cityscapes数据集_图像语意分割训练Cityscapes数据集SegNet-ConvNet神经网络详解

版权声明:本文首发于本人CSDN博客。
前言:经过将近一个月的陆续学习研究,在神经网络中训练多分类任务识别Cityscapes数据集,终于在最近得到了理想中的实验结果。在我陷入对细节参数调整不当及诸多问题时,苦于没有一篇能够“面向新手编程”的博客。因而我在能够在解决一系列问题到达终点后总结这一路踩过的坑,希望对后来者有所帮助。
接下来就是用我得到的神经网络模型结合我所学专业(风景园林)完成小论文,希望能投稿核心成功。^ _^
我所提供的代码及讲解均是基于Cityscapes这一数据集默认19分类的基础上完成,若有朋友想要训练其他数量分类及其他用处,可参考思路并自行修改代码。
放一组训练完成模型进行识别出来的图,激励各位朋友和我自己在深度学习的路上坚持下去。
我使用百度地图API获取了天津大学门口的一处坐标点图片进行识别测试。


1.图片数据获取
需要使用Cityscapes这一数据集训练的主要目的:
用来做汽车自动驾驶识别,要么是像我用来做城市街道元素的相关识别。模型训练出来后,识别数据的获取就至关重要,在我的另一篇博客中:
Python通过百度全景图API爬取街景图像_loving___-CSDN博客_百度地图 街景图片python
详细讲解了如何通过百度地图官方API,通过Python简单的爬虫代码批量获取图片。
2.数据集预处理
我们知道,在深度学习图像语意分割的训练过程中,需要有数据集及分好类的标签,这样才可以让你的神经网络进行学习,进而训练出模型,用来识别你想要识别的图片场景等。Cityscapes便是包含大量街道图片、视频用来训练识别的数据集。
在我另一篇博客中对数据集的下载、处理都进行了详细的解释,这里就不做过多解释。
图像语意分割Cityscapes训练数据集使用方法分享_loving___-CSDN博客_怎么引用cityscapes数据集到图像分割中
3.图像语意分割神经网络列举
这里还是要感谢博主:
Bubbliiiing的学习小课堂_Bubbliiiing_CSDN博客-神经网络学习小记录,睿智的目标检测,有趣的数据结构算法领域博主
提供的神经网络合集及博文讲解。
博主提供的神经网络代码均是基于2分类的斑马线图像分割,而我在这基础上改为多分类的数据识别,各位朋友在学习时可以仔细对照修改前与修改后的网络,会对网络细节需要修改的参数有自己的理解。
我将博主共享的模型代码做了一份整理(下图),我将分两篇博文选取其中两个进行讲解。
分别是SenNet-ConvNet(简单)和DeepLabNet-XceptionNet(复杂)。

4.Make_Dataset
神经网络通过图片进行网络参数训练时,图片的获取需要从电脑异步读取,例如读取2张训练2张,如果读取所有上千张图片再抽取训练这样并不可行。
通过将图片和标签名称写入txt文件,在网络中读取txt文件合成完整的图片路径,进行读取。
import os
left = os.listdir(r"F:202006PracticecityscapesScripts-masterleftImg8bitval")
gtfine = os.listdir(r"F:202006PracticecityscapesScripts-mastergtFineval")
with open("read_data/val_data0.txt","w") as f:
for name in left:
png = name.replace("leftImg8bit","gtFine_labelTrainIds")
# 判断left是否存在对应的gtfine
if png in gtfine:
f.write(name+";"+png+"n")我将leftImg8bit和gtFine下的train和val数据集,将图片从各个城市的文件夹中剪切到了一个文件下。原因是我并没有想到什么非常好的办法,可以让程序按城市顺序读取图片并训练,不如将2974张train及500张val图片分别放到一起进行训练及验证。
代码第3、4行,路径可以更改为你电脑内可以找到这些图片即可。我这里仅放一张截图作为示例。
因为有原图及标签两个文件夹,所以也需要生成两个txt文件,第3、4行路径及第6行生成文件名称需要相对应的修改。
5.SenNet-ConvNet神经网络图像语意分割多分类训练
为了篇幅美观及阅读舒适,所有代码均放到了文章末尾。
编码网络ConvNet及解码网络SegNet均放在nets这一文件夹下,主要是通过
model = Model (输入,输出)
这一代码进行网络的构建,网络的结构Bubbliiiing已经进行了非常详细的讲解,我就不需要过多解释,并且代码也无任何的修改。
在train这一训练主函数中,需要对一些代码细节进行修改:
- 11行:NCLASSES需要从2改为19。这里便是控制最终多分类的数量。
- 18行:我将城市的名字写成一个列表。因为我尝试用for循环遍历城市名字,并随机从城市列表中取图片进行训练,上文解释过最终我还是将所有城市图片复制到了同一文件夹下,故这两行代码可以注释掉或忽略。
- 20行:共18个城市,我尝试生成一个1~18的随机数,用于随机取数据。最终放弃,同上。
- 22行:非随机取城市。最终放弃,同上。
- 38行:路径改为你电脑中存放的原图位置。37行为原代码,注释掉方便回溯,可忽略。
- 48行:路径改为你电脑中存放的标签位置。47行为原代码,注释掉方便回溯,可忽略。
- 51行:原代码是基于斑马线的二分类训练,原图及标签格式分别为PNG和JPG,然而在cityscapes中原图和标签格式均为PNG,此时就会出现一个问题,RGB三个值相等的灰度PNG图读取进来的维度会变为1维,而非JPG图片的3维。当时经过我多次“野路子”测试,通过PIL.Image中convert方法可以将读取的“L”灰度图模式转为“RGB”格式。
- 57行:问题同上。我尝试直接将1维升为3维,失败。此行代码可忽略。
- 62行:问题同上上。这是最优的解决办法,但和57行的方法仅能用其中一种,另一种注释掉。和通过和Bubbliiiing交流后得知,仅需将:0删掉即可,使用57行图像格式转换的方法有可能在训练时数据会出问题。我测试没出问题。
- 84行:预训练网络路径。若你没有下载预训练网络,可以在第一次训练时使用79-82行代码,控制台会显示一个网址,并进行预训练网络的下载,此时停止训练,使用网页下载这一链接,并放到新建一个model的文件夹内。第二次训练即可使用第84行代码(注释掉79-82),直接指向你电脑内的预训练网络路径位置。
- 85行:最终训练完成后,会自动保存一个名为“last1.h5”的权重文件,假如你认为并没有达到你的预期效果,只需将预训练网络替换为上次训练保存结果即可继承之前的权重继续训练。
- 91行:替换txt文件路径。
至此代码便没有进行其他内容的修改。
6.下期预告
有细心的朋友可能会发现,只用到了一个txt文件进行训练集的数据读取,而另外一个验证集txt根本没有用到,也没有用到验证集的图片。
在代码101行可以找到问题的答案。
原博主将训练集数量的90%用于训练,而剩下10%用于验证,这确实是一种取巧的方法,优点是快速简单。
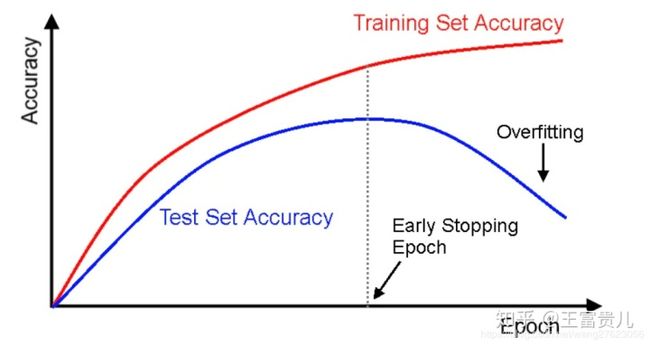
然而对最终训练模型的过拟合临界点、训练早停轮次(epoch)的选择会有影响,原因如下:
虽然在一个轮次中分为了90%训练和10%验证,但神经网络的参数终究在之前的轮次中训练过100%的图片,所以对网络曾“见过”的图片在另外轮次中作为验证集终究是有失公允。
思考题 :针对这样一个问题,在没有给出解决代码的前提下,你能否根据原博主的原网络代码尝试仿写出获取训练集的方法呢?
在下一篇博文代码中,增加了数据增强函数,迁移学习函数,以及上一个未解决问题验证集获取函数。
个人水平有限,若有理解不到之处,还请多指正~
from nets.segnet import convnet_segnet
from keras.optimizers import Adam
from keras.callbacks import TensorBoard, ModelCheckpoint, ReduceLROnPlateau, EarlyStopping
from PIL import Image
import keras
from keras import backend as K
import numpy as np
import cv2
import random
from keras.utils.data_utils import get_file
NCLASSES = 19
HEIGHT = 416
WIDTH = 416
#[aachen,1][bochum,2][bremen,3][cologne,4][darmstadt,5][dusseldorf,6][erfurt,7][hamburg,8][hanover,9]
#[jena,10][krefeld,11][monchengladbach,12][strasbourg,13][stuttgart,14][tubingen,15][ulm,16][weimar,17][zurich,18]
city_list = ["aachen","bochum","bremen","cologne","darmstadt","dusseldorf","erfurt","hamburg","hanover",
"jena","krefeld","monchengladbach","strasbourg","stuttgart","tubingen","ulm","weimar","zurich"]
# txt_number = random.randint(1,18)
txt_number = 0
# name_path = city_list[txt_number-1]
def generate_arrays_from_file(lines,batch_size):
# 获取总长度
n = len(lines)
i = 0
while 1:
X_train = []
Y_train = []
# 获取一个batch_size大小的数据
for _ in range(batch_size):
if i==0:
np.random.shuffle(lines)
name = lines[i].split(';')[0]
# 从文件中读取图像
# img = Image.open(r".dataset2jpg" + '/' + name)
img = Image.open(r"F:202006PracticecityscapesScripts-masterleftImg8bittrain" + '/' + name)
img = img.resize((WIDTH,HEIGHT))
img = np.array(img)
img = img/255
X_train.append(img)
name = (lines[i].split(';')[1]).replace("n", "")
# 从文件中读取图像
# img = Image.open(r".dataset2png" + '/' + name)
img = Image.open(r"F:202006PracticecityscapesScripts-mastergtFinetrain" + '/' + name)
#一种方法:尝试从“L”转为“RGB”
# img = img.convert("RGB")
img = img.resize((int(WIDTH/2),int(HEIGHT/2)))
img = np.array(img)
#二种方法:尝试升维 失败
# img = img[:, :, None]
seg_labels = np.zeros((int(HEIGHT/2),int(WIDTH/2),NCLASSES))
for c in range(NCLASSES):
# seg_labels[: , : , c ] = (img[:,:,0] == c ).astype(int)
seg_labels[: , : , c ] = (img[:] == c ).astype(int)
seg_labels = np.reshape(seg_labels, (-1, NCLASSES))
Y_train.append(seg_labels)
# 读完一个周期后重新开始
i = (i+1) % n
yield (np.array(X_train),np.array(Y_train))
def loss(y_true, y_pred):
loss = K.categorical_crossentropy(y_true,y_pred)
return loss
if __name__ == "__main__":
log_dir = "logs/"
# 获取model
model = convnet_segnet(n_classes=NCLASSES,input_height=HEIGHT, input_width=WIDTH)
# model.summary()
# WEIGHTS_PATH_NO_TOP = 'https://github.com/fchollet/deep-learning-models/releases/download/v0.1/vgg16_weights_tf_dim_ordering_tf_kernels_notop.h5'
# weights_path = get_file('vgg16_weights_tf_dim_ordering_tf_kernels_notop.h5',
# WEIGHTS_PATH_NO_TOP,
# cache_subdir='models')
weights_path = (r"model/vgg16_weights_tf_dim_ordering_tf_kernels_notop.h5")
# weights_path = (log_dir+r"last1.h5")
model.load_weights(weights_path,by_name=True)
# 打开数据集的txt
with open(r"F:202006Practice1.make_datasetread_datatrain_data{}.txt".format(txt_number),"r") as f:
lines = f.readlines()
# 打乱行,这个txt主要用于帮助读取数据来训练
# 打乱的数据更有利于训练
np.random.seed(10101)
np.random.shuffle(lines)
np.random.seed(None)
# 90%用于训练,10%用于估计。
num_val = int(len(lines)*0.1)
num_train = len(lines) - num_val
# 保存的方式,3世代保存一次
checkpoint_period = ModelCheckpoint(
log_dir + 'ep{epoch:03d}-loss{loss:.3f}-val_loss{val_loss:.3f}.h5',
monitor='val_loss',
save_weights_only=True,
save_best_only=True,
period=3
)
# 学习率下降的方式,val_loss3次不下降就下降学习率继续训练
reduce_lr = ReduceLROnPlateau(
monitor='val_loss',
factor=0.5,
patience=3,
verbose=1
)
# 是否需要早停,当val_loss一直不下降的时候意味着模型基本训练完毕,可以停止
early_stopping = EarlyStopping(
monitor='val_loss',
min_delta=0,
patience=10,
verbose=1
)
# 交叉熵
model.compile(loss = loss,
optimizer = Adam(lr=1e-3),
metrics = ['accuracy'])
batch_size = 4
print('Train on {} samples, val on {} samples, with batch size {}.'.format(num_train, num_val, batch_size))
# 开始训练
model.fit_generator(generate_arrays_from_file(lines[:num_train], batch_size),
steps_per_epoch=max(1, num_train//batch_size),
validation_data=generate_arrays_from_file(lines[num_train:], batch_size),
validation_steps=max(1, num_val//batch_size),
epochs=50,
# epochs=1,
initial_epoch=0,
callbacks=[checkpoint_period, reduce_lr,early_stopping])
model.save_weights(log_dir+'last1.h5')