从数据分布的角度提高对抗样本的可迁移性
1 引言
对抗迁移性攻击一般是先通过代理模型生成对抗样本,然后将该样本迁移到其它黑盒模型中进行攻击,对抗迁移性的根本原因目前仍有待于探究。以前的工作主要从模型的角度探讨原因,例如决策边界、模型架构和模型容量等。在该论文中,作者从数据分布的角度研究对抗样本的可迁移性,其核心思想是针对于无目标攻击,将图像移出其原始分布会使不同的模型很难对图像进行正确分类。针对于有目标攻击,则是将图像拖入目标分布会误导模型将图像分类为目标类。因此作者提出了一种通过操纵图像的分布来生成对抗样本的新方法。实验结果证明了所提出方法的有效性。
论文链接:https://arxiv.org/abs/2210.04213
论文代码:https://github.com/alibaba/easyrobust
2 预备知识
给定一个参数 θ \theta θ的代理模型 f θ f_\theta fθ,图像 x \boldsymbol{x} x,标签 y y y,其中共 n n n类, f θ ( x ) [ k ] f_\theta(x)[k] fθ(x)[k]表示神经网络最后一层第 k k k类输出,则条件概率 p θ ( y ∣ x ) p_\theta(y|\boldsymbol{x}) pθ(y∣x)表示为
p θ ( y ∣ x ) = exp ( f θ ( x ) [ y ] ) ∑ k = 1 n exp ( f θ ( x ) [ k ] ) p_\theta(y|\boldsymbol{x})=\frac{\exp(f_\theta(\boldsymbol{x})[y])}{\sum\limits_{k=1}^n \exp(f_\theta(\boldsymbol{x})[k])} pθ(y∣x)=k=1∑nexp(fθ(x)[k])exp(fθ(x)[y])对抗扰动通常是损失函数 L \mathcal{L} L关于样本 x \boldsymbol{x} x的梯度,无目标攻击可以表示为:
x ′ = x + ∇ x L ( f θ ( x ) , y ) = x − ∇ x log p θ ( y ∣ x ) \boldsymbol{x}^\prime =\boldsymbol{x}+\nabla_{\boldsymbol{x}}\mathcal{L}(f_\theta(\boldsymbol{x}),y)=\boldsymbol{x}-\nabla_{\boldsymbol{x}}\log p_\theta(y|\boldsymbol{x}) x′=x+∇xL(fθ(x),y)=x−∇xlogpθ(y∣x)其中 x ′ \boldsymbol{x}^\prime x′是 x \boldsymbol{x} x的对抗样本。有目标公式可以表示为 x ′ = x − ∇ x L ( f θ ( x ) , y t a r g e t ) = x + ∇ x log p θ ( y t a r g e t ∣ x ) \boldsymbol{x}^\prime=\boldsymbol{x}-\nabla_{\boldsymbol{x}}\mathcal{L}(f_\theta(\boldsymbol{x}),y_{\mathrm{target}})=\boldsymbol{x}+\nabla_{\boldsymbol{x}}\log p_\theta(y_{\mathrm{target}}|\boldsymbol{x}) x′=x−∇xL(fθ(x),ytarget)=x+∇xlogpθ(ytarget∣x)
3 论文方法
在介绍论文方法之前,需要先对比一下在黑盒迁移攻击中作者的攻击策略与流行攻击策略的不同之处。如下图所示,一般流行的攻击策略先用数据集训练出一个普通的代理分类模型,然后在该代理模型中利用一个好的攻击算法去生成对抗样本,再将该对抗样本迁移到其它黑盒模型中进行攻击,该攻击策略的核心部分在于提出一个好的攻击算法。而论文中,作者的攻击策略是先训练出一个好的代理模型,该分类模型不仅可以正确分类样本,而且可以估计出数据分布关于样本的梯度,然后在该代理模型中利用一个普通攻击算法去生成对抗样本,再将该对抗样本迁移到其它黑盒模型中进行攻击,该攻击策略的核心部分在于提出一个多功能的代理模型分类器。

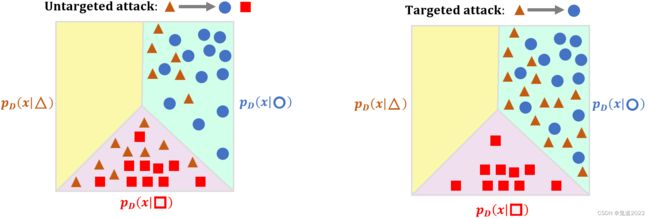
作者从数据分布的视角下提出了一个可以理解和提高对抗样本可迁移性的算法,该算法建立在机器学习方法中的经典假设之上,深度学习模型可以正确分类与训练集独立同分布的验证集的数据,但很难对分布外的样本进行分类,即深度学习模型能够正确将与 p D ( x ∣ y ) p_D(\boldsymbol{x}|y) pD(x∣y)独立同分布的数据分类预测为标签 y y y,但是它不能处理该分布以外的数据。作者假设将图片移动到初始分布以外的区域即可实现迁移性高的无目标攻击,将图片移动到目标分布 p D ( x ∣ y t a r g e t ) p_D(\boldsymbol{x}|y_{\mathrm{target}}) pD(x∣ytarget)即可实现迁移性高的有目标攻击。即如下两图所示:

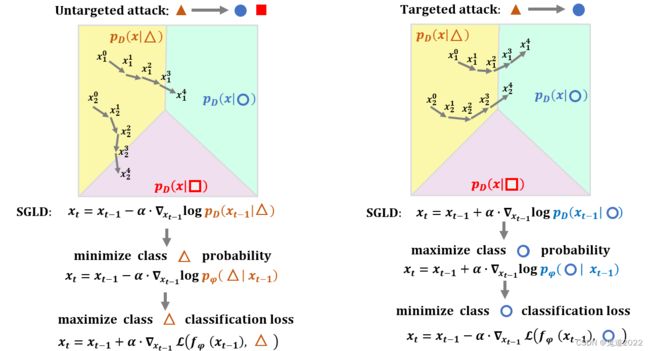
作者借用score-matching生成模型的想法,其中该方法主要估计真实数据分布的梯度,然后通过SGLD的迭代公式将图像从初始分布 P D ( x ∣ y 0 ) P_D(\boldsymbol{x}|y_0) PD(x∣y0)移动到目标分布 P D ( x ∣ y ) P_D(\boldsymbol{x}|y) PD(x∣y)
x t = x t − 1 + α ⋅ ∇ x t − 1 log p D ( x t − 1 ∣ y ) + 2 α ⋅ ϵ \boldsymbol{x}_t = \boldsymbol{x}_{t-1}+\alpha \cdot \nabla_{\boldsymbol{x}_{t-1}}\log p_D(\boldsymbol{x}_{t-1}|y)+\sqrt{2\alpha}\cdot \epsilon xt=xt−1+α⋅∇xt−1logpD(xt−1∣y)+2α⋅ϵ其中 ϵ ∼ N ( 0 , I ) \epsilon \sim\mathcal{N}(0,I) ϵ∼N(0,I), α \alpha α表示固定步长。当 α → 0 \alpha \rightarrow 0 α→0和 T → ∞ T\rightarrow \infty T→∞时, x T \boldsymbol{x}_T xT则精确地从分布 p D ( x ∣ y ) p_D(\boldsymbol{x}|y) pD(x∣y)采样。
作者定义了对数条件概率密度梯度和真实标签条件数据分布梯度的距离公式
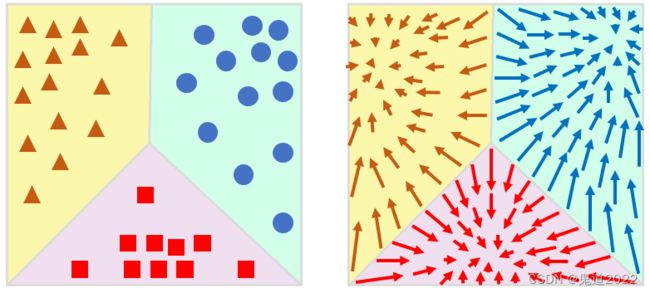
D C G = E p D ( y ) E p D ( x ∣ y ) ∥ ∇ x log p θ ( y ∣ x ) − ∇ x log p D ( x ∣ y ) ∥ 2 2 = ∫ ∫ ∥ ∇ x log p θ ( y ∣ x ) − ∇ x log p D ( x ∣ y ) ∥ 2 2 p D ( x ∣ y ) p D ( y ) d x d y = ∫ ∫ ∥ ∇ x log p D ( x ∣ y ) ∥ 2 2 p D ( x ∣ y ) p D ( y ) d x d y + ∫ ∫ ∥ ∇ x log p θ ( y ∣ x ) ∥ 2 2 p D ( x ∣ y ) p D ( y ) d x d y − 2 ∫ ∫ ( ∇ x log p θ ( y ∣ x ) ⊤ ⋅ ∇ x log p D ( x ∣ y ) ) p D ( x ∣ y ) p D ( y ) d x d y \begin{aligned}\mathrm{DCG}&=\mathbb{E}_{p_D(y)}\mathbb{E}_{p_D(\boldsymbol{x}|y)}\|\nabla_{\boldsymbol{x}}\log p_\theta(y|\boldsymbol{x})-\nabla_{\boldsymbol{x}}\log p_D(\boldsymbol{x}|y)\|_2^2\\&=\int\int\|\nabla_{\boldsymbol{x}}\log p_\theta(y|\boldsymbol{x})-\nabla_{\boldsymbol{x}}\log p_D(\boldsymbol{x}|y)\|_2^2 p_D(\boldsymbol{x}|y)p_D(y)d\boldsymbol{x}dy\\&=\int\int\|\nabla_{\boldsymbol{x}}\log p_D(\boldsymbol{x}|y)\|_2^2 p_D(\boldsymbol{x}|y)p_D(y)d\boldsymbol{x}dy\\&+\int\int\|\nabla_{\boldsymbol{x}}\log p_\theta(y|\boldsymbol{x})\|_2^2 p_D(\boldsymbol{x}|y)p_D(y)d\boldsymbol{x}dy \\&-2\int\int(\nabla_{\boldsymbol{x}}\log p_\theta (y|\boldsymbol{x})^\top\cdot \nabla_{\boldsymbol{x}}\log p_D (\boldsymbol{x}|y))p_D(\boldsymbol{x}|y)p_D(y)d\boldsymbol{x}dy\end{aligned} DCG=EpD(y)EpD(x∣y)∥∇xlogpθ(y∣x)−∇xlogpD(x∣y)∥22=∫∫∥∇xlogpθ(y∣x)−∇xlogpD(x∣y)∥22pD(x∣y)pD(y)dxdy=∫∫∥∇xlogpD(x∣y)∥22pD(x∣y)pD(y)dxdy+∫∫∥∇xlogpθ(y∣x)∥22pD(x∣y)pD(y)dxdy−2∫∫(∇xlogpθ(y∣x)⊤⋅∇xlogpD(x∣y))pD(x∣y)pD(y)dxdy第一项与参数 θ \theta θ无关可以忽略;中间项比较难求因为真实分布不可知;最后一项不能够直接计算,因为 ∇ x log p D ( x ∣ y ) \nabla_{\boldsymbol{x}}\log p_D(\boldsymbol{x}|y) ∇xlogpD(x∣y)是不可知的。利用部分积分法可以对以上公式进行简化,具体推导如下所示 ∫ − ∞ + ∞ p D ( y ) ∫ x ∈ R n ( ∇ x log p θ ( y ∣ x ) ⊤ ⋅ ∇ x log p D ( x ∣ y ) ) p D ( x ∣ y ) d x d y = ∫ − ∞ + ∞ p D ( y ) ∫ x ∈ R n ( ∇ x log p θ ( y ∣ x ) ⊤ ⋅ ∇ x p D ( x ∣ y ) ) d x d y = ∫ − ∞ + ∞ p D ( y ) ∑ i = 1 n ∫ x ∈ R n ∇ x i log p θ ( y ∣ x ) ∇ x i p D ( x ∣ y ) d x d y = ∫ − ∞ + ∞ p D ( y ) ∑ i = 1 n ∫ x ~ i ∈ R n − 1 [ ∫ − ∞ + ∞ ∇ x i log p θ ( y ∣ x ) ∇ x i p D ( x ∣ y ) d x i ] d x ~ i d y = ∫ − ∞ + ∞ p D ( y ) ∑ i = 1 n ∫ x ~ i ∈ R n − 1 [ lim M → ∞ p D ( x ∣ y ) ∇ x i log p θ ( y ∣ x ) ∣ − M i + M i ] d x ~ i d y − ∫ − ∞ + ∞ p D ( y ) ∑ i = 1 n ∫ x ~ i ∈ R n − 1 [ ∫ − ∞ + ∞ p D ( x ∣ y ) ∇ x i 2 log p θ ( y ∣ x ) d x i ] d x ~ i d y = ∫ − ∞ + ∞ p D ( y ) ∑ i = 1 n ∫ x ~ i ∈ R n − 1 [ lim M → ∞ p D ( x ∣ y ) ∇ x i log p θ ( y ∣ x ) ∣ − M i + M i ] d x ~ i − ∫ − ∞ + ∞ p D ( y ) ∑ i = 1 n ∫ x ∈ R n [ p D ( x ∣ y ) ∇ x i 2 log p θ ( y ∣ x ) ] d x d y = ∫ − ∞ ∞ p D ( y ) d y ∑ i = 1 n ∫ x ~ ∈ R n − 1 [ lim M → ∞ p D ( x ∣ y ) ∇ x i log p θ ( y ∣ x ) ∣ − M i + M i ] d x ~ i d y − E p D ( y ) E p D ( x ∣ y ) [ t r ( ∇ x 2 log p θ ( y ∣ x ) ) ] = − E p D ( y ) E p D ( x ∣ y ) [ t r ( ∇ x 2 log p θ ( y ∣ x ) ) ] \begin{aligned}&\int_{-\infty}^{+\infty}p_D(y)\int_{\boldsymbol{x}\in\mathbb{R}^n}(\nabla_{\boldsymbol{x}}\log p_\theta(y|\boldsymbol{x})^{\top}\cdot\nabla_{\boldsymbol{x}}\log p_D(\boldsymbol{x}|y))p_D(\boldsymbol{x}|y)d\boldsymbol{x}dy\\=&\int_{-\infty}^{+\infty}p_D(y)\int_{\boldsymbol{x}\in\mathbb{R}^n}(\nabla_{\boldsymbol{x}}\log p_\theta(y|\boldsymbol{x})^\top \cdot \nabla_{\boldsymbol{x}}p_D(\boldsymbol{x}|y))d\boldsymbol{x}dy\\=&\int_{-\infty}^{+\infty}p_D(y)\sum\limits_{i=1}^n\int_{\boldsymbol{x}\in \mathbb{R}^n}\nabla_{x_i}\log p_\theta (y|\boldsymbol{x})\nabla_{x_i}p_D(\boldsymbol{x}|y)d\boldsymbol{x}dy\\=&\int_{-\infty}^{+\infty}p_D(y)\sum\limits_{i=1}^n \int_{\tilde{\boldsymbol{x}}_i\in\mathbb{R}^{n-1}}\left[\int_{-\infty}^{+\infty}\nabla_{x_i}\log p_\theta (y|\boldsymbol{x})\nabla_{x_i}p_D(\boldsymbol{x}|y)dx_i\right]d\tilde{\boldsymbol{x}}_idy\\=&\int_{-\infty}^{+\infty}p_D(y)\sum\limits_{i=1}^n\int_{\tilde{\boldsymbol{x}}_i\in \mathbb{R}^{n-1}}\left[\lim\limits_{M\rightarrow \infty}p_D(\boldsymbol{x}|y)\nabla_{\boldsymbol{x}_i}\log p_\theta(y|\boldsymbol{x})|_{-M_i}^{+M_i}\right]d\tilde{\boldsymbol{x}}_idy\\-&\int_{-\infty}^{+\infty}p_D(y)\sum\limits_{i=1}^n\int_{\tilde{\boldsymbol{x}}_i\in\mathbb{R}^{n-1}}\left[\int_{-\infty}^{+\infty}p_D(\boldsymbol{x}|y)\nabla_{x_i}^2 \log p_\theta (y|\boldsymbol{x})dx_i\right]d\tilde{\boldsymbol{x}}_idy\\=&\int_{-\infty}^{+\infty}p_D(y)\sum\limits_{i=1}^n \int_{\tilde{\boldsymbol{x}}_i\in\mathbb{R}^{n-1}}\left[\lim\limits_{M\rightarrow \infty}p_D(\boldsymbol{x}|y)\nabla_{x_i}\log p_\theta(y|\boldsymbol{x})|_{-M_i}^{+M_i}\right]d\tilde{\boldsymbol{x}}_i\\-&\int_{-\infty}^{+\infty}p_D(y)\sum\limits_{i=1}^n\int_{\boldsymbol{x}\in\mathbb{R}^n}\left[p_D(\boldsymbol{x}|y)\nabla_{x_i}^2 \log p_\theta (y|\boldsymbol{x})\right]d\boldsymbol{x}dy\\=&\int_{-\infty}^{\infty}p_D(y)dy\sum\limits_{i=1}^n\int_{\tilde{\boldsymbol{x}}\in\mathbb{R}^{n-1}}\left[\lim\limits_{M\rightarrow \infty}p_D(\boldsymbol{x}|y)\nabla_{x_i}\log p_\theta(y|\boldsymbol{x})|^{+M_i}_{-M_i}\right]d\tilde{\boldsymbol{x}}_idy\\-&\mathbb{E}_{p_D(y)}\mathbb{E}_{p_D(\boldsymbol{x}|y)}\left[\mathrm{tr}(\nabla_{\boldsymbol{x}}^2\log p_\theta(y|\boldsymbol{x}))\right]\\=&-\mathbb{E}_{p_D(y)}\mathbb{E}_{p_D(\boldsymbol{x}|y)}\left[\mathrm{tr}(\nabla^2_{\boldsymbol{x}}\log p_\theta(y|\boldsymbol{x}))\right]\end{aligned} ====−=−=−=∫−∞+∞pD(y)∫x∈Rn(∇xlogpθ(y∣x)⊤⋅∇xlogpD(x∣y))pD(x∣y)dxdy∫−∞+∞pD(y)∫x∈Rn(∇xlogpθ(y∣x)⊤⋅∇xpD(x∣y))dxdy∫−∞+∞pD(y)i=1∑n∫x∈Rn∇xilogpθ(y∣x)∇xipD(x∣y)dxdy∫−∞+∞pD(y)i=1∑n∫x~i∈Rn−1[∫−∞+∞∇xilogpθ(y∣x)∇xipD(x∣y)dxi]dx~idy∫−∞+∞pD(y)i=1∑n∫x~i∈Rn−1[M→∞limpD(x∣y)∇xilogpθ(y∣x)∣−Mi+Mi]dx~idy∫−∞+∞pD(y)i=1∑n∫x~i∈Rn−1[∫−∞+∞pD(x∣y)∇xi2logpθ(y∣x)dxi]dx~idy∫−∞+∞pD(y)i=1∑n∫x~i∈Rn−1[M→∞limpD(x∣y)∇xilogpθ(y∣x)∣−Mi+Mi]dx~i∫−∞+∞pD(y)i=1∑n∫x∈Rn[pD(x∣y)∇xi2logpθ(y∣x)]dxdy∫−∞∞pD(y)dyi=1∑n∫x~∈Rn−1[M→∞limpD(x∣y)∇xilogpθ(y∣x)∣−Mi+Mi]dx~idyEpD(y)EpD(x∣y)[tr(∇x2logpθ(y∣x))]−EpD(y)EpD(x∣y)[tr(∇x2logpθ(y∣x))]其中 ∇ x \nabla_{\boldsymbol{x}} ∇x表示关于 x \boldsymbol{x} x的Hessian矩阵, + M i +M_i +Mi表示向量 [ x 1 , ⋯ , x i − 1 , + M , x i + 1 , ⋯ , x n ] [x_1,\cdots,x_{i-1},+M,x_{i+1},\cdots,x_n] [x1,⋯,xi−1,+M,xi+1,⋯,xn]; − M i -M_i −Mi表示向量 [ x 1 , ⋯ , x i − 1 , − M , x i + 1 , ⋯ , x n ] [x_1,\cdots,x_{i-1},-M,x_{i+1},\cdots,x_n] [x1,⋯,xi−1,−M,xi+1,⋯,xn]。 x = [ x 1 , ⋯ , x n ] \boldsymbol{x}=[x_1,\cdots,x_n] x=[x1,⋯,xn]表示 n n n维向量。 x ~ i = [ x 1 , ⋯ , x i − 1 , x i + 1 , ⋯ , x n ] \tilde{x}_i=[x_1,\cdots,x_{i-1},x_{i+1},\cdots,x_n] x~i=[x1,⋯,xi−1,xi+1,⋯,xn]。因为当 ∥ x ∥ 2 → ∞ \|\boldsymbol{x}\|_2\rightarrow \infty ∥x∥2→∞时,概率分布 p D ( x ∣ y ) → 0 p_D(\boldsymbol{x}|y)\rightarrow 0 pD(x∣y)→0,进而则有如下公式 ∫ − ∞ + ∞ ∇ x i f ( x ) ∇ x i g ( x ) d x i = lim M → ∞ g ( x ) ∇ x i f ( x ) ∣ − M i + M i − ∫ − ∞ + ∞ g ( x ) ∇ x i 2 f ( x ) d x i \int_{-\infty}^{+\infty}\nabla_{x_i}f(\boldsymbol{x})\nabla_{x_i}g(\boldsymbol{x})dx_i=\lim\limits_{M\rightarrow \infty}g(\boldsymbol{x})\nabla_{x_i}f(\boldsymbol{x})|_{-M_i}^{+M_i}-\int_{-\infty}^{+\infty}g(\boldsymbol{x})\nabla_{x_i}^2f(\boldsymbol{x})dx_i ∫−∞+∞∇xif(x)∇xig(x)dxi=M→∞limg(x)∇xif(x)∣−Mi+Mi−∫−∞+∞g(x)∇xi2f(x)dxi综上所述,DCG距离公式可以重新表示为 D C G = E p D ( y ) E p D ( x ∣ y ) ∥ ∇ x log p θ ( y ∣ x ) − ∇ x log p D ( x ∣ y ) ∥ 2 2 = E p D ( y ) E p D ( x ∣ y ) ∥ ∇ x log p θ ( y ∣ x ) ∥ 2 2 + 2 E p D ( y ) E p D ( x ∣ y ) [ t r ( ∇ x 2 log p θ ( y ∣ x ) ) ] + c o n s t \begin{aligned}\mathrm{DCG}&=\mathbb{E}_{p_D(y)}\mathbb{E}_{p_D(\boldsymbol{x}|y)}\|\nabla_{\boldsymbol{x}}\log p_\theta(y|\boldsymbol{x})-\nabla_{\boldsymbol{x}}\log p_D(\boldsymbol{x}|y)\|_2^2\\&=\mathbb{E}_{p_D(y)}\mathbb{E}_{p_D}(\boldsymbol{x}|y)\|\nabla_{\boldsymbol{x}}\log p_\theta(y|\boldsymbol{x})\|_2^2+2\mathbb{E}_{p_D(y)}\mathbb{E}_{p_D(\boldsymbol{x}|y)}\left[\mathrm{tr}(\nabla^2_{\boldsymbol{x}}\log p_\theta(y|\boldsymbol{x}))\right]+\mathrm{const}\end{aligned} DCG=EpD(y)EpD(x∣y)∥∇xlogpθ(y∣x)−∇xlogpD(x∣y)∥22=EpD(y)EpD(x∣y)∥∇xlogpθ(y∣x)∥22+2EpD(y)EpD(x∣y)[tr(∇x2logpθ(y∣x))]+const忽略常数项,进而则有 L D C G = E p D ( y ) E p D ( x ∣ y ) ∥ ∇ x log p θ ( y ∣ x ) ∥ 2 2 + 2 E p D ( y ) E p D ( x ∣ y ) [ t r ( ∇ x 2 log p θ ( y ∣ x ) ) ] \mathcal{L}_{\mathrm{DCG}}=\mathbb{E}_{p_D(y)}\mathbb{E}_{p_D}(\boldsymbol{x}|y)\|\nabla_{\boldsymbol{x}}\log p_\theta(y|\boldsymbol{x})\|_2^2+2\mathbb{E}_{p_D(y)}\mathbb{E}_{p_D(\boldsymbol{x}|y)}\left[\mathrm{tr}(\nabla^2_{\boldsymbol{x}}\log p_\theta(y|\boldsymbol{x}))\right] LDCG=EpD(y)EpD(x∣y)∥∇xlogpθ(y∣x)∥22+2EpD(y)EpD(x∣y)[tr(∇x2logpθ(y∣x))]以上公式涉及到求解Hessian矩阵的迹,当矩阵的维度很高时,计算量也会飙升。当给定任意方阵 A \boldsymbol{A} A,可以采用一种随机算法去估计矩阵的迹 t r ( A ) \mathrm{tr}(\boldsymbol{A}) tr(A),给定一个随机向量 v \boldsymbol{v} v且有 E p ( v ) [ v v ⊤ ] = I \mathbb{E}_{p(\boldsymbol{v})}\left[\boldsymbol{v}\boldsymbol{v}^\top\right]=I Ep(v)[vv⊤]=I,进而则有 t r ( A ) = E p ( v ) [ v ⊤ A v ] \mathrm{tr}({\boldsymbol{A}})=\mathbb{E}_{p(\boldsymbol{v})}\left[\boldsymbol{v}^\top\boldsymbol{A}\boldsymbol{v}\right] tr(A)=Ep(v)[v⊤Av]。所以可以用 E p ( v ) [ v ⊤ ∇ x 2 log p θ ( y ∣ x ) v ] \mathbb{E}_{p(\boldsymbol{v})}\left[\boldsymbol{v}^\top\nabla_{\boldsymbol{x}}^2\log p_\theta(y|\boldsymbol{x})\boldsymbol{v}\right] Ep(v)[v⊤∇x2logpθ(y∣x)v]代替矩阵的迹 t r ( ∇ x 2 log p θ p ( y ∣ x ) ) \mathrm{tr}(\nabla_{\boldsymbol{x}}^2\log p_\theta p(y|\boldsymbol{x})) tr(∇x2logpθp(y∣x)),所以损失函数 D C G \mathcal{\mathrm{DCG}} DCG可以表示为 L D C G = E p D ( y ) E p D ( x ∣ y ) ∥ ∇ x log p θ ( y ∣ x ) ∥ 2 2 + 2 E p D ( y ) E p D ( x ∣ y ) E p ( v ) [ v ⊤ ∇ x 2 log p θ ( y ∣ x ) v ] \mathcal{L}_{\mathrm{DCG}}=\mathbb{E}_{p_D(y)}\mathbb{E}_{p_D}(\boldsymbol{x}|y)\|\nabla_{\boldsymbol{x}}\log p_\theta(y|\boldsymbol{x})\|_2^2+2\mathbb{E}_{p_D(y)}\mathbb{E}_{p_D(\boldsymbol{x}|y)}\mathbb{E}_{p(\boldsymbol{v})}\left[\boldsymbol{v}^\top\nabla^2_{\boldsymbol{x}}\log p_\theta(y|\boldsymbol{x})\boldsymbol{v}\right] LDCG=EpD(y)EpD(x∣y)∥∇xlogpθ(y∣x)∥22+2EpD(y)EpD(x∣y)Ep(v)[v⊤∇x2logpθ(y∣x)v]作者首先通过用交叉熵损失和DCG损失联合训练出一个代理模型,优化目标如下所示 min θ [ L ( f θ ( x ) , y ) + λ L D C G ] \min\limits_{\theta}\left[\mathcal{L}(f_\theta(x),y)+\lambda \mathcal{L}_{\mathrm{DCG}}\right] θmin[L(fθ(x),y)+λLDCG]其中 λ \lambda λ表示正则化系数。模型训练结束后可以得到如下图所示的梯度分布,其中可以发现梯度是从样本点稀疏的区域流向样本点密集的区域,而且样本点稀疏的区域梯度值更大,样本点密集区梯度值更小。
之后再用该代理模型生成对抗样本,无目标攻击的形式如下所示 { x n = x n − 1 + η ⋅ s i g n ( ∇ x n − 1 L ( f θ ( x n − 1 ) , y l a b e l ) x n = c l i p ( x n , x 0 − ϵ , x 0 + ϵ ) \left\{\begin{aligned}\boldsymbol{x}_n&=\boldsymbol{x}_{n-1}+\eta \cdot \mathrm{sign}(\nabla_{\boldsymbol{x}_{n-1}}\mathcal{L}(f_\theta(\boldsymbol{x}_{n-1}),y_{\mathrm{label}})\\\boldsymbol{x}_n&=\mathrm{clip}(\boldsymbol{x}_n,\boldsymbol{x}_0-\epsilon,\boldsymbol{x}_0+\epsilon)\end{aligned}\right. {xnxn=xn−1+η⋅sign(∇xn−1L(fθ(xn−1),ylabel)=clip(xn,x0−ϵ,x0+ϵ)有目标攻击的形式表示为 { x n = x n − 1 − η ⋅ s i g n ( ∇ x n − 1 L ( f θ ( x n − 1 ) , y t a r g e t ) x n = c l i p ( x n , x 0 − ϵ , x 0 + ϵ ) \left\{\begin{aligned}\boldsymbol{x}_n&=\boldsymbol{x}_{n-1}-\eta \cdot \mathrm{sign}(\nabla_{\boldsymbol{x}_{n-1}}\mathcal{L}(f_\theta(\boldsymbol{x}_{n-1}),y_{\mathrm{target}})\\\boldsymbol{x}_n&=\mathrm{clip}(\boldsymbol{x}_n,\boldsymbol{x}_0-\epsilon,\boldsymbol{x}_0+\epsilon)\end{aligned}\right. {xnxn=xn−1−η⋅sign(∇xn−1L(fθ(xn−1),ytarget)=clip(xn,x0−ϵ,x0+ϵ)综上所述可以发现,之前对抗迁移性的工作都是基于优化的方法,而本文作者则是关注点放在真实数据分布上,首先将真实数据分布关于样本的梯度与代理模型分布关于样本的梯度相匹配。然后在训练好的代理模型上生成对抗样本,具体过程如下图所示。
实验结果
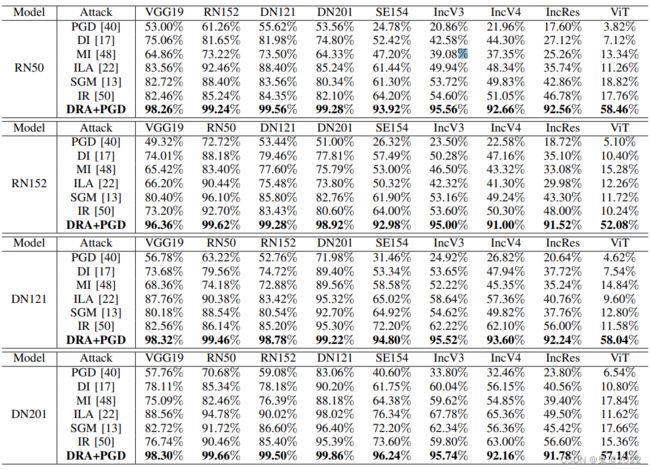
该论文的实验结果非常出色,如下图所示为在黑盒迁移攻击下,不同的攻击算法的无目标攻击的攻击成功率。可以惊奇的发现论文中提出的方法的攻击成功率比其它攻击算法要高出一个等级,甚至在某些模型中如VGG19,RN152,DN121和DN201模型,其黑盒迁移攻击成功率要直逼白盒攻击成功率。
下图是论文的一个定性的结果,可以清晰的发现,当源类目标为青蛙,目标攻击类为玉米的时候,可以发现论文中提出的攻击方法生成的对抗样本在青蛙的腿上有清晰的玉米特征。

代码实现
论文的代码已开源,为了能够更好的理解论文方法,以下程序是根据论文的算法流程图编写的一个在mnist数据集上的一个简易的程序。论文中的损失函数变成起来较为棘手,原始的损失函数如下所示 L D C G = E p D ( y ) E p D ( x ∣ y ) ∥ ∇ x log p θ ( y ∣ x ) ∥ 2 2 + 2 E p D ( y ) E p D ( x ∣ y ) E p ( v ) [ v ⊤ ∇ x 2 log p θ ( y ∣ x ) v ] \mathcal{L}_{\mathrm{DCG}}=\mathbb{E}_{p_D(y)}\mathbb{E}_{p_D}(\boldsymbol{x}|y)\|\nabla_{\boldsymbol{x}}\log p_\theta(y|\boldsymbol{x})\|_2^2+2\mathbb{E}_{p_D(y)}\mathbb{E}_{p_D(\boldsymbol{x}|y)}\mathbb{E}_{p(\boldsymbol{v})}\left[\boldsymbol{v}^\top\nabla^2_{\boldsymbol{x}}\log p_\theta(y|\boldsymbol{x})\boldsymbol{v}\right] LDCG=EpD(y)EpD(x∣y)∥∇xlogpθ(y∣x)∥22+2EpD(y)EpD(x∣y)Ep(v)[v⊤∇x2logpθ(y∣x)v]需要对该损失函数的形式进行一定的变换,变换形式如下所示: L D C G = E p D ( x , y ) ∥ ∇ x log p θ ( y ∣ x ) ∥ 2 2 + 2 E p D ( x , y ) E p ( v ) [ v ⊤ ∇ x 2 log p θ ( y ∣ x ) v ] \mathcal{L}_{\mathrm{DCG}}=\mathbb{E}_{p_D(x,y)}\|\nabla_{\boldsymbol{x}}\log p_\theta(y|\boldsymbol{x})\|_2^2+2\mathbb{E}_{p_D(x,y)}\mathbb{E}_{p(\boldsymbol{v})}\left[\boldsymbol{v}^\top\nabla^2_{\boldsymbol{x}}\log p_\theta(y|\boldsymbol{x})\boldsymbol{v}\right] LDCG=EpD(x,y)∥∇xlogpθ(y∣x)∥22+2EpD(x,y)Ep(v)[v⊤∇x2logpθ(y∣x)v]进一步可得其离散的形式为,根据离散形式的损失函数,可以更好地对论文算法进行实现。 L D C G = 1 N ∑ i = 1 N ∥ ∇ x i log p θ ( y i ∣ x i ) ∥ 2 2 + 2 M N ∑ i = 1 N ∑ j = 1 M [ v j ⊤ ∇ x i 2 log p θ ( y i ∣ x i ) v j ] \mathcal{L}_{\mathrm{DCG}}=\frac{1}{N}\sum\limits_{i=1}^N\|\nabla_{\boldsymbol{x}_i}\log p_\theta(y_i|\boldsymbol{x}_i)\|_2^2+\frac{2}{M N}\sum\limits_{i=1}^N\sum\limits_{j=1}^M\left[\boldsymbol{v}_j^\top\nabla^2_{\boldsymbol{x}_i}\log p_\theta(y_i|\boldsymbol{x}_i)\boldsymbol{v}_j\right] LDCG=N1i=1∑N∥∇xilogpθ(yi∣xi)∥22+MN2i=1∑Nj=1∑M[vj⊤∇xi2logpθ(yi∣xi)vj]
from torchvision import datasets, transforms
from torch.utils.data import DataLoader, Dataset
import torch
import torch.nn as nn
from torch.autograd import Variable
import torch.optim as optim
import torch.nn.functional as F
import os
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.fc1 = nn.Linear(784, 300)
self.fc2 = nn.Linear(300, 100)
self.fc3 = nn.Linear(100, 10)
def forward(self, x):
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
out = self.fc3(x)
return out
def DR_training():
lambda1 = 0
lambda2 = 1
epoch = 5
model = Net()
optimizer = torch.optim.SGD(model.parameters(), lr=0.005)
loss_fn = torch.nn.CrossEntropyLoss()
use_cuda = torch.cuda.is_available()
mnist_transform = transforms.Compose([transforms.ToTensor(), transforms.Lambda(lambda x : x.resize_(28*28))])
mnist_train = datasets.MNIST(root="mnist-data", train=True, download=True, transform=mnist_transform)
train_loader = torch.utils.data.DataLoader(mnist_train, batch_size=32, shuffle=True, num_workers=0)
for epoch_idx in range(epoch):
for batch_idx, (inputs, targets) in enumerate(train_loader):
if use_cuda:
inputs, targets = inputs.cuda(), targets.cuda()
inputs, targets = Variable(inputs), Variable(targets)
inputs.requires_grad_(True)
predict = model(inputs)
CE_loss = loss_fn(predict, targets)
# DCG loss
# Grad loss
log_pro = torch.log(F.softmax(predict, 1))
log_pro_target = log_pro.gather(1, targets.view(-1,1)).squeeze(1)
grad = torch.autograd.grad(log_pro_target, inputs, grad_outputs = torch.ones_like(log_pro_target), retain_graph = True, create_graph=True)
DCG_grad_loss = torch.mean(torch.norm(grad[0], dim = 1, p = 2))
# Hessian loss
v = torch.rand_like(inputs)
v = v / torch.norm(v, dim = -1, keepdim = True)
mid_vector = torch.sum(v * grad[0], dim = 1)
grad2 = torch.autograd.grad(mid_vector, inputs, grad_outputs = torch.ones_like(mid_vector), retain_graph = True, create_graph = True)
DCG_Hessian_loss = torch.mean(torch.sum(v * grad2[0], dim = 1))
DCG_loss = DCG_grad_loss + 2 * DCG_Hessian_loss
loss = lambda1 * CE_loss + lambda2 * DCG_loss
print('CE_loss: ', CE_loss.item(), 'grad_loss: ', DCG_grad_loss.item(), 'Hessian_loss: ', DCG_Hessian_loss.item(), 'loss: ',loss.item)
optimizer.zero_grad()
loss.backward()
optimizer.step()
print('successful')
if __name__ == '__main__':
DR_training()