Kaggle Feedback Prize 3比赛总结:如何高效使用hidden states输出(1)
比赛链接:https://www.kaggle.com/competitions/feedback-prize-english-language-learning
FeedBack 3 kaggle 主要使用了Transformer类的模型进行。对于如何使用高效transformer输出完成任务,本系列做了一些常见用法的总结。
hugging face中bert类的预训练模型对于hidden states的输出有两种:
- last hidden state (batch size, seq Len, hidden size) 这是最后一层的hidden states 输出。
- all hidden states (n layers, batch size, seq Len, hidden size) 是所有每一层的hidden states 都会输出。
在为下游任务进行微调的过程中,最后一层的输出不一定是输入文本的最佳表示。对于预训练的语言模型,包括Transformer,输入文本的最有效的上下文表征往往出现在中间层,而顶层则专门用于语言建模。因此,仅仅使用最后一层输出可能会限制预训练的表征能力。
如下图就表示了不同层的hidden states 对于上下文的表征能力对整体任务的效果。可以看到结合不同层的hidden states 比仅仅使用最后一层会得到更好的效果。
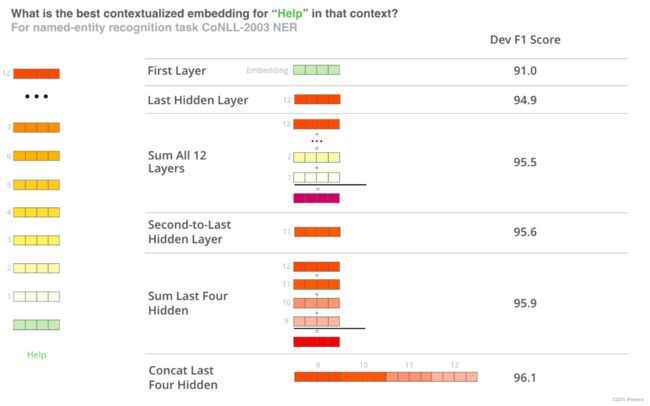
Last layer hidden state
首先还是介绍一些常见的针对last layer hidden states的特征处理办法。
CLS token embeddings
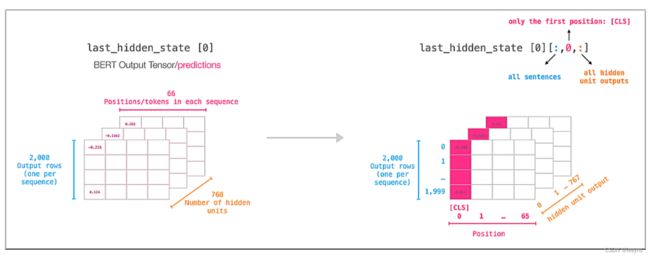
如图中所示表示last_hidden_state,蓝色2000表示一起处理的sequence数量,即 batch size 为2000。Squence length 长度为66。右图中标红的特征为 [CLS] token. 一般last hidden state的输出维度为 [batch, maxlen, hidden_state]. 如果要曲 [CLS] token,那么维度将变为 [batch, 1, hidden_state],因此对于 [CLS] token, [batch, hidden_state]。
Bert类的预训练模型,对于序列额外增加了 [CLS] token,用来获取整体的上下文信息,这对于简单的例如文本分类的任务是足够的。
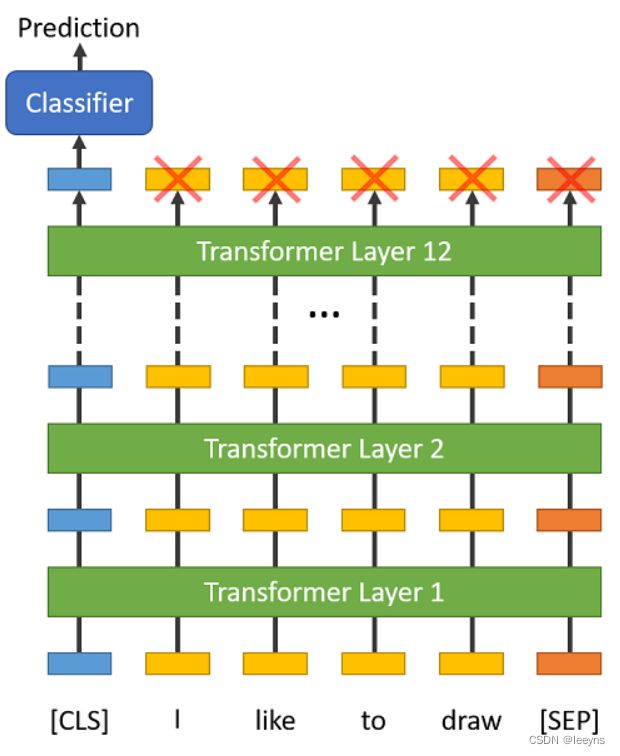
例,使用hugging face 定义的模型进行使用 [CLS] token的二分类任务。
with torch.no_grad():
outputs = model(features['input_ids'], features['attention_mask'])
last_hidden_state = outputs[0]
cls_embeddings = last_hidden_state[:, 0]
logits = nn.Linear(config.hidden_size, 1)(cls_embeddings) # regression head
print(f'Last Hidden State Output Shape: {last_hidden_state.detach().numpy().shape}')
print(f'CLS Embeddings Output Shape: {cls_embeddings.detach().numpy().shape}')
print(f'Logits Shape: {logits.detach().numpy().shape}')
输出为:
Last Hidden State Output Shape: (16, 256, 768)
CLS Embeddings Output Shape: (16, 768)
Logits Shape: (16, 1)
Pooling method
上述基于 [CLS] token 的方法,仅仅使用了 last layer hidden state 的第一个 token的特征。有时候,整个squence 的特征对于下游任务都有帮助,因此我们可以使用pooling的方法来合理的利用整个sequeence中的特征。常见的pooling的办法有 mean pooling, max pooling。
Max pooling
Mean pooling 是使用整个last layer hidden state,取其中最大的作为下游任务的特征。下图,左边是只使用 [CLS] token,右图是使用了 max pooling 策略。
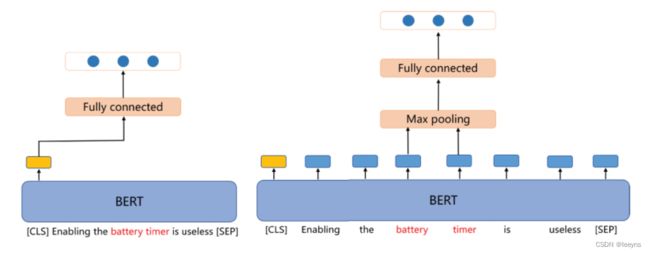
一般我们使用torch.max(last_hidden_state, 1)来操作。但是,对于NLP任务,有时候我们会对序列进行padding,因此在使用mean pooling的时候,要注意去掉那些padding token。
代码如下:
with torch.no_grad():
outputs = model(features['input_ids'], features['attention_mask'])
last_hidden_state = outputs[0]
attention_mask = features['attention_mask']
input_mask_expanded = attention_mask.unsqueeze(-1).expand(last_hidden_state.size()).float()
last_hidden_state[input_mask_expanded == 0] = -1e9 # Set padding tokens to large negative value
max_embeddings = torch.max(last_hidden_state, 1)[0]
logits = nn.Linear(config.hidden_size, 1)(max_embeddings) # regression head
print(f'Last Hidden State Output Shape: {last_hidden_state.detach().numpy().shape}')
print(f'Max Embeddings Output Shape: {max_embeddings.detach().numpy().shape}')
print(f'Logits Shape: {logits.detach().numpy().shape}')
输出为:
Last Hidden State Output Shape: (16, 256, 768)
Max Embeddings Output Shape: (16, 768)
Logits Shape: (16, 1)
Mean pooling
Mean pooling 是使用整个last layer hidden state 求平均来得到最后的平均嵌入表示。一般我们使用torch.mean(last_hidden_state, 1)来求平均。但是,对于NLP任务,有时候我们会对序列进行padding,因此在使用mean pooling的时候,要注意去掉那些padding token。
步骤如下:
- Step 1: Expand Attention Mask from
[batch_size, max_len]to[batch_size, max_len, hidden_size]. - Step 2: Sum Embeddings along
max_lenaxis so now we have[batch_size, hidden_size]. - Step 3: Sum Mask along
max_lenaxis. This is done so that we can ignore padding tokens. - Step 4: Take Average.
代码实现如下:
with torch.no_grad():
outputs = model(features['input_ids'], features['attention_mask'])
# 获取最后一层输出及padding mask
last_hidden_state = outputs[0]
attention_mask = features['attention_mask']
# 扩展mask
input_mask_expanded = attention_mask.unsqueeze(-1).expand(last_hidden_state.size()).float()
sum_embeddings = torch.sum(last_hidden_state * input_mask_expanded, 1) # 求和
sum_mask = input_mask_expanded.sum(1)
sum_mask = torch.clamp(sum_mask, min=1e-9)
mean_embeddings = sum_embeddings / sum_mask # 求平均
logits = nn.Linear(config.hidden_size, 1)(mean_embeddings) # regression head
print(f'Last Hidden State Output Shape: {last_hidden_state.detach().numpy().shape}')
print(f'Mean Embeddings Output Shape: {mean_embeddings.detach().numpy().shape}')
print(f'Logits Shape: {logits.detach().numpy().shape}')
输出为:
Last Hidden State Output Shape: (16, 256, 768)
Mean Embeddings Output Shape: (16, 768)
Logits Shape: (16, 1)
Mean-max pooling
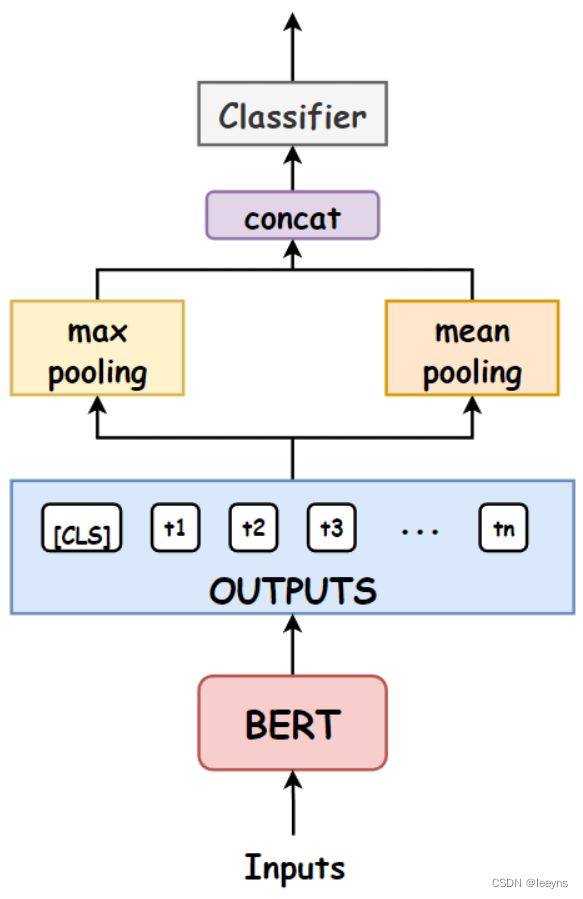
Mean Max Pooling是竞赛中最常用的技术。我们首先找到均值和最大嵌入,然后将其串联起来,得到一个两倍于隐藏大小的最终表示。上图显示了这是如何做到的。
with torch.no_grad():
outputs = model(features['input_ids'], features['attention_mask'])
last_hidden_state = outputs[0]
mean_pooling_embeddings = torch.mean(last_hidden_state, 1)
_, max_pooling_embeddings = torch.max(last_hidden_state, 1)
mean_max_embeddings = torch.cat((mean_pooling_embeddings, max_pooling_embeddings), 1)
logits = nn.Linear(config.hidden_size*2, 1)(mean_max_embeddings) # twice the hidden size
print(f'Last Hidden State Output Shape: {last_hidden_state.detach().numpy().shape}')
print(f'Mean-Max Embeddings Output Shape: {mean_max_embeddings.detach().numpy().shape}')
print(f'Logits Shape: {logits.detach().numpy().shape}')
输出为:
Last Hidden State Output Shape: (16, 256, 768)
Mean-Max Embeddings Output Shape: (16, 1536)
Logits Shape: (16, 1)
总结
至此对于如何使用last layer hidden state进行下游任务的常见方法就全部介绍完了。就如文章一开始描述的仅仅使用last layer hidden states可能并不能有十分好的效果,接下来将会更新如何高效的利用Transformer输出的hidden states。