如何使用部署百度飞桨的YOLOv3模型
01.概述
本文是OpenVINO™ 工具套件与百度飞桨PaddlePaddle模型转换/部署系列的第三部——目标检测模型。前面两篇文章分别谈到了用DeeplabV3和BiSeNetV2的语义分割模型来做路面分割. 本篇文章将关注展示如何将百度飞桨PaddleDetection下的 YOLOv3 MobileNet 多目标检测模型转换为OpenVINO™ 工具套件的IR模型,并且部署到CPU上.
为了使本文拥有更广的受众面,文章的目标部署平台选择了CPU。关于如何部署到边缘设备例如Intel® Movidius MyraidX VPU上, 请参考第一篇文章:
Ubuntu20.04环境下使用OpenVINO部署BiSeNetV2模型
目标检测的主要任务就是从一张图或者视频流的图像中检测图像内某个或者某几个类别对象实例的任务[1]。用更通俗易懂的话来解释就是 在图像中识别出有多少个物体,每个物体是什么类别的,并且对于每个识别出来的物体给出相应的定位。

理解了什么是目标检测之后我们就可以看出此类功能的重要性以及应用场景之广,大到可以在武器制导中做特定目标的自动跟踪,小到可以用来统计商店里客流量等等。
本篇文章的主要目的是展示如何把您已有的模型(这里我们采用百度飞桨PaddleDetection下面的YOLO模型)一步一步的部署到CPU上,同时本文也展示了一种思路:如何在浩瀚的Internet网络找到正确的信息,少走弯路。
1.1OpenVINO™ 工具套件的重要性
面对当下众多流行的AI框架,比如PaddlePaddle、PyTorch、Tensorflow等等,每个框架都有自己特殊的神经网络结构和文件类型,每个框架内的设计也尽不一样, 如此训练出来的模型则千差万别,这对软件开发和重用造成了一定的麻烦。
是否可以有一种工具可以使我们,不管选用什么AI框架来构建专属于自己的神经网络时,在最后部署到生产环境中的环节,都可以拥有统一的接口,可重用的代码呢?
答案是肯定的。OpenVINO™ 工具套件就是这样的一款工具,有了它的帮助,AI工程师可以在模型构建、训练阶段,选择自己熟悉的任何AI框架来搭建起符合要求的个性化神经网络, 而在后期使用OpenVINO™ 快速构建起专属的解决方案,提供统一的接口,并在Intel® 的硬件上优化性能。
1.2这篇文章的着重点和非着重点
正如前面提到的,,这篇文章的着重点在于一步一步演示怎样导出已经训练好的或者已有的百度飞桨PaddleSeg模型,并且怎样转换Paddle模型到ONNX格式,最后再转到OpenVINO™ 工具套件IR模型,直至部署到CPU上为止。在每一步我都会提供相应的官方网址,一步一步的把读者推向正确的官网文档,减少走弯路。
再来讲一下这篇文章不讲什么。这篇文章不讲解怎样安装Python,Anaconda,OpenVINO™ 工具套件这样的基础需求框架。以上几个产品的官方网站教程都做的非常详细,而且会实时更新,相信对于每个不同的技术,阅读相对应的官方文档可以省去很多麻烦,少走弯路。这篇文章更多的精力会用在讲解模型之间的转换,部署,以及排错。
1.3Intel OpenVINO简介
OpenVINO™ 工具套件(以下简称OV)是Intel® 发布的一个综合性工具套件,用于快速开发解决各种任务的应用程序和解决方案。它包括人类视觉,自动语音识别,自然语言处理,推荐系统等。该工具套件基于最新一代人工神经网络,包括卷积神经网络 (CNN)、Recurrent Network和基于注意力的网络,可跨英特尔® 硬件扩展计算机视觉和非视觉工作负载,从而最大限度地提高性能。
1.4百度飞桨
百度飞桨(以下简称Paddle)是百度旗下一个致力于让AI深度学习技术的创新与应用更加简单的工具集。其中包括,PaddleCV,PaddleSeg,PaddleClas等工具帮助您快速的搭建起AI应用程序,最快落地AI模型项目。对于有过Tensorflow, PyTorch经验的朋友来说, Paddle的角色和前面二者是一样的,都是高度集成的AI框架。目前Paddle有很活跃的开发者社区,有利于快速找到自己需要的答案和帮助。
02面向的读者和需要的软件
2.1面向的读者
本文面向的读者是具有一定编程能力和经验的开发人员,AI模型开发员,熟悉Python语言,并使用Anaconda,已有训练好的模型,期待能部署到边缘设备上来投入实际生产中。对于0基础的读者也是一个很好的机会通过一篇文章一并了解以上的几个技术以及怎样综合使用这些技术,让它们成为您得心应手的工具来帮助您最快的实现AI部署。
2.2需要的软件
Anaconda,Python(创建Anaconda虚拟环境的时候会自带),OpenVINO™ 工具套件,Paddle,PaddleDetection,PaddleX(可选),Paddle2Onnx, Mamba(可选)。
03安装PaddlePaddle &
PaddleDetection
在介绍完以上内容后,我们可以正式动工啦。由于本文用到的YOLOv3 Mobile的目标检测模型是来自于PaddleDetection的Model Zoo, 所以需要先安装PaddleDetection的基础库 PaddlePaddle。然后再安装PaddleDetection。
在安装Paddle组件之前,请确保您已经安装好了Anaconda。(地址:
https://docs.anaconda.com/anaconda/install/index.html)
第一步:创建一个conda 虚拟环境:
conda create -n “paddle” python=3.8.8 ipython
创建好环境后,别忘了激活环境:
conda activate paddle
第二步:安装GPU或者CPU版本的PaddlePaddle:
至于是选择GPU还是CPU版本的Paddle,主要是根据您的硬件配置。如果您有NVIDIA最近几年的显卡例如:RTX 1060,RTX 2070等,那么请选择安装GPU版本。查看CUDA对GPU支持的具体信息,请阅读NVIDIA官网的GPU Compute Capability(地址:
https://developer.nvidia.com/cuda-gpus)
首先安装NVIDIA的cudnn
conda install cudnn
安装的时候也可以把conda 换成mamba(地址:https://github.com/mamba-org/mamba),从而得到更快的下载速度。

安装PaddlePaddle的时候,Paddle的官网(https://www.paddlepaddle.org.cn/)是您的好朋友,(任何时候安装任何东西,找到官网一般就能获取最新的指南), 我以Ubuntu 20.04的系统为例(如果您用其他的系统,那么请选择相应的选项)
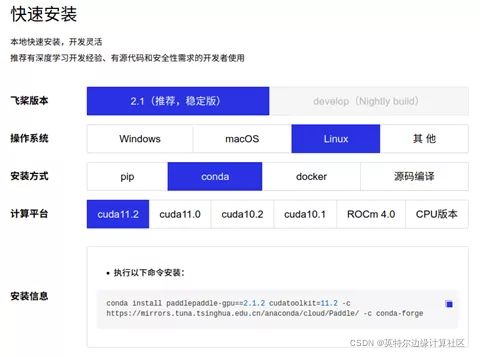
具体命令如下:
conda install paddlepaddle-gpu==2.1.2 cudatoolkit=11.2 -c https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/Paddle/ -c conda-forge
安装完底层框架之后,是时候安装PaddleDetection啦. 同理, 安装的时候您的好朋友是它的Github仓库。
git clone https://github.com/PaddlePaddle/PaddleDetection.git
当PaddleDetection的代码库下载完之后,就是激动人心的拿来即用步骤。下一步我们将会导出PaddleDetection Model Zoo里训练好的Yolo V3模型~!
04模型转换
模型的转换分为4个步骤:
-
导出已经训练好的模型 -
转换到ONNX模型 -
通过ONNX模型转换到OpenVINO™ 工具套件的 IR模型 -
最后编译IR模型成为.blob模型(只适用于Intel® VPU,神经棒等, 部署到CPU时不需要)

4.1导出已经训练好的模型
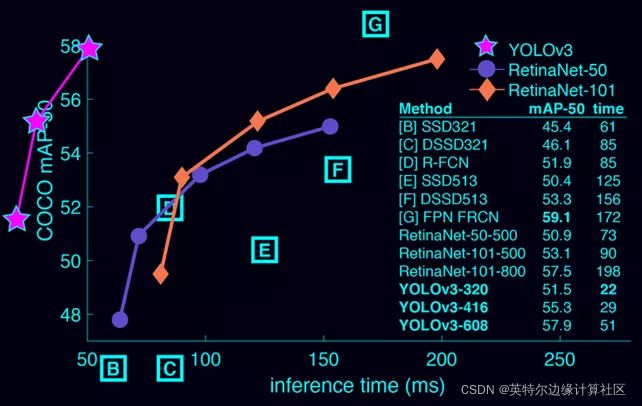
本文将会以PaddleDetection的Yolo模型为例来演示。Yolo: You Only Look Once, 它最显著的特性就是惊人的速度和不错的准确度。自从推出以来,已经历经多次更新,技术日益完善。本文中使用的就是YOLOv3。从下图可以看出YOLOv3的惊人表现。
-
首先请下载YOLOv3的参数文件 (YOLOv3_mobilenet_v3_large_270e_voc.pdparams). 下载后请在PaddleDetection目录下创建一个叫做models的文件夹,并且把参数文件放在里面。
-
激活刚才安装好的Anaconda Paddle环境
conda activate paddle
- 克隆PaddleDetection的代码库(如果您在前面已经下载好请略过这一步)
git clone https://github.com/PaddlePaddle/PaddleDetection.git
- 安装依赖项
cd PaddleDetection
pip install -r requirements.txt
- 导出模型
python tools/export_model.py
-c configs/YOLOv3/YOLOv3_mobilenet_v3_large_270e_voc.yml \
-o weights=models/YOLOv3_mobilenet_v3_large_270e_voc.pdparams \
–output_dir inference_model
注意,请先创建一个 名为: inference_model的文件夹,记得把参数文件的路径也改成您存放参数文件的相应路径。
导出后的模型将会保存在
inference_model/YOLOv3_mobilenet_v3_large_270e_voc这个文件夹下面。
如果想知道更多参数,您的好朋友还是PaddleDetection的官方Github Repository: 模型导出
(https://github.com/PaddlePaddle/PaddleDetection/blob/release/2.3/deploy/EXPORT_ONNX_MODEL.md)
来看一下YOLOv3_mobilenet_v3_large_270e_voc.yml配置文件 的内容:
(https://github.com/PaddlePaddle/PaddleDetection/blob/develop/configs/yolov3/yolov3_mobilenet_v3_large_270e_voc.yml)
BASE: [
‘…/datasets/voc.yml’,
‘…/runtime.yml’,
‘base/optimizer_270e.yml’,
‘base/YOLOv3_mobilenet_v3_large.yml’,
‘base/YOLOv3_reader.yml’,
]
snapshot_epoch: 5
weights: output/YOLOv3_mobilenet_v3_large_270e_voc/model_final
#set collate_batch to false because ground-truth info is needed
#on voc dataset and should not collate data in batch when batch size
#is larger than 1.
EvalReader:
collate_batch: false
LearningRate:
base_lr: 0.001
schedulers:
-
!PiecewiseDecay
gamma: 0.1
milestones:
-
216
-
243
-
-
!LinearWarmup
start_factor: 0.
steps: 1000
不难看出,这个配置文件是参照了5个模板,我们可以在_BASE_里面看到这些模板。那么我们就只需要指定任何与5个参照的模板不一样的地方。这样做的好处显而易见,最大化的重用代码,丙炔用最少的代码和改动完成个性化的设置。
4.2转模型到ONNX: Paddle --> ONNX
模型导出后第一道转换现在开始了。Paddle提供了转换工具 Paddle2onnx. (地址:
https://github.com/PaddlePaddle/Paddle2ONNX)
但是由于OpenVINO™ 工具套件目前在推理过程中,要求模型的各计算节点shape固定,而目标检测模型的后处理NMS(地址:
https://towardsdatascience.com/non-maximum-suppression-nms-93ce178e177c)
节点中,最终出来的目标数量是不确定的,即shape不固定。所以我们必须做一些小处理。
如果按照之前的步骤直接安装Paddle2Onnx工具来转换那么之后在转换成OpenVINO™ 工具套件IR格式的时候会出问题,(地址:
https://github.com/openvinotoolkit/openvino/issues/8426)
如果想知道具体原因,(地址:
https://github.com/PaddlePaddle/Paddle2ONNX/blob/release/0.9/experimental/openvino_ppdet_cn.md)
可以点击链接来查看。
比起之前的直接用Paddle2Onnx命令行工具,我们这次要直接使用Paddle2Onnx的源代码。
#如果事先已安装paddle2onnx,需先卸载或者创建一个新的conda环境
#pip uninstall paddle2onnx
git clone https://github.com/PaddlePaddle/Paddle2ONNX.git
cd Paddle2ONNX
git checkout release/0.9
python setup.py install
在Paddle2ONNX项目的根目录下建一个 convertYOLOv3.py
from build.lib import paddle2onnx
#import paddle2onnx
import paddle
model_prefix = “/Models/Paddle/Detection/YOLOv3_mobilenet_v3_large_270e_voc_origin/model”
model = paddle.jit.load(model_prefix)
input_shape_dict = {
“image”: [1, 3, 608, 608],
“scale_factor”: [1, 2],
“im_shape”: [1, 2]
}
onnx_model = paddle2onnx.run_convert(model, input_shape_dict=input_shape_dict, opset_version=11)
with open("./YOLOv3.onnx", “wb”) as f:
f.write(onnx_model.SerializeToString())
在运行上面一段代码的时候请确认您的模型的input size. 可以通过Netron 来查看模型的各项参数, 具体做法就是用Netron把刚才生成的model.pdmodel 文件打开 然后查看Model Properties.
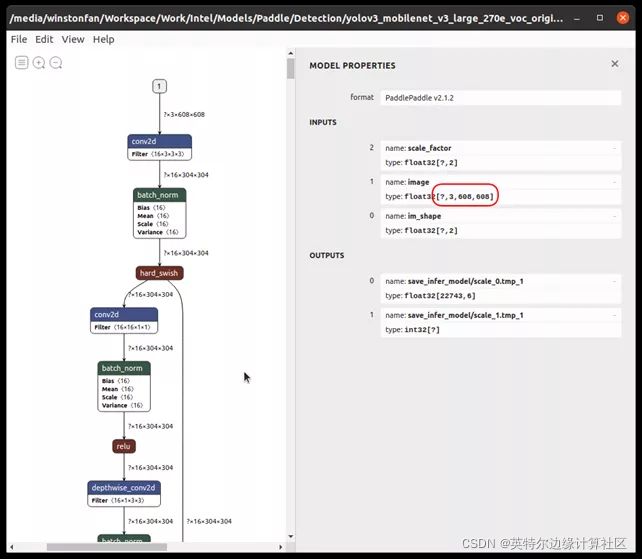
运行这段代码可得到ONNX相应的模型. 您将会看到一个 YOLOv3.onnx的文件在当前文件夹下面生成.
4.3转换ONNX模型到OpenVINO™ IR模型
铺垫了很久,终于来到了这一步。
先来快速介绍一下OpenVINO™ 的IR模型。IR的全称叫做Intermediate Representation. IR格式的模型是由2个文件组成的,它们分别是 .xml 和 .bin.
来到这一步之前请确保您的Intel OpenVINO安装成功啦。怎样安装Intel OpenVINO呢?您的好朋友又要出现了:Intel OpenVINO官网安装教程(地址:
https://docs.openvinotoolkit.org/cn/latest/openvino_docs_install_guides_installing_openvino_linux.html#install-openvino),这里是Intel OpenVINO官方下载地址(https://software.seek.intel.com/openvino-toolkit)
Intel OpenVINO的安装包里3种安装选项分别是:
-
图像界面GUI安装 -
命令行安装 -
命令行安装安静模式
对于新手,推荐用GUI安装,清清楚楚、明明白白。
4.3.1设置外部软件依赖
安装成功后,记得把Install External Software Dependencies这个部分的要求也跟完。
(地址:
https://docs.openvinotoolkit.org/cn/latest/openvino_docs_install_guides_installing_openvino_linux.html#install-external-dependencies)
4.3.2激活OpenVINO™ 工具套件环境变量
小提示:接下来要使用OV就要设置好它的环境变量。官方教程(地址:
https://docs.openvinotoolkit.org/cn/latest/openvino_docs_install_guides_installing_openvino_linux.html#set-the-environment-variables)要求把环境变量加载到您的 .bashrc文件里,这样每次打开任何命令行接口都可以自动加载OV的环境变量。但是我在实际使用过程中发现了一个问题。安装完OV后,我的一部分程序开始报错,出现了一个和Gstreamer相关的错误信息。经过研究发现原来OV的环境变量会和Anaconda的虚拟环境冲突,导致GStreamer出现问题。
其实解决方法也很简单。我们一般只会在模型转换的时候用到OV,那么就不要把OV的环境变量设置到.bashrc文件里面,只需要在使用OV之前,在命令行里激活OV的环境变量就行。激活环境变量的方法如下:
source /opt/intel/openvino_2021/bin/setupvars.sh
记住/opt/intel/openvino_2021/bin 是默认的OV安装路径,如果您改变了路径,请记得也随之改变这里的路径。
4.3.3配置模型优化器
Model Optimizer(MO)
MO是一个基于Python的命令行工具,可以用来从其他流行的人工智能框架例如Caffe,ONNX,TensorFlow等导入训练好的模型。没有用MO优化过的模型是不能用来在OV上做推理的。
在这一步可以只为您需要的环境比如ONNX,或者Tensorflow等做配置,但也可以一下配置好可以适用于各种人工智能框架的环境。我在这里选择了后者,毕竟路慢慢其修远 现在用ONNX 之后也有可能用到任何其他网络。
4.3.4转ONNX模型到IR模式
配置好MO之后 CD到MO设置的文件夹里面:
cd /opt/intel/openvino_2021/deployment_tools/model_optimizer
记得激活一下OpenVINO™ 工具套件的环境变量:
source /opt/intel/openvino_2021/bin/setupvars.sh
之后我们就可以开始期待已久的OpenVINO™ 工具套件IR模型转换(请把下面文件的路径替换成您相应的路径)。
$ python mo_onnx.py --input_model /Paddle2ONNX/YOLOv3.onnx --output_dir /Intel/Models/Paddle/Detection/YOLOv3_mobilenet_v3_large_270e_voc/OpenVINO/
Model Optimizer arguments:
Common parameters:
- Path to the Input Model: /media/winstonfan/Workspace/Learning/Github/Paddle2ONNX/YOLOv3.onnx
- Path for generated IR: /media/winstonfan/Workspace/Work/Intel/Models/Paddle/Detection/YOLOv3_mobilenet_v3_large_270e_voc_origin/OpenVINO/
- IR output name: YOLOv3
- Log level: ERROR
- Batch: Not specified, inherited from the model
- Input layers: Not specified, inherited from the model
- Output layers: Not specified, inherited from the model
- Input shapes: Not specified, inherited from the model
- Mean values: Not specified
- Scale values: Not specified
- Scale factor: Not specified
- Precision of IR: FP32
- Enable fusing: True
- Enable grouped convolutions fusing: True
- Move mean values to preprocess section: None
- Reverse input channels: False
ONNX specific parameters:
- Inference Engine found in: /opt/intel/openvino_2021/python/python3.8/openvino
Inference Engine version: 2021.4.0-3839-cd81789d294-releases/2021/4
Model Optimizer version: 2021.4.0-3839-cd81789d294-releases/2021/4
[ SUCCESS ] Generated IR version 10 model.
[ SUCCESS ] XML file: /media/winstonfan/Workspace/Work/Intel/Models/Paddle/Detection/YOLOv3_mobilenet_v3_large_270e_voc_origin/OpenVINO/YOLOv3.xml
[ SUCCESS ] BIN file: /media/winstonfan/Workspace/Work/Intel/Models/Paddle/Detection/YOLOv3_mobilenet_v3_large_270e_voc_origin/OpenVINO/YOLOv3.bin
[ SUCCESS ] Total execution time: 24.99 seconds.
[ SUCCESS ] Memory consumed: 575 MB.
4.4验证转换后的IR模型
在继续下去之前我们应该先检验一下这个模型是否真的转换成功。
在运行如下代码之前,请换一个命令行窗口,并且启动之前创建的Anaconda 环境,这样做是为了确保OV的环境变量和Conda的不互相冲突,产生错误。
幸运的是, 在Paddle2ONNX代码库的 release/0.9分支有提供给我们一个检测IR模型的代码。(地址:
https://github.com/PaddlePaddle/Paddle2ONNX/tree/release/0.9)
所以我们只需要在Paddle2Onnx代码库的根目录下创建一个文件 YOLOv3_infer.py,代码如下(请替换相应的文件路径):
from experimental.openvino_ppdet.YOLOv3_infer import YOLOv3
xml_file ="/Intel/Models/Paddle/Detection/YOLOv3_mobilenet_v3_large_270e_voc/OpenVINO/YOLOv3.xml”
bin_file = “/Intel/Models/Paddle/Detection/YOLOv3_mobilenet_v3_large_270e_voc/OpenVINO/YOLOv3.bin”
model = YOLOv3(xml_file=xml_file,bin_file=bin_file,model_input_shape=[608, 608])
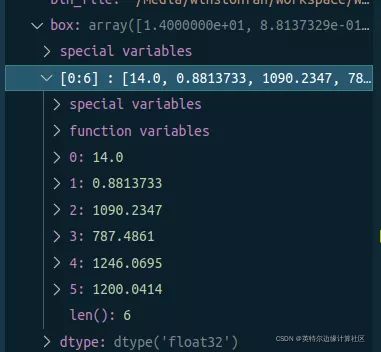
boxes = model.predict(“street.jpeg”, visualize_out=“result.jpg”, threshold=0.1)

这里如果不需要可视化结果 只要得到检测框和分类的话 那么便不需要 visualize_out 参数。
boxes里面装的东西是检测结果。每一个Box是一个装载了6个数字的数组,分别代表了 分类的ID(14代表人类),确定度,以及检测框的左上角和右下角的坐标。
4.5模型性能和吞吐量
测试好模型之后,我们还可以检查一下模型的性能和吞吐量。幸运的是,Intel® DevCloud已经提供了现有的工具来帮助我们快速完成这项工作。
这里是它的Jupyter Notebooks平台:
https://devcloud.intel.com/zh/edge/advanced/connect_and_create/
在使用前,需要先注册账户。
任意挑选了几套硬件搭配,来看一下刚转换好的IR模型性能。

由此可见更好的GPU,CPU会有更少的延迟,更高的输出量,但低端集成GPU反而不如CPU的表现好。本教程使用了图像尺寸为608*608的大小,而目标检测任务其实不需要很高的分辨率便可以达到较好的效果,所以在适当权衡速度和精确度之后 可以稍微降低图像的输入尺寸,这样也能大幅度提升模型的性能。

表格2展示的是同样的YOLOv3构架,但在减小输入图像的分辨率至320*320后,模型的整体吞吐量(Throughput) 提升了4倍左右,延迟(Latency)降低了3.5到4.2倍左右。
05总结
最后,我们来回顾一下。本文介绍了目标识别任务的内容, 阐述了使用OpenVINO™ 工具套件部署模型的重要性, 简单介绍了百度PaddlePaddle框架,然后一步一步展示了如何将您已有的模型转换到ONNX格式,最后直至OpenVINO™ 工具套件的IR格式。然后通过一段代码展示了如何使用和验证转换后的IR模型。用户可以根据自己的需求做适当的改变,便能轻松快速开发,部署属于自己的AI应用程序。
那么恭喜大家跟完了整个教程,期待看到更多的精彩应用. 最后贴上本文对应的Github 仓:
https://github.com/franva/Intel-OpenVINO-Paddle/tree/main/PaddleDetection,欢迎大家提出宝贵的意见。