语义分割模型架构演进与相关论文阅读
本文总结分析了主流语义分割模型架构演进过程,涉及FCN、DeepLab系列、RefineNet、PSPNet、BiSeNet、FastFCN、ConvCRFs、DUpsampling、DFANet、DANet、FickleNet、LedNet、ACNet等在内的20多个模型,本来是2019年一次组会的分享,这里重新总结,就当复习一下了。
1. FCN-用于语义分割的全卷积神经网络
Long J , Shelhamer E , Darrell T . Fully Convolutional Networks for Semantic Segmentation[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2014, 39(4):640-651.
第一次使用深度学习的方法进行语义分割的,论文的分析基于下面两个问题:
- 下采样过程中的图像细节丢失
- 图像语义信息和位置信息的矛盾
这两个问题也是标准语义分割问题的难点,基本上不考虑实时性的语义分割模型架构都是尝试对这两个问题进行阐述并提出特定解决方案。
具体地,下采样过程中特征图尺寸不断减小,这个过程势必抛弃了一些信息,这些信息通常是图像中目标的位置信息。

那为啥还要下采样?是因为这是对图像中目标进行分类的要求,比如下图所示的典型的图像分类网络VGG-16,经过全连接层后,变成(1000,1)的向量,表示属于每个类别的概率。

这也就引出了第二个问题,越深层也就是尺寸越小的特征图,包含更多的语义信息,更有利于鉴别这个目标区域是什么类别;而越浅层也就是尺寸越大的特征图,包含更多的位置信息,更有利于划分目标的边界。
基于语义分割这个两个互相矛盾的问题,FCN提出使用全卷积和跳跃结构。
首先是全卷积,也就是最后不把特征图映射为一个列向量,以保持特征图尺寸,如下图所示,这个特征图尺寸长宽一直折半,最终分别都是原始输入尺寸的三十二分之一而非列向量,之后的语义分割模型实际上也都采取了这种全卷机的神经网络形式,只不过各有各的调整与改进。

模型第二个特点是跳跃结构,根据上面全卷机网络生成的不同尺寸的特征图,选取不同层产生的特征图进行上采样与融合,如下图所示:

基于这种跳跃结构有FCN-32s(32x特征图32x上采样作为分割结果)、FCN-16s(32x特征图先进行2x上采样得到16x特征图然后与“真”16x特征图融合后进行2x上采样作为分割结果)、FCN-8s,之后甚至产生了FCN-4s和FCN-2s。
以FCN-16s为例简单看一下代码:
class FCN16s(nn.Module):
def __init__(self, pretrained_net, n_class):
super().__init__()
self.n_class = n_class
self.pretrained_net = pretrained_net
self.relu = nn.ReLU(inplace=True)
self.deconv1 = nn.ConvTranspose2d(512, 512, kernel_size=3, stride=2, padding=1, dilation=1, output_padding=1)
self.bn1 = nn.BatchNorm2d(512)
self.deconv2 = nn.ConvTranspose2d(512, 256, kernel_size=3, stride=2, padding=1, dilation=1, output_padding=1)
self.bn2 = nn.BatchNorm2d(256)
self.deconv3 = nn.ConvTranspose2d(256, 128, kernel_size=3, stride=2, padding=1, dilation=1, output_padding=1)
self.bn3 = nn.BatchNorm2d(128)
self.deconv4 = nn.ConvTranspose2d(128, 64, kernel_size=3, stride=2, padding=1, dilation=1, output_padding=1)
self.bn4 = nn.BatchNorm2d(64)
self.deconv5 = nn.ConvTranspose2d(64, 32, kernel_size=3, stride=2, padding=1, dilation=1, output_padding=1)
self.bn5 = nn.BatchNorm2d(32)
self.classifier = nn.Conv2d(32, n_class, kernel_size=1)
def forward(self, x):
output = self.pretrained_net(x)
x5 = output['x5'] # size=(N, 512, x.H/32, x.W/32)
x4 = output['x4'] # size=(N, 512, x.H/16, x.W/16)
score = self.relu(self.deconv1(x5)) # size=(N, 512, x.H/16, x.W/16)
score = self.bn1(score + x4) # element-wise add, size=(N, 512, x.H/16, x.W/16)
score = self.bn2(self.relu(self.deconv2(score))) # size=(N, 256, x.H/8, x.W/8)
score = self.bn3(self.relu(self.deconv3(score))) # size=(N, 128, x.H/4, x.W/4)
score = self.bn4(self.relu(self.deconv4(score))) # size=(N, 64, x.H/2, x.W/2)
score = self.bn5(self.relu(self.deconv5(score))) # size=(N, 32, x.H, x.W)
score = self.classifier(score) # size=(N, n_class, x.H/1, x.W/1)
return score # size=(N, n_class, x.H/1, x.W/1)
2. DeepLabV1- 使用深度卷积网络与全连接条件随机场进行图像语义分割
Chen L, Papandreou G, Kokkinos I, et al. Semantic Image Segmentation with Deep Convolutional Nets and Fully Connected CRFs[C]. international conference on learning representations, 2015.
论文旨在解决两个关键问题:
- 下采样过程中的图像细节丢失
- CNN空间不变性
第一个问题不再赘述,看第二个问题,CNN空间不变形,就是说无论目标怎样平移、缩放都不太会影响CNN对其类别的判定,如下图所示,但是这分割任务影响就很大。

在这篇论文之前的不少研究中都认为空间不变形可能是之前提到的下采样结构造成的,但最近的研究发现并不是,所以之后的论文也就基本不提这个不变形对DCNN的定位精度的影响了
DeepLabV1为平衡这两个问题使用了全卷积神经网络、空洞卷积再加上全连接条件随机场后处理,这个过程如下所示:

实际上,DeepLabV1的主干部分和FCN差不多,只不过在最后一部分下采样操作处使用了空洞卷积,使得特征图尺寸保持了十六分之一。空洞卷积是能够增大感受野同时保持特征图尺寸的卷积技术,既不影响特征描述效果,还可保留丰富的空间位置信息。
如下图所示,空洞卷积和标准卷积的一个对比,以输入 5 × 5 5\times 5 5×5为例,标准卷积的一步操作如下图b所示,卷积核尺寸为 3 × 3 3\times3 3×3,步长为2,填充值为1,感受野尺寸 3 × 3 3\times3 3×3;空洞/扩张卷积的一步操作如下图b所示,卷积核尺寸 3 × 3 3\times3 3×3,扩张率2,步长1,填充值2,感受野尺寸 5 × 5 5\times5 5×5,虽然步长更小填充更大,但是空洞卷积能够很好的应对,能够实现上面提到的目的。

最后是关于全连接条件随机场,这种后处理的方式是端到端学习不推荐的所以进来直接使用很少,但是可以将其变形为损失函数甚至直接作为网络层的论文取得了不错的效果。
条件随机场是马尔科夫随机场的一个特例,我自己画了几幅图粗略的描述了一下全连接条件随机场的建模过程:
如图a,有一副原始图像,要逐像素点进行分类。简单地,每一点的像素类别只和它自身有关,得到图b,这样效果显然是不够的。令每一点的像素它的四邻域的像素点有关得到图c,但如果相邻的点出现了波动,那么这种程度的关联是不够的。令每一点的像素和其他所有的像素点相关,这种相关可以是正的也可以是负的,这样得到图d,全连接条件随机场。也叫Dense CRF。

下面的公式是全连接条件随机场的能量函数,其中x指每一个像素点的类别标签,这个函数计算的是图像中所有点的能量之和:

它的前半部分是一个一元函数,其中P(xi)是由深度卷积神经网络产生的一个概率值:
![]()
后半部分表示一对像素点之间的关系,计算公式如下:

u ( x i , y j ) u(x_i,y_j) u(xi,yj)表示约束力的传导方向,是增强还是减弱,比如像素1可能是人,像素2可能是人,像素3可能是车,那么1和2互相增强,2和3互相减弱;后面的加权项是典型得分权重乘以特征,计算两个像素点之间的亲密度,具体计算过程是这样的:
![]()
其中 p p p是像素的2维位置, I I I是图像的3维像素值,有三个不同的方差符号表示三个高斯分布的方差;后半部分就是一个平滑的处理。从这里可以看出:像素距离越近,颜色越接近,特征就越强;而分母即方差大的话feature就很难强起来;所以这里就是一个在五维空间寻找相近像素并进行特征增强的过程。
DenseCRF看起来很难实现,但实际上python中有封装好的包,pydensecrf可以实现,而且作为后处理的手段也不参与训练。
在DeepLabV1论文中, w 2 , σ γ = 3 w_2,\sigma_{\gamma}=3 w2,σγ=3, w 1 , σ a l p h a , σ β w_1 ,\sigma_{alpha},\sigma_{\beta} w1,σalpha,σβ在一个100张图片的小数据集上交叉验证,得到一个粗略的范围值,其中 w 1 ∈ [ 5 ; 10 ] w_1\in[5; 10] w1∈[5;10], σ a l p h a ∈ [ 50 : 10 : 100 ] \sigma_{alpha}\in[50 : 10 : 100] σalpha∈[50:10:100], σ β ∈ [ 3 : 1 : 10 ] \sigma_{\beta}\in[3 : 1 : 10] σβ∈[3:1:10]。
3. 使用空洞卷积的多尺度语义聚合模型
Yu F, Koltun V. Multi-Scale Context Aggregation by Dilated Convolutions[C]. international conference on learning representations, 2016.
论文提出了两个问题:
- 是否真的需要下采样层?
- 对多个重新缩放的图像进行分开分析是否必要?(deeplabV1等模型就是将多个不同分辨率的图像作为训练样本的)
论文对上面两个问题进行分析并设计了这样一个模型架构,即全卷积神经网络+空洞卷积、前端模块+上下文模块,如下图所示:

前端模块就是fc-final之前的,之后的是上下文模块,看起来像个网络的堆叠,因为前端模块本质上是个改进过后的VGG16(将VGG-16最后两个poooling层移除,并且随后的卷积层被空洞卷积代替,pool4和pool5之间的空洞卷积的空洞率为2,在pool5之后的空洞卷积的空洞率为4),其本身就能独立完成语义分割任务而且效果不错。 而上下文模块旨在通过聚合多尺度的上下文信息来提高语义分割网络结构的性能,它接收的输入和输出的尺寸保持一致,所以可以在其他的模型中进行嵌入,具体地,一共有7层,每一层都采用具有不同空洞率的 3 × 3 3\times3 3×3卷积核进行空洞卷积。最后通过执行 1 × 1 × C 1\times1\times C 1×1×C的卷积核产生输出模块。特别地,基础上下文模块根据卷积的通道不同又分为两种形式:basic和large,本文C取64。
论文中实现的最好效果也需要全连接条件随机场作为后处理手段。
4. DeepLabV2-DeepLabV1+ASPP
Chen L C , Papandreou G , Kokkinos I , et al. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2016, 40(4):834-848.
DeepLabV2相较于V1,多了一个空洞卷积空间池化特征金字塔(ASPP),更关注多尺度目标的问题。ASPP进一步利用了空洞卷积,该模块结构如下所示:
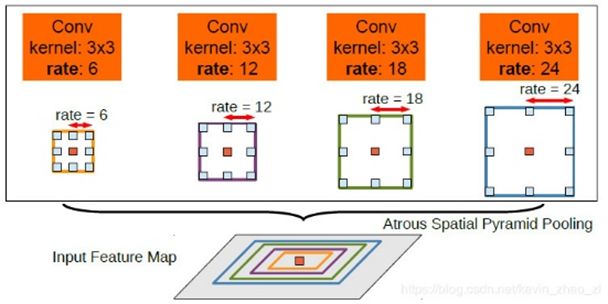
论文使用这个模块来进行多尺度语义的聚合,它抛弃了之前使用的方法,比如将输入进行多个尺度的缩放然后进行训练,或者是刚才提到的上下文模块的线性聚合。该模块先对相同的输入进行并行的不同采样率的空洞卷积然后进行特征融合,该版本的DeepLab中使用的空洞率是6、12、18、24。实际上这种空洞率的扩张卷积对显卡资源要求很高,速度也很慢。而且由于ResNet的出现,论文主干网络用了调整后的ResNet101,这就导致模型更加的“重”。
5. RefineNet-用于高分辨率图像语义分割的多路精细网络
论文提到的问题除了下采样过程中的图像细节丢失外,提到了空洞卷积的两个问题:
- 本质上是一种粗糙的欠采样
- 计算代价巨大
使用的架构包括:
- 全卷机神经网络(ResNet)
- 多路并行网络特征抽取
- 链式残差池化
重点看一下这种多路并行网络架构设计,这是一种很灵活的方式,具体有单路、双路级联、多路四级级联以及二级级联和四级级联的混合架构,架构分别如下图所示:
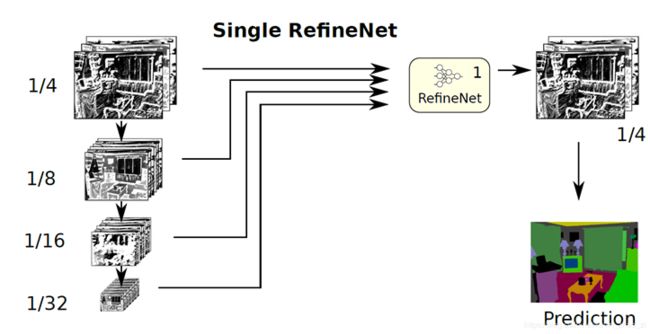



本质上是对原始图片进行了更多尺度的缩放,这模型训练起来也不简单。四种结构都有一个RefineNet模块,这个模块如下图所示:

其中,RCU是全卷积形式的ResNet;Multi-Resolution Fusion是对输入的同尺寸的特征图进行处理使其尺寸一致并融合;Chained Residual Pooling这个模块主要用于较大图像区域中捕获背景的上下文信息,实际上就是一个多重的残差连接,Output Convolutions主要用于产生带有分类概率的特征图。
6. PSPNet-金子塔型场景解析网络
Zhao H, Shi J, Qi X, et al. Pyramid Scene Parsing Network[C]. computer vision and pattern recognition, 2017: 6230-6239.
这篇论文并不是标准语义分割的模型,但是也差不多,其分析了四个问题:
- 缺乏对上下文关系的捕获【即各个像素的互相影响】
- 不能充分利用类别间的关系【比如水上出现的大概率的船而非汽车】
- 对不显眼的目标捕获能力弱【小的目标或者相似目标互相遮挡】
- 全局平均池化导致位置信息丢失【为了获得分类,基于FCN的模型多直接使用全局平均池化处理特征图】
基于这些问题,论文设计了如下图所示的模型架构,包括金字塔池化和更加有效的ResNet训练损失函数,模型架构如下图所示:

模型通过带有空洞卷积的ResNet作为主干网络提取特征图,大小是输入图像的1/8。经过金字塔池化模块来获取语义信息,使用四种不同的层级的金字塔并上采样将其融合为原始特征图大小。经过一个卷积层得到预测的输出。
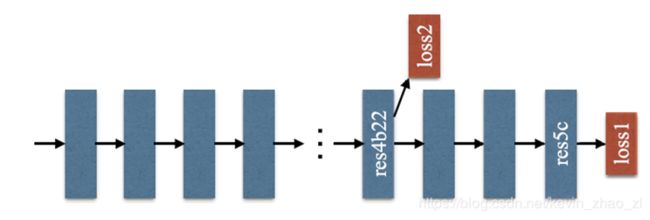
而第二点,更加有效的ResNet训练损失函数如下图所示,就是在ResNet101的基础上做了改进,除了使用后面的softmax分类做loss,额外的在第四阶段添加了一个辅助的loss,两个loss一起传播,使用不同的权重,共同优化参数。后续的实验证明这样做有利于快速收敛。
7. DeepLabV3-重新思考用于图像语义分割的空洞卷积
Chen L, Papandreou G, Schroff F, et al. Rethinking Atrous Convolution for Semantic Image Segmentation[J]. arXiv: Computer Vision and Pattern Recognition, 2017.
模型的架构重新在于:
- 改进的空洞卷积空间金字塔池化
- 抛弃全连接条件随机场
其中改进的金字塔池化,加入ImagePooling,就是一个全局池化,加大位置信息的权重,我理解是避免空洞卷积信息损失的问题,但是这一个系列的论文基于空洞卷积,所以,论文并不直说。论文抛弃了繁琐的后处理,使得模型能够端到端的训练、推断,并且在实现细节,包括学习率策略,批量正则化层,主干网络池化和空洞卷积都进行了一些列调整

8. DeepLabV3+ 用于图像语义分割的带有空洞卷积的编解码结构
Chen L, Zhu Y, Papandreou G, et al. Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation[C]. european conference on computer vision, 2018: 833-851.
论文将DeepLabV3作为编码模块,设计简单的解码模块进行上采样,提出编解码结构,论文结构如下图所示:

可以看到,这里其实还在解码器中加入了一个浅层特征,增加位置信息所占的权重。
论文为了加快推断,将Xception主干网络进行改进得到一个具有如下特征的主干网络:
- more layers
- 将所有的最大池化操作修改为带步长的深度可分离卷积,以便应用空洞可分离卷积
- 额外的BN层和RELU激活层附加在每一个3x3 DW Conv后
深度可分离卷积就是把标准卷积分解为一个Depthwise Conv和一个Pointwise Conv,其中DW独立地对每个输入通道做空间卷积,PW用于结合DW的输出。将空洞卷积与深度可分离卷积结合可以减少运算量的同时保持不错的效果。

简单看一下代码:
class DeepLab(nn.Module):
def __init__(self, backbone='resnet', output_stride=16, num_classes=21,
sync_bn=True, freeze_bn=False):
super(DeepLab, self).__init__()
if backbone == 'drn':
output_stride = 8
if sync_bn == True:
BatchNorm = SynchronizedBatchNorm2d
else:
BatchNorm = nn.BatchNorm2d
self.backbone = build_backbone(backbone, output_stride, BatchNorm)
self.aspp = build_aspp(backbone, output_stride, BatchNorm)
self.decoder = build_decoder(num_classes, backbone, BatchNorm)
if freeze_bn:
self.freeze_bn()
def forward(self, input):
x, low_level_feat = self.backbone(input)
x = self.aspp(x)
x = self.decoder(x, low_level_feat)
x = F.interpolate(x, size=input.size()[2:], mode='bilinear', align_corners=True)
return x
class Decoder(nn.Module):
def __init__(self, num_classes, backbone, BatchNorm):
super(Decoder, self).__init__()
if backbone == 'resnet' or backbone == 'drn':
low_level_inplanes = 256
elif backbone == 'xception':
low_level_inplanes = 128
elif backbone == 'mobilenet':
low_level_inplanes = 24
else:
raise NotImplementedError
self.conv1 = nn.Conv2d(low_level_inplanes, 48, 1, bias=False)
self.bn1 = BatchNorm(48)
self.relu = nn.ReLU()
self.last_conv = nn.Sequential(nn.Conv2d(304, 256, kernel_size=3, stride=1, padding=1, bias=False),
BatchNorm(256),
nn.ReLU(),
nn.Dropout(0.5),
nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=1, bias=False),
BatchNorm(256),
nn.ReLU(),
nn.Dropout(0.1),
nn.Conv2d(256, num_classes, kernel_size=1, stride=1))
self._init_weight()
class ASPP(nn.Module):
def __init__(self, backbone, output_stride, BatchNorm):
super(ASPP, self).__init__()
if backbone == 'drn':
inplanes = 512
elif backbone == 'mobilenet':
inplanes = 320
else:
inplanes = 2048
if output_stride == 16:
dilations = [1, 6, 12, 18]
elif output_stride == 8:
dilations = [1, 12, 24, 36]
else:
raise NotImplementedError
self.aspp1 = _ASPPModule(inplanes, 256, 1, padding=0, dilation=dilations[0], BatchNorm=BatchNorm)
self.aspp2 = _ASPPModule(inplanes, 256, 3, padding=dilations[1], dilation=dilations[1], BatchNorm=BatchNorm)
self.aspp3 = _ASPPModule(inplanes, 256, 3, padding=dilations[2], dilation=dilations[2], BatchNorm=BatchNorm)
self.aspp4 = _ASPPModule(inplanes, 256, 3, padding=dilations[3], dilation=dilations[3], BatchNorm=BatchNorm)
self.global_avg_pool = nn.Sequential(nn.AdaptiveAvgPool2d((1, 1)),
nn.Conv2d(inplanes, 256, 1, stride=1, bias=False),
BatchNorm(256),
nn.ReLU())
self.conv1 = nn.Conv2d(1280, 256, 1, bias=False)
self.bn1 = BatchNorm(256)
self.relu = nn.ReLU()
self.dropout = nn.Dropout(0.5)
self._init_weight()
def forward(self, x):
x1 = self.aspp1(x)
x2 = self.aspp2(x)
x3 = self.aspp3(x)
x4 = self.aspp4(x)
x5 = self.global_avg_pool(x)
x5 = F.interpolate(x5, size=x4.size()[2:], mode='bilinear', align_corners=True)
x = torch.cat((x1, x2, x3, x4, x5), dim=1)
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
return self.dropout(x)
9. 2019年的前沿展望
- BiSeNet:用于实时语义分割的双向分割网络
- 重新思考空洞卷积: 为弱监督和半监督语义分割设计的简捷方法
- FastFCN: 重新思考语义分割模型主干网络中的扩张卷积
- ConvCRFs:用于语义分割的卷积条件随机场
- DUpsampling-新型上采样模块:能够聚合丰富特征的数据相关型解码方式
- DFANet:用于实时语义分割的深层特征聚合网络
- DANet-集成双路注意力机制的场景分割网络
- 使用知识蒸馏的语义分割方法
- 联合传播数据增广+标签松弛提升边界精度=语义分割效果提升
- FickleNet-使用随机推理的用于弱监督和半监督的图像语义分割
- LEDNet-用于实时语义分割的轻量级编解码网络
- ACNet-使用注意力网络的RGBD图像语义分割方法
- Gated CRF Loss -一种用于弱监督图像语义分割的新型损失函数
欢迎扫描二维码关注微信公众号 深度学习与数学 [每天获取免费的大数据、AI等相关的学习资源、经典和最新的深度学习相关的论文研读,算法和其他互联网技能的学习,概率论、线性代数等高等数学知识的回顾]
