7 Papers | MIT学神开源微分太极;北大等提出没有乘法的神经网络
点击上方“深度学习技术前沿”,选择“星标”公众号
资源干货,第一时间送达
目录:
AdderNet: Do We Really Need Multiplications in Deep Learning?
DeepFakes and Beyond: A Survey of Face Manipulation and Fake Detection
DiffTaichi: Differentiable Programming for Physical Simulation
Optimization for deep learning: theory and algorithms
Audio-based automatic mating success prediction of giant pandas
Knowledge Consistency between Neural Networks and Beyond
Q-BERT: Hessian Based Ultra Low Precision Quantization of BERT
ArXiv Weekly Radiostation:NLP、CV、ML更多精选论文(附音频)
论文 1:AdderNet: Do We Really Need Multiplications in Deep Learning?
作者:Hanting Chen、Yunhe Wang、Chunjing Xu 等
论文链接:https://arxiv.org/pdf/1912.13200v2.pdf
摘要:和加法运算相比,乘法运算在计算复杂度上要高很多。在深度学习中,被广泛使用的卷积运算相当于是衡量输入特征和卷积滤波器之间相似度的交叉相关计算。在这一过程中需要很大规模的浮点乘法,因此很多研究都在考虑将乘法运算换成等价的加法运算。近日,北大、华为诺亚方舟实验室等的研究者提出了一个名为 AdderNets 的网络,用于将深度神经网络中,特别是卷积神经网络中的乘法,转换为更简单的加法运算,以便减少计算成本。
在 AdderNets 中,研究者采用了 L1 正则距离,用于计算滤波器和输入特征之间的距离,并作为输出的反馈。为了取得更好的性能,研究者构建了一种特殊的反向传播方法,并发现这种几乎完全采用加法的神经网络能够有效收敛,速度与精度都非常优秀。从结果来看,AdderNets 在 ResNet-50 上 对 ImageNet 数据集进行训练后,能够取得 74.9% 的 top-1 精确度和 91.7% 的 top-5 精确度,而且在卷积层上不使用任何乘法操作。这一研究引起了深度学习社区的热议。

AdderNet 和 CNN 的特征可视化。

二值网络、加法网络和卷积网络在 CIFAR-10 与 CIFAR-100 数据集上的效果。

ImageNet 上的分类结果。
推荐:深度学习对算力要求太高,怎么简化计算复杂度呢?北大、华为诺亚方舟实验室等提出完全用加法代替乘法,用 L1 距离代替卷积运算,从而显著减少计算力消耗。
论文 2:DeepFakes and Beyond: A Survey of Face Manipulation and Fake Detection
作者:Ruben Tolosana、Ruben Vera-Rodriguez、Julian Fierrez 等
论文链接:https://arxiv.org/pdf/2001.00179v1.pdf
摘要:大规模公共数据集的免费获取和深度学习技术(尤其是 GAN)的快速发展,导致以假乱真的内容大量出现,在假新闻时代这些伪造内容对社会产生了一定的影响。本文对人脸图像操纵技术进行了全面的综述,包括 DeepFake 方法以及检测此类操纵技术的方法。具体而言,本文综述了四种人脸操纵类型:人脸合成、换脸(DeepFakes)、人脸属性操纵和人脸表情操纵。
对于每种人脸操纵类型,本文详细介绍了其相关的人脸操纵技术、现有的公共数据库以及用于评估人脸操纵检测方法的重要基准,包括对这些评估结果的总结。在本文提及的多个可用数据库中,FaceForensics++ 是最常用于检测人脸身份转换(即「换脸」)和人脸表情操纵的数据库之一,基于该数据集的操纵检测准确率在 90-100% 范围内。此外,本文还讨论了该领域的发展趋势,并对正在进行的工作进行了展望,如近期宣布的 DeepFake 检测挑战赛(DFDC)。

根据操纵的级别,人脸操纵技术可分为四类:人脸合成、换脸、人脸属性操纵和人脸表情操纵,上图为每种人脸操纵类别的真假图像示例。
推荐:这是一篇不错的人脸操纵和检测技术综述文章,结构和逻辑清晰,希望能够帮助大家一览该领域的发展过程。
论文 3:DiffTaichi: Differentiable Programming for Physical Simulation
作者:Yuanming Hu、Luke Anderson、Tzu-Mao Li 等
论文链接:https://arxiv.org/pdf/1910.00935.pdf
摘要:去年 5 月,机器之心报道了 MIT 华人学神胡渊鸣等开源的计算机图形库——太极。近日,这位作者联合其他研究者推出了自动微分版本的太极——微分太极。这一框架可以基于太极实现自动微分,在物理模拟优化方面有很高的性能和灵活性。
太极原本是用于计算机图形计算和模拟的,为什么要开发为微分框架呢?这是因为使用可微模拟器进行物理控制器优化,相比 model-free 的强化学习算法,可以提升 1 到 4 个量级的收敛速度。微分太极是基于太极项目的,它能够使用源码转换的方式,对模拟步骤生成梯度。模拟程序由一个轻量的 tape 进行记录,并以降序方式返回核的梯度,实现端到端反向传播。

左:微分太极可以和神经网络控制器及物理模拟模块无缝结合,并向控制器或初始化转台参数更新梯度。模拟过程通常有 512 到 2048 个时间步,每个时间步达到 1000 次并行运算;右:10 个基于微分太极构建的微分模拟器。

自动微分架构。左:微分太极系统。白色部分为来自太极语言的重用架构,蓝色为微分程序的扩展部分。右:Tape 记录了核的运行,在反向传播时以降序方式重放(replay)梯度核。
推荐:本篇论文已被 ICLR 2020 接收,也意味着太极从计算机图形学进入了机器学习的领域。
论文 4:Optimization for deep learning: theory and algorithms
作者:Ruoyu Sun
论文链接:https://arxiv.org/pdf/1912.08957.pdf
摘要:深度学习优化方法都有哪些?其理论依据是什么?最近,来自伊利诺伊大学香槟分校(UIUC)的研究者孙若愚就此主题写了一篇长达 60 页的综述论文。
这篇文章首先讨论了梯度爆炸/消失问题以及更通用的谱控制问题,并讨论了一些实际解决方案,如初始化和归一化方法。其次,本文综述了神经网络训练过程中使用的一般优化方法,如 SGD、自适应梯度方法和分布式方法,还介绍了这些算法的现有理论结果。最后,本文综述了关于神经网络训练的全局问题的研究,包括糟糕的局部极小值上的结果、模式连接(mode connectivity)、彩票假设和无限宽度分析。

成功训练神经网络的几项主要的设计选择(已具备理论理解)。它们对算法收敛的三个方面产生影响:实现收敛、实现更快收敛、获得更好的全局解。这三项相互关联,这里只是大致的分类。

本文将优化问题划分为三部分:收敛、收敛速度和全局质量。
推荐:本篇论文详细讲述了用于训练神经网络的优化算法和理论。
论文 5:Audio-based automatic mating success prediction of giant pandas
作者:WeiRan Yan、MaoLin Tang、Qijun Zhao 等
论文链接:https://arxiv.org/abs/1912.11333
摘要:我们都知道,大熊猫是地球上最濒危的物种之一,但我们并不清楚它为什么会濒危。据研究表明,大熊猫成为濒危物种主要是因为繁殖艰难,而繁殖难的问题主要源于「性冷淡」。熊猫的繁殖季节时间非常短,一年 365 天中,最佳交配时间仅有 1 天。更令人惆怅的是,雄性熊猫每天将大把的时间用来吃饭和睡觉,压根注意不到异性,所以生育率一直很低。
传统上,认定大熊猫的发情与确认交配结果(即是否交配成功)是基于它们的荷尔蒙分泌情况来评估的,这种方法操作非常复杂,而且无法实时获得结果。近期的研究表明,处于繁殖季节的大熊猫会有特殊的发声行为,这为分析大熊猫的交配成功情况提供了新的机会。
受近段时间语音识别方法快速发展的启发以及计算机技术在野生动植物保护方面的应用,四川大学、成都大熊猫繁育研究基地和四川省大熊猫科学研究院的研究者提出根据大熊猫的发声情况来自动预测其交配的成功率。为此,他们将这个问题定义成了一个语音情绪识别(SER)问题。他们没有使用人工定义的特征和发声类型,而是使用了深度网络来学习不同的发声特征,自动预测交配成功率。

基于大熊猫发声行为的自动交配成功率预测能更好地协助大熊猫繁殖。

CGANet 架构主要包含卷积模块、GRU 模块和注意力模块。

CGANet、FLDA 和 SVM 在准确率(acc)、F1 分数、召回率(recall)、精度和曲线下面积(auc)5 项指标上的效果对比。可以看出,本文提出的 CGANet 架构的效果均为最佳。
推荐:大熊猫交配叫声暗藏玄机,川大学者用音频 AI 预测大熊猫何时怀上宝宝。
论文 6:Knowledge Consistency between Neural Networks and Beyond
作者:Ruofan Liang、Tianlin Li、Longfei Li、Quanshi Zhang
论文链接:https://arxiv.org/pdf/1908.01581.pdf
摘要:深度神经网络(DNN)已经在很多任务中表现出了强大的能力,但目前仍缺乏诊断其中层表征能力的数学工具,如发现表征中的缺陷或识别可靠/不可靠的特征。由于数据泄漏或数据集发生变化,基于测试准确率的传统 DNN 评测方法无法深入评估 DNN 表征的正确性。
因此,在本论文中,来自上海交大的研究者提出了一种从知识一致性的角度来诊断 DNN 中层网络表征能力的方法。即,给定两个为同一任务训练的 DNN(无论二者架构是否相同),目标是检验两个 DNN 的中间层是否编码相似的视觉概念。该研究实现了:(1)定义并量化了神经网络之间知识表达的不同阶的一致性;(2)对强弱神经网络中层知识进行分析;(3)对中层特征的诊断,在不增加训练样本标注的前提下进一步促进神经网络分类准确率;(4)为解释神经网络压缩和知识蒸馏提供了一种新的思路。

知识一致性。
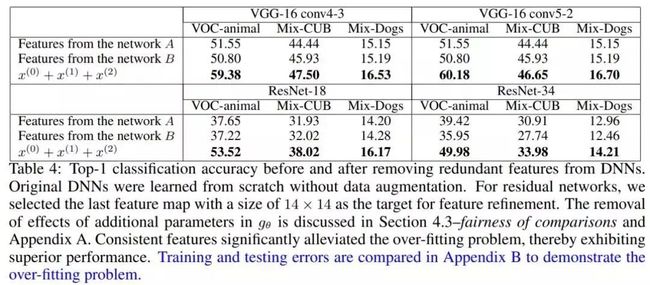
知识一致性算法可以有效的去除与目标应用无关的冗余特征分量,进一步提升目标应用的性能。
推荐:本文介绍了上海交通大学张拳石团队的一篇 ICLR 2020 接收论文,提出了一种对神经网络特征表达一致性、可靠性、知识盲点的评测与解释方法。
论文 7:Q-BERT: Hessian Based Ultra Low Precision Quantization of BERT
作者:Sheng Shen、Zhen Dong、Jiayu Ye 等
论文链接:https://arxiv.org/pdf/1909.05840.pdf
摘要:在本文中,研究者介绍了一个用于计算 Hessian 信息的全新可扩展框架,以解决二阶信息计算速度很慢的问题。此外,他们表示在训练期间也可以使用 Hessian 信息,且开销很少。与 ImageNet 上基于一阶方法训练 ResNet18 的时间相比,研究者采用的方法可提速 3.58 倍。
推荐:这篇论文已被 AAAI 2020 大会接收,作者之一 Zhewei Yao 是加州大学伯克利分校 BAIR、RISELab(前 AMPLab)、BDD 和数学系博士。
更多人工智能领域前沿资讯,请关注我们的公众号,第一时间为您送达!!!
