r语言随机抽取数据框_R语言 第3章 R语言常用的数据管理(2)
缺失值分析
在R中,缺失值以符号NA(Not Available,不可用)表示。不可能出现的值(例如,被0除的结果)通过符号NaN(Not a Number,非数值)来表示。与SAS等程序不同,R中字符型和数值型数据使用的缺失值符号是相同的。
R提供了一些函数,用于识别包含缺失值的观测:
na.omit(x)删除含有缺失值的观测
complete.cases(x)返回一个逻辑向量,不存在缺失值的行的值为TRUE,存在缺失值的行的值为FALSE。
complete.cases(x)
返回一个逻辑向量,不存在缺失值的行的值为true,存在缺失值的行的值为FALSE
is.na(x)
返回一个与x等长的逻辑向量,并且由相应位置的元素是否是NA来决定这个逻辑向量相应位置的元素是TRUE还是FALSE。TRUE表示该位置的元素是缺失值。
anyNA(x, recursive = FALSE)
判断数据中是否存在缺失值,返回TRUE或FALSE值。若存在缺失值则返回TRUE,否则返回FALSE。
x1,is.na(x)[1] FALSE FALSE FALSE TRUE FALSEanyNA(x)[1] TRUE实例:检验数据集score中的缺失值,并删除score中含有缺失值的行。
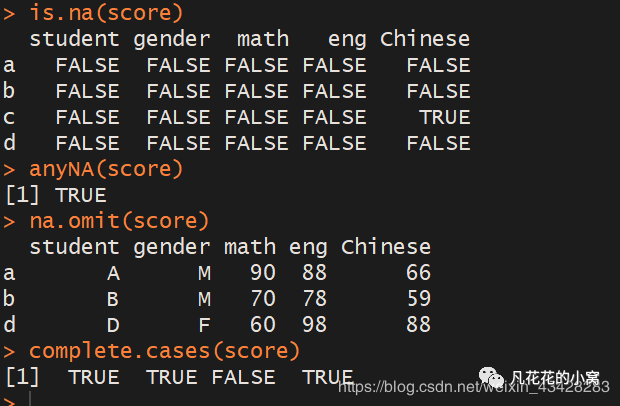
is.na(score) #检测缺失值,TURE表明该位置为缺失值anyNA(score) #检测score中是否存在缺失值na.omit(score) #删除score中存在缺失值的行complete.cases(score) #检测哪一行存在缺失值,FALSE表明该值对应的行存在缺失值数据排序
R中涉及排序的基本函数有order、sort和rank三个。下面看下其基本用法:
sort(x, na.last=NA,decreasing = FALSE, …)order(…, na.last = TRUE, decreasing = FALSE)rank(x, na.last = TRUE, ties.method = c(“average”, “first”, “random”, “max”, “min”))x表示需要排序的数据,decreasing表示是否按降序排序数据,为FALSE表示按从小到大的顺序排列,为TRUE表示按从大到小顺序排列。
na.last用来说明如何处理NA值,如果为NA表示在排序结果中缺失值将被删除,如果为FALSE,表示将数据缺失值放在前面,如果为TRUE,表示将数据缺失值放到最后。
ties.method表示所使用的排序算法。
Average表示对重复数据的秩取平均值作为这几个数据共同的秩;first表示重复数据中的位于前面的数据的秩取小,
位于后面的一次递增;random表示随机定义重复数据的秩;max表示以重复数据可能对应的最大秩作为这几个数据共同的秩;min表示重复数据可能对应的最小秩作为这几个数据共同的秩。
数据排序
下面通过例子,来更加深刻地理解这些问题:
> x > order(x)[1] 4 1 3 2> rank(x)[1] 2 4 3 1> sort(x)[1] 2 19 64 84从结果中可以很容易看出三个函数之间的区别,order函数返回的是排序数据所在向量中的索引,rank函数返回该值处于第几位(在统计学上称为秩),sort函数则返回的是按次排好的数据。
随机抽样
简单随机抽样可通过srswr()函数,srswor()和sample()函数实现。srswr()函数和srswor()函数在sampling包中,使用前需要先加载sampling包。下面看下其基本用法:
srswr(n, N) #在总体N中有放回地抽取n个样本srswor(n, N) #在总体N中无放回抽取n个样本sample(x,size,replace=FALSE,prob=NULL)srswr()函数可实现放回简单随机抽样;srswor()可函数实现不放回简单随机抽样;sample()函数可实现放回简单抽样和不放回简单随机抽样,同时也可对数据进行随机分组。
随机抽取x中的数据,size为抽取样本的数量,replace=FALSE为不放回简单随机抽样replace=TRUE为放回的简单随机抽样,如果使用sample()函数对数据进行分组x,为分组数,size为抽取样本数,prob为权重向量,replace=TRUE
●句子
●编程学习
●大学生生活图鉴
●JavaScript
●计算机网络原理
●计算机组成原理
●操作系统
●数据库系统概论
●数据结构
●英语
●R语言
●Linux
●人生哲学以及电竞
●云计算与人工智能
●新媒体运营以及各种资源分享
●明星电视剧社会现象娱乐



 仙女都在看点点点,赞和在看都在这儿!
仙女都在看点点点,赞和在看都在这儿!