基于强化学习SAC_LSTM算法的机器人导航
【前言】在人群之间导航的机器人通常使用避碰算法来实现安全高效的导航。针对人群中机器人的导航问题,本文采用强化学习SAC算法,并结合LSTM长短期记忆网络,提高移动机器人的导航性能。在我们的方法中,机器人使用奖励来学习避碰策略,这种方法可以惩罚干扰行人运动的机器人行为。

【问题描述】
状态 移动机器人在人群中的导航问题可描述为部分可观测马尔可夫决策过程(POMDP)。其中,机器人的状态为s_t = [so_t, sh_t ],由机器人可以观测到的状态 so_t 和机器人本身隐藏状态 sh_t 组成。其中,so_t表示为:
![]()
sh_t表示为:
![]()
动作 机器人的动作由平移和旋转速度组成,即:a_t=[w,v],在我们的方法中,设置机器人的动作为一种连续性动作。
奖励函数 奖励机器人达到其目标并惩罚机器人与行人碰撞或离行人太近。此外,设置一个基于势能的奖励塑造来引导机器人接近目标:

【训练策略】
长短期记忆网络(LSTM)可以接受可变大小的输入,因此我们将行人状态(so_t)编码为状态序列,作为LSTM的输入,其网络结构如下图所式:

LSTM 将相关信息存储在其隐藏状态中,并忘记输入中不太重要的部分。输入最终行人的状态后,我们可以将 LSTM 的最终隐藏状态作为该决策步骤的固定长度、编码的环境状态。在具有大量智能体状态的情况下,为了减轻智能体忘记早期状态的影响,将这些状态以与智能体的距离相反的顺序输入,这意味着距离最近的智能体对应最终的隐藏状态:hn。将hn与机器人自身的状态拼接joint_state=[self_state,hn],joint_state作为全连接网络的输入。
关于SAC_LSTM的Actor Critic网络结构参考下图,

策略的更新我们采用自动熵的SAC算法,关于SAC算法描述参考文献[3]。
关于Q网络和策略部分代码如下:
class DQFunc(nn.Module):
def __init__(self, state_dim, action_dim, hidden_size, lstm_hidden_dim, self_state_dim):
super(DQFunc, self).__init__()
self.action_dim = action_dim
self.self_state_dim = self_state_dim
self.lstm_hidden_dim = lstm_hidden_dim
self.lstm = nn.LSTM(state_dim - self_state_dim, lstm_hidden_dim, batch_first=True)
self.linear1 = nn.Linear(action_dim + lstm_hidden_dim + self_state_dim, hidden_size)
self.linear2 = nn.Linear(hidden_size, hidden_size)
self.network1 = nn.Linear(hidden_size, 1)
self.network2 = nn.Linear(hidden_size, 1)
def forward(self, state, action):
size = state.shape
self_state = state[:, 0, :self.self_state_dim]
human_state = state[:, :, self.self_state_dim:]
h0 = torch.zeros(1, size[0], self.lstm_hidden_dim)
c0 = torch.zeros(1, size[0], self.lstm_hidden_dim)
output, (hn, cn) = self.lstm(human_state, (h0, c0))
hn = hn.squeeze(0)
joint_state = torch.cat([hn, self_state], dim=1)
action = action.reshape(-1, self.action_dim)
x = torch.cat((joint_state, action), -1)
x = torch.tanh(self.linear1(x))
x = torch.tanh(self.linear2(x))
x1 = self.network1(x)
x2 = self.network2(x)
return x1, x2
class PolicyNetGaussian(nn.Module):
def __init__(self, state_dim, action_dim, hidden_size, self_state_dim, lstm_hidden_dim):
super(PolicyNetGaussian, self).__init__()
# print(state_dim)
self.self_state_dim = self_state_dim
self.lstm_hidden_dim = lstm_hidden_dim
self.lstm1 = nn.LSTM(state_dim - self_state_dim, lstm_hidden_dim, batch_first=True)
self.linear1 = nn.Linear(lstm_hidden_dim + self_state_dim, hidden_size)
self.linear2 = nn.Linear(hidden_size, hidden_size)
self.mean_linear = nn.Linear(hidden_size, action_dim)
self.log_std_linear = nn.Linear(hidden_size, action_dim)
def forward(self, state):
# print(state)
size = state.shape # torch.Size([1, 5, 13])
self_state = state[:, 0, :self.self_state_dim] # torch.Size([1, 6])
human_state = state[:, :, self.self_state_dim:]
h0 = torch.zeros(1, size[0], self.lstm_hidden_dim)
c0 = torch.zeros(1, size[0], self.lstm_hidden_dim)
output, (hn, cn) = self.lstm1(human_state, (h0, c0))
hn = hn.squeeze(0) # torch.Size([1, 128])
joint_state = torch.cat([self_state, hn], dim=1)
x = torch.relu(self.linear1(joint_state))
x = torch.relu(self.linear2(x))
mean = self.mean_linear(x)
log_std = self.log_std_linear(x)
# weights initialize
log_std = torch.clamp(log_std, -20, 2)
return mean, log_std
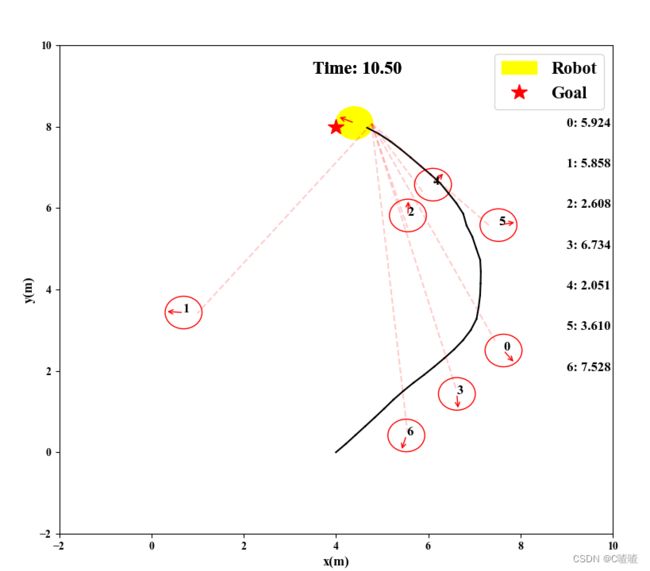
训练结果
其中黄色圆形表示机器人,其余圆圈表示移动的行人。
参考文献
1.Collision Avoidance in Pedestrian-Rich Environments with Deep Reinforcement Learning
2.Motion Planning Among Dynamic, Decision-Making Agents with Deep Reinforcement Learning
3.Soft Actor-Critic Algorithms and Applications