深度学习中遇到的各种参数总结
深度学习里面的各种参数做一个学习记录
提示:自己根据自己的理解写的,水平有限,仅供参考,如有错误,欢迎指正
个人学习记录,仅供参考
-
- 深度学习里面的各种参数做一个学习记录
- 1. batchsize,iteration,epoch
- 2. filter,kernel_size,stride,padding
- 3. ReLU,sigmoid,softmax
- 4. BatchNormal,Dropout,num_classes,mini_batch
- 5. receptive field
1. batchsize,iteration,epoch
batchsize:批大小。在深度学习中,每次训练在训练集中一次性取batchsize个样本训练,举例子,就比如你在操场跑步比赛,一共200人参加,一共10个跑道,每次就10个一组的上,batchsize就是每次一组的10个人,一般大小设置为2的N次方,因为GPU的线程一般为2的N次方,GPU内部的并行计算效率最高。比如设置为64,128等。那怎么确定大小呢?
batch_size设的大,收敛得快,需要训练的次数少,准确率上升的也很稳定,但是实际使用起来精度不高;
batch_size设的小,收敛得慢,可能准确率来回震荡,因此需要把基础学习速率降低一些,但是实际使用起来精度较高。
可以根据实际情况多试几次,选一个合适的值。更多详情参考这里
iteration:迭代。1个iteration等于使用batchsize个样本训练一次。用跑步的例子来说,就是200除以10等于20,iteration就是20。
epoch:1个epoch等于使用训练集中的全部样本训练一次,epoch的值就是整个数据集被训练几次。你在操场跑步跑圈,一圈就是把全部样本训练一次,跑多少圈就是训练多少次。因为训练数据不是跑一圈就完了,那样结果很不好,要经过多轮的训练,结果才会比较好,一般epoch的大小也是根据实际情况。更多详情参考这里(英文版)
2. filter,kernel_size,stride,padding
代码如下(示例):
self.conv1_1 = nn.Conv2d(3, 64, kernel_size=3, stride=1, padding=1)
self.conv1_2 = nn.Conv2d(64, 64, kernel_size=3, stride=1, padding=1)
filter:滤波器,也就是卷积核。
kernel_size:卷积核大小。卷积核一般为奇数。
stride:步长。每次卷积核做卷积时移动的距离。
padding:填充。padding参数有两项:valid | same,valid表示无填充,same表示有填充。
详情可参考这里
3. ReLU,sigmoid,softmax
ReLU:线性整流函数(Rectified Linear Unit, ReLU),又称修正线性单元,是一种人工神经网络中常用的激活函数(activation function),通常指代以斜坡函数及其变种为代表的非线性函数。
ReLU函数如下图所示:
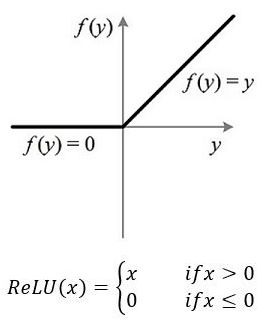
ReLU函数我们称为神经网络中的激活函数,激活函数作用。ReLU实现稀疏后的模型能够更好地挖掘相关特征,拟合训练数据。详情请看这里
我的理解是,ReLU函数相比于其他激活函数可以减小计算量,可以避免梯度消失,可以缓解过拟合问题。详情请看这里
sigmoid:sigmoid函数也叫Logistic函数,用于隐层神经元输出,取值范围为(0,1),它可以将一个实数映射到(0,1)的区间,可以用来做二分类。在特征相差比较复杂或是相差不是特别大时效果比较好。Sigmoid作为激活函数有以下优缺点:
优点:平滑、易于求导。
缺点:激活函数计算量大,反向传播求误差梯度时,求导涉及除法;反向传播时,很容易就会出现梯度消失的情况,从而无法完成深层网络的训练。
Sigmoid函数由下列公式定义:
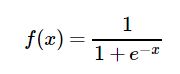
Sigmoid函数的图形如S曲线:更多详情请看
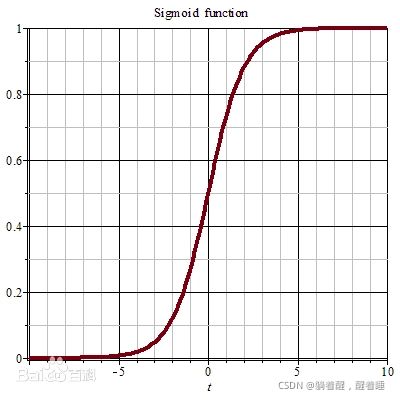
softmax:在数学,尤其是概率论和相关领域中,归一化指数函数,或称Softmax函数,是逻辑函数的一种推广。它能将一个含任意实数的K维向量z“压缩”到另一个K维实向量σ(z)中,使得每一个元素的范围都在(0,1)之间,并且所有元素的和为1。该函数多用于多分类问题中。比如MNIST手写数字辨识。详情请看
4. BatchNormal,Dropout,num_classes,mini_batch
BatchNormal: BatchNormal作用是把数据归一化,这样训练更快,因为把数据集都映射到原点周围了。详情请看
没有它之前,需要小心的调整学习率和权重初始化,但是有了BN可以放心的使用大学习率,但是使用了BN,就不用小心的调参了,较大的学习率极大的提高了学习速度,
Batchnorm本身上也是一种正则的方式,可以代替其他正则方式如dropout等
另外,个人认为,batchnorm降低了数据之间的绝对差异,有一个去相关的性质,更多的考虑相对差异性,因此在分类任务上具有更好的效果。
Dropout:dropout改变之前稠密网络中,权重统一学习,参数统一更新的模式,提出在每次训练迭代中,让网络中的部分参数得到学习,即部分参数得到更新,部分参数保持不更新。详情请看
num_classes:要分类的类别数,比如MNIST共有(0-9)10种类别。
mini_batch:当我们的数据很大时,理论上我们需要将所有的数据作为对象计算损失函数,然后去更新权重,可是这样会浪费很多时间。类比在做用户调查时,理论上我们要获得所有用户的评分再计算平均值,可这样也很浪费时间,但我们知道在调查中,可以用随机抽样的值来近似估计总体的值。于是,我们想要随机选择小批量的数据(Mini Batch)作为样本,来计算损失函数,然后当做总体训练数据的近似值。详情请看
5. receptive field
receptive filed:感知野。在机器视觉领域的深度神经网络中有一个概念叫做感受野,用来表示网络内部的不同位置的神经元对原图像的感受范围的大小。神经元之所以无法对原始图像的所有信息进行感知,是因为在这些网络结构中普遍使用卷积层和pooling层,在层与层之间均为局部相连(通过sliding filter)。神经元感受野的值越大表示其能接触到的原始图像范围就越大,也意味着他可能蕴含更为全局、语义层次更高的特征;而值越小则表示其所包含的特征越趋向于局部和细节。因此感受野的值可以大致用来判断每一层的抽象层次。详情请看
后续补充。。。