如何正确使用机器学习中的训练集、验证集和测试集?
王树义
读完需要
19
分钟速读仅需7分钟
训练集、验证集和测试集,林林总总的数据集合类型,到底该怎么选、怎么用?看过这篇教程后,你就能游刃有余地处理它们了。

1
问题
审稿的时候,不止一次,我遇到作者错误使用数据集合跑模型准确率,并和他人成果比较的情况。
他们的研究创意有的很新颖,应用价值较高,工作可能也做了着实不少。
但因对比方法错误,得出来的结果,不具备说服力。几乎全部都需要返工。
这里,我帮你梳理一下,该怎么使用不同的数据集合:
训练集(training set)
验证集(validation set)
测试集(test set)
目的只有一个——避免你踩同样的坑。
其实这个问题,咱们之前的教程文章,已有涉及。
《如何用 Python 和深度迁移学习做文本分类?》一文中,我曾经给你布置了一个类似的问题。
在文章的末尾,我们对比了当时近期研究中, Yelp 情感分类的最佳结果。
下表来自于:Shen, D., Wang, G., Wang, W., Min, M. R., Su, Q., Zhang, Y., ... & Carin, L. (2018). Baseline needs more love: On simple word-embedding-based models and associated pooling mechanisms. arXiv preprint arXiv:1805.09843.
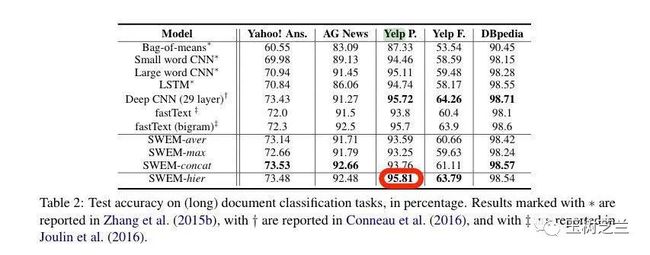
注意这里最高的准确率(Accuracy)数值,是 95.81 。
我们当时的模型,在验证集上,可以获得的准确率,是这个样子的:
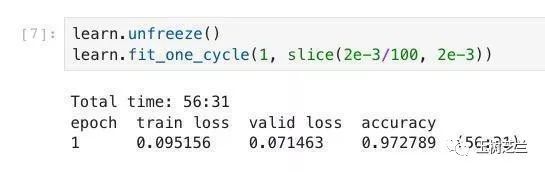
97.28%,着实不低啊!
于是我问你:
咱们这种对比,是否科学?
你当时的答案是什么?
这么久过去了,又看了那么多新的教程和论文,你的答案发生变化了吗?
现在咱们公布一下答案吧。
不科学。
为什么?
因为对比方法有问题。
2
方法
原文中有这样一句:
这里数据集只提供了训练集和“测试集”,因此我们把这个“测试集”当做验证集来使用。
作为演示,数据集咱们想怎么用,就可以怎么用。
甚至你把测试集拿来做训练,然后在训练集上跑测试,都没有人管。
但是写学术论文,声称你的模型优于已有研究,却绝不能这么草率。
注意,比较模型效能数值结果时,你只能拿不同的模型,在同样的测试集上面比。
测试集不同,当然不可以。
但模型A用测试集,模型B用验证集(与A的测试集数据完全一致)比,可以吗?
很多人就会混淆了,觉得没问题啊。既然数据都一样,管它叫做什么名称呢?
可是请你注意,哪怕A模型用的测试集,就是B模型用的验证集,你也不能把这两个集合跑出来的结果放在一起比较。
因为这是作弊。
你可能觉得我这样说,颇有些吹毛求疵的意味。
咱们下面就来重新梳理一下,不同数据集合的作用。
希望你因此能看清楚,这种似乎过于严苛的要求,其实是很有道理的。
咱们从测试集开始谈,继而是验证集,最后是训练集。
这样“倒过来说”的好处,是会让你理解起来,更加透彻。
先说测试集吧。
3
测试
只有在同样的测试集上,两个(或以上)模型的对比才有效。
这就如同参加高考,两个人考同样一张卷子,分数才能对比。
甲拿A地区的卷子,考了600分,乙拿B地区的卷子,考了580分。你能不能说,甲比乙成绩高?
不行吧。
为了让大家更易于比较自己的模型效果,许多不同领域的数据集,都已开放了。而且开放的时候,都会给你指明,哪些数据用于训练,哪些用于测试。
以 Yelp 数据为例。
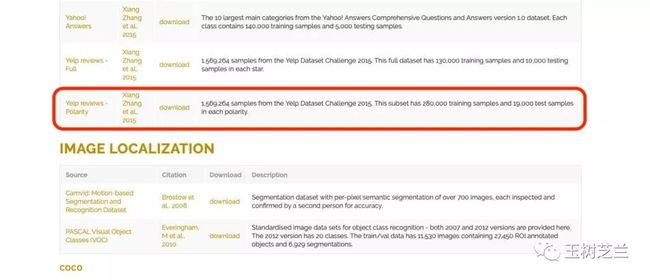
在 AWS 上存储的 fast.ai 公开数据集中,训练集和测试集都已为你准备好。
你不需要自己进行划分。
大家达成共识,做研究、写论文,都用这个测试集来比拼,就可以。
所以,如果你的研究,是靠着比别人的模型效果来说事儿,那就一定先要弄明白对方的测试集是什么。
但是,这个听起来很容易达成的目标,实践中却很容易遇到困难。
因为有的人写论文,喜欢把数据和代码藏着掖着,生怕别人用了去。
他们一般只提一下,是在某个公开数据集上切了一部分出来,作为测试集。
测试数据集不发布,切分方法(包括工具)和随机种子选取办法也不公开。
这是非常不靠谱的行为,纯属自娱自乐。
作为严肃的审稿人,根本就不应该允许这样的研究发表。
因为机器学习研究的数据集不开放,便基本上没有可重复性(Reproducibility)。
如果你没有办法精确重复他的模型训练和测试过程,那么他想汇报多高的准确率,就纯凭个人爱好了。
当然,我们不是活在理想世界的。
你在某一个领域,用机器学习做应用研究的时候,面对这种无法重复已发表论文的情境,该怎么办?
直接用他声称的结果与你的实际运行结果比较,你可能是在追逐海市蜃楼。累到气喘吁吁,甚至怀疑自我的程度,也徒劳无功。
忽视它?
也不行。
审稿人那关你过不去。
人家会说,某某研究跟你用的是一样的数据,准确率已经达到98%,你的才96%,有什么发表的意义呢?
看,左右为难不是?
其实解决办法很简单。
不要考虑对方声称达到了多高准确率。把他提供给你的数据全集,自行切分。之后复现对方的模型,重新跑。
模型架构,一般都是要求汇报的,所以这几乎不是问题。
至于这种复现,越是复杂的模型,我越推荐你用 PyTorch 。
之后把你的模型,和复现的对方模型在同样的测试集上做对比,就可以了。
当然,论文里要写上一句:
由于某篇文章未提供代码与具体数据切分说明,带来可重复性问题,我们不得不独立复现了其模型,并在测试集完全一致的情况下,进行了比对。
这里多说一句,一定要保证你自己的研究,是可重复的。
不要怕公布你的代码和数据。它们不是你的独门暗器,而是支撑你研究的凭据。
回看我们前面提到的 Yelp 公开数据的例子。
这时候你会发现一个奇怪的问题——为什么它只有训练集和测试集?
我们一直反复提到的验证集哪里去了?
4
验证
验证集,就如同高考的模拟考试。
不同于高考,模拟考只是你调整自己状态的指示器而已。
状态不够满意,你可以继续调整。
当然,参加过高考的同学都有经验——这种调整的结果(从模拟考到高考),有可能更好,也有可能更糟糕。
回到机器学习上,那就是测试集上检验的,是你最终模型的性能。
什么叫“最终模型”?
就是你参加高考时候的状态。包括你当时的知识储备、情绪心态,以及当天的外部环境(温度、湿度、东西是否带齐)等。
最终模型,只有一个。
就如同每年的高考,你只能参加一回。
考成什么样儿,就是什么样。
而验证集上跑的,实际上却是一个模型集合,集合的大小,你可能数都数不过来。
因为这里存在着超参数(hyper-parameter)设置的问题。不同超参数组合,就对应着不同的潜在模型。
验证集的存在,是为了从这一堆可能的模型中,帮你表现最好的那个。
注意这里的表现,是指在验证集上的表现。
好比说,有个超参数叫做训练轮数(epochs)。
在同样的训练集上,训练3轮和训练10轮,结果可能是不一样的模型。它们的参数并不相同。
那么到底是训练3轮好,还是10轮好?
或者二者都不好,应该训练6轮?
这种决策,就需要在训练后,在验证集上“是骡子是马牵出来溜溜”。
如果发现训练3轮效果更好,那么就应该丢弃掉训练6轮、10轮的潜在模型,只用训练3轮的结果。
这对应着一种机器学习正则化(Regularization)方式——提早停止训练(early stopping)。
其他的超参数选取,你也可以举一反三。总之就是按照验证集的效果,来选超参数,从而决定最终模型。
下一步,自然就是把它交给测试集,去检验。这个我们前面已经详细讲解过了。
至于这个最终选择模型,在新数据集(测试集)上表现如何,没人能打包票。
所以,回到咱们之前的问题。在《如何用 Python 和深度迁移学习做文本分类?》一文中,我故意用验证集上筛选出的最好模型,在验证集上跑出来分数,当成是测试成绩,这显然是不妥当的。
你不能把同样的题做他个三五遍,然后从中找最高分去跟别人比。
即便你的模拟考,用的是别人的高考真题。两张卷子完全一样,也没有说服力。
所以你看,验证集的目的,不是比拼最终模型效果的。
因此,怎么设定验证集,划分多少数据做验证,其实是每个研究者需要独立作出的决策,不应该强行设定为一致。
这就如同我们不会在高考前去检查每个考生,是否做过一样多的模拟试卷,且试卷内容也要一致。
极端点儿说,即便一个考生没参加过模拟考,可高考成绩突出,你也不能不算他的成绩,对吧?
不过,讲到这里,我们就得要把训练集拿进来,一起说说了。
5
训练
如果测试集是高考试卷,验证集是模拟考试卷,那么训练集呢?
大概包括很多东西,例如作业题、练习题。
另外,我们上高三那时候(噫吁嚱,已经上个世纪的事儿了),每周有“统练”,每月有“月考”。也都可以划定在训练集的范畴。
减负这么多年以后,现在的高中生应该没有那么辛苦了吧?真羡慕他们。
这样一对比,你大概能了解这几个集合之间本应有的关系。
学生平时练题,最希望的,就是考试能碰到原题,这样就可以保证不必动脑,却做出正确答案。
所以,出模拟考卷时,老师尽量要保证不要出现学生平时练过的题目,否则无法正确估量学生目前的复习备考状态,噪声过高容易误事儿。
验证集和训练集,应该是不交叠的。这样选择模型的时候,才可以避免被数据交叠的因素干扰。
每个学校的模拟考,却都恨不得能押中高考的题。这样可以保证本校学生在高考中,可以“见多识广”,取得更高分数。
高考出卷子的老师,就必须尽力保证题目是全新的,以筛选出有能力的学生,而不是为高校选拔一批“见过题目,并且记住了标准答案”的学生。
因此,测试集应该既不同于训练集,又不同于验证集。
换句话说,三个数据集合,最好都没有重叠。
学生应该学会举一反三,学会的是知识和规律。
用知识和规律,去处理新的问题。
我们对机器模型的期许,其实也一样。
在学术论文中,你见到的大部分用于机器学习模型对比的公开数据集(例如 fast.ai 公开数据集中的 Yelp, IMDB, ImageNet 等),都符合这一要求。
然而,例外肯定是有的。
例如我在 INFO 5731 课程里面给学生布置的某期末项目备选项,来源于某学术类数据科学竞赛,目标是社交媒体医学名词归一化。
其中就有数据,既出现在了训练集,又出现在了验证集,甚至测试集里也会有。
面对这种问题,你该怎么办?
你怎么判断自己的模型,究竟是强行记住了答案,还是掌握了文本中的规律?
这个问题,作为思考题留给你。
我希望在知识星球中和热爱学习的你,做进一步讨论。
另外的一个问题,是训练集要不要和别人的完全一致?
一般来说,如果你要强调自己的模型优于其他人,那么就要保证是在同样的训练集上训练出来。
回顾深度学习的三大要素:
数据(Data)
架构(Architecture)
损失(Loss)
如果你的训练数据,比别人多得多,那么模型自然见多识广。
对于深度学习而言,如果训练数据丰富,就可以显著避免过拟合(Overfitting)的发生。
GPT-2 模型,就是因为具备了海量 Reddit 数据做训练,才能傲视其他语言模型(Language Model),甚至以安全为理由,拒绝开放模型。
但是这时候,你跟别人横向比较,似乎就不大公平了。
你的架构设计,未必更好。假使对方用同样多的数据训练,结果可能不必你差,甚至会更优。
这就如同一个复读了5年的学生甲,充分利用每一分每一秒,做了比应届生乙多5倍的卷子。结果在高考的时候,甲比乙多考了1分(同一张卷子)。
你能说甲比乙更有学习能力,学习效果更好吗?
6
小结
这篇教程里,我为你梳理了机器学习中常见的三种不同数据集类别,即:
训练集
验证集
测试集
咱们一一分析了其作用,并且用“考试”这个大多数人都参加过,且容易理解的例子做了诠释。
希望读过本文之后,你的概念架构更为清晰,不再会误用它们,避免给自己的研究挖坑。
祝深度学习愉快,论文发表顺利哦!
7
作业
这里给你留一道思考题:
有的时候,你看到有人把训练集切分固定的一部分,作为验证集。但是另一些时候,你会看到有人采用“交叉验证”的方式,即每一轮训练,都动态轮转着,把一部分的数据,作为验证集。对吧?
那么问题来了,什么样的情况下,你应该采用第一种方式,即固定分配验证集?什么样的情况下,你应该采用“交叉验证”方式呢?后者的优势和缺点,又各是什么呢?
欢迎你留言回复,写下自己的判断标准与原因阐述。咱们一起交流讨论。
8
征稿
One more thing ……
这里还有个征稿启事。
国际学术期刊 Information Discovery and Delivery 要做一期关于 “Information Discovery with Machine Intelligence for Language” 的特刊(Special Issue)。

本人是客座编辑(guest editor)之一。另外两位分别是:
我在北得克萨斯大学(University of North Texas)的同事 Dr. Alexis Palmer 教授
南京理工大学章成志教授

征稿的主题包括但不限于:
Language Modeling for Information Retrieval
Transfer Learning for Text Classification
Word and Character Representations for Cross-Lingual Analysis
Information Extraction and Knowledge Graph Building
Discourse Analysis at Sentence Level and Beyond
Synthetic Text Data for Machine Learning Purposes
User Modeling and Information Recommendation based on Text Analysis
Semantic Analysis with Machine Learning
Other applications of CL/NLP for Information Discovery
Other related topics
具体的征稿启事(Call for Paper),请查看 Emerald 期刊官网的这个链接(http://dwz.win/c2Q)。
作为本专栏的老读者,欢迎你,及你所在的团队踊跃投稿哦。
如果你不巧并不从事上述研究方向(机器学习、自然语言处理和计算语言学等),也希望你能帮个忙,转发这个消息给你身边的研究者,让他们有机会成为我们特刊的作者。
谢谢!
9
延伸阅读
你可能也会对以下话题感兴趣。点击链接就可以查看。
如何在《玉树芝兰》快速找到你想要的教程文章?
如何快速写作论文初稿?
如何选研究题目?
数据科学入门后,该做什么?
文科生如何理解循环神经网络(RNN)?
《文科生数据科学上手指南》分享
喜欢别忘了点赞,并且把它转发给你身边有需要的朋友。
别忘了,赞赏就是力量。

由于微信公众号外部链接的限制,文中的部分链接可能无法正确打开。如有需要,请点击文末的“阅读原文”按钮,访问可以正常显示外链的版本。
订阅我的微信公众号“玉树芝兰”,第一时间免费收到文章更新。别忘了加星标,以免错过新推送提示。

如果你对 Python 与数据科学感兴趣,希望能与其他热爱学习的小伙伴一起讨论切磋,答疑解惑,欢迎加入知识星球。
题图: Photo by Jonah Pettrich on Unsplash