k近邻算法_KNN 算法——不学习我也能预测

前言
KNN(K-Nearest Neighbor)算法是机器学习中算法中最基础和简单的算法之一。它既能用于分类,也能用于回归。本文将在不同的小节详细地介绍 KNN 算法在分类和回归两种任务下的运用原理。
KNN 算法的思想非常简单:对于任意的 n 为输入向量,其对应于特征空间一个点,输出为该特征向量所对应的类别标签或者预测值。KNN 算法在机器学习算法中有一个十分特别的地方,那就是它没有一个显示的学习过程。它实际上的工作原理是利用训练数据对特征向量空间进行划分,并将其划分的结果作为其最终的算法模型。
KNN 分类算法
KNN 分类算法的分类预测过程十分的简单和容易理解:对于一个需要预测的输入向量 x,我们只需要在训练数据集中寻找 k 个与向量 x 最近的向量的集合,然后把 x 的类标预测为这 k 个样本中类标数最多的那一类。

图1 KNN 分类算法示意图
如上图所示,w1、w2、w3 分别代表的是训练集中的三个类别。图中与 xu 最相近的5(k=5)个点如图中箭头所指,很明显与 xu 最相近的5个点中最多的类标为 w1,因此 KNN 算法将 xu 的类别预测为 w1。
基于上述思想给出如下所示的 KNN 算法:
输入: 训练数据集
T={(x1,y1),(x2,y2),...,(xN,yN)}
其中:
xi∈X⊆Rn
为 n 维的实例特征向量。
yi∈Y={c1,c2,...,cK}
为实例的类别,i=1,2,...,N,预测实例 x。
输出: 预测实例 x 所属类别 y。
算法执行步骤:
- 根据给定的距离度量方法(一般情况下使用欧氏距离)在训练集 T 中寻找出与 x 最相近的 k 个样本点,并将这 k 个样本点所表示的集合记为 Nk(x);
- 根据如下所示的多数投票的原则确定实例 x 所属类别 y:
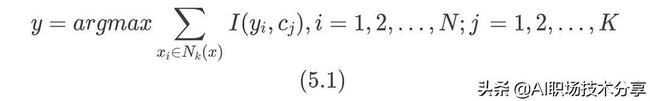
式(5.1)中 I 为指示函数:
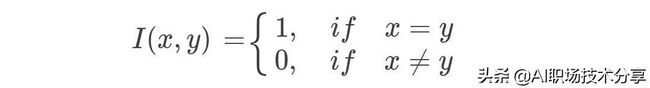
从上述的 KNN 算法原理的讲解中,我们会发现有两个因素必须确定才能使 KNN 分类算法真正能够运行:(1)算法超参数 K;(2)模型向量空间的距离度量。
k 值的确定
KNN 算法中只有唯一的一个超参数 K,很明显 K 值的选择对最终算法的预测结果会产生至关重要的影响。接下来就简单的讨论一下 K 值的大小对算法结果的影响以及一般情况下如何选择 K 值。
如果 K 值选择的比较小,这时候我们就相当于使用较小的领域中的训练样本对实例进行预测。这时候,算法的近似误差(Approximate Error)会减小,因为只有与输入实例相近的训练样本才能才会对预测结果起作用。但是它也会有明显的缺点:算法的估计误差会偏大,预测的结果会对近邻点十分敏感,也就是说如果近邻点是噪声点的话,那么预测就会出错。也就是说,K 值太小会使得 KNN 算法容易过拟合。
同理,如果 K 值选的比较大的话,这时候距离较远的训练样本都能够对实例的预测结果产生影响。这时候,而模型相对比较鲁棒,不会因个别噪声点对最终的预测产生影响。但是缺点也是十分明显的:算法的近似误差会偏大,距离较远的点(与预测实例不相似)也会同样对预测结果产生作用,使得预测产生较大偏差。此时相当于模型发生欠拟合。
因此,在实际的工程实践过程中,我们一般采用交叉验证的方式选取 K 值。从上面的分析也可以知道,一般 K 值取得比较小。我们会选取 K 值在较小的范围,同时在测试集上准确率最高的那一个确定为最终的算法超参数 K。
距离度量
样本空间中两个点之间的距离度量表示的是两个样本点之间的相似程度:距离越短,表示相似程度越高;相反,距离越大,表示两个样本的相似程度低。
常用的距离度量方式有:
- 闵可夫斯基距离;
- 欧氏距离;
- 曼哈顿距离;
- 切比雪夫距离;
- 余弦距离。
1.闵可夫斯基距离
闵可夫斯基距离不是一种距离,而是一类距离的定义。对于 n 维空间中的两个点 x(x1,x2,...,xn) 和 y(y1,y2,...,yn) ,那么 x 和 y 两点之间的闵可夫斯基距离为:
dxy=p ⎷n∑k=1(xk−yk)p
其中 p 是一个可变参数:
- 当 p=1 时,被称为曼哈顿距离;
- 当 p=2 时,被称为欧氏距离;
- 当 p=∞ 时,被称为切比雪夫距离。
2.欧氏距离
由以上说明可知,欧式距离的计算公式为:
dxy= ⎷n∑k=1(xk−yk)2
欧式距离(L2 范数)是最易于理解的一种距离计算方法,源自欧式空间中两点间的距离公式,也是最常用的距离度量方式。
3.曼哈顿距离
由闵可夫斯基距离定义可知,曼哈顿距离的计算公式为:
dxy=n∑k=1|xk−yk|
KNN 算法的核心:KDTree
通过以上的分析,我们知道 KNN 分类算法的思想非常简单,它采用的就是 K 最近邻多数投票的思想。所以,算法的关键就是在给定的距离度量下,对预测实例如何准确快速地找到它的最近的 K 个邻居?
也许绝大多数初学者会说,直接暴力寻找呗,反正 K 一般取值不会特别大。确实,特征空间维度不高并且训练样本容量小的时候确实可行,但是当特征空间维度特别高或者样本容量大时,计算就会非常耗时,因此该方法并不可行。
因此,为了快速查找到 K 近邻,我们可以考虑使用特殊的数据结构存储训练数据,用来减少搜索次数。其中,KDTree 就是最著名的一种。
KD 树简介
KD 树(K-dimension Tree)是一种对 K 维空间中的实例点进行存储以便对其进行快速检索的树形数据结构。KD 树是是一种二叉树,表示对 K 维空间的一个划分,构造 KD 树相当于不断地用垂直于坐标轴的超平面将 K 维空间切分,构成一系列的 K 维超矩形区域。KD 树的每个结点对应于一个 K 维超矩形区域。利用 KD 树可以省去对大部分数据点的搜索,从而减少搜索的计算量。
KD 树的构造
KD 树的构造是一个递归的方法:(1)构造根节点,使根节点对应于 K 维空间中包含的所有点的超矩形区域;(2)不断地对 K 维空间进行切分,生成子节点。
- 构造根节点
首先,在包含所有节点的超矩形区域选择一个坐标轴和在此坐标轴上的一个切分点,确定一个垂直于该坐标轴的超平面,这个超平面将当前区域划分为两个子区域(也即二叉树的两左右孩子节点)。
- 递归构造子节点
递归地对两个子区域进行相同的划分,直到子区域内没有实例时终止(此时只有叶子节点)。
通常我们循环地选择坐标轴对空间进行划分,当选定一个维度坐标时,切分点我们选择所有训练实例在该坐标轴上的中位数。此时我们来构造的 KD 树是平衡二叉树,但是平衡二叉树在搜索时不一定是最高效的。
KNN 回归算法
上面我们讲的 KNN 算法主要是用于分类的情况,实际上,KNN 算法也能够用于回归预测。本节我们就介绍一下 KNN 算法如何用于回归的情况。
众所周知,KNN 算法用于分类的方法如下:首先,对于一个新来的预测实例,我们在训练集上寻找它的最相近的 K 个近邻;然后,采用投票法将它分到这 K 个邻居中的最多的那个类。
但是,怎么将 KNN 算法用于回归呢?其实大致的步骤是一样的,也是对新来的预测实例寻找 K 近邻,然后对着 K 个样本的目标值去均值即可作为新样本的预测值:
^y=1KK∑i=1yi
KNN 预测实战
接下来,我们使用 scikit-learn 库中的 KNN 对 iris 数据集分类效果进行预测实战。众所周知,iris 数据集有四个维度的特征,但是为了方便展示效果,我们只使用其中的两个维度。完整的代码实现如下:
import numpy as npimport matplotlib.pyplot as pltfrom matplotlib.colors import ListedColormapfrom sklearn import neighbors, datasetsn_neighbors = 15# import some data to play withiris = datasets.load_iris()# we only take the first two features. We could avoid this ugly# slicing by using a two-dim datasetX = iris.data[:, :2]y = iris.targeth = .02 # step size in the mesh# Create color mapscmap_light = ListedColormap(['#FFAAAA', '#AAFFAA', '#AAAAFF'])cmap_bold = ListedColormap(['#FF0000', '#00FF00', '#0000FF'])for weights in ['uniform', 'distance']: # we create an instance of Neighbours Classifier and fit the data. clf = neighbors.KNeighborsClassifier(n_neighbors, weights=weights) clf.fit(X, y) # Plot the decision boundary. For that, we will assign a color to each # point in the mesh [x_min, x_max]x[y_min, y_max]. x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1 y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1 xx, yy = np.meshgrid(np.arange(x_min, x_max, h), np.arange(y_min, y_max, h)) Z = clf.predict(np.c_[xx.ravel(), yy.ravel()]) # Put the result into a color plot Z = Z.reshape(xx.shape) plt.figure() plt.pcolormesh(xx, yy, Z, cmap=cmap_light) # Plot also the training points plt.scatter(X[:, 0], X[:, 1], c=y, cmap=cmap_bold, edgecolor='k', s=20) plt.xlim(xx.min(), xx.max()) plt.ylim(yy.min(), yy.max()) plt.title("3-Class classification (k = %i, weights = '%s')" % (n_neighbors, weights))plt.show()代码运行结果如下图所示:
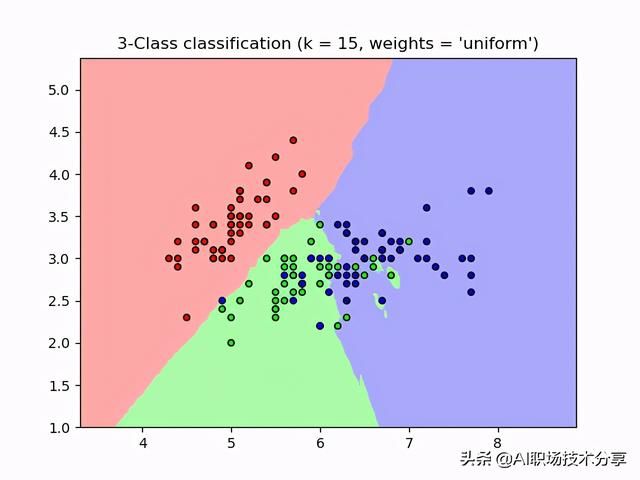
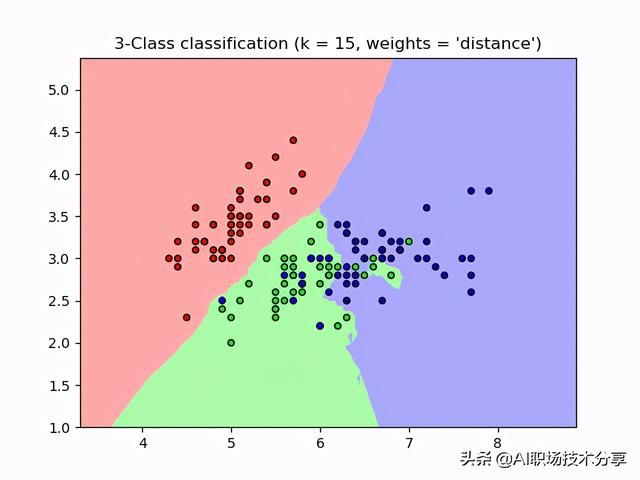
- 对代码进行解释:
代码中邻居数使用的是 n_neighbors = 15,只使用 iris 的前两维特征作为分类特征。权重度量采用了两种方式:均值(uniform)和距离(distance)。均值代表的是所有的 K 个近邻在分类时重要性选取的是一样的,该参数是默认参数;距离也就是说,分类时 K 个邻居中每个邻居所占的权重与它与预测实例的距离成反比。