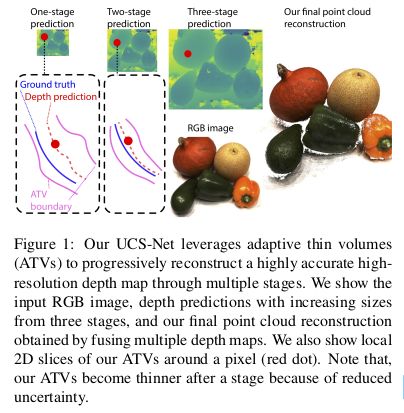
论文阅读《UCS-Net: Deep Stereo using Adaptive Thin Volume Representation with Uncertainty Awareness》
论文地址:https://arxiv.org/abs/1911.12012v1
源码地址:https://github.com/touristCheng/UCSNet
背景
现有的模型都是基于固定大小的深度假设空间进行深度值搜索,这种方法很难得到高分辨率的深度图,本文提出一种基于自适应分辨率代价体的深度预测方法,每层的深度假设空间是由上一层的像素预测的不确定性来得到;该模型主要分为三个部分:
- 基于平行窗口的代价体用于预测低分辨率的初始深度图;
- 使用两层ATV(adaptive thin volumes) 来不断精细化深度图,得到更高分辨率的深度图,AVT 模块构建的深度假设空间只包含较少的深度层,可以得到较高的计算效率;
- 使用基于方差的不确定性预估方式来构建自适应AVT层;
模型架构
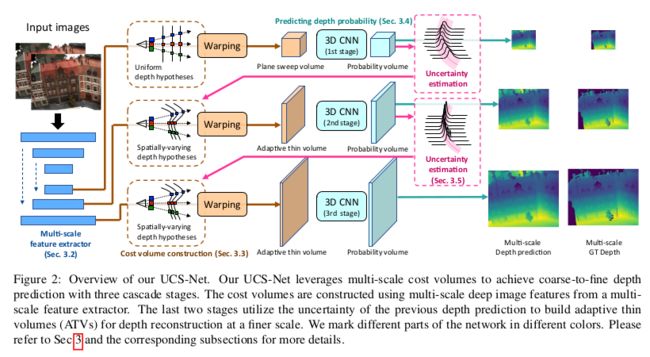
对于参考图像 I 1 ∈ R H × W I_1\in R^{H\times W} I1∈RH×W 与 N − 1 N-1 N−1 张源图像 { I i } i = 2 N ∈ R H × W \{I_i\}_{i=2}^N\in R^{H\times W} {Ii}i=2N∈RH×W ,先使用2D CNN提取三个尺度特征图;深度图预测通过三个阶段实现,利用多尺度图像特征预测多分辨率深度图。在三个尺度上都建立了匹配代价体,并使用3D CNN对代价提处理得到概率体,最后基于期望的形式回归得到深度图;为了实现高效的空间划分(紧凑的深度假设空间建立),利用上一个阶段的深度预测的不确定性来构造这一个阶段的自适应代价体;
多尺度特征提取
使用权值共享的 U-Net 结构提取多尺度特征,得到输入图像的特征金字塔: F i , 1 ∈ R 1 4 H × 1 4 W × 32 , F i , 2 ∈ R 1 2 H × 1 2 W × 16 , F i , 3 ∈ R H × W × 8 F_{i,1}\in R^{\frac{1}{4}H\times \frac{1}{4}W\times 32}, F_{i,2}\in R^{\frac{1}{2}H\times \frac{1}{2}W\times 16}, F_{i, 3}\in R^{H\times W\times 8} Fi,1∈R41H×41W×32,Fi,2∈R21H×21W×16,Fi,3∈RH×W×8 ;
代价体构建
将源视图的特征图根据相机参数warp回参考视图构建深度假设空间;单应性矩阵如式1所示:
H i ( d ) = K i [ R i , t i ] − 1 [ R 1 , t 1 ] K 1 (1) H_i (d) = K_i [R_i , t_i ]^{−1} [R_1 , t_1 ]K_1 \tag1 Hi(d)=Ki[Ri,ti]−1[R1,t1]K1(1)
用 L k , j ( x ) L_{k,j}(x) Lk,j(x) 表示第k个stage的深度值为第j层,像素点x的深度值; D k D_k Dk 代表第K个stage的深度假设层的层数,对于第一层,基于平行窗口的形式构建深度假设层: L 1 , j ( x ) = d j L_{1, j}(x)=d_j L1,j(x)=dj ,其中 d j d_j dj从 [ d m i n , d m a x ] [d_{min}, d_{max}] [dmin,dmax] 均匀采样而来, { d j } j = 1 D 1 \{d_j\}_{j=1}^{D_1} {dj}j=1D1,然后使用 H i ( d ) H_i (d) Hi(d) 来将源视图中的特征warp到参考视图,与MVS-Net相同,基于方差的形式构建代价体;对于第stage2与stage3,文中使用上一层的深度图预测不确定性来构建本层的自适应假设空间;
不确定性估计与自适应深度假设空间
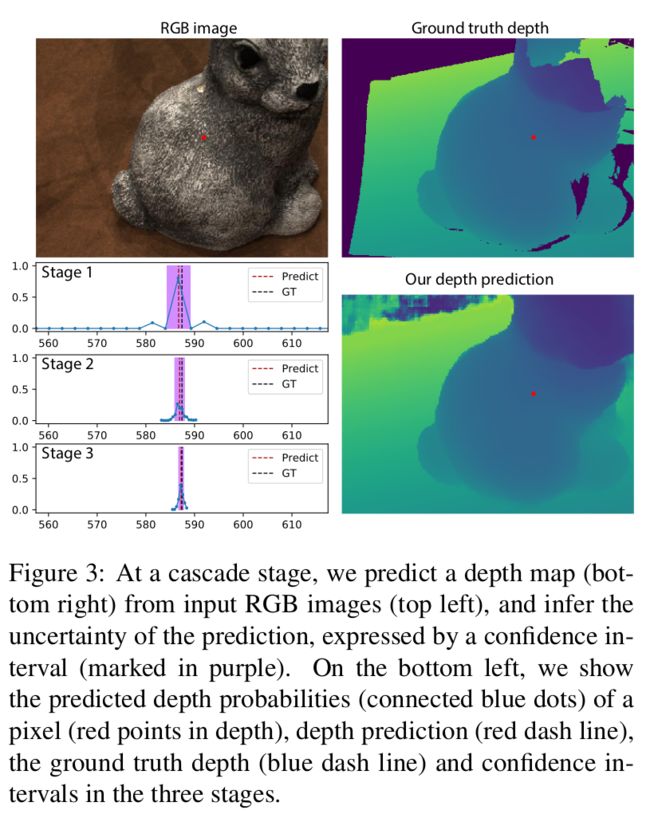
在每个stage,都使用 3D U-Net结构来对代价体处理,推断多视图像素间的匹配关系和预测深度概率分布,然后使用softmax得到概率体 P k , j P_{k, j} Pk,j,最后基于期望的形式计算深度图如式2所示:
L ^ k ( x ) = ∑ j = 1 D k L k , j ( x ) ⋅ P k , j ( x ) (2) \hat{\mathbf{L}}_{k}(x)=\sum_{j=1}^{D_{k}} \mathbf{L}_{k, j}(x) \cdot \mathbf{P}_{k, j}(x)\tag2 L^k(x)=j=1∑DkLk,j(x)⋅Pk,j(x)(2)
对于概率体 P P P ,使用分布的方差来进行不确定性估计,并使用估计结果构建下一层的AVT,深度分布的方差计算方式如式3所示:
V ^ k ( x ) = ∑ j = 1 D k P k , j ( x ) ⋅ ( L k , j ( x ) − L ^ k ( x ) ) 2 (3) \hat{\mathbf{V}}_{k}(x)=\sum_{j=1}^{D_{k}} \mathbf{P}_{k, j}(x) \cdot\left(\mathbf{L}_{k, j}(x)-\hat{\mathbf{L}}_{k}(x)\right)^{2}\tag3 V^k(x)=j=1∑DkPk,j(x)⋅(Lk,j(x)−L^k(x))2(3)
其中 L k , j \mathbf{L}_{k, j} Lk,j为深度假设值, L ^ k ( x ) \hat{\mathbf{L}}_{k}(x) L^k(x) 为深度预测值,标准差为 σ ^ k ( x ) = V ^ k \hat{\sigma}_{k}(x)=\sqrt{\hat{\mathbf{V}}_{k}} σ^k(x)=V^k,给定 x x x 点的深度预测值 L ^ k ( x ) \hat{\mathbf{L}}_{k}(x) L^k(x)与方差 σ ^ k ( x ) 2 \hat{\sigma}_{k}(x)^2 σ^k(x)2,使用一个基于方差的置信区间来衡量预测的不确定性如式4所示:
C k ( x ) = [ L ^ k ( x ) − λ σ ^ k ( x ) , L ^ k ( x ) + λ σ ^ k ( x ) ] (4) \mathbf{C}_{k}(x)=\left[\hat{\mathbf{L}}_{k}(x)-\lambda \hat{\sigma}_{k}(x), \hat{\mathbf{L}}_{k}(x)+\lambda \hat{\sigma}_{k}(x)\right]\tag4 Ck(x)=[L^k(x)−λσ^k(x),L^k(x)+λσ^k(x)](4)
其中 λ \lambda λ 是一个用来决定区间长度的参数;对于每个在stage k 的像素点 x x x ,从 C k C_k Ck 的区间中均匀采样 D k + 1 D_{k+1} Dk+1 个深度值作为 stage k+1 的深度假设层: L k + 1 , 1 ( x ) , L k + 1 , 2 ( x ) , . . . , L k + 1 , D k + 1 ( x ) L_{k+1, 1}(x),L_{k+1, 2}(x),...,L_{k+1, D_{k+1}}(x) Lk+1,1(x),Lk+1,2(x),...,Lk+1,Dk+1(x)
C k ( x ) C_{k}(x) Ck(x) 代表了 L ^ k ( x ) \hat{\mathbf{L}}_{k}(x) L^k(x) 的不确定性,这也决定了AVT中深度范围,上阶段的预测确定性越高,这一阶段的深度假设值间隔就越小(可以预测更细节的信息),在端对端的训练过程中不断优化区间.
从粗糙到精细的预测
本文在多个阶段不断精细化预测的深度图,文中每个stage的深度假设空间的层数为: D 1 = 160 , D 2 = 16 , D 3 = 8 D_1=160,D_2=16,D_3=8 D1=160,D2=16,D3=8.ATVs的尺寸为: W 4 × H 4 × 160 , W 2 × H 2 × 16 , H × W × 160 \frac{W}{4}\times \frac{H}{4}\times 160,\frac{W}{2}\times \frac{H}{2}\times 16,H\times W\times 160 4W×4H×160,2W×2H×16,H×W×160,由于最后两个尺度拥有较小层数的深度假设层,可以节省显存空间,提高了模型的运算效率.
损失函数
在3个stage上使用 L 1 L_1 L1 损失:
L = L 1 + L 2 + L 3 (5) L = L_1+L_2+L_3\tag5 L=L1+L2+L3(5)
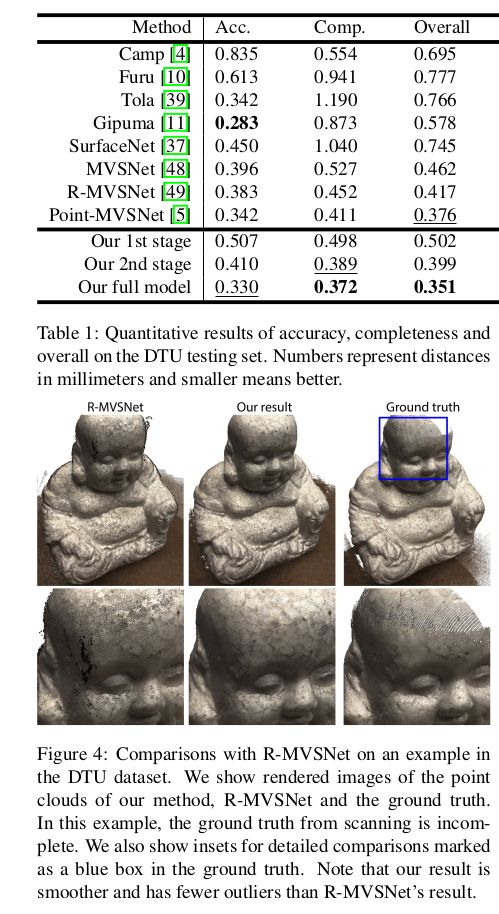
实验结果