【Xception】《Xception: Deep Learning with Depthwise Separable Convolutions》

CVPR-2017
(solo CVPR,???)
作者介绍

github:https://github.com/fchollet
linkedin:https://www.linkedin.com/in/fchollet
twitter:https://twitter.com/fchollet
google scholar:https://scholar.google.com/citations?user=VfYhf2wAAAAJ&hl=en
Xception 的作者也是 Keras 的作者。Francois Chollet 是真正的大神。
源码
caffe版:https://github.com/soeaver/caffe-model/blob/master/cls/inception/deploy_xception.prototxt
caffe代码可视化工具:http://ethereon.github.io/netscope/#/editor
在 CIFAR-10 上的小实验可以参考博客 【Keras-Xception】CIFAR-10
文章目录
- 作者介绍
- 源码
- 1 Background and Motivation
- 2 Advantages / Contributions
- 3 Innovations
- 4 Method
-
- 4.1 inception to xception
- 4.2 Xception(extreme inception) 和 depth-wise separable convolution 的不同
- 4.3 Xception
- 5 Datasets
- 6 Experiments
-
- 6.1 Optimization configuration
- 6.2 Classification performance
- 6.3 Size and speed
- 6.4 Effect of the residual connections
- 6.5 Effect of an intermediate activation after pointwise convolutions
- 7 Conclusion / Future work
- 8 References
1 Background and Motivation
CNN 不断发展,从 AlexNet、ZF、VGG 到 inception family
Inception family empirically appears to be capable of learning richer representations with less parameters.
作者三连问
- How do they work?
- how do they differ from regular convolutions?
- What design strategies come after Inception?
作者深入探究,提出 inception module 是 regular convolution 和 depth-wise separable convolution 之间的过度的观点,并将 inception module 引申到极致,提出 xception(extreme inception) 结构(也即 depth-wise separable convolution),在同 inception-v3 参数相仿的情况下,在 ImageNet 和 JFT 数据集上,优于 inception-v3!
2 Advantages / Contributions
- 提出一种解释,inception modules 是传统卷积和 depth-wise separable convolution 卷积的过渡阶段
- 提出的 xception 结构和 Inception V3 的相仿的 parameters,但是 performance 要稍微好些(ImageNet、JFT 数据集)
the performance gains are not due to increased capacity but rather to a more efficient use of model parameters.
传统 inception
- 1×1 cross-channel correlations
- 3×3 all correlations(cross-channel correlations + spatial correlations)
fundamental hypothesis behind Inception: cross-channel correlations and spatial correlations
- are sufficiently decoupled
- not to map them jointly
xception 或者 depth-wise separable convolution
- 3×3 spatial correlations
- 1×1 cross-channel correlations
3 Innovations
感觉最大的创新点不是提出 xception 结构, 而是认为 inception 是 regular convolution 与 depth-wise separable convolution 的过渡阶段!
出发点是从 spatial convolution 卷积的 channel space 分割情况来划分的,传统卷积 single-segment case,depth-wise convolution channels 是 one segment per channel,两个极端。inception 介于 两者之间!懂 group 卷积就很好理解了!一个所有人一组,一个一人一组,一个几个人一组!
多说一句,不得不佩服 google,实验资源相当的恐怖!
4 Method
4.1 inception to xception
1)inception v3
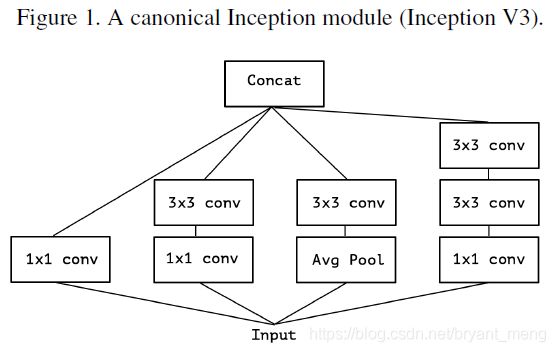
2)简化下 inception v3

3)和 figure 2 等价的形式,我个人的理解如我画的红色部分,图 2 input 经过 1x1 变成3 份,图 3 把 3份合起来,从 output channels 的角度看,我们把输入分成了三份,去进行后续的 3x3 操作!

4)引申一下,从output channels 的角度看,我们可以划分成极端的 channels number 份,接后续的 3x3 卷积!这样就相当于先 point-wise convolution,然后 depth-wise convolution,与 depth-wise separable convolution 的顺序正好相反,但是不影响,因为都是两者的堆叠形式!

4.2 Xception(extreme inception) 和 depth-wise separable convolution 的不同
1)depth-wise 和 point wise convolution 的顺序
extreme inception:先 1×1 再 3×3,depth-wise separable convolution 先 3×3 再 1×1
2)是否 non-linear activation
extreme inception 中,1x1 和 3x3 之间有 non-linear activation,depth-wise separable convolution 的 3×3 与 1×1没有 non-linear convolution!
第一种不同不影响,因为都是两者的堆叠形式,先后顺序影响不大,作者实现的时候用的 depth-wise separable convolution,在 keras 中为 SeparableConv2D https://keras.io/layers/convolutional/#separableconv2d
论文中说注意不要和数字图像处理中的 spatially separable convolution 混淆了,也简写成 separable convolution,指的是类似二维高斯可分离卷积这种吗?
4.3 Xception
36 layers 14 modules

注意两点:
1)上图中每一个 SeparableConv 后都接一个 BatchNormalization
2)所有 SeparableConv 的 depth_multiplier 参数都设置为1,也即 depth-wise convolution 的输入和输出 channels 相同,官方文档介绍如下:
depth-wise convolution output channels = input channels * depth_multiplier

https://keras.io/layers/convolutional/#separableconv2d
5 Datasets
- ImageNet:1000 classes (single-label classification task,1M+)
- JFT:17,000-class (multi-label classification task,350M)
- FastEval14k:6,000 classes(14,000 images with dense annotations,36.5 labels per image on average),评估 Mean Average Precision for top 100 predictions (MAP@100)
JFT:Google 内部数据集,300倍于 ImageNet(Hinton主导弄的)
6 Experiments
Xception 和 inception-v3 参数量相仿,trained on 60 NVIDIA K80 GPUs(哈哈,一块都用不起,60块,望洋兴叹)
60块 NVIDIA K80 GPUs ImageNet 实验跑3天,JFT 迭代 300M 次 a month,full convergence 3 month(……)
6.1 Optimization configuration
On ImageNet:
- Optimizer: SGD
- Momentum: 0.9
- Initial learning rate: 0.045
- Learning rate decay: decay of rate 0.94 every 2 epochs
On JFT:
- Optimizer: RMSprop
- Momentum: 0.9
- Initial learning rate: 0.001
- Learning rate decay: decay of rate 0.9 every 3,000,000 samples
这些 hyper parameters(包括没写的 weight decay、dropout) 是 inception-v3 最优的,Xception 也用同样的超参数,没有专门进行调整(suboptimal),inception-v3 还用了 auxiliary classifier(Auxiliary loss tower),Xception 没有使用这个。
总结, 作者表达的是,用 Xception 同 inception-v3 PK,什么要求都你说的算(优化策略,超参数),我们俩一个重量级(capacity 或者说 parameters),你(inception-v3)就是打不过我(Xception)!我的武艺(architecture)就是胜你一筹。
6.2 Classification performance
1)ImageNet solo


2)JFT solo
FC layers:two fully-connected layers of 4096 units each before the logistic regression layer



可以看出相比 inception-v3,Xception 在 JFT 数据集上的提升要大于在 ImageNet 数据集上的提升,作者的解释为,inception-v3 was developed with a focus on ImageNet and may thus be by design over-fit to this specific task.
6.3 Size and speed

没有 FC layer 的参数量,training steps per second is reported on ImageNet with 60 K80 GPUs running synchronous gradient descent.
6.4 Effect of the residual connections
在 ImageNet 上

有些不厚道(uncharitable)——作者说的,因为 non-residual 和 residual 都用的是 residual 的 optimization parameters,但是还是可以看出,redisual 结构的优势。在搭建 depth-wise separable convolution 的时候, residual 结构不是必要的,作者也跑了 VGG + depth-wise separable convolution non-residual 的结构,在与 inception-v3 相同的参数量下,在 ImageNet 和 JFT 上的结果要优于 Inception-v3
6.5 Effect of an intermediate activation after pointwise convolutions
在 depth-wise convolution 和 point-wise convolution 直接不加 activation funciton 效果最好,作者分析 possibly due to a loss of information,激活对有深度(channels 不为1)的 feature map 有效,对 1 channel 的可能有害。

7 Conclusion / Future work
We noted earlier the existence of a discrete spectrum between regular convolutions and depthwise separable convolutions, parametrized by the number of independent channel space segments used for performing spatial convolutions.
从传统的 convolution,到 depth-wise separable convolution,存在一个 discrete spectrum,就是 depth-wise convolution 的对象有多深,传统 convolution 对应的深度为 input channels,depth-wise separable convolution 对应的深度为 1,我们没有理由相信 depth-wise separable convolution 是最优的,可能最优的存在于 discrete spectrum 之上,all to 1 之间……
Q1:synchronous gradient descent(ImageNet) 和 asynchronous gradient descent(JFT)的细节和区别
Q2:如何解释 Xception-Non-residual 一开始 accuracy 停滞不前,或者说泛一点,跑自己的 model 时候,遇见这种情况怎么解决(accuracy 在开始的一些 epoch 下一直很低,例如类别分之一,然后某个 epoch 突然开始正常了),什么原因导致的呢?
8 References
【1】无需数学背景,读懂ResNet、Inception和Xception三大变革性架构