MPII数据集解析
1 简介
官网:MPII Human Pose Database
MPII Human Pose 数据集是人体姿势估计的一个benchmark,约有 25k 张图像,包含 40k 多个均被标注了 16 个关节点信息的人体目标,这些图片是从 YouTube video 中抽取出来的。一般把其中28k个用来training,11k用来testing。其数据以多人为主,有用于单帧单人姿态、单帧多人姿态和视频多人姿态的验证和测试集,大部分方法以使用单帧多人姿态测试集为主。在测试集中还收录了身体部位遮挡、3D 躯干、头部方向的标注。
2 MPII数据集输出格式
16个关键点,0 - r ankle, 1 - r knee, 2 - r hip,3 - l hip,4 - l knee, 5 - l ankle, 6 - l ankle, 7 - l ankle,8 - upper neck, 9 - head top,10 - r wrist,11 - r elbow, 12 - r shoulder, 13 - l shoulder,14 - l elbow, 15 - l wrist
3 h5文件格式
annot文件夹中一般有train.h5、valid.h5和test.h5组成。
center:表示原图像中框图bbox的中心点位置,即水平方向x宽和垂直方向y高。
imgname:表示每个人所在图片的文件名称。
index:表示每个人所在图片的编号。?
name:表示数据集名称,例如MPII。
name_:表示数据集名称,例如MPII。
normalize:头部大小,正规化系数,距离除以此数。
part:每张图片中人的身体部位的位置xy(分别存储于两个表格中)。
![]()
person:每个图片中包含的人的个数。
scale:图片缩放率。就是原图像框图bbox范围(就是包括的人,相当于裁剪)。官方的说法是:person scale w.r.t. 200 px height。mpii数据集中的人体框都是个正方形。scale=图片中人体框的高度/200。scale是那个个体的大概尺寸,要乘以200,因为是以200像素做比得到的scale。但是实际上,我用scale和obj的x,y裁出来的个体图像并不很准确,各种脚不见了。
torsoangle:躯干偏转角度。
visible:每个图片中16个部位能可见度,1.0表示可见,0.0表示不可见。
4 anno文件解析
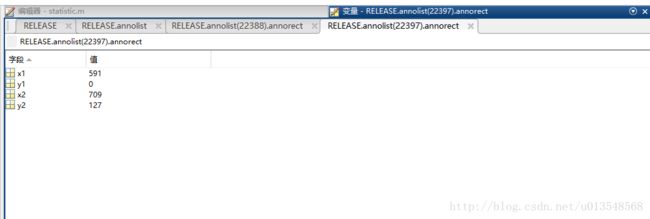
原版官网只提供了mpii_human_pose_v1_u12_1.mat标注文件。内容格式如下图:

在训练hourglass的时候,有几个文件需要清楚
annot.h5文件是包含了25925个人的训练集,对应着17408张图片
train.h5是包含了22246个人的训练集,对应着14679张图片
valid.h5是包含了2958个人的验证集,对应着2729张图片
test.h5是包含了11731个人的测试集,对应着6619张图片
注:valid数据集是根据tompson的划分来的,是从训练集的一部分数据来的,那么问题来了,mat标注文件里面一共有24987张图片,上面的(14679+2729+6619=22207张),差了很多,那么差在哪里了呢?
4.1 测试集
首先分析测试集,通过数据分析,一共有6908张测试集,很抱歉,由于数据标注的残缺,最后只有6619张图片可以用
数据标注的问题在于两个
1)annorect域缺失,一共244张
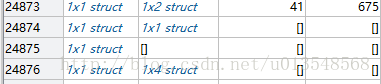
2)annorect域存在,但是1x1的struct是空的,一共45张

244+45=289张,而6908-6619=289张,恰好吻合了
注:6908是img_train=0统计出来的
4.2 训练+验证
1)annorect域缺失,一共576张

2)annorect域不为空,但是只有x1,x2,x3,x4的信息,没有关键点信息,一共95张
576+95 = 671张,而18079-2729-14679 = 671,吻合
注:18079是img_train=1统计出来的
5 偏差分析
在图像数量上已经达到了吻合,但是模型训练单位是人,人数上也存在偏差,现在分析
5.1 测试集
h5文件给的是11731个人,但是经过我们的统计,最终的结果却是11776个人,统计代码如下
for kk = 1:length(RELEASE.annolist(i).annorect)
person_test_num_all = person_test_num_all+ 1; %i是img_train=0对应的index
end那么究竟是什么原因呢
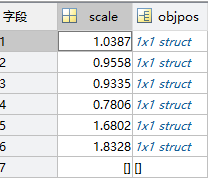
原因是因为对于每一个annorect,虽然从外边看是1x7的结构体,但是进去一看确实这样的
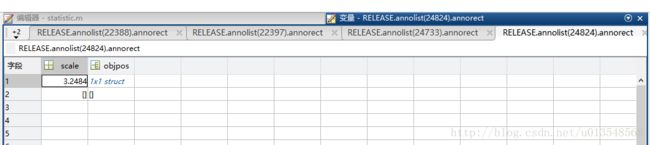
将代码改为
for kk = 1:length(RELEASE.annolist(i).annorect)
if(length(RELEASE.annolist(i).annorect(kk).scale)~=0)
person_test_num_all = person_test_num_all+ 1;
end
end这样统计出来的就是11731了,好坑
5.2 训练集+验证集
首先我们用一开始的方法统计出来的人数一共有29017人,然后用后来的统计一共有28883个人(类似于5.1)
现在开始分析
28883-2958=25925,那么问题来了,train.h5里面是啥啊
tompson提取的2958个人,只是从所对应的图像中选取几个人而已,而不是选取所有的标注得人,所以就差在了这里
例如052475643.jpg这张图片,valid.h5只从这张图片中选取了一个人,但实际上这张图片标注了两个人,train.h5和annot.h5区别就在这里,annot.h5会把剩下的另一个人加入到自己的训练中,但是train.h5则不会,他会将已经选定作为验证的这个人的这张图片都不再参与训练,所以就导致了train.h5只有22246个人,而annot.h5则含有25925个人
5.3 讨论
hourglass采用的是annot.h5和valid.h5作为训练,这个似乎更合理
PyraNet则是采用train.h5和valid.h5作为训练
在一些训练中会采用mpii_annotation.json文件,该文件包含了train.h5和valid.h5的整合,因此和PyraNet的训练是一致,都是没有将全部的训练集用于最后的训练。
6 JSON格式读入
MPII 数据集本身是以 JSON 格式进行的标注的,h5格式标注文件是后来采用的。JSON 格式标注文件可以通过 JSON 库进行读入。
import jsonanno = json.load(self.mpii_anno_pah)将每个图片打包成(图片,标注,bounding box)的形式,bounding box 即图片大小,其目的是将大小不一的图片处理成 256 x 256 的大小。
from PIL import Imagefor idd, joint_idd in enumerate(joints):
image_name = "im%s.jpg" % str(idd + 1).zfill(5)
if count else "im%s.jpg" % str(idd + 1).zfill(4)
joint_id = idd + len(joints) if count else idd
im_path = os.path.join(self.lsp_data_path[count], image_name)
im = Image.open(im_path)
im = np.asarray(im)
shape = im.shape
bbox = [0, 0, shape[1], shape[0]]
joint_dict[joint_id] = {'imgpath': im_path, 'joints': joint_idd, 'bbox': bbox}JSON格式文件包括train.json、trainval.json、valid.json、test.json。格式文件内容如下:
ann={
"joints_vis": int[16], # 值为0 or 1,表示每个关节是否可见
"joints": int[16,2], # 每个关节点的坐标
"image": int, # 图片id
"scale": float, # 缩放比例
"center": float[2], # 人的中心点坐标
}7 数据增强
作者用到了几种数据增强的手段:
-
缩放 scale
-
旋转 rotate
-
翻转 flip
-
添加颜色噪声 add color noise
7.1 缩放
读入数据后,需要先把大小不一的标注图片统一转换成 256 x 256。
对于 LSP 测试集,作者使用的是图像的中心作为身体的位置,并直接以图像大小来衡量身体大小。数据集里的原图片是大小不一的(原图尺寸存在 bbox 里),一般采取 crop 的方法有好几种,比如直接进行 crop,然后放大,这样做很明显会有丢失关节点的可能性。也可以先把图片放在中间,然后将图片缩放到目标尺寸范围内原尺寸的可缩放的大小,然后四条边还需要填充的距离,最后 resize 到应有大小。
这里采用的是先扩展边缘,然后放大图片,再进行 crop,这样做能够保证图片中心处理后依然在中心位置,且没有关节因为 crop 而丢失。注意在处理图片的同时需要对标注也进行处理。
要注意 OpenCV 和 PIL 读入的 RGB 顺序是不一样的,在使用不同库进行处理时要转换通道。
import cv2big_img = cv2.copyMakeBorder(img, add, add, add, add, borderType = cv2.BORDER_CONSTANT, value=self.pixel_means.reshape(-1))#self.show(bimg)
bbox = np.array(dic['bbox']).reshape(4, ).astype(np.float32)
bbox[:2] += addif 'joints' in dic:
process(joints_anno)objcenter = np.array([bbox[0] + bbox[2] / 2., bbox[1] + bbox[3] / 2.])
minx, miny, maxx, maxy = compute(extend_border, objcenter, in_size, out_size)
img = cv2.resize(big_img[min_y: max_y, min_x: max_x,:], (width, height))示例图:

▲ 左:原图,右:缩放后
示例图的十四个标注点:
(88.995834, 187.24898);(107.715065, 160.57408);(119.648575, 124.30561) (135.3259, 124.53958);(145.38748, 155.4263);(133.68799, 165.95587) (118.47862, 109.330215);(108.41703, 104.65042);(120.81852, 84.05927) (151.70525, 86.63316);(162.93677, 101.14057);(161.29883, 124.773575) (136.0279, 85.93119);(138.13379, 66.509995)
7.2 旋转
旋转后点的坐标需要通过一个旋转矩阵来确定,在网上的开源代码中,作者使用了以下矩阵的变换矩阵围绕着 (x,y) 进行任意角度的变换。

在 OpenCV 中可以使用:
cv2.getRotationMatrix2D((center_x, center_y) , angle, 1.0)
newimg = cv2.warpAffine(img, rotMat, (width, height))得到转换矩阵,并通过仿射变换得到旋转后的图像。而标注点可以直接通过旋转矩阵获得对应点。
rot = rotMat[:, : 2]
add = np.array([rotMat[0][2], rotMat[1][2]])
coor = np.dot(rot, coor) + w该部分代码:
def rotate(self, img, cord, anno, center):
angle = random.uniform(45, 135)
rotMat = cv2.getRotationMatrix2D((center[0], center[1]) , angle, 1.0)
newimg = cv2.warpAffine(img, rotMat, (width, height))
for i in range(n):
x, y = anno[i][0], anno[i][1]
coor = np.array([x, y])
rot = rotMat[:, : 2]
add = np.array([rotMat[0][2], rotMat[1][2]])
coor = np.dot(rot, coor) + add
label.append((coor[0], coor[1]))
newimg = newimg.transpose(2, 0, 1)
train_data[cnt++] = newimg
train_label[cnt++] = np.array(label)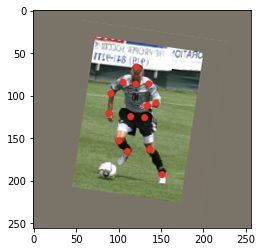
7.3 翻转
使用 OpenCV 中的 flip 进行翻转,并对标注点进行处理。在 OpenCV 中 flip 函数的参数有 1 水平翻转、0 垂直翻转、-1 水平垂直翻转三种。
def flip(self, img, cod, anno_valid, symmetry): '''对图片进行翻转'''
newimg = cv2.flip(img, 1)
'''处理标注点,symmetry是flip后所对应的标注,具体需要自己根据实际情况确定'''
train_data[counter] = newimg.transpose(2, 0, 1)
for (l, r) in symmetry:
cod[l], cod[r] = cod[l], cod[r]
for i in range(n):
label.append((cod[i][0],cod[i][1]))
train_label[cnt++] = np.array(label)
7.4 添加颜色噪声
我所采用的方法是直接添加 10% 高斯分布的颜色点作为噪声。人为地损失部分通道信息也可以达到添加彩色噪声的效果。
def add_color_noise(self, image, percentage=0.1):
noise_img = image '''产生图像大小10%的随机点'''
num = int(percentage*image.shape[0]*image.shape[1]) '''添加噪声'''
for i in range(num):
x = np.random.randint(0,image.shape[0])
y = np.random.randint(0,image.shape[1])
for j in range(3):
noise_img[x, y, i] = noise_img[x, y, i] + random.gauss(2,4)
noise_img[x, y, i] = 255 if noise_img[x, y, ch] > 255 else 0
return noise_img
除此之外,以下数据增强的方法也很常见:
1. 从颜色上考虑,还可以做图像亮度、饱和度、对比度变化、PCA Jittering(按照 RGB 三个颜色通道计算均值和标准差后在整个训练集上计算协方差矩阵,进行特征分解,得到特征向量和特征值);
2. 从图像空间性质上考虑,还可以使用随机裁剪、平移;
3. 从噪声角度,高斯噪声、椒盐噪声、模糊处理;
4. 从类别分布的角度,可以采用 label shuffle、Supervised Data Augmentation(海康威视 ILSVRC 2016 的 report)。
在这个具体例子中,进行数据增强的时候要考虑的是:1)形变会不会影响结果;2)会不会丢掉部分节点。
8 性能评价标准-PCK
PCK是mpii使用的人体关键点估计评价标准,在coco之前,PCK一直是比较主流的metric,包括deepfashion,fashionAI等,都是使用的此标准。
PCK(Percentage of Correct Keypoints)定义为关键点被准确检测的比例。计算检测的关键点与其对应的groundtruth间的归一化(Normalization)距离小于设定阈值的比例。FLIC 中是以躯干直径作为归一化参考。MPII 归一化距离是关键点预测值与人工标注值的欧式距离,进行人体尺度因子的归一化,MPII数据集是以当前人的头部直径作为尺度因子,即头部矩形框的左上点与右下点的欧式距离,使用此尺度因子的姿态估计指标也称PCKh。。可以认为预测的关键点与GT标注的关键点经过head size normalize后的距离。
需要注意的是PCK是针对于一个人joints的predict和gt,也就是说不存在多么预测结果与gt之前对应的问题,或者说这个对应问题在PCK计算之前就应该解决了,而PCK解决多人姿态估计时使用的方式是在人的维度上进行平均。
从下面的代码也可以看出,距离的计算是一一对应的,而多人的PCK就是求平均值。

from mmpose
def keypoint_pck_accuracy(pred, gt, mask, thr, normalize):
"""Calculate the pose accuracy of PCK for each individual keypoint and the
averaged accuracy across all keypoints for coordinates.
Note:
PCK metric measures accuracy of the localization of the body joints.
The distances between predicted positions and the ground-truth ones
are typically normalized by the bounding box size.
The threshold (thr) of the normalized distance is commonly set
as 0.05, 0.1 or 0.2 etc.
batch_size: N
num_keypoints: K
Args:
pred (np.ndarray[N, K, 2]): Predicted keypoint location.
gt (np.ndarray[N, K, 2]): Groundtruth keypoint location.
mask (np.ndarray[N, K]): Visibility of the target. False for invisible
joints, and True for visible. Invisible joints will be ignored for
accuracy calculation.
thr (float): Threshold of PCK calculation.
normalize (np.ndarray[N, 2]): Normalization factor for H&W.
Returns:
tuple: A tuple containing keypoint accuracy.
- acc (np.ndarray[K]): Accuracy of each keypoint.
- avg_acc (float): Averaged accuracy across all keypoints.
- cnt (int): Number of valid keypoints.
"""
distances = _calc_distances(pred, gt, mask, normalize)
acc = np.array([_distance_acc(d, thr) for d in distances])
valid_acc = acc[acc >= 0]
cnt = len(valid_acc)
avg_acc = valid_acc.mean() if cnt > 0 else 0
return acc, avg_acc, cnt
def _calc_distances(preds, targets, mask, normalize):
"""Calculate the normalized distances between preds and target.
Note:
batch_size: N
num_keypoints: K
dimension of keypoints: D (normally, D=2 or D=3)
Args:
preds (np.ndarray[N, K, D]): Predicted keypoint location.
targets (np.ndarray[N, K, D]): Groundtruth keypoint location.
mask (np.ndarray[N, K]): Visibility of the target. False for invisible
joints, and True for visible. Invisible joints will be ignored for
accuracy calculation.
normalize (np.ndarray[N, D]): Typical value is heatmap_size
Returns:
np.ndarray[K, N]: The normalized distances.
If target keypoints are missing, the distance is -1.
"""
N, K, _ = preds.shape
distances = np.full((N, K), -1, dtype=np.float32)
# handle invalid values
normalize[np.where(normalize <= 0)] = 1e6
distances[mask] = np.linalg.norm(
((preds - targets) / normalize[:, None, :])[mask], axis=-1)
return distances.T
def _distance_acc(distances, thr=0.5):
"""Return the percentage below the distance threshold, while ignoring
distances values with -1.
Note:
batch_size: N
Args:
distances (np.ndarray[N, ]): The normalized distances.
thr (float): Threshold of the distances.
Returns:
float: Percentage of distances below the threshold.
If all target keypoints are missing, return -1.
"""
distance_valid = distances != -1
num_distance_valid = distance_valid.sum()
if num_distance_valid > 0:
return (distances[distance_valid] < thr).sum() / num_distance_valid
return -1
9 各参数的意义
image
输入图像
scalefactor
当我们将图片减去平均值之后,还可以对剩下的像素值进行一定的尺度缩放,它的默认值是1,如果希望减去平均像素之后的值,全部缩小一半,那么可以将scalefactor设为1/2
mean
需要将图片整体减去的平均值,如果我们需要对RGB图片的三个通道分别减去不同的值,那么可以使用3组平均值,如果只使用一组,那么就默认对三个通道减去一样的值。减去平均值(mean):为了消除同一场景下不同光照的图片,对我们最终的分类或者神经网络的影响,我们常常对图片的R、G、B通道的像素求一个平均值,然后将每个像素值减去我们的平均值,这样就可以得到像素之间的相对值,就可以排除光照的影响。
swapRB
是否交换RB,OpenCV中认为我们的图片通道顺序是BGR,但是我平均值假设的顺序是RGB,所以如果需要交换R和G,那么就要使swapRB=true
crop
图像裁剪,默认为False.当值为True时,先按比例缩放,然后从中心裁剪成size尺寸
size
输出图像的空间尺寸,如size=(200,300),Width=200, Height=300
depth
当cv2.imshow()处理图像深度为CV_8U(默认范围为[0,255])时,按原数据显示;当处理图像深度为CV_16U(默认范围为[0,65535])时,除以256,映射到[0,255];当图像深度为CV_32F和CV_64F时(默认范围为[0,1]),乘以255映射到[0,255];当碰到负数时,首先取其绝对值,然后按照上述图像深度将超出数据范围的部分采取截断操作,最后映射到[0,255]显示图像
参考链接
coco数据集+MPII数据集下载链接_hua_007的专栏-CSDN博客coco数据集下载链接各个链接的意思看链接里面的描述基本上就够了。不过还在罗嗦一句,第一组是train数据,第二组是val验证数据集,第三组是test验证数据集。数据包括了物体检测和keypoints身体关键点的检测。http://images.cocodataset.org/zips/train2017.ziphttp://images.cocodataset.org/annotati...https://blog.csdn.net/hua_007/article/details/88787184?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522164603109216780357234631%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fall.%2522%257D&request_id=164603109216780357234631&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~first_rank_ecpm_v1~rank_v31_ecpm-7-88787184.pc_search_result_cache&utm_term=mpii%E6%95%B0%E6%8D%AE%E9%9B%86&spm=1018.2226.3001.4187
MPII数据集单人方面的数据分析!!!_u013548568的博客-CSDN博客_mpii数据集1、在训练hourglass的时候,有几个文件需要清楚annot.h5文件是包含了25925个人的训练集,对应着17408张图片train.h5是包含了22246个人的训练集,对应着14679张图片valid.h5是包含了2958个人的验证集,对应着2729张图片test.h5是包含了11731个人的测试集,对应着6619张图片注:valid数据集是根据tompson的划分来的...https://blog.csdn.net/u013548568/article/details/79056986?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522164603109216780357234631%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fall.%2522%257D&request_id=164603109216780357234631&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~first_rank_ecpm_v1~rank_v31_ecpm-2-79056986.pc_search_result_cache&utm_term=mpii%E6%95%B0%E6%8D%AE%E9%9B%86&spm=1018.2226.3001.4187
人体姿态估计-评价指标(一)_ZXF_1991的博客-CSDN博客_pck指标人体姿态估计-@1{评价指标}摘要摘要人体姿态估计可以细分成四个任务:单人姿态估计 (Single-Person Skeleton Estimation)、多人姿态估计 (Multi-person Pose Estimation)、人体姿态跟踪 (Video Pose Tracking)、3D人体姿态估计 (3D Skeleton Estimation)。单人姿态估计: 输入是切割出来的单个...https://blog.csdn.net/ZXF_1991/article/details/104279387?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522164603436116780265439763%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fall.%2522%257D&request_id=164603436116780265439763&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~first_rank_ecpm_v1~rank_v31_ecpm-2-104279387.pc_search_result_cache&utm_term=mpii%E8%AF%84%E4%BB%B7%E6%8C%87%E6%A0%87&spm=1018.2226.3001.4187