[论文阅读] 20 AAAI TreeGen
TreeGen: A Tree-Based Transformer Architecture for Code Generation
TreeGen发表在2020年AAAI上,论文链接: TreeGen: A Tree-Based Transformer Architecture for Code Generation。
Abstract
代码生成 在给定自然语言描述的条件下,让模型生成符合描述的代码。
当前SOTA的代码生成方法主要是通过神经网络实现的。但它们普遍存在两个问题:
- 长依赖 (long dependency) 问题
一个代码元素可能会依赖很久之前出现的元素。
例如,代码中第100行为赋值语句 a = 10,其中 a 在代码的第 10 行就被声明。 - 结构建模 (structure modeling) 问题
程序包含比自然语言更丰富的结构化信息。
程序语言的语法正确性要求更高,程序的语法约束更强。
因此作者提出一种Tree-based 神经网络模型—— TreeGen,解决目前代码生成领域的挑战。
作者在HearthStone数据集和2个semantic parsing数据集上评估了TreeGen,发现TreeGen取得SOTA效果。
Introduction
代码生成 给定自然语言描述,代码生成模型会生成符合描述的可执行程序。
目前的代码生成方法主要是深度学习模型,常见做法是使用sequence to sequence或者sequence to tree模型。目前SOTA做法是预测语法规则序列来生成代码,也就是根据当前生成的部分抽象语法树 (partial AST),预测一条语法规则来扩展某个非终结结点。
为解决 long dependency 问题 (challenge 1),作者采用2017年提出的 Transformer 架构。
为了能够利用代码结构进行建模 (challenge 2),作者在模型中添加 strcutural convolution 子层。
Model
问题形式化
作者采用的是基于AST的代码生成方式,每次选择一条语法规则对一个非终结结点进行扩展,最终生成代码。
如 figure1 所示,目标是生成代码:
length = 10
可以通过预测一个语法规则序列来实现目标:
1. root -> module
2. module -> body
...
8. n->10
![[论文阅读] 20 AAAI TreeGen_第1张图片](http://img.e-com-net.com/image/info8/cb25041c41914308989d7f95bb46a7d3.jpg)
用数学公式表达的话,如下所示: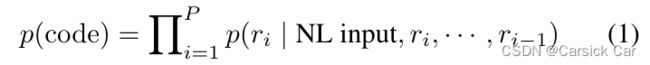
模型设计
模型的整体设计如 figure2 所示,由 NL Reader, AST Reader 和 Decoder 三个组件构成。
![[论文阅读] 20 AAAI TreeGen_第2张图片](http://img.e-com-net.com/image/info8/d924f8b5c29d405b81038973e99ff92e.jpg)
下面具体讲解每个部分的原理。注意文中的embedding dimension都是256。
1. NL Reader
![[论文阅读] 20 AAAI TreeGen_第3张图片](http://img.e-com-net.com/image/info8/81635b61a018471a8bd9b283024f636b.jpg)
给定自然语言描述,记为 n 1 , n 2 , ⋯ , n L n_1, n_2, \cdots, n_L n1,n2,⋯,nL( L 个 token,例如 how are you today )。
输入文本表示
NL Reader 模块有两个来源的输入,token embedding(自然语言输入 NL input)与 character embedding
Token Embedding
作者通过检索lookup table对输入的n个token进行编码,得到 n 1 , n 2 , ⋯ , n L \bold{n_1}, \bold{n_2}, \cdots, \bold{n_L} n1,n2,⋯,nL 一排向量。
Character Embedding
考虑 program 和 programs 两个单词,它们在lookup table中是不一样的词,但实际上它们的含义相近,因此作者从字符层面上再对 token 进行编码。
对于一个单词 n i n_i ni, 它有 S 个字母组成,记为 c 1 n i , c 2 n i , ⋯ , c S n i c_1^{n_i}, c_2^{n_i}, \cdots, c_S^{n_i} c1ni,c2ni,⋯,cSni。首先填充到 M 个字符 c 1 n i , c 2 n i , ⋯ , c S n i , c s + 1 n i , ⋯ , c M n i c_1^{n_i}, c_2^{n_i}, \cdots, c_S^{n_i}, c_{s+1}^{n_i}, \cdots, c_M^{n_i} c1ni,c2ni,⋯,cSni,cs+1ni,⋯,cMni,然后连接起来通过一个全连接层,就得到这个token字符层面的向量编码

NL Reader的网络架构
把NL input处理成一排 token embedding 后首先添加 position embedding 。这里作者用了一种不同于attention is all you need中的变体形式。
对于第 b 个 block 中第 i 个位置的 token,它的位置编码是 256 维,奇数维按照公式 4 计算,偶数维按照公式 3 计算。
![[论文阅读] 20 AAAI TreeGen_第4张图片](http://img.e-com-net.com/image/info8/8df424ae33c144ec84d0d72eb43422bd.jpg)
Self Attention
添加 position 信息后的向量过一个 self-attention 层,这里是用 multi-head 自注意力机制。具体原理见原论文 Attention is All You Need。
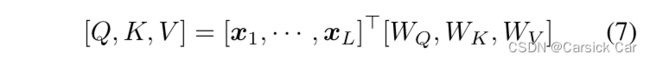


self-attention层后得到一排向量 y 1 s e l f , y 2 s e l f , ⋯ , y L s e l f y_1^{self}, y_2^{self}, \cdots, y_L^{self} y1self,y2self,⋯,yLself。
Gating mechanism
直观理解就是找出一组权重,把 token 的 self-attention 向量与 character 向量融合在一起。
做法如下:
第 i 个token是 n i n_i ni, 它的 self attention 向量为 y i s e l f y_i^{self} yiself ,character 层面向量为 c i n i c_i^{n_i} cini
对 y i s e l f y_i ^{self} yiself 做一个线性变化L1,得到 k i y k_i^y kiy
对 y i s e l f y_i ^{self} yiself 做一个线性变化L2,得到 v i y v_i^y viy
对 c i n i c_i^{n_i} cini 做一个线性变化L3,得到 k i c k_i^c kic
对 c i n i c_i^{n_i} cini 做一个线性变化L4,得到 v i c v_i^c vic
对 y i s e l f y_i ^{self} yiself 做一个线性变化L5,得到 q i q_i qi
q i q_i qi的作用是control vector,与 k i k_i ki 向量点乘得到一个数值,softmax 后作为权重。
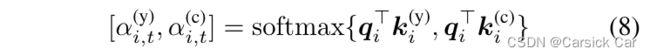
最后 gating 层就是把两个来源的 embedding 加权求和,融合在一起:
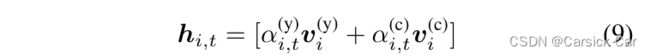
i t 代表第i个位置处的token,t。例如第5个位置处token是hello。
Word Convolution
简单理解就是把位置相邻的几个 token 的信息进一步融合。
这里设置了2个卷积层,每一层的输入是上一层的输出。公式理解起来较为简单,以 i 为中心,把距离它 w 位置内的embedding(包括自己的)都加权求和。这里的W是一个1 * k 的可学习的向量。

k = 2 ∗ w + 1 k = 2 * w + 1 k=2∗w+1是窗口大小。
最终 NL Reader 的输出是自然语言描述的embedding表示: y 1 N L , y 2 N L , ⋯ , y L N L y_1^{NL}, y_2^{NL},\cdots, y_L^{NL} y1NL,y2NL,⋯,yLNL
2.AST Reader
![[论文阅读] 20 AAAI TreeGen_第5张图片](http://img.e-com-net.com/image/info8/ab14ae532cd9412d91a120e325bf9a0b.jpg)
AST Reader 模块的作用是建模已经生成的 partial AST,编码其信息用于解码。
AST表示
假设目前生成的partial AST是 r 1 , r 2 , ⋯ , r P r_1, r_2, \cdots, r_P r1,r2,⋯,rP。
这里的 r i r_i ri 是规则的ID,例如 2. module -> body 的 ID是 2, 那么就用数字 2 对应的 token embedding去编码。
通过 token embedding 技术对这一个rule sequence进行编码得到 r 1 , r 2 , ⋯ , r P \bold{r_1}, \bold{r_2}, \cdots, \bold{r_P} r1,r2,⋯,rP。
此外,作者还考虑规则本身的内容信息。例如 i : α → β 1 ⋯ β K i : \alpha \rightarrow \beta_1\cdots\beta_K i:α→β1⋯βK 除了ID i可以被编码,我们也可以对语法规则本身进行编码。
检索lookup table得到 α , β 1 , . . . , \bold{\alpha}, \bold{\beta_1}, ..., α,β1,..., ,然后把它们拼接起来过一个全连接层得到 r c r^c rc。
最终某条规则的编码表示为

同样地,作者对这一排向量添加位置编码。
此外,由于语法规则在AST中的深度不同,因此作者还添加了深度信息,通过lookup table为每一个语法规则添加深度信息的向量 d 1 , ⋯ , d P d_1, \cdots, d_P d1,⋯,dP。
至此,我们得到的向量为 r i + d i + p i r r_i + d_i + p_i ^r ri+di+pir (ID编码 + 深度编码 + 位置编码)。
AST Reader的网络架构
Self attention
首先通过一层 self-attention 层。原理同 NL Reader 中的Self attention,略。
Gating Mechanism
然后通过 Gating 层。主要是把公式11得到的 y i r u l e y_i^{rule} yirule 内容信息融合。略。
NL Attention
这一个模块实际上已经在解码了。参考Transformer架构,为了能够解码,需要使用到自然语言描述信息。
Tree Convolution
rule sequence采用的是先序遍历,因此sequence中距离很远的两条规则在tree上可能很接近。为了更好利用起抽象语法树的结构信息,采用一种图卷积层,也就是Tree Convolution。
f i f_i fi表示树中第i个结点的embedding。利用一点本科学习的数据结构+离散知识,通过邻接矩阵M,即可得到它们父结点的编码。
![]()
通过如下公式即可融合结点本身、结点父亲、结点父亲的父亲、…的信息。

f是激活函数,采用GELU。
作者为每个AST Reader添加了2层Tree Convolution。
AST Reader层的输出记为:
y 1 a s t , y 2 a s t , ⋯ , y P a s t y_1^{ast}, y_2^{ast}, \cdots, y_P^{ast} y1ast,y2ast,⋯,yPast
3. Decoder
Query向量的计算如下:
首先确定要扩展的非终结结点(partial AST中先序遍历的第一个),然后得到root结点到它的路径,例如要扩展Assign结点,那么路径就是:
root, Module, body, Assign
把这些结点表示成向量,并且填充到固定长度,按照公式2的做法拼接起来后过一个全连接层,得到 q i p a t h q_i^{path} qipath。
得到query向量后,再依次和编码AST Reader输出(当前已经扩展的语法树的信息)与NL Reader输出(自然语言描述)做 attention。
AST Attention为例,query 是 q i p a t h q_i^{path} qipath,K 和 V 矩阵由目前的partial AST序列 y 1 a s t , y 2 a s t , ⋯ , y P a s t y_1^{ast}, y_2^{ast}, \cdots, y_P^{ast} y1ast,y2ast,⋯,yPast计算得到。
最后过一个Dense层(两层fcn+GELU),得到最终用于预测的向量 h d e c h^{dec} hdec。
Training & Inference
如果自然语言中出现了些比较特别的信息(e.g, declare a variable called this_is_a_very_very_very_long_variable),需要模型捕获并使用,那怎么办?
作者使用pointer network,让模型直接从自然语言描述中拷贝一些单词。例如,
α → a \alpha \rightarrow a α→a中, α \alpha α是非终结结点, a a a是终结结点,那么模型有一定概率会去拷贝自然语言描述中出现的token。
规则的选择方式如下
![[论文阅读] 20 AAAI TreeGen_第6张图片](http://img.e-com-net.com/image/info8/d2391b3967044c44a6664788d287a544.jpg)
把语法规则分两种情况:
- 形如 α → a \alpha \rightarrow a α→a的
- 其它
如果是情况2,那么不需要考虑公示14。直接用 h d e c h^{dec} hdec 过两层FCN和Sigmoid,然后用softmax计算概率分布p。例如Assign结点如果有多个生成式,实际上我们就是去计算用哪个生成式的概率最高。
Assign -> targets value
Assign -> A B
如果是情况1,那么这个时候,用 p g p_g pg去控制模型选择。
例如要生成下式,模型就必须要学会拷贝。
this_is_a_very_very_very_long_variable = 10
首先模型还是会用 h d e c h^{dec} hdec 过两层FCN和Sigmoid,然后用softmax计算概率分布p。但是得到的p需要再乘以 p g p_g pg。
同时pointer network还会用 h d e c h^{dec} hdec 和自然语言中的每一个token的编码表示去计算一个分数,决定拷贝该token的概率,并且乘以 1 − p g 1-p_g 1−pg。
![[论文阅读] 20 AAAI TreeGen_第7张图片](http://img.e-com-net.com/image/info8/7ebf7b4da96a4ea2bdeac1c964d42922.jpg)
最后就是看计算后的概率哪个更大,就选择哪个。