RGB-D salient object detection: A survey 综述
摘要:显著对象检测是模拟场景中最重要物体的视觉感知,已广泛应用于各种计算机视觉任务。现在,深度传感器的出现意味着深度地图可以很容易地捕获;这种额外的空间信息可以提高显著目标检测的性能。虽然在过去的几年中,已经提出了各种基于RGB-D的具有良好性能的显著目标检测模型,但对这些模型和该领域的挑战仍然缺乏深入的理解。本文从不同的角度对基于RGB-D的显著对象检测模型进行了全面的调查,并详细回顾了相关的基准数据集。此外,由于光场也可以提供深度图,我们也回顾了来自该领域的显著对象检测模型和流行的基准数据集。此外,为了研究现有模型检测显著对象的能力,我们对几个具有代表性的基于RGB-D的显著对象检测模型进行了基于属性的综合评估。最后,我们讨论了几个挑战和解决问题。
question:
RGB-D综述
1、introduction
1.1背景
突出对象(显著性目标)检测的目标是定位给定场景[1]中视觉上最突出的对象。它在立体匹配[2]、立体匹配[2]、图像理解[3]、共显著性检测[4]、动作识别[5]、视频检测与分割[6-9]、语义分割[10,11]、医学图像分割[12-14]、目标跟踪[15,16]、人再识别[17,18]、伪装对象检测[19]、图像检索[20]等一系列现实应用中发挥着关键作用。虽然在过去的几年里,显著的物体检测领域取得了重大进展[21-35],但当面对具有挑战性的因素,如复杂的背景或不同的照明条件时,仍有改进的空间。克服这些挑战的一种方法是使用深度图,它提供与RGB图像互补的空间信息,并且由于深度传感器(如微软Kinect)的现成可用性而变得更容易捕获。
近年来,基于RGB-D的显著对象检测受到了越来越多的关注,[38,45]开发了多种方法。早期基于RGB-D的显著对象检测模型倾向于提取手工制作的特征,然后融合RGB图像和深度图。例如,Lang等人。[46]是第一个基于RGB-D的显著性目标检测的工作,它利用高斯混合模型来模拟深度诱导的显著性的分布。Ciptadi等人。[47]从深度测量中提取了三维布局和形状特征。有几种方法利用不同区域之间的深度差异来测量深度对比度。在参考文献中。[51]是一种包括局部对比、全局对比和背景对比在内的多背景对比模型,用于使用深度图检测显著对象。然而,更重要的是,这项工作也为显著的对象检测提供了第一个大规模的RGB-D数据集。尽管使用手工制作功能的传统方法很有效,但它们的低级功能往往是为了限制泛化能力,而且它们缺乏对复杂场景所需的高级推理。为了解决这些限制,我们已经开发了几种基于深度学习的RGB-D显著目标检测方法[38],并提高了性能。DF[52]是第一个将深度学习技术引入基于RGB-D的显著目标检测任务的模型。最近,各种基于深度学习的模型[41-44,53-55]都专注于利用有效的多模态相关性和多尺度或水平信息来提高显著对象检测性能。为了更清楚地描述基于RGB-D的显著目标检测领域的进展,我们在图中提供了一个简短的年表。 2.在本文中,我们对基于RGB-D的显著对象检测进行了全面的调查,旨在全面涵盖用于该任务的模型的各个方面,并为未来工作的挑战和开放的方向提供深刻的讨论。我们还回顾了一个相关的主题,光场显著目标检测,因为光场也可以提供额外的信息(包括焦点堆栈、全聚焦图像和深度图),以提高显著目标检测的性能。此外,我们对现有的基于RGB-D的显著目标检测模型进行了全面的比较评价,并讨论了其主要优点。

fig.1 使用两种经典模型:DCMC[36]和SE[37]对样本图像进行显著对象预测,同时使用的是7种最先进的深度模型:D3Net[38],SSF[39],A2dele[40],S2MA[41],ICNet[42],JL-DCF[43],和UC-Net[44]。
1.2Related reviews and surveys
几项调查考虑了显著的物体检测。例如,Borji等人[59]对35种最先进的非深度学习显著性检测方法进行了定量评估。Cong等人[60]综述了几种不同的显著性检测模型,包括基于RGB-D的显著目标检测、共显著性检测和视频显著目标检测。Zhang等人[61]提供了共显著性检测的概述,并回顾了其历史,并总结了该领域的几种基准算法。Han等人[62]回顾了在显著对象检测方面的最新进展,包括模型、基准数据集和评估度量,并讨论了一般对象检测、显著对象检测和类别特定对象检测之间的潜在联系。Nguyen等人[63]审查与显著性应用相关的各种工作,并提供了对显著性的作用的深刻的讨论。Borji等人[64]对显著对象检测的最新进展进行了全面的综述,并讨论了相关主题,包括一般场景分割、固定预测的显著性和对象提案的生成。Fan等人。[1]提供了几种最先进的基于cnn的显著目标检测模型的全面评估,并提出了一个高质量的显著目标检测数据集,SOC(见:http://dpfan.net/socbenchmark/)。赵等人[65]详细回顾了各种基于深度学习的对象检测模型和算法,以及各种特定的任务,包括显著的目标检测。Wang等人[66]专注于回顾基于深度学习的显著对象检测模型。与以往的显著目标检测调查不同,在本文中,我们重点回顾了基于RGB-D的显著目标检测模型和基准数据集。
 1.3 Contributions and organization
1.3 Contributions and organization
我们的贡献和组织是:第一次对基于RGB-D的显著对象检测模型进行系统的回顾。
-
我们将现有的RGB-D显著对象检测模型分为传统或深度方法、融合方法、单流或多流方法和注意感知方法(第2节);
-
对该领域常用的9个RGB-D数据集的回顾,给出了每个数据集的详细信息(第3节)。
-
我们还对几个具有代表性的基于RGB-D的显著目标检测模型提供了全面的、基于属性的评估(第5节);
-
光场显著目标检测模型和基准数据集的首次调查(第4节);
-
深入研究了基于RGB-D的显著目标检测所面临的挑战,以及显著目标检测与其他主题之间的关系,阐明了未来研究的潜在方向(第6节);
-
结论见第7节
2 RGB-D based salient object detection models
2.1 Approach
在过去的几年里,几种基于RGB-D的显著目标检测方法;它们提供了良好的性能。表1-4总结了这些模型。更多的信息可在http://dpfan.net/d3netbenchmark/上找到。回顾这些基于RGB-d的显著目标检测,详细地,我们从不同的角度考虑如下。(1)作为传统的还是深度模型,根据是使用手动特征还是深度特征进行特征提取。这有助于读者了解RGB-D显著对象检测模型的历史发展。(2)根据融合模型:在这个任务中有效地融合RGB和深度图像是至关重要的,因此我们回顾了不同的融合策略来了解它们的有效性。(3)作为单流或多流模型:使用单个流可以减少参数的数量,但最终结果可能不是最优的;多个流可能需要更多的参数。这有助于理解不同模型的计算量和准确性之间的平衡。(4)根据注意意识。注意机制已被广泛应用于各种视觉任务,包括显著的目标检测。我们回顾了RGB-D显著对象检测的相关工作,以分析不同的模型如何使用注意意识。注意模块的替代设计可能在未来的工作中有用。
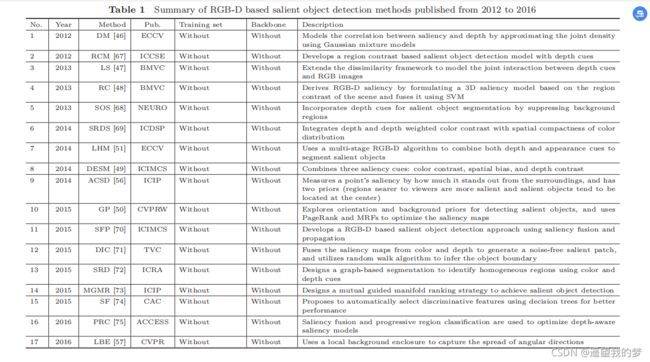
 2.2传统和深度模型
2.2传统和深度模型
2.2.1传统模型
传统模型使用深度线索,一些有用的属性,如边界、形状属性、表面法线等,可以通过探索来提高对复杂场景中突出物体的识别。在过去的几年里,许多基于手工制作特性的传统RGB-D模型已经被开发出来[36、37、47-51、56、57、69-71、75、82-84、95]。例如,参考文献中的早期工作。[47]专注于建模从RGB图像和深度图生成的布局和形状特征之间的交互建模。参考文献中的代表性工作。[51]开发了一种新的多阶段RGB-D模型,并构建了第一个大规模的RGB-D基准数据集,NLPR。
2.2.2 Deep models
由于手工制作特征的表达能力有限,上述传统方法的显著目标检测性能不理想。为了解决这个问题,一些研究已经转向深度神经网络(DNNs)来融合RGB-D数据[39、40、42-44、52-55、83、93、94、96、102-106、111-113、117-119、137]。这些模型可以学习高级表示,以探索RGB图像和深度线索之间的复杂相关性,以提高显著的目标检测性能。接下来,我们将回顾一些有代表性的作品。
DF[52]开发了一种新的卷积神经网络(CNN),将不同的低水平显著性线索整合到层次特征中,有效地定位RGB-D图像中的显著性区域。这是第一个基于cnn的RGB-d显著目标检测模型。然而,它利用了一个较浅的架构来学习显著性地图。
PCF[92]提出了一个互补感知的融合模块来集成跨模态和跨层次的特征表示。它可以通过显式地使用跨模态和级连接以及模态和级的监督来有效地利用互补信息,从而有效地减少融合的模糊性。
CTMF[58]使用一个计算模型从RGB-d场景中识别显著对象,利用cnn学习RGB图像和深度线索的高级表示,同时利用互补关系和联合表示。该模型将模型的结构从源域(RGB图像)转移到目标域(深度图)。
CPFP[53]提出了一种对比增强网络来生成增强图,并提出了一个流体锥体集成模块来分层有效地融合跨模态信息。由于深度线索往往会受到噪声的影响,一个特征增强的模块被用来学习增强的深度线索,以有效地提高显著的目标检测性能。
UC-Net[44]提出了一种基于概率RGB-D的显著对象检测网络,通过条件变分自动编码器来建模人类注释的不确定性。它通过采样学习到的潜在空间,为每个输入图像生成多个显著性映射。这是第一个研究基于RGB-D的显著目标检测的不确定性的工作,并受到数据标记过程的启发。它利用不同的显著性映射来提高最终的显著性目标检测性能。
2.3 Fusion approach
对于基于RGB-D的显著目标检测模型,有效融合RGB图像和深度图具有重要意义。现有的融合策略可以分为早期融合、多尺度融合或晚期融合,正如我们现在所解释的那样;也见图。 3.
2.3.1 Early fusion
早期基于融合的方法有两种方式之一:(i)RGB图像和深度地图直接集成形成一个四通道输入[50,51,87,96],我们称之为输入融合,或者(ii)RGB和深度图像首先输入单独的网络,它们的低级表示被组合成一个联合表示,然后输入后续网络,用于进一步的显著性地图预测[52]。我们称之为早期的特征融合。
2.3.2 Late fusion
基于晚期融合晚期融合的方法也可以进一步分为两类:(i)采用两个并行网络流分别学习RGB和深度数据的高级特征,然后连接起来,生成最终的显著性预测[48,58,106]。我们称之为后来的特征融合。(ii)利用两个并行网络流获得RGB图像和深度线索的独立显著性图,然后将两个显著性图连接起来,得到最终的预测图[108]。这被称为后期结果融合。
2.3.3 Multi-scale fusion
为了有效地探索RGB图像与深度图之间的相关性,有几种方法提出了一种多尺度融合策略[42,43,55,109,116,122,123,128]。这些模型可以分为两类。首先学习跨模态交互,然后将它们融合到一个特征学习网络中。例如,Chen等人。
[55]开发了一个多尺度、多路径融合网络,以集成RGB图像和深度图,并采用跨模态交互(MMCI)模块。该方法将跨模态交互引入多层,可以为增强深度流的学习提供额外的梯度,并能够探索低级和高级表示之间的互补性。第二类将来自RGB图像和深度图的特征融合到不同的层中,然后将它们集成到一个解码器网络中(例如,通过跳过连接),以生成最终的显著性检测图。现在我们简要讨论了一些有代表性的工作。
ICNet[42]提出了一种信息转换高级特性的交互转换模块,在该模型中,引入了一种跨模态深度加权组合(CDC)块来增强在不同层次上具有深度特征的RGB特征。
DPANet[109]使用一个门控的多模态注意(GMA)模块来利用远程依赖关系。GMA模块可以利用空间注意机制提取出最具区分性的特征。该模型还利用门函数控制跨模态信息的融合速率,可以减少不可靠的深度线索引起的一些影响。
BiANet[116]采用多尺度的双侧注意模块(MBAM)从多层中捕获更好的全局信息。
JL-DCF[43]将深度图像视为彩色图像的特例,并使用共享的CNN进行RGB和深度特征提取。它还提出了一种密集合作的融合策略,以有效地结合从不同的模式中学习到的特征。
BBS-Net[128]使用分叉主干策略(BBS)将多层次特征表示划分为教师和学生特征,并开发了一个深度增强模块(DEM),从空间和通道视图中探索深度图中的信息部分。
2.4 Single- and multi-stream models
2.4.1 Single-stream models
一些基于RGB-D的显著性目标检测工作[52,53,83,87,93,96,102]集中于单流架构,以实现显著性预测。这些模型通常融合输入通道或特征学习部分融合RGB图像和深度信息。例如,MDSF[87]采用多尺度判别显著性融合框架作为显著目标检测模型,计算三个层次的四种特征,然后融合得到最终的显著性图。BED[83]利用CNN架构来集成自下而上和自上而下的信息,用于显著的目标检测。它包含多个特性,包括背景外壳分布(BBD)和低级别深度图(例如,深度直方图距离和深度对比度),以提高显著的目标检测性能。PDNet[102]使用一个附属网络提取基于深度的特征,它充分利用深度信息来辅助主流网络。
2.4.2 Multi-stream models
双流模型[54,106,111]有两个独立的分支来分别处理RGB图像和深度线索,并且通常生成不同的高级特征或显著性图,然后在两个流的中间阶段或最后合并它们。最近的基于深度学习的模型[40,42,45,55,92,104,109,112,114,117]利用这种双流架构,多个模型捕获了多层RGB图像和深度线索之间的相关性。此外,一些模型利用多流结构[38,103],然后设计不同的融合模块,有效地融合RGB和深度信息,以利用它们的相关性。
2.5 Attention models
现有的基于RGB-D的显著对象检测方法通常以相同的方式使用提取的特征平等地对待所有区域,而忽略了不同区域可以对最终的预测图做出不同贡献的事实。这些方法很容易受到杂乱的背景的影响。此外,有些方法要么认为RGB图像和深度图具有相同的状态,要么过度依赖于深度信息。这使得他们无法考虑不同领域(RGB图像或深度线索)的重要性。为了克服这些问题,一些方法引入了注意机制来衡量不同区域或领域的重要性。ASIF-Net[117]利用交织融合从RGB图像和深度线索中获取互补信息,并通过深度监督的注意机制对显著性区域进行权重。AttNet[111]引入了注意图,以区分突出物体和背景区域,以减少某些低质量深度线索的负面影响。TANet[103]利用自下而上和自下而下的RGB图像和深度图制定了一个多模态融合框架。然后引入了一个通道级注意模块,有效地融合了来自不同模式和层次的互补信息。
2.6 Open-source implementations
表5提供了本调查中回顾的基于RGB-D的显著对象检测模型的可用开源实现。进一步的源代码将会出现继续更新:https://github.com/taozh2017/RGBD-sodsouply
3 RGB-D datasets
随着基于RGB-D的显著目标检测的快速发展,过去几年已经构建了各种数据集。表6总结了9个流行的RGB-D数据集。4显示了来自这些数据集的图像的示例(包括RGB图像、深度图和注释)。接下来,我们将提供每个数据集的详细信息。
STERE[139]。作者从Flickr(http://www.flickr.com/)、NVIDIA3D视觉Live(http://photos.3dvisionlive.com/)和立体图像画廊(http://www.stereophotography.com/)中收集了1250张立体图像。每个图像中最显著的对象都由三个用户进行了注释。然后根据重叠的突出区域对所有带有注释的图像进行排序,并选择前1000张图像来构建最终的数据集。这是该领域首次收集的立体图像。
GIT[47]由80张彩色和深度图像组成,在现实世界的家庭环境中使用移动操作器机器人收集。每个图像都根据其对象的像素级分割进行注释
DES[49]包含135张室内RGB-D图像,由Kinect拍摄,分辨率为640×640。在收集该数据集时,三个用户被要求在每个图像中标记显著的对象,重叠的标记区域被视为地面真相。
NLPR[51]由1000张RGB图像和相应的深度图组成,由标准的微软Kinect获得。该数据集包括一系列在室外和室内放置的位置,如办公室、超市、校园、街道等。
LFSD[140]包括使用Lytro光场相机收集的100个光场,包括60个室内场景和40个室外场景。为了标记这个数据集,三个人被要求手动分割突出区域;当三个结果的重叠部分超过90%时,分割后的结果被认为是地面事实。
NJUD[56]由1985年从互联网上收集的立体声图像对、3D电影和由富士W3立体声相机拍摄的照片组成。
SSD[85]使用三部立体声电影构建,包括室内和室外场景。它包含80个样本;每张图像的分辨率为960×1080。
DUT-RGBD[137]由800个室内场景和400个室外场景以及相应的深度图像组成。该数据集提供了几个具有挑战性的因素:多个和透明的对象、复杂的背景、与背景相似的前景和低强度环境。
SIP[38]由929张带注释的高分辨率图像组成,每个图像中有多个突出的人物。在这个数据集中,深度地图是使用智能手机(华为Mate10)捕获的。该数据集涵盖了不同的场景和各种具有挑战性的因素,并使用像素级的地面真相进行了注释。详细的数据集统计分析(包括中心偏差、对象的大小、背景对象、对象边界条件和突出对象的数量)可以在参考文献中找到。[38]。
4 Saliency detection on light fields
4.1 Models
4.1.1 Background
显著对象检测方法可根据输入数据类型分为三类:RGB、RGB-D或光域[141]。我们已经回顾了基于RGB-D的显著目标检测模型,其中深度图提供了几何信息,从而在一定程度上提高了显著目标检测性能。然而,不准确或低质量的深度图往往会降低性能。为了克服这一问题,人们提出了利用光场捕获的丰富信息的光场突出物体检测方法。具体来说,光场数据可以提供全聚焦图像、焦点堆栈和粗糙的深度图[137]。表7提供了光场突出物体检测工作的总结;我们现在对它们进行更详细的回顾。
4.1.2 Traditional and deep models
光场显著物体检测的经典模型通常使用超像素级手工制作的特性[137、140、142-147、149、155]。早期的工作[140,147]表明,光场独特的重聚焦能力可以提供有用的聚焦、深度和物体识别线索,从而使用光场数据建立几个显著的物体检测模型。例如,Zhang等人。[143]利用一组焦切片进行计算一个背景先验,然后将其与一个位置先验结合起来,以进行显著的目标检测。Wang等人。[146]提出了一种两阶段贝叶斯融合模型来整合多重对比,以提高显著的目标检测性能。近年来,几种基于深度学习的光场突出目标检测模型也被开发出来[141151-154156],取得了显著的性能。在参考文献中。[151],一个专注的循环CNN来融合所有焦点切片,同时使用对抗的例子增加数据多样性,以增强模型的鲁棒性。Zhang等人。[153]开发了一种面向内存的用于光场检测的显著目标的解码器,它利用高级信息以自上而下的方式融合多层次特征来指导低层次特征选择。LFNet[141]采用一种新的集成模块,根据光场数据的贡献融合其特征,并捕获场景的空间结构,以提高显著的目标检测性能。
4.2 Refinement-based models
几种改进策略已被用来加强邻域约束或减少显著对象检测的多种模式的同质性。例如,在参考文献中。[142],显著性字典使用估计的显著性映射进行细化。MA方法[145]采用两阶段的显著性细化策略来生成最终的预测图,从而使相邻的超像素获得相似的显著性值。LFNet[141]提出了一个有效的细化模块来减少不同模式之间的同质性,并细化它们的差异性。
4.3 Light field data
五个具有代表性的数据集在现有的光场显著目标检测方法中得到了广泛的应用,正如我们现在所述。LFSD[140]由100个不同场景的光场组成,空间分辨率为360×360,使用Lytro光场相机拍摄。该数据集包含60个室内场景和40个室外场景,大多数场景只包含一个突出的对象。三个人被要求手动分割每个图像中的突出区域,当所有三个分割结果重叠超过90%时,确定地面真相发生。(https://sites.duke.edu/nianyi/publication/saliencydetection-on-light-field/)
HFUT[145]由使用Lytro相机拍摄的255个光场组成。大多数场景包含在不同位置和尺度上的多个对象,具有复杂的背景杂波。(https://github.com/铅笔张/HFUT-激光数据集)
DUTLF-FS[151]包括1465个样本,1000个用作训练集,465个用于测试集。每幅图像的分辨率为600×400。该数据集包含了几个挑战,包括突出物体和杂乱的背景之间的低对比度,多个断开的突出物体,以及黑暗和明亮的照明条件。(https://github.com/OIPLab-DUT/ICCV2019数据场显著性)
DUTLF-MV[152]包括1580个样本,1100个用于训练,其余用于测试。图像由LytroIllum相机拍摄,每个光场由多视图图像和相应的地面真相组成。(https://github.com/OIPLab-DUT/IJCAI2019-Deep-Light-Field-Driven-Saliency-Detectionfrom-A-Single-View)LytroIllum
LytroIllum[156]由640个光场和相应的每像素地面真实显著性图组成。它包括几个具有挑战性的因素,例如,不一致的光照条件,以及在类似或杂乱的背景中存在的小的突出物体。(https://github.com/pencilzhang/MAClight-field-saliency-net)
5 Model evaluation and analysis
5.1 Evaluation metrics
我们简要回顾了几个显著对象检测评估的流行指标:精度召回(PR)、Fmeasth[59,157]、平均绝对误差(MAE)[158]、结构测量(s-度量)[159]和增强对齐度量(E-度量)[160]。



为了深入了解最好的六种模型,我们将在下面讨论它们的主要优势。D3Net[38]由两个关键组件组成,一个流特征学习模块和一个深度净化器单元。流特征学习模块有三个子网络:RgbNet、RgbdNet和DepthNet。RgbNet和DepthNet分别用于学习RGB和深度图像的高级特征表示,而RgbdNet则用于学习它们的融合表示。这个三重特征学习模块可以捕获特定的信息以及模式之间的相关性。平衡这两个方面对于多模态学习非常重要,有助于提高显著的目标检测性能。深度净化器单元作为一个门,明确地去除低质量的深度图,其他现有的方法往往没有考虑其影响。由于低质量的深度图会阻碍RGB图像和深度图的融合,深度净化器单元可以确保有效的多模态融合,以实现鲁棒的显著目标检测。
JL-DCF[43]有两个关键组件,用于联合学习(JL)和密集合作融合(DCF)。具体来说,JL模块用于学习鲁棒显著性特征,而DCF模块用于互补特征发现。该方法采用中间融合策略,从RGB图像和深度图中提取深度层次特征,有效地利用跨模态互补性来实现准确的预测。
UC-Net[44]不是产生单一的显著性预测,而是通过将特征输出空间的分布建模为基于RGB-D图像的生成模型来产生多种预测。因为每个人在标记显著性地图时都有特定的偏好,所以当使用确定性学习管道对图像对生成单个显著性地图时,可能无法捕获显著性的随机特征。该模型中的策略可以考虑到人类在显著性注释中的不确定性。此外,深度图还会受到噪声的影响。直接融合RGB图像和深度图可以导致网络适应这种噪声。因此,利用作为辅助组件的深度校正网络,利用语义引导损失细化深度信息。所有这些关键组件都有助于提高显著的目标检测性能。
在SSF[39]中,开发了一个互补交互模块(CIM),以探索判别跨模态互补性和融合跨模态特征,其中引入区域注意,以补充每个模态的丰富边界信息。补偿感知损失被用来提高网络对不可靠深度图中的硬样本的置信度。这些关键组件使所提出的模型能够有效地探索和建立跨模态特征表示的互补性,同时减少了低质量深度图的负面影响,提高了显著的目标检测性能。
ICNet[42]使用一个信息转换模块来交互式和自适应式地探索高级RGB和深度特性之间的相关性。引入了一个跨模态深度加权组合块来增强RGB和深度特征之间的差异,确保特征得到不同的处理。ICNet利用跨模态特征的互补性,并探索跨层次特征的连续性,这两者都有助于实现准确的预测。
S2MA[41]使用自相互注意模块(SAM)融合RGB和深度图像,整合自我注意和相互注意,以更准确地传播上下文。SAM可以提供来自多模态数据的额外互补信息,以提高显著的对象检测性能,克服了仅使用自我注意的局限性,即单一的模态。为了减少低质量深度线索的影响(如噪声),我们使用了一种选择机制来重新加权相互注意。这可以过滤掉不可靠的信息,从而导致更准确的显著性预测。
6 Challenges and open directions
6.1 Effects of imperfect depth
6.1.1 Effects of low-quality depth maps
具有详细空间信息的深度图已被证明有助于检测杂乱背景下的显著物体,而深度质量直接影响显著的物体检测性能。由于深度传感器的性质,深度图的质量在不同的场景中差异很大,这在试图减少低质量深度图的影响时带来了挑战。然而,大多数现有的方法都是直接融合RGB图像和来自深度图的原始原始数据,而没有考虑低质量深度图的影响。也有一些值得注意的例外。例如,在参考文献中。[53]提出了一种对比度增强的网络来学习增强的深度图,其对比度比原始深度要高得多。在参考文献中。[39]是一种补偿感知损失,旨在更多地关注包含不可靠深度信息的硬样本。D3Net[38]使用深度净化器单元将深度图划分为合理的或低质量的。它还可以作为一个过滤掉低质量深度地图的大门。具有详细空间信息的深度图已被证明有助于检测杂乱背景下的显著物体,而深度质量直接影响显著的物体检测性能。由于深度传感器的性质,深度图的质量在不同的场景中差异很大,这在试图减少低质量深度图的影响时带来了挑战。然而,大多数现有的方法都是直接融合RGB图像和来自深度图的原始原始数据,而没有考虑低质量深度图的影响。也有一些值得注意的例外。例如,在参考文献中。[53]提出了一种对比度增强的网络来学习增强的深度图,其对比度比原始深度要高得多。在参考文献中。[39]是一种补偿感知损失,旨在更多地关注包含不可靠深度信息的硬样本。D3Net[38]使用深度净化器单元将深度图划分为合理的或低质量的。它还可以作为一个过滤掉低质量深度地图的大门。开发一个端到端框架,可以实现深度增强或在多模态融合过程中自配地分配低权值,这将更有助于降低低质量深度图的影响,提高显著的目标检测性能。
6.1.2 Incomplete depth maps
在RGB-D数据集中,由于采集设备的限制,不可避免地会出现一些低质量的深度图。如前所述,几种深度增强算法已经被用来提高深度图的质量。然而,遭受严重噪声或边缘模糊的深度图往往被丢弃。在这种情况下,我们有完整的RGB图像,但有些样本没有深度图,这与不完整的多视图模态学习问题类似[166-170]。我们可以把这个问题称为不完全基于RGB-d的显著对象检测。由于目前的模型只关注使用完整的RGB图像和深度图的显著目标检测,我们认为这可能是RGB-d显著目标检测的一个新方向。
6.1.3 Depth estimation
深度估计为恢复高质量深度和克服低质量深度图的影响提供了一个有效的解决方案。已经开发了各种深度估计方法[171-174],可以将其引入到基于RGB-D的显著目标检测任务中,以提高性能。
6.2 Effective fusion strategies
6.2.1 Adversarial learning-based fusion
有效融合RGB图像和深度图对于基于RGB-d的显著目标检测具有重要意义。现有的模型通常采用不同的融合策略(早期融合、中期融合或晚期融合)来利用RGB图像和深度图之间的相关性。近年来,生成对抗网络(GANs)[175]在显著性检测任务[176,177]中得到了广泛的关注。在常见的基于gan的显著性对象检测模型中,生成器将RGB图像作为输入并生成相应的显著性映射,而鉴别器决定给定的图像是合成图像还是地面真值。基于GAN的模型可以很容易地扩展到RGB-D显著目标检测,由于其具有优越的特征学习能力,有助于提高性能。此外,GANs还可以用于学习RGB图像和深度地图[114]的共同特征表示,这有助于实现特征或显著性地图融合,进一步提高显著的目标检测性能。
6.2.2 Attention-induced fusion
注意机制已广泛应用于各种基于深度学习的任务[178-181],允许网络选择性地注意区域子集,以提取强大和有区别的特征。共同注意机制也被发展来探索多种模式之间的潜在相关性。它们在视觉问题回答[182,183]和视频对象分割[184]中得到了广泛的研究。因此,对于基于RGB-D的显著目标检测任务,我们也可以开发基于注意力的融合算法来利用RGB图像和深度线索之间的相关性来提高性能。
6.3 Different supervision strategies
现有的RGB-D模型通常使用完全监督的策略来学习显著性预测模型。然而,注释像素级显著性映射是一个繁琐而耗时的过程。为了缓解这一问题,人们对弱监督学习和半监督学习的兴趣越来越大,这些学习已被应用于显著的目标检测[185-189]。通过利用图像级标签[185]和伪像素级注释[188,190],还可以将半、弱监督引入到RGB-D显著对象检测中,以提高检测性能。此外,[191,192]的一些研究表明,使用自我监督预先训练的模型可以有效地用来获得更好的性能。因此,我们可以以自监督的方式对大量注释的RGB图像训练显著性预测模型,然后将预先训练好的模型转移到RGBD显著性目标检测任务中。
6.5 Model design for real-world scenarios
一些智能手机可以捕捉深度地图(例如,使用SIP数据集中的图像捕获的是华为Mate10)。因此,对智能设备上的现实应用进行显著的对象检测是可行的。然而,大多数现有的方法都包括复杂的深度dnn,以提高模型容量和更好的性能,从而防止它们直接应用于此类平台。为了克服这一点,模型压缩[195,196]技术可以用于学习紧凑的基于RGB-D的显著目标检测模型,具有良好的检测精度。此外,JL-DCF[43]利用一个共享网络,使用RGB和深度视图来定位显著对象,这大大减少了模型参数,使实际应用成为可行
6.6 Extension to RGB-T
除了RGB-d显著目标检测外,还有其他几种方法融合不同的方式进行更好的检测,如RGB-T显著目标检测,它集成了RGB和热红外数据。热红外摄像机可以捕捉任何物体发出的热辐射,使热红外图像对光照条件[197]不敏感。因此,热图像可以提供补充信息,以改善当显著物体的图像遭受不同的光、眩光或阴影时,对显著物体的检测。一些RGB-T模型[197-205]和数据集(VT821[199]、VT1000[203]和VT5000[205])在过去几年中已经被提出。与RGB-D显著目标检测一样,RGB-T显著目标检测的关键目标是融合RGB和热红外图像,并利用这两种模式之间的相关性。因此,几种先进的RGB-D显著目标检测中的多模态融合技术可以扩展到RGB-T显著目标检测任务。