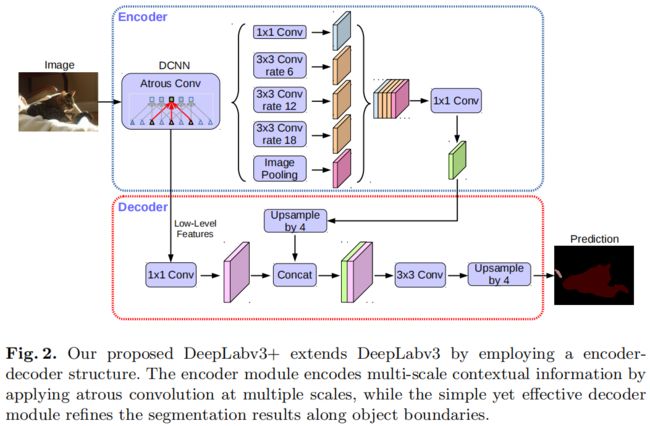
encoder的输出特征首先通过双线性插值进行4倍上采样,然后与backbone中对应的具有相同分辨率的浅层特征进行concatenate(比如ResNet-101中striding前的Conv2),在拼接之前首先对浅层feature map通过1x1卷积进行降维,因为对应的浅层特征的通道数比较大(256或512),而encoder的输出特征图通道数为256,如果不降维直接拼接可能会让前者的比重更大使得训练变得困难。拼接之后再接3x3卷积来refine特征,最后再通过一个bilinear插值进行4倍上采样。
Modified Aligned Xception
Xception在ImageNet上展现了很好的分类效果同时计算速度很快,MSRA团队对其进行了改进提出了Aligned Xception并进一步推动了目标检测任务的性能。作者又对其进一步改进使其更适合语义分割任务,具体来说包括(1)更深的层数(2)所有的max pooling都替换成了stride>1的深度可分离卷积(空洞深度可分离卷积)(3)类似于MobileNet,每个3x3 depthwise convolution后都加了BN和ReLU。
实现细节解析
下面以MMSegmentation中的deeplab v3+实现为例,介绍一下具体实现细节
假设batch_size=4,输入shape为(4, 3, 480, 480)。backbone采用ResNet-50,output_stride=8
Backbone
backbone和上面的deeplab v3中的一样。
DepthwiseSeparableASPP Head
- 取ResNet第四个stage的输出(4, 2048, 60, 60)作为sep_aspp head的输入。全局池化分支和1x1卷积分支与aspp中一样。另外三个3x3膨胀卷积分支都替换成对应的深度可分离膨胀卷积,即3x3的depthwise_conv + 1x1的pointwise_conv,每个分支的dilation不变。然后将5个分支的输出拼接,经过3x3卷积得到(4, 512, 60, 60),和原始aspp保持一致。
- 【新增】接着融合backbone中low-level feature,注意这里backbone用的是ResNet-50,而不是文章中的ResNet-101,因此这里sep_aspp module的output_stride=8,取backbone中conv2即第一个输出(4, 256, 120, 120),首先通过1x1卷积降维,输出(4, 48, 120, 120)。接着sep_aspp的输出(4, 512, 60, 60)通过bilinear上采样2倍(ResNet-101上采样4倍)得到(4, 512, 120, 120),然后和降维后的low-level特征(4, 48, 120, 120)拼接得到(4, 560, 120, 120),然后通过"a few 3x3 convolutions to refine the features",具体实现中是2个连续的3x3深度可分离卷积,且每个卷积后都有BN-ReLU,最终输出(4, 512, 120, 120)。
- 采用dropout,dropout_ratio=0.1。
- 最后经过1x1卷积得到模型的输出(4, num_classes, 60, 60),这里num_classes包括背景类。
Loss
- 模型输出(4, num_classes, 60, 60)经过双线性插值resize成原始输入大小,得到(4, num_classes, 480, 480)。
- 采用交叉熵损失函数。
Auxiliary Head
- 和DeepLab v3中一样。
DepthwiseSeparableASPP Head代码解析
# Copyright (c) OpenMMLab. All rights reserved.
import torch
import torch.nn as nn
from mmcv.cnn import ConvModule, DepthwiseSeparableConvModule
from mmseg.ops import resize
from ..builder import HEADS
from .aspp_head import ASPPHead, ASPPModule
class DepthwiseSeparableASPPModule(ASPPModule):
"""Atrous Spatial Pyramid Pooling (ASPP) Module with depthwise separable
conv."""
def __init__(self, **kwargs):
super(DepthwiseSeparableASPPModule, self).__init__(**kwargs)
for i, dilation in enumerate(self.dilations):
if dilation > 1:
self[i] = DepthwiseSeparableConvModule(
self.in_channels,
self.channels,
3,
dilation=dilation,
padding=dilation,
norm_cfg=self.norm_cfg,
act_cfg=self.act_cfg)
@HEADS.register_module()
class DepthwiseSeparableASPPHead(ASPPHead):
"""Encoder-Decoder with Atrous Separable Convolution for Semantic Image
Segmentation.
This head is the implementation of `DeepLabV3+
`_.
Args:
c1_in_channels (int): The input channels of c1 decoder. If is 0,
the no decoder will be used.
c1_channels (int): The intermediate channels of c1 decoder.
"""
def __init__(self, c1_in_channels, c1_channels, **kwargs):
super(DepthwiseSeparableASPPHead, self).__init__(**kwargs)
assert c1_in_channels >= 0
self.aspp_modules = DepthwiseSeparableASPPModule(
dilations=self.dilations,
in_channels=self.in_channels,
channels=self.channels,
conv_cfg=self.conv_cfg,
norm_cfg=self.norm_cfg,
act_cfg=self.act_cfg)
if c1_in_channels > 0:
self.c1_bottleneck = ConvModule(
c1_in_channels,
c1_channels,
1,
conv_cfg=self.conv_cfg,
norm_cfg=self.norm_cfg,
act_cfg=self.act_cfg)
else:
self.c1_bottleneck = None
self.sep_bottleneck = nn.Sequential(
DepthwiseSeparableConvModule(
self.channels + c1_channels,
self.channels,
3,
padding=1,
norm_cfg=self.norm_cfg,
act_cfg=self.act_cfg),
DepthwiseSeparableConvModule(
self.channels,
self.channels,
3,
padding=1,
norm_cfg=self.norm_cfg,
act_cfg=self.act_cfg))
def forward(self, inputs):
"""Forward function."""
x = self._transform_inputs(inputs) # (2,2048,60,60)
aspp_outs = [
resize(
self.image_pool(x),
size=x.size()[2:],
mode='bilinear',
align_corners=self.align_corners)
]
aspp_outs.extend(self.aspp_modules(x)) # [(4,512,60,60),(4,512,60,60),(4,512,60,60),(4,512,60,60),(4,512,60,60)]
aspp_outs = torch.cat(aspp_outs, dim=1) # (4,2560,60,60)
output = self.bottleneck(aspp_outs) # (4,512,60,60)
if self.c1_bottleneck is not None:
c1_output = self.c1_bottleneck(inputs[0]) # (4,256,120,120) -> (4,48,120,120)
output = resize(
input=output,
size=c1_output.shape[2:],
mode='bilinear',
align_corners=self.align_corners) # (4,512,120,120)
output = torch.cat([output, c1_output], dim=1) # (4,560,120,120)
output = self.sep_bottleneck(output) # (4,512,120,120)
output = self.cls_seg(output) # (4,2,120,120)
return output
参考
深度学习|语义分割:DeepLab系列 - 知乎
《Deeplab V1》论文阅读