【论文笔记】AN IMAGE IS WORTH 16X16 WORDS:TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE

论文标题:AN IMAGE IS WORTH 16X16 WORDS:TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE
论文链接:https://arxiv.org/abs/2010.11929
论文代码:https://github.com/google-research/vision_transformer
发表时间:2020年10月-最后修订2021年6月
核心思想
将自注意力机制应用在CV领域,关键在于,将图片分割等大的patch,添加位置信息,然后按序排成一排,输入进Vision Transformer(ViT)进行训练
引入Transformer在机器翻译任务上的应用,ViT的模型只是采用了Encoder部分
在大规模数据集中进行训练,应用在小数据集上进行微调,效果超过目前最好的CNN架构
在NLP领域中,是Transformer的主场,大家可以自行检索一下Transformer的架构,自行学习
Transformer简单架构:字符级编码---正则化---多头注意力机制---残差
摘要
虽然 Transformer 架构已成为自然语言处理任务的事实标准,但其在计算机视觉中的应用仍然有限。在视觉上,注意力要么与卷积网络结合使用,要么用于替换卷积网络的某些组件,同时保持其整体结构不变
我们表明,这种对 CNN 的依赖是不必要的,直接应用于图像块序列的 Transformer 可以在图像分类任务上表现得非常好。当对大量数据进行预训练并转移到多个中型或小型图像识别基准(ImageNet、CIFAR-100、VTAB 等)时,与最先进的卷积网络相比,Vision Transformer (ViT) 获得了出色的结果,同时训练所需的计算资源大大减少
框架结构

方法

Transformer输入的是一维序列,而图片的数据是二维序列,因此将图片分割等大的patch,进行Patch Embedding的方法将图片以合适的方式输入到模型中
首先,将原始图片划分为多个patch子图,每个子图相当于一个token。接着,对每个patch进行embedding,通过一个线性变换层将二维的patch嵌入表示为长度为D的一维向量,并添加位置嵌入信息(0,1,2,…),即每个patch在原始图像中的位置信息(目的是:引入位置信息有利于模型正确评估注意力权重)
图像中0的位置是起一个占位符的作用,类似Bert中的CLS(不太了解Bert…不太懂这个操作)
实验
典型模型设置
“Base”和“Large”模型直接来自 BERT,我们添加了更大的“Huge”模型
在下文中,我们使用简短的符号来表示模型大小和输入补丁大小:例如,ViT-L/16 表示具有 16×16 输入补丁大小的“大”变体
请注意,Transformer 的序列长度与块大小的平方成反比,因此块大小较小的模型计算成本更高
实验任务:图像分类
实验结果:ViT-H/14的架构,具有明显优势

实验任务:将 VTAB 任务分解为各自的组,并在此基准上与之前的 SOTA 方法进行了比较
实验结果:ViT-H/14效果最优

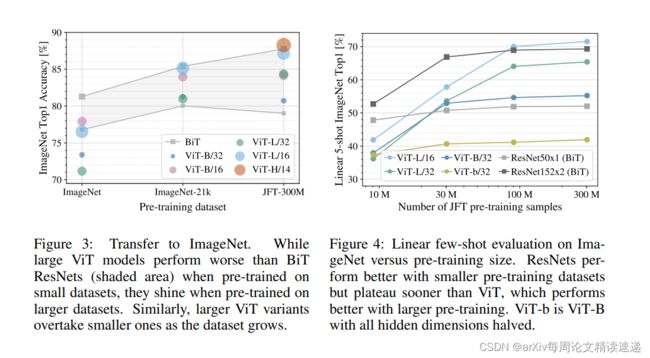
实验任务:证明ViT在大型数据集训练后,效果最佳,而小数据集训练后,效果不如CNN
实验结果:在大数据集JFT-300M上训练后,ViT效果最佳

写在最后
ViT已经具有取代CNN架构的一切准备了么?ViT的实际应用是否也会如同Transformer在NLP中的地位呢?
也许,ViT将会引领一个时代