Transformer 在计算机视觉领域疯狂“内卷”
继『Transformer 杀疯了,图像去雨、人脸幻构、风格迁移、语义分割等通通上分』之后,Transformer 在计算机视觉领域继续疯狂“内卷”。
01
CAT: Cross Attention in Vision Transformer
来自快手&北邮
Transformer 的计算量大仍是一大问题。
方案:在 Transformer 提出新的 attention 机制:Cross Attention,在 image patch 内部而不是整个图像中交替使用 attention,以捕捉局部信息;在从单通道特征图中划分出来的 image patches 之间应用 attention,以捕捉全局信息。这两种操作的计算量都比 Transformer 中的标准 self-attention 少。通过交替应用 attention 内部 patch 和 patchs 之间,实现 cross attention(交叉注意),以较低的计算成本保持性能,并为其他视觉任务建立一个称为 Cross Attention Transformer(CAT)的层次网络。
结果:在 ImageNet-1K 上达到了最先进的水平,并提高了其他方法在 COCO 和 ADE20K 上的性能,证明该网络有望称为通用骨干网。
论文链接:https://arxiv.org/abs/2106.05786
项目链接:https://github.com/linhezheng19/CAT

标签:Transformer+Attention
02
Keeping Your Eye on the Ball: Trajectory Attention in Video Transformers
来自Facebook&牛津大学
提出一个新的用于视频数据的通用注意块,它沿着隐式确定的运动轨迹聚集信息,为模型提供了现实的归纳偏置。用一种新的注意力近似算法进一步解决它对输入大小的二次依赖问题,大大降低了内存要求,而内存是 transformer 模型的最大瓶颈。由此,在多个基准数据集上获得新的 SOTA。
论文链接:https://arxiv.org/abs/2106.05392
项目链接:https://github.com/facebookresearch/Motionformer
主页链接:https://facebookresearch.github.io/Motionformer/

标签:Transformer+视频数据
03
MST: Masked Self-Supervised Transformer for Visual Representation
来自中科院&国科大&商汤&加利福尼亚大学洛杉矶分校
问题:目前视觉自监督学习的两个问题:缺乏局部信息提取和空间信息的损失。
方案:提出一个全新的基于 Transformer 的自监督学习方法:Masked Self-supervised(MST),可以明确地捕捉图像的局部上下文,同时保留全局语义信息。具体来说,是受 NLP 中 Masked Language Modeling(MLM)的启发,提出基于多头自注意图的 masked token 策略。在不破坏自监督学习的关键结构情况下,动态地遮蔽局部 patches 的一些 tokens。更重要的是,被屏蔽的tokens 与剩余的 tokens 一起被全局图像解码器进一步恢复,这保留了图像的空间信息,对下游的密集预测任务更加友好。
结果:在多个数据集上的实验证明了所提方法的有效性和通用性。例如,MST 在DeiT-S 上通过线性评估,仅使用 300 个 epoch 的预训练就达到了 76.9% 的Top-1 精度,比相同 epoch 的监督方法高出 0.4%,比 DINO 高出1.0%。对于密集预测任务,MST 在 MS COCO 目标检测上也取得了 42.7% 的 mAP,在Cityscapes 分割上仅用 100 个 epoch 预训练就取得了 74.04% 的 mIoU。
论文链接:https://arxiv.org/abs/2106.05656

标签:Transformer+自监督学习
04
Space-time Mixing Attention for Video Transformer
来自三星
问题:Transformer 在视频识别中应用,由于对时间信息的额外建模而引起巨大的计算开销。
方案:提出 Video Transformer 模型,其复杂性与视频序列中的帧数呈线性关系,因此与基于图像的 Transformer 模型相比,没有引起任何开销。为了实现上述目标,作者将所提出模型对 Video Transformer 中使用的全时空注意力做了两个 approximations:将时间注意力限制在一个局部的时间窗口,并利用Transformer 的深度来获得视频序列的全时间覆盖;使用有效的时空混合来共同关注空间和时间位置,而不会在仅有的空间注意模型上引起任何额外的成本。以及如何整合2个非常轻量级的全局时空关注机制,以最小的计算成本提供额外的准确性改进。
结果:通过实验证明所提出模型在最流行的视频识别数据集上产生了非常高的识别精度,同时比其他的 Video Transformer 模型明显更有效率。代码将被提供。
论文链接:https://arxiv.org/abs/2106.05968
项目链接:coming

标签:Transformer+视频识别
05
LocalTrans: A Multiscale Local Transformer Network for Cross-Resolution Homography Estimation
来自清华大学&东北大学&北京理工大学
目的:跨分辨率图像对齐是 multiscale gigapixel photography(多尺度十亿级像素摄影)中的关键问题,要求使用具有较大分辨率差距的图像来估计Homography matrix(单应性矩阵)。当前已有的 deep homography 方法将输入的图像或特征串联起来,忽略了它们之间对应关系的明确表述,引起在跨分辨率挑战中准确性下降。
方案:将跨分辨率 homography estimation(单应性估计)视为一个多模态问题,提出一个嵌入多尺度结构的 local transformer 网络,明确学习多模态输入之间的对应关系,即不同分辨率的输入图像。local transformer 专门针对特征中的每个位置采用了局部注意图。将 local transformer 与多尺度结构相结合,该网络能够有效而准确地捕获长短距离的对应关系。
结果:在 MS-COCO 数据集和真实拍摄的跨分辨率数据集上的实验表明,所提出的网络优于现有最先进的基于特征和基于深度学习的单应性估计方法,并且能够在 10 倍分辨率差距下准确地对齐图像。
论文链接:https://arxiv.org/abs/2106.04067

标签:Transformer+图像对齐
06
Fully Transformer Networks for Semantic ImageSegmentation
来自百度等
目的:研究基于纯 Transformer 的方法在图像分割中可以取得怎样的效果。
方案:提出基于全 Transformer 网络(FTN)的编码器-解码器,用于语义图像分割。具体来说,先是设计一个 Pyramid Group Transformer(PGT),作为逐步学习分层特征的编码器,同时降低标准 visual transformer(ViT)的计算复杂性。其次,设计一个 Feature Pyramid Transformer(FPT)来融合来自 PGT 编码器多个层次的语义级和空间级信息,用于语义图像分割。
结果:在多个具有挑战性的语义分割基准上取得新的 SOTA,包括 PASCAL Context、ADE20K 和 COCO-Stuff。源代码将发布。
论文链接:https://arxiv.org/abs/2106.04108
项目链接:coming

标签:语义分割+Transformer
07
MViT: Mask Vision Transformer for Facial Expression Recognition in the wild
来自中国科学技术大学
方案:本次工作首次提出基于纯 Transformer 的 mask vision transformer (MViT),用于自然的人脸表情识别。由两个模块组成:一个是基于 transformer 的 mask 生成网络(MGN),用于生成能够过滤掉复杂背景和人脸图像遮挡的 mask ;另一个是动态重新标记模块,用于纠正自然 FER 数据集中的错误标签。
结果:MViT 在 RAF-DB、FERPlus、AffectNet-7 上的实验结果分别以 88.62%、89.22%、64.57% 的成绩超越了最先进的方法,在 AffectNet-8 上取得了 61.40%的可比结果。
论文链接:https://arxiv.org/abs/2106.04520

标签:Transformer+人脸表情识别
08
Scaling Vision Transformers
来自谷歌
基于注意力的神经网络,如 Vision Transformer(ViT)最近在许多计算机视觉基准上取得了不错的结果。
研究目的:Scale 是 Vision Transformers 取得成果的主要因素,本文主要来探讨一下在 Vision Transformers 中的 Scale 方式。
方案:对 ViT 模型和数据的规模进行了扩展,包括向上和向下,并描述了错误率、数据和计算之间的关系。在此过程中,完善了 ViT 的架构和训练,减少了内存消耗,提高了模型的准确性。
结果:成功地训练了一个具有 20亿 个参数的 ViT 模型,在 ImageNet 上达到了90.45% 的 top-1 准确率。该模型在小样本学习中也表现良好,例如,在ImageNet 上,每类只有 10 个例子,就能达到 84.86% 的 top-1 准确率。
论文链接:https://arxiv.org/abs/2106.04560

标签:Transformer
09
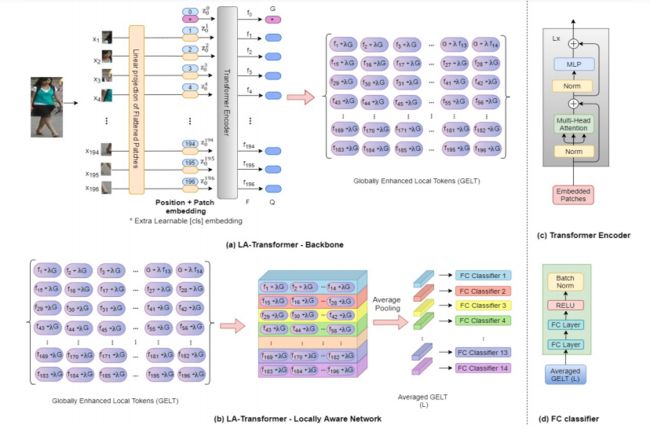
Person Re-Identification with a Locally Aware Transformer
来自马里兰大学巴尔的摩分校
当前大多数人员重新别技术都是基于卷积神经网络(CNN),但 Vision Transformers 也已开始在各种目标识别任务中取代纯 CNN。Vision Transformers 的主要输出是一个全局分类 token,但 Vision Transformers 也产生局部tokens,其中包含关于图像局部区域的额外信息。而利用这些局部 tokens 来提高分类精度的技术是一个活跃的研究领域。
本次工作,作者提出 Locally Aware Transformer(LA-Transformer),采用基于 Parts 的卷积基线(PCB)启发的策略,将全局增强的局部分类 tokens 聚集到 √ N 分类器的集合中,其中 N 是 patches 的数量。另外一个创新之处在于,加入了 blockwise fine-tuning,进一步提高重识别的准确性。
带有 blockwise fine-tuning 的 LA-Transformer 在 Market-1501 和 CUHK03 数据集上分别取得了 98.27% 和98.7% 的 rank-1 准确率,标准偏差为 0.13。作者称在论文撰写时超过了所有其他最先进的已公布方法。
论文链接:https://arxiv.org/abs/2106.03720
标签:NurIPS 2021+Transformer+人员重识别
10
Refiner: Refining Self-attention for Vision Transformers
来自新加坡国立大学
与 CNN 相比,Vision Transformers(ViTs)在图像分类任务中表现出了很强的准确性。但后者通常需要更多的数据进行模型预训练。因此,近期的大部分工作都致力于设计更复杂的架构或训练方法来解决 ViTs 的数据效率问题。但都忽略了对改进自注意力机制进行探索,而它是区分 ViTs 和 CNNs 的一个关键因素。
本次工作,作者就引入一个概念上简单的方案,refiner,直接完善 ViTs 的自注意图。具体来说,Refiner 对自注意力的扩展进行了探索,将多头注意力图映射到一个更高的维度空间,以促进其多样性。此外,refiner 应用卷积来增强注意力图的局部模式,这相当于一个分布式的局部注意力特征在局部用可学习的内核聚合,然后用自注意力进行全局聚合。
实验结果表明 Refiner 的工作效果出奇的好。重要的是,它使 ViTs 在 ImageNet 上仅用 81M 的参数就能达到 86% 的 top-1 分类准确率。
论文链接:https://arxiv.org/abs/2106.03714
项目链接:https://github.com/zhoudaquan/Refiner_ViT

标签:Transformer+图像分类
11
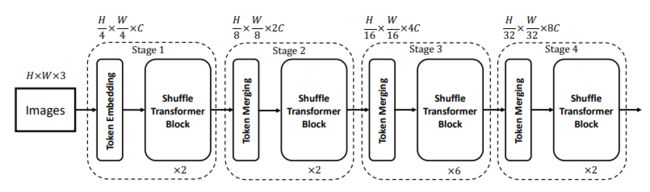
Shuffle Transformer: Rethinking Spatial Shuffle for Vision Transformer
来自腾讯光影研究室
腾讯光影研究室研究员提出 Shuffle Transformer,效率高易实现,只需修改两行代码。另外,引入 depth-wise 卷积对 spatial shuffle 进行补充来加强 neighbor-window 的连接。所提出的架构在广泛的视觉任务上取得了优异的性能,包括图像级分类、目标检测和语义分割。
论文链接:https://arxiv.org/abs/2106.03650
标签:Transformer+计算机视觉
12
ViTAE: Vision Transformer Advanced by Exploring Intrinsic Inductive Bias
来自悉尼大学&京东
作者通过提出两个新的基本单元(reduction cells 和 normal cells)来重新设计 transformer 块,将两种类型的内在的 inductive bias(归纳偏差IB)纳入transformer,即 locality(位置性)和 scale-invariance(尺度不变性),从而形成一个简单而有效的 vision transformer 架构,ViTAE。在 ImageNet 以及下游任务上的实验证明了 ViTAE 比基线 transformer 和同期工作的优越性。作者也称源代码和预训练模型将在 GitHub 上提供。
论文链接:https://arxiv.org/abs/2106.03348
项目链接:https://github.com/Annbless/ViTAE

标签:Transformer
13
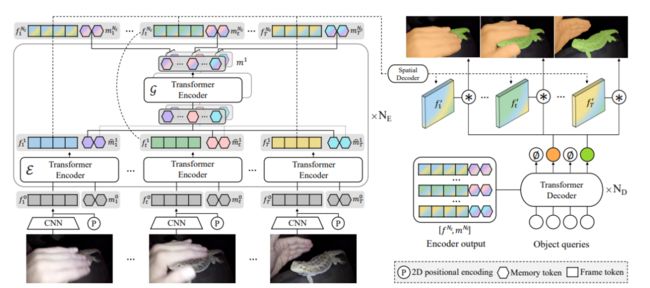
Video Instance Segmentation using Inter-Frame Communication Transformers
来自延世大学&Adobe Research
视频实例分割任务中,per-clip 比 per-frame 显出更好的性能,而 per-clip 模型需要大量的计算和内存使用来实现帧与帧之间的通信,限制了实用性。
本次工作,提出 Inter-frame Communication Transformers(IFC),通过对输入片段中的上下文进行有效编码,大大降低帧间信息传递的开销。具体来说,提出利用简明的记忆 tokens 作为传达信息的手段,并对每一帧场景进行总结。通过精确编码的记忆 tokens 之间的信息交流,每一帧的特征都已充实并与其他帧相关联。
在最新的基准集上对所提出方法进行了验证,并取得了最先进的性能(在 YouTube-VIS 2019 价值集上使用离线推理的 AP 44.6),同时具有相当快的运行时间(89.4 FPS)。该方法也可以应用于近乎在线的推理,以实时处理视频,只有很小的延迟。
论文链接:https://arxiv.org/abs/2106.03299
标签:Transformer+视频实例分割
14
Transformer in Convolutional Neural Networks
来自苏黎世联邦理工学院&南开大学& 电子科技大学
研究目的:解决 MHSA 中由高计算/空间复杂性引起的 vision transformer 的低效率缺陷。
方案:Hierarchical MHSA(H-MHSA),其表示方法是以分层方式计算的。具体来说,H-MHSA 首先通过将图像patches 视为 tokens 来学习小网格内的特征关系。然后,将小网格合并成大网格,在大网格内,通过将前一步的每个小网格视为一个 tokens 来学习特征关系。这个过程是反复进行的,以逐渐减少 tokens 的数量。H-MHSA 模块很容易插入任何 CNN 架构中,并可通过反向传播进行训练。称新主干为 TransCNN,基本上继承了 Transformer 和 CNN 的优点。
结果:TransCNN 在图像识别方面达到了最先进的精度。
论文链接:https://arxiv.org/abs/2106.03180

标签:Transformer + CNN +图像识别
15
Oriented Object Detection with Transformer
来自纽约州立大学布法罗分校&北航&百度
基于 Transformer 的目标检测(DETR)已经取得了比传统检测器(如Faster R-CNN)更具竞争力的性能。但对于更具挑战性的面向任意目标检测问题,DETR 的潜力在很大程度上仍未得到开发。
本次工作首次尝试并实现了基于端到端网络的 TRansformer(O2DETR)的 OOD。O2DETR 的贡献如下:
1)通过应用 Transformer 来直接有效地定位目标,而不像传统的检测器那样需要一个繁琐的旋转锚点过程,从而为 OOD 提供了一个新的见解。
2)为 Transformer 设计一个简单但高效的编码器,用深度可分离卷积代替了注意力机制,可以大大减少原始Transformer 中使用多尺度特征的内存和计算成本。
3)O2DETR 可以成为 OOD 领域的另一个新基准,比 Faster R-CNN 和 RetinaNet 实现了高达 3.85 mAP 的改进。只需在级联架构中对 O2DETR 的头部安装进行微调,并在 DOTA 数据集中取得了比 SOTA 更有竞争力的性能。
论文链接:https://arxiv.org/abs/2106.03146

标签:Transformer+目标检测
16
Uformer: A General U-Shaped Transformer for Image Restoration
来自中国科学技术大学&澳门大学&国科大
Uformer,用于图像修复的有效且高效的 U-shaped Transformer。具体来说,引入一个局部增强的窗口Transformer 块,使 Uformer 在图像修复方面达到更好的性能。在 Uformer 架构中还提出三种类型的 skip-connections,包括两种新的 skip-connections 方案。
在几个图像修复任务上的广泛实验证明了 Uformer 的优越性,包括图像去噪、去雨、去模糊和去摩尔纹。作者期望本次工作可以鼓励该领域进一步的研究,以探索基于 Transformer 的低级视觉任务的架构。
论文链接:https://arxiv.org/abs/2106.03106
项目链接:https://github.com/ZhendongWang6/Uformer

标签:Transformer+图像恢复
17
Patch Slimming for Efficient Vision Transformers
来自北大&华为诺亚方舟实验室&悉尼大学
研究目的:通过挖掘给定网络中的冗余计算来研究 vision transformers 的效率问题。尽管 transformers 架构已经被证明其在一系列计算机视觉任务上取得优异性能的有效性。但与卷积神经网络类似,vision transformers 的巨大计算成本仍然是一个严重的问题。
方案:根据注意力机制会逐层聚集不同的 patches,提出 patch slimming 方法,在自上而下的范式中舍弃无用的 patches。首先确定最后一层的有效 patches,然后用它们来指导前面几层的 patche 选择过程。对于每一层,patch 对最终输出特征的影响是近似的,而影响较小的 patch 将被删除。
在基准数据集上的实验结果表明,所提出的方法可以在不影响 vision transformers 性能的情况下大大降低其计算成本。例如,在 ImageNet 数据集上,ViT-Ti 模型的 FLOPs 可以减少 45% 以上,而 top-1 的准确率只下降 0.2%。
论文链接:https://arxiv.org/abs/2106.02852

标签:Transformer
18
Visual Transformer for Task-aware Active Learning
来自帝国理工学院&韩国科学技术院
主动学习(AL)中基于 Pool 的采样代表了处理深度学习模型时标注信息性的数据的一个关键框架。在本文中,提出一个基于 Pool 的主动学习新方法。与之前的大多数工作不同,该方法在训练期间利用可访问的未标记例子来估计它们与标记例子的共同关系。
另一个贡献是将 Visual Transformer 作为 AL 管道中的一个 sampler。Visual Transformer 对已标记和未标记例子之间的非局部视觉概念依赖性进行建模,对识别有影响的未标记例子至关重要。另外,与现有的以多阶段方式训练learner 和 sampler 的方法相比,作者提出以 task-aware 方式联合训练它们,这样可以将隐空间转化为两个独立的任务:一个是对已标记例子进行分类;另一个是区分标记的方向。
在 CIFAR10、CIFAR100、FashionMNIST、RaFD 和 Pascal VOC 2007,四个不同的分类和检测任务的挑战性基准上对该工作进行了评估。结果表明,与现有方法相比,所提出方法具有优越性。
论文链接:https://arxiv.org/abs/2106.03801
项目链接:https://github.com/razvancaramalau/Visual-Transformer-for-Task-aware-Active-Learning

标签:Transformer+主动学习
- END -
编辑:CV君
转载请联系本公众号授权

备注:TFM

Transformer交流群
Transformer等最新资讯,若已为CV君其他账号好友请直接私信。
在看,让更多人看到 