【AI视野·今日CV 计算机视觉论文速览 第193期】Fri, 7 May 2021
AI视野·今日CS.CV 计算机视觉论文速览
Fri, 7 May 2021
Totally 64 papers
上期速览✈更多精彩请移步主页

Interesting:
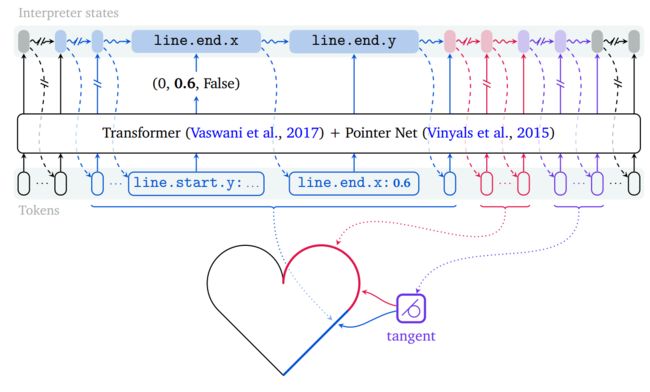
*****DeepMind提出的基于语言模型的自动CAD建模方法, 可以辅助设计人员低成本高效地绘制2D CAD草图。(from DeepMind)

*****前向传播堆叠网络, 通过简单的前向传播层堆叠实现了接近transformer的效果。(from 牛津)

code:https://github.com/lukemelas/do-you-even-need-attention
acorn:针对大型多边形三维物体的自适应渲染方法, 提出了一种混合的显试-隐式模型和八叉树的方式来进行多尺度坐标分解和处理大规模的渲染问题。(from 斯坦福)



website: http://computationalimaging.org/publications/acorn
基于双边transformer的手写数学公式识别, (from 北大)

code:https://github.com/Green-Wood/BTTR
一种可以将骨架/动捕标志点映射到人物上形成动作的方法, (from 北大和北影)

DroneCrowd, 无人机检测、追踪、计数数据集(from JD Finance America Corporation)
dataset: https://github.com/VisDrone/DroneCrowd
多模态图形态领域信息的融合学习, (from 斯坦福)

基于非监督的图像匹配, (from Inria Sophia-Antipolis)
基于文本对监控视频中的人进行自动检索, (from Ahmedabad University, India)

可解释的文本问答模型, 基于视觉和文本实现可解释性.(from 亚马逊)


link:https://www.amazon.jobs/en/teams/product-assurance-risk-security
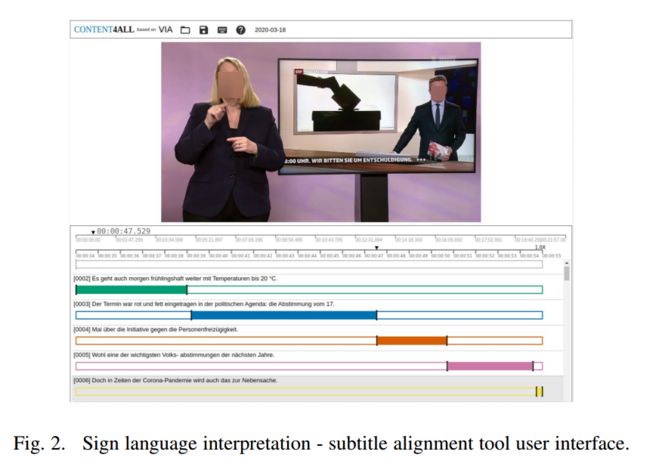
Content4All, 手语翻译数据集(from 萨里大学)
dataset: https://www.cvssp.org/data/c4a-news-corpus
Daily Computer Vision Papers
| Q-Match: Iterative Shape Matching via Quantum Annealing Authors Marcel Seelbach Benkner, Zorah L hner, Vladislav Golyanik, Christof Wunderlich, Christian Theobalt, Michael Moeller 找到形状对应关系可以配制为NP硬二次分配问题QAP,其变形密度具有高的形状。有希望的研究方向是通过Quantum退火的二进制变量来解决这些二元优化问题,从而理论上允许找到依赖于新的计算范例的全球最佳解决方案。不幸的是,通过罚款强制执行QAP中的线性平等约束显着限制了当前可用量子硬件上这些方法的成功概率。为了解决这些限制,本文提出了Q匹配,即由α扩展算法启发的QAP的新迭代量子方法,这允许求解大于电流量子方法的数量级的问题。它通过以循环方式更新当前估计来隐式强制执行QAP约束来工作。此外,Q匹配可以迭代地应用于形状匹配问题,在良好选择的对应关系中,允许我们扩展到现实世界问题。使用最新的量子退火器D波优势,我们评估了在QAPLIB的子集上的提出方法以及来自FAUST DataSet的等距形状匹配问题。 |
| Aligning Subtitles in Sign Language Videos Authors Hannah Bull, Triantafyllos Afouras, G l Varol, Samuel Albanie, Liliane Momeni, Andrew Zisserman 这项工作的目标是在暂时对齐在手语视频中的异步字幕。特别是,我们专注于手语解释的电视广播数据,包括我是与音频内容对应的连续签名的视频和II字幕。以前的工作利用此类弱对齐数据仅考虑查找关键字标志对应关系,而我们旨在在连续签名中本地化完整的字幕文本。我们提出了一种为此任务量身定制的变压器体系结构,我们在手动注释的对齐方面培养超过15K字幕的跨越17.7小时的视频。我们使用BERT字幕嵌入式和CNN视频表示,以便签署识别来编码两个信号,通过一系列注意层进行交互。我们的模型输出帧级别预测,即对于每个视频帧,无论是属于查询的字幕还是不属于查询的字幕。通过广泛的评估,我们对现有的对齐基线显示出实质性的改进,这些基线不会使用字幕文本嵌入进行学习。我们的自动对准模型通过提供连续同步的视频文本数据,为推进语言翻译的可能性。 |
| Deep Polarization Imaging for 3D shape and SVBRDF Acquisition Authors Valentin Deschaintre, Yiming Lin, Abhijeet Ghosh 我们介绍了一种用于使用极化线索有效地采集形状和空间变化的3D对象的空间变化反射的方法。与以前的作品不同,这些作品在某些约束下估计材料或物体外观的已知形状或多视图采集,我们通过耦合具有深度学习的偏振成像来实现这种限制,以实现使用单个3D对象形状的高度估计的3D对象形状正常和深度和SVBRDF俯视偏振光照明下的偏振成像。除了获得的偏振图像之外,我们还提供了具有与形状和反射率相关的强大新型线索的深网络,以标准化的斯托克斯地图和弥漫性颜色的估计。我们另外描述对网络架构和培训损失的修改,提供了进一步的定性改进。与近期工程相比,我们展示了我们实现卓越的结果,与闪光照明结合使用深度学习。 |
| Animatable Neural Radiance Fields for Human Body Modeling Authors Sida Peng, Junting Dong, Qianqian Wang, Shangzhan Zhang, Qing Shuai, Hujun Bao, Xiaowei Zhou 本文解决了从多视图视频重建动画人体模型的挑战。最近的一些作品已经提出将动态场景分解为规范神经辐射场和一组变形字段,即将观察空间点映射到规范空间,从而使它们能够从图像中学习动态场景。然而,它们代表变形场作为翻译矢量场或SE 3场,这使得优化高度受到约束。此外,这些表示不能通过输入运动明确控制。相反,我们介绍了神经混合体重以产生变形领域。基于骨架驱动变形,混合重量与3D人骨骼一起使用,以产生对典范和规范的观察和观察对应。由于3D人类骨架更可观察到,它们可以规范变形领域的学习。此外,学习的混合权重场可以与输入骨架运动组合以产生新的变形字段以为人类模型进行动画。实验表明,我们的方法显着优于最近的人类合成方法。代码将可用 |
| Online Preconditioning of Experimental Inkjet Hardware by Bayesian Optimization in Loop Authors Alexander E. Siemenn, Matthew Beveridge, Tonio Buonassisi, Iddo Drori 高性能半导体光电子等钙钛矿具有高维和庞大的构图空间,用于控制材料的性能特性。为了有效地搜索这些组合物空间,我们利用了通过喷墨沉积快速打印离散液滴的高通量试验方法,其中每个液滴包括半导体材料的独特置换。然而,喷墨打印机系统未经过优化以在半导体材料上运行高吞吐量实验。因此,在这项工作中,我们开发了一种计算机视觉驱动的贝叶斯优化框架,用于优化来自喷墨打印机的沉积液滴结构,使得它被调谐以在半导体材料上执行高吞吐量实验。此框架的目标是使用最少数量的液滴样本在最短的时间内调谐到喷墨打印机的硬件条件,使得我们最大限度地减少在设置系统发现应用程序的系统上的时间和资源。我们在10分钟内展示了最佳喷墨硬件条件的收敛,使用贝叶斯优化的计算机视觉得分液滴结构。我们将贝叶斯优化结果与随机梯度下降进行比较。 |
| Multi-Perspective LSTM for Joint Visual Representation Learning Authors Alireza Sepas Moghaddam, Fernando Pereira, Paulo Lobato Correia, Ali Etemad 我们提出了一种新的LSTM单元架构,其能够在多个视角捕获的视觉序列中学习可用的内部和透视关系。我们的架构采用了一种新的经常性联合学习策略,在细胞层面使用额外的盖茨和记忆。我们证明,通过使用所提出的单元来创建网络,可以获得更有效和更丰富的视觉表示用于识别任务。我们在两个多透视视觉识别任务的上下文中验证了我们所提出的架构的性能,即唇读和面部识别。考虑了三个相关数据集,并将结果与融合策略,其他现有的多输入LSTM架构进行比较,以及替代识别解决方案。实验表明我们在识别准确性和复杂性方面对所考虑的基准解决方案的优越性。我们将我们的代码公开提供 |
| Object-centric Video Prediction without Annotation Authors Karl Schmeckpeper, Georgios Georgakis, Kostas Daniilidis 为了与世界互动,代理商必须能够预测世界动态的结果。通过视频预测来了解这些动态的自然方法,因为相机是无处不在的传感器。引导像素到像素视频预测是困难的,不利用已知的前沿的优势,并且不提供易于利用学习动态的界面。对象中心视频预测通过利用世界对物体制成的简单来提供这些问题的解决方案,并通过提供更自然的控制接口。然而,现有的对象以中心视频预测管道需要在训练视频序列中进行密集的物体注释。在这项工作中,我们在没有注释OPA的情况下呈现对象中心预测,该对象以中心为中心的视频预测方法,其利用来自强大的计算机视觉模型的前沿。我们在由堆叠对象的视频序列组成的数据集上验证了我们的方法,并演示了如何通过端结束视频预测培训在环境中调整感知模型。 |
| Real-Time Video Super-Resolution by Joint Local Inference and Global Parameter Estimation Authors Noam Elron, Alex Itskovich, Shahar S. Yuval, Noam Levy 视频超分辨率SR中最先进的技术是基于深度学习的技术,但它们在现实世界视频上表现不佳,请参见图1。原因是通过缩小高分辨率图像来产生低分辨率对应物,通常创建训练图像对。因此,深层模型训练以撤消缩减,并不概括为超级解决现实世界形象。最近的几种出版物目前用于改善基于学习的SR的概括,但都非常适合实时应用。 |
| ACORN: Adaptive Coordinate Networks for Neural Scene Representation Authors Julien N. P. Martel, David B. Lindell, Connor Z. Lin, Eric R. Chan, Marco Monteiro, Gordon Wetzstein 神经表示作为渲染,成像,几何建模和模拟中的应用程序的新范式。与传统表示相比,例如网格,点云或卷,它们可以灵活地结合到基于可分辨的学习的管道中。虽然最近对神经表示的改进现在可以在中等分辨率下表示具有细节的信号,例如,用于图像和3D形状,充分代表大规模或复杂的场景已经证明了挑战。目前的神经表示未能准确地代表大于百万像素或3D场景的分辨率,具有超过几十万多边形的分辨率。在这里,我们介绍了一种新的混合隐式显式网络架构和培训策略,其基于感兴趣的信号的局部复杂性,在训练和推理期间自适应地分配资源。我们的方法使用多尺度块坐标分解,类似于在训练期间优化的四叉树或八角体。网络架构在两个阶段使用大量网络参数操作,坐标编码器在单个向前通过中生成特征网格。然后,可以使用轻量级特征解码器有效地评估每个块内的数百或数千个样本。通过这种混合隐式显式网络架构,我们证明了将Gigapixel图像拟合到近40dB峰值信号的第一个实验到噪声比。值得注意的是,与先前显示的图像配合实验的分辨率相比,这表示超过1000倍的规模增加。此外,我们的方法能够明显表示3D形状,比以前的技术更快,更好地通过数量级从天到几小时或分钟和内存要求减少训练时间。 |
| Computer-Aided Design as Language Authors Yaroslav Ganin, Sergey Bartunov, Yujia Li, Ethan Keller, Stefano Saliceti 计算机辅助设计CAD应用程序用于制造,以将所有内容从咖啡杯到跑车模拟。这些计划很复杂,需要多年的培训和经验。所有CAD模型的组件特别难以制作,是躺在每个3D构造的核心的高度结构化的2D草图。在这项工作中,我们提出了一种能够自动产生这种草图的机器学习模型。通过这一点,我们为开发智能工具铺平了道路,这些工具将帮助工程师创造更好的设计,较少的努力。我们的方法是一般目的语言建模技术的组合,沿着货架数据序列化协议。我们表明我们的方法有足够的灵活性来适应域的复杂性,并对无条件综合和图像表现良好,以绘制翻译。 |
| Pose-Guided Sign Language Video GAN with Dynamic Lambda Authors Christopher Kissel, Christopher K mmel, Dennis Ritter, Kristian Hildebrand 我们提出了一种使用GANS合成手语视频的新方法。我们扩展了Stoll等人的前一部工作。通过使用柔软门控扭曲GaN的人类语义解析器从区域级空间布局引导的照片仪器仪器。合成目标姿势提高了独立和对比签名者的性能。因此,我们已经评估了我们的系统,其系统具有高度异构的MSAL数据集,具有超过200个签名者,导致SSIM为0.893。此外,我们向发电机介绍一个周期性的加权方法,该发电机重新激活训练并导致定量更好的结果。 |
| Sparse convolutional context-aware multiple instance learning for whole slide image classification Authors Marvin Lerousseau, Maria Vakalopoulou, Nikos Paragios, Eric Deutsch 整个幻灯片显微载玻片显示出关于潜在的组织指导诊断和许多疾病的选择选择的许多线索。然而,他们巨大的尺寸经常在千兆像素妨碍了传统的神经网络架构的使用。为了解决这个问题,多个实例学习MIL将袋子分类而不是整个幻灯片。大多数MIL战略认为,修补程序是独立的并相同分布的。我们的方法通过与基于稀疏输入卷积的MIL策略的鸿沟的空间信息集成了一种范式转变。配制的框架是通用的,灵活,可扩展的,是第一个引入修补程序级别所拍摄的决策之间的上下文依赖性的。它达到了泛癌亚型分类中的最新性能。这项工作的代码将可用。 |
| Do You Even Need Attention? A Stack of Feed-Forward Layers Does Surprisingly Well on ImageNet Authors Luke Melas Kyriazi 视觉变压器对图像分类和其他愿景任务的强大性能通常归因于他们的多头注意层的设计。但是,关注对这种强大性能负责的程度尚不清楚。在这篇短暂的报告中,我们询问的是注意层甚至必要的注意层,我们更换了视觉变压器中的注意层,施加在贴片尺寸上的前向前层。由此产生的架构只是通过交替的方式施加在补丁和特征尺寸上的一系列馈送前线。在想象中的实验中,这种架构表现出令人惊讶的是,vit Deit基础大小的模型获得74.9前1个精度,而分别为77.9和79.9。这些结果表明,除了关注之外的视觉变压器的各个方面,例如补丁嵌入,可能更负责它们的性能而不是先前的想法。我们希望这些结果提示社区花费更多时间试图理解为什么我们目前的模型与它们一样有效。 |
| Deep Weighted Consensus: Dense correspondence confidence maps for 3D shape registration Authors Dvir Ginzburg, Dan Raviv 我们提出了一种新的范例,用于基于可知的加权共识的点云之间的刚性对齐,这是对噪声的鲁棒以及旋转组的全谱。 |
| VideoLT: Large-scale Long-tailed Video Recognition Authors Xing Zhang, Zuxuan Wu, Zejia Weng, Huazhu Fu, Jingjing Chen, Yu Gang Jiang, Larry Davis 现实世界中的标签分布通常是长期尾尾和不平衡的,导致偏置模型对主导标签。虽然长尾识别已被广泛研究了图像分类任务,但为视频领域进行了有限的努力。在本文中,我们引入了Videol,一个大规模的长尾视频识别数据集,作为迈向真实世界视频识别的一步。我们的视频电阻包含256,218个未经监测的视频,注释为1,004级,具有长尾部分布。通过广泛的研究,我们证明,由于视频数据中的附加时间维度,用于长尾图像识别的技术方法的状态在视频域中不执行良好。这激励我们提出粉碎,这是一个简单而有效的长尾视频识别任务的方法。特别地,Framestack在帧级执行采样以便平衡类分布,并且使用从训练期间使用从网络的知识动态地确定采样比率。实验结果表明,弗拉米斯克可以在不牺牲整体准确性的情况下提高分类性能。 |
| Cascade Image Matting with Deformable Graph Refinement Authors Zijian Yu, Xuhui Li, Huijuan Huang, Wen Zheng, Li Chen 图像消光是指前景对象的不透明度的估计。它需要正确的轮廓和前景对象的细节,以获得消光结果。为了更好地完成人类的图像消光任务,我们提出了具有可变形图形改进的级联图像消光网络,其可以自动从单个人类图像中预测精确的alpha遮罩,而没有任何额外的输入。我们采用网络级联架构从低至高分辨率执行消光,这对应于粗略优化。我们还介绍了基于图形神经网络GNN的可变形图形细化DGR模块,以克服卷积神经网络CNN的局限性。 DGR模块可以有效地捕获长距离关系,并获得更多全球和本地信息,以帮助产生更精细的alpha遮罩。我们还通过动态预测邻居并将DGR模块应用于更高分辨率的功能来降低DGR模块的计算复杂性。实验结果表明,我们的CASDGR在合成数据集上实现了最先进性能的能力,并在真实人类图像上产生良好的结果。 |
| Estimating Presentation Competence using Multimodal Nonverbal Behavioral Cues Authors mer S mer, Cigdem Beyan, Fabian Ruth, Olaf Kramer, Ulrich Trautwein, Enkelejda Kasneci 公开演讲和呈现能力在我们的教育,专业和日常生活中的社会互动领域发挥着重要作用。由于我们在演讲中的意图可能与受众实际上理解的内容有所不同,因此适当传达我们的信息的能力需要一组复杂的技能。展示能力在早期学年培养,随着时间的推移不断发展。一种能够促进呈现能力的有效发展的一种方法是在基于视觉和音频特征和机器学习的演讲中自动分析人类行为。此外,该分析可用于建议改进和与呈现能力相关的技能的发展。在这项工作中,我们调查不同非语言行为提示,即面部,身体姿势和音频相关特征的贡献,估算呈现能力。在251名学生的视频上进行分析,而自动评估是根据手动额定值根据T Bingen仪器进行介绍能力尖端。我们的分类结果达到了最佳性能,早期融合在相同的数据集评估准确度为71.25,讲话,面部和身体姿势的后期融合中的交叉数据集评估准确度为78.11。同样,回归结果具有融合策略的最佳状态。 |
| A First Look: Towards Explainable TextVQA Models via Visual and Textual Explanations Authors Varun Nagaraj Rao, Xingjian Zhen, Karen Hovsepian, Mingwei Shen 可说明的深度学习模型在许多情况下是有利的。前面的工作主要通过HOC方法不包括原始系统设计的一部分提供单峰解释。说明机制还忽略图像中存在的有用文本信息。在本文中,我们提出了MTXNet,结束了最终培训的多模式架构,以产生多模级解释,其侧重于图像中的文本。我们策划一个新型数据集TextVQA X,包含地面真理视觉和多参考文本解释,可以在培训和评估期间利用。然后,我们定量表明,使用多式联运解释的培训补充了模型性能,并在苹果酒分数和IO中的2中超越了多峰基线。更重要的是,我们证明多式联字解释与人类解释一致,有助于证明模型决定,并提供有用的见解,以帮助诊断错误的预测。最后,我们描述了使用生成的多模级解释的真实世界商业应用程序。 |
| A Novel Falling-Ball Algorithm for Image Segmentation Authors Asra Aslam, Ekram Khan, Mohammad Samar Ansari, M.M. Sufyan Beg 图像分割是指从背景中分离物体,并且是数字图像处理的最具挑战性的方面之一。实际上,不可能设计具有100个精度的分割算法,因此在文献中提出了许多分段技术,每个细分技术具有一定限制。本文介绍了一种新的下落球算法,其是基于区域的分割算法,以及基于瀑布模型的流域变换的替代。所提出的算法通过假设从丘陵地毯落下的球将停止在集水区盆地中来检测集水盆。一旦识别出集水盆,使用多标准模糊逻辑获得每个像素与其中一个集水区盆地的关联。通过在隶属函数的帮助下将图像划分为不同的集水区盆地来构造边缘。最后闭合轮廓算法应用于查找封闭区域,并且使用强度信息分割封闭区域内的对象。所提出的算法的性能被客观地和主观评估。仿真结果表明,该算法在传统的Sobel边缘检测方法和流域分割算法上提供了卓越的性能。对于比较分析,各种比较方法用于证明在现有的分段方法上提出的方法的优越性。 |
| Vision based Pedestrian Potential Risk Analysis based on Automated Behavior Feature Extraction for Smart and Safe City Authors Byeongjoon Noh, Dongho Ka, David Lee, Hwasoo Yeo 尽管最近的车辆安全技术进展,但道路交通事故仍然对人类生活产生严重威胁,并成为过早死亡的主要原因。特别是,人行横道对行人提出了重大威胁,但我们缺乏密集的行为数据来调查他们面临的风险。因此,我们提出了一种综合分析模型,用于使用在此类交叉口的道路安全摄像机收集的视频素材来播放的录像潜力风险。该建议的系统自动检测车辆和行人,通过框架计算轨迹,并提取影响这些对象之间潜在危险场景的可能性的行为特征。最后,我们通过使用数据仓库中累积的大量提取功能来设计数据多维数据集模型,以对抽象级别的潜在风险场景进行多维分析,但这超出了本文的范围,并将详细介绍未来的研究。在我们的实验中,我们专注于通过相机地点提取来自多人行横道的各种行为特征,并通过相机地点可视化和解释它们之间的行为和关系,以展示它们的可能性或可能不会导致潜在风险。我们通过将其应用于韩国奥山城的多人行横道,验证了可行性和适用性。 |
| Local Relation Learning for Face Forgery Detection Authors Shen Chen, Taiping Yao, Yang Chen, Shouhong Ding, Jilin Li, Rongrong Ji 随着面部操纵技术的快速发展,由于安全问题,面部伪造检测在数字媒体取证中受到了相当大的关注。大多数现有方法将面部伪造检测为分类问题,并利用二元标签或操纵区域掩模作为监督。然而,在不考虑当地地区之间的相关性,这些全球监督不足以学习广义特征和容易过度装备。为了解决这个问题,我们提出了一种通过本地关系学习的面部伪造检测的新视角。具体地,我们提出了一种多尺度补丁相似性模块MPSM,其测量本地区域的特征之间的相似性,并形成稳健和广义的相似性模式。此外,我们提出了一个RGB频率注意力模块RFAM,以融合RGB和频域中的信息,以获得更全面的本地特征表示,这进一步提高了相似性模式的可靠性。广泛的实验表明,该方法始终如一地占据了广泛使用的基准的技术状态。此外,详细的可视化显示了我们方法的鲁棒性和可解释性。 |
| A novel method of predictive collision risk area estimation for proactive pedestrian accident prevention system in urban surveillance infrastructure Authors Byeongjoon Noh, Hwasoo Yeo 道路交通事故,在人行横道特别是车辆行人碰撞,全球范围内对人类生命构成了严重威胁,已成为过早死亡的主要原因。为了保护此类弱势道路用户免受碰撞,有必要提前识别可能的冲突并警告道路用户,而不是事实上。积极防止行人碰撞的突破是根据诸如中央电视台等视觉传感器来识别行人的潜在风险。在这项研究中,我们提出了一种在无罪交流中的预测碰撞风险区域估计系统。在预处理后,所提出的系统从视频素材从视频镜头应用了车辆和行人的轨迹,然后通过使用深LSTM网络预测其轨迹。随着使用的预测轨迹,这种系统可以推断出碰撞危险地区统计,水平的进一步严重程度划分为危险,警告,和相对安全的。为了验证所提出的系统的可行性和适用性,我们申请了它并评估了韩国奥山市两家无罪化斑点的潜在风险的严重程度。 |
| Unsupervised Visual Representation Learning by Tracking Patches in Video Authors Guangting Wang, Yizhou Zhou, Chong Luo, Wenxuan Xie, Wenjun Zeng, Zhiwei Xiong 灵感来自于人眼继续在早期和中年童年中发展跟踪能力,我们建议使用跟踪作为计算机视觉系统的代理任务,以学习视觉表示。在儿童播放的Catch游戏中建模,我们设计了一个捕获3D CNN模型的补丁CTP游戏,以了解有助于视频相关任务的视觉表示。在提出的预先训练框架中,我们从给定视频剪切图像修补程序,并根据预先设置的轨迹来缩放并移动。代理任务是估算仅在第一帧中的目标边界框给出的视频帧序列中的图像修补程序的位置和大小。我们发现使用多个图像补丁同时带来明显的好处。我们通过随机制作隐形斑块来进一步提高游戏的难度。关于主流基准的广泛实验证明了CTP对其他视频预制方法的卓越性能。此外,CTP预磨损功能对域间隙的敏感性低于受监督动作识别任务训练的域间隙。当两者都在动力学400上培训时,我们会惊喜地发现CTP预磨削的代表在数据集上的完全监督的对应上实现了更高的行动分类准确性。代码可在线获取 |
| (ASNA) An Attention-based Siamese-Difference Neural Network with Surrogate Ranking Loss function for Perceptual Image Quality Assessment Authors Seyed Mehdi Ayyoubzadeh, Ali Royat 最近,利用对抗图像恢复和增强的对抗训练框架的深度卷积神经网络DCNN显着改善了处理的图像清晰度。令人惊讶的是,尽管这些DCNNs产生了比视觉上的其他方法产生克隆的图像,但是当使用流行措施来评估它们时,它们可能会获得较低的质量得分。因此,有必要开发定量指标以反映其性能,这与图像的感知质量很好。着名的定量度量,例如峰值信号到噪声比PSNR,结构相似性指标测量SSIM和感知指数PI与图像的平均意见评分MOS不良好相关,特别是对于用过越野丢失功能训练的神经网络。 |
| Federated Face Recognition Authors Fan Bai, Jiaxiang Wu, Pengcheng Shen, Shaoxin Li, Shuigeng Zhou 近年来,计算机视觉和人工智能社区广泛研究了面部识别。面部认可的一个重要问题是数据隐私,它受到越来越多的公众问题。作为一种常见的隐私保存技术,建议联合学习来协同培训模型,而不在各方之间共享数据。但是,据我们所知,它尚未成功地应用于面部识别。本文提出了一个名为Fedface的框架,以创新联合学习的人脸识别。具体而言,FEDFACE依赖于两个主要的创新算法,部分联合势头PFM和联合验证FV。 PFM在本地应用估计的等效全局势头,以有效地逼近集中性动量。 FV通过在某些私有验证数据集上测试聚合模型反复搜索更好的联合聚合权重,这可以提高模型的泛化能力。消融研究和广泛的实验验证了Fedface方法的有效性,并表明它与性能中集中基线相当或甚至更好。 |
| Why Approximate Matrix Square Root Outperforms Accurate SVD in Global Covariance Pooling? Authors Yue Song, Nicu Sebe, Wei Wang 全球协方差汇总GCP旨在利用卷积特征的二阶统计数据。在提高卷积神经网络CNNS的分类性能方面已经证明了其有效性。奇异值分解SVD用于GCP以计算矩阵平方根。然而,使用牛顿山丘兹迭代CITE Li2018Towards计算的近似矩阵平方根优先于通过SVD CITE LI2017SECOND计算的准确性。我们从数据精度和梯度平滑度的角度明确分析了性能差距背后的原因。研究了用于计算平滑SVD梯度的各种补救措施。基于我们的观察和分析,提出了一种基于SVD的GCP元层,使竞争性表现能够抵御牛顿Schulz迭代。此外,我们提出了一种新的GCP元层,在前向通过中使用SVD,并在后向传播中填充近似值以计算梯度。所提出的元层已经集成到不同的CNN模型中,并在大规模和细粒度的数据集上实现了最新的现有性能。 |
| MAFER: a Multi-resolution Approach to Facial Expression Recognition Authors Fabio Valerio Massoli, Donato Cafarelli, Claudio Gennaro, Giuseppe Amato, Fabrizio Falchi 情绪在每个人的社会生活中发挥着核心作用,他们的研究代表了多学科主题,拥有各种各样的研究领域。特别是关于后者,由于其与人机交互应用的相关性,面部表情的分析代表了非常活跃的研究区。在这种情况下,面部表情识别FER是识别人类面临表情的任务。通常,面部图像由具有自然,诸如输出分辨率的不同特性的摄像机获取。它已经在文献中显示,在针对多分辨率场景测试时,应用于面部识别的深度学习模型在其性能下进行劣化。由于FER任务涉及分析可以用异构来源获取的面部图像,从而涉及具有不同质量的图像,因此可以预期在这种情况下扮演重要作用是合理的。从这样的假设中源,我们证明了多分辨率培训对识别面部表情的模型的好处。因此,我们提出了一项名为MAFER的两步学习程序,培训DCNN,使他们能够在各种分辨率方面产生强大的预测。 Mafer的相关特征是,它是任务不可知的,即,它可以互补地使用其他客观相关技术。为了评估拟议方法的有效性,我们在公开可用的数据集FER,RAF和OULU上进行了广泛的实验活动。对于多分辨率的上下文,我们观察到我们的方法,学习模型在当前的SOTA上提高,同时报告固定解决方案的可比结果。最后,我们分析了我们模型的性能,并观察了从它们产生的深度特征的更高辨别力。 |
| A Simple and Strong Baseline for Universal Targeted Attacks on Siamese Visual Tracking Authors Zhenbang Li, Yaya Shi, Jin Gao, Shaoru Wang, Bing Li, Pengpeng Liang, Weiming Hu 暹罗追踪器最近被证明易受对抗性攻击的影响。然而,现有的攻击方法独立地为每个视频进行扰动,这以不可忽略的计算成本。在本文中,我们展示了能够实现目标攻击的普遍扰动的存在,例如,强制跟踪器遵循具有指定偏移的地面真理轨迹,以成为视频不可知论并从网络中推断出来。具体地,我们通过向模板图像添加通用难以察觉的扰动并将虚假目标(即,小通用侵略性补丁添加到涉及所述预定轨迹的搜索图像中来攻击跟踪器,使得跟踪器输出所述位置和大小假目标而不是真实的目标。我们的方法允许除了仅仅添加操作之外,没有额外成本的新型视频,而不需要梯度优化或网络推断。若干数据集上的实验结果表明,我们的方法可以有效地以目标攻击方式愚弄暹罗跟踪器。我们表明,拟议的扰动不仅是普遍的视频,而且还概括了不同的跟踪器。因此,这种扰动是双重普遍的,两者都是关于数据和网络架构。我们将宣传我们的代码。 |
| Body Meshes as Points Authors Jianfeng Zhang, Dongdong Yu, Jun Hao Liew, Xuecheng Nie, Jiashi Feng 我们考虑在这项工作中挑战多人3D身体网格估算任务。现有方法大多是基于人的本地化的一个阶段,以及个人身体网格估计的另一个阶段,导致具有高计算成本和复杂场景的性能高的冗余管道,例如,封闭的人实例。在这项工作中,我们呈现一个单一阶段模型,身体网格为BMP,简化管道并提升效率和性能。特别地,BMP采用一种新方法,该方法表示多个人实例,作为空间深度空间中的点,其中每个点与一个主体网格相关联。唤起这样的表示,BMP可以通过同时定向人实例点并估计相应的身体网格来直接在单个阶段中预测多人的身体网格。为了更好地理解在同一场景中所有人员的深度排序,BMP设计了一个简单但有效的Immant实例序列深度损耗,以获得深度相干的身体网格估计。 BMP还介绍了一种新颖的Keypoint意识增强,以增强模型鲁棒性,以遮挡人员实例。基准Panoptic,MUPOTS 3D和3DPW的综合实验清楚地证明了BMP的技术效率的状态,用于多人体网格估计,以及出色的精度。可以找到代码 |
| PoseAug: A Differentiable Pose Augmentation Framework for 3D Human Pose Estimation Authors Kehong Gong, Jianfeng Zhang, Jiashi Feng 现有的3D人类姿势估计器对新数据集的泛化性能较差,主要是由于训练数据中的2D 3D姿势对的数量有限。为了解决这个问题,我们提出了一个新的自动增强框架,该框架学会增加可用培训朝向更大的多样性,从而提高训练2D的泛化到3D姿势估计。具体而言,Poseaug引入了一种新型姿势增强器,用于通过可微分操作来调整各种几何因素的各种几何因素,姿势,体尺寸,观点和姿势的位置。具有这种可分辨能力的能力,可以将增强器与3D姿势估计器联合优化,并将估计误差作为反馈,以以在线方式产生更多样化的姿势。此外,Poseaug引入了一种新的部分感知运动链空间,用于评估局部关节角度合理性,并相应地开发鉴别模块,以确保增强姿势的合理性。这些精心设计使POSEAUG能够产生比现有的离线增强方法更多样化但更合理的姿势,从而产生更好的姿势估算器的泛化。 Poseaug是通用的,易于应用于各种3D姿势估算。广泛的实验表明,POSEAG在内部场景和跨场景数据集中明确提高了改进。值得注意的是,它在Cross DataSet评估设置下实现了88.6d 3D PCK在MPI INF 3DHP上,提高了基于先前的基于数据增强的方法9.1。可以找到代码 |
| Development of a Fast and Robust Gaze Tracking System for Game Applications Authors Manh Duong Phung, Cong Hoang Quach, Quang Vinh Tran 在本研究中,开发了一种新型眼睛跟踪系统,用于提取人的凝视,可用于现代游戏机,为玩家带来新的和创新的互动体验。系统的组件的核心,是一种坚固的虹膜中心和眼角检测算法,它基于它的凝视是连续和自适应提取的。评估测试应用于九人以评估系统的准确性,结果在水平方向上为2.50度观点,垂直方向3.07度。 |
| Generalizable Representation Learning for Mixture Domain Face Anti-Spoofing Authors Zhihong Chen, Taiping Yao, Kekai Sheng, Shouhong Ding, Ying Tai, Jilin Li, Feiyue Huang, Xinyu Jin 基于域泛化的面部反欺骗方法DG由于其鲁棒性不断努力方案而引起了不断的关注。现有的DG方法假设DO主标签是已知的。然而,在现实世界应用程序中,TheCollected DataSet始终包含混合域,其中Thedomain标签未知。在这种情况下,大多数现有的美化ODS可能无法正常工作。此外,即使我们可以获得DomainLabel作为现有方法,我们认为这只是一个Seal OptimalPartition。为了克服限制,我们提出了在不使用主标签的情况下提出域名namic调整元学习D2AM,其迭代地将长异形域表示的混合域分开,并列进了Meta学习的全面性能够面对反欺骗。具体而言,基于实例归一化的域特征呈现域特征,并提出域表示学习模块DRLM以提取群集的判别域特征。此外,为了降低异常值对聚类性能的副作用,我们还利用了最大平均值折射MMD来对准样本FeatureSto的分布,这提高了Clus Teating的可靠性。广泛的实验表明,所提出的法规表达常规的基于DG的面部反欺骗甲基ODS,包括利用域标签的甲基臭虫。此外,通过Visualizatio来解释性 |
| Detection, Tracking, and Counting Meets Drones in Crowds: A Benchmark Authors Longyin Wen, Dawei Du, Pengfei Zhu, Qinghua Hu, Qilong Wang, Liefeng Bo, Siwei Lyu 为促进对象检测的发展,跟踪和计数算法在无人机捕获的视频中,我们构建了一个带有新的无人机捕获的大型数据集的基准,名为Dronecrowd,由112个视频剪辑中形成了33,600个HD帧的各种场景。值得注意的是,我们注释了480万头和几个视频级属性的20,800人轨迹。同时,我们设计空间时间邻居网络STNNet作为强大的基线,以解决对象检测,跟踪和在密集的人群中共同计数。 STNNET由特征提取模块形成,其次是密度图估计头,以及定位和关联子网。要利用相邻对象的上下文信息,我们设计了相邻的上下文丢失来指导关联子网培训,该培训在时间域中强制执行附近对象的一致相对位置。在我们的Dronecrowd DataSet上进行了广泛的实验表明Stnnet对艺术状态有利地执行。 |
| Weakly Supervised Action Selection Learning in Video Authors Junwei Ma, Satya Krishna Gorti, Maksims Volkovs, Guangwei Yu 本地化视频中的操作是计算机视觉中的核心任务。弱监督的时间本地化问题调查此任务是否可以仅用视频级标签进行充分解决,显着降低了所需的昂贵和错误的易受记录的量。一种常见的方法是训练帧级分类器,选择具有最高概率概率的帧以进行视频级预测。然后将帧级激活用于本地化。但是,缺失帧级注释使分类器在每个帧上赋予类别偏差。为了解决这个问题,我们提出了学习ASL方法来捕获一般行动概念的行动选择,这是我们称为Actionsness的财产。在ASL下,该模型培训具有新型类不可知任务,以预测分类器将选择哪些帧。凭经验,我们表明ASL优于两种流行的基准测试Thumos 14和ActivityNET 1.2的领先基线,分别具有10.3和5.7的相对改善。我们进一步分析了ASL的属性,并证明了行动的重要性。此工作的完整代码可在此处提供 |
| Towards Novel Target Discovery Through Open-Set Domain Adaptation Authors Taotao Jing, Hong Liu, Zhengming Ding 开放式域适配OSDA认为目标域包含来自外部源域中的新型类别的示例。不幸的是,现有的OSDA方法始终忽略对未操作类别信息的需求,并且只需进一步解释即可将其识别为未知集。这使我们能够通过探索潜在的结构并恢复可解释的语义属性来更具体地了解未知类别。在本文中,我们提出了一种新颖的框架,可以准确地识别目标域中的等类,并有效地恢复未经证明类别的语义属性。具体地,通过域不变特征学习开发了保留部分对准的结构以识别所看到的类别。 Visual Graphy的属性传播旨在通过视觉语义映射平稳地通过视觉语义映射来平稳地过境属性。此外,建立了两个新的十字主基准,以评估新颖和实际挑战中的提议框架。开放式识别和语义恢复的实验结果证明了所提出的方法在其他比较基线上的优越性。 |
| Inverting Generative Adversarial Renderer for Face Reconstruction Authors Jingtan Piao, Keqiang Sun, Kwanyee Lin, Hongshneg Li 给定单眼图像作为输入,3D面几何重建旨在恢复相应的3D面网。最近,基于优化和基于学习的面部重建方法利用了新兴的可分解渲染器,并显示了有希望的结果。然而,差异化渲染器主要基于图形规则,简化了现实世界的照明,反思等的现实机制,因此不能产生现实的图像。这为优化或培训过程带来了大量的域移位噪声。在这项工作中,我们介绍了一种新颖的生成对抗性渲染器GAR,并建议将其倒置版定制到一般拟合管道,以解决上述问题。具体地,精心设计的神经渲染器采用面部正常地图和表示其他因素的潜在代码,作为输入,呈现逼真的脸部图像。由于GAR学习模拟复杂的现实世界形象,而不是依赖简化的图形规则,它能够产生现实图像,其基本上抑制了培训和优化中的域移位噪声。配备阐述的GAR,我们进一步提出了一种新的方法来预测3D面参数,其中我们首先通过渲染器反转获得精细的初始参数,然后用基于梯度的优化器来改进它。已经进行了广泛的实验,以证明所提出的生成的对抗性渲染器和基于新的优化面部重建框架的有效性。我们的方法实现了多个面部重建数据集的最新性能。 |
| Split and Connect: A Universal Tracklet Booster for Multi-Object Tracking Authors Gaoang Wang, Yizhou Wang, Renshu Gu, Weijie Hu, Jenq Neng Hwang 多目标跟踪MOT是计算机视觉字段中的重要任务。随着近年来深度学习技术的快速发展,MOT取得了巨大的改善。然而,一些挑战仍然存在,例如遮挡的敏感性,在不同的照明条件下不稳定,不稳定的对象等,以解决大多数现有跟踪器中的这种共同挑战,提出了一种轨迹增压算法,可以构建在任何其他跟踪器上。动机是潜在的ID开关位置上的简单且直接的分割轨迹,然后如果来自同一对象,则将多个katchlet连接到一个。换句话说,轨迹助推器由两个部分,即分离器和连接器组成。首先,通过用自适应高斯核的标签平滑策略用于分割位置预测,采用具有堆叠时间扩张卷积块的架构。然后,利用基于多头自我注意的编码器,用于轨迹嵌入,该嵌入器进一步用于将Tracklet连接到更大的组中。我们对MOT17和MOT20基准数据集进行了足够的实验,这表明了有希望的结果。结合所提出的轨迹助推器,现有的跟踪器通常可以对IDF1得分进行大量改进,这表明了该方法的有效性。 |
| Person Retrieval in Surveillance Using Textual Query: A Review Authors Hiren Galiyawala, Mehul S Raval 生物识别技术,计算机愿景和自然语言处理研究的最新进展已经发现了使用文本查询的监控视频检索的机会。监视系统的主要目标是使用描述来定位一个人,例如,一位带有粉红色T恤和携带黑色钱包的粉红色T恤和白色裙子的短女性。她有棕色的头发。这样的描述包含了性别,高度,衣物类型,衣物颜色,毛发颜色和配件等属性。这些属性正式称为软生物识别性。它们帮助桥接人类描述和机器之间的语义差距,因为文本查询包含人员软生物识别属性。手动搜索巨大的监视镜头也是不可行的,以检索特定的人。因此,使用视觉和基于语言的算法进行自动检索的人正在变得流行。与其他国家的评论相比,纸张的贡献如下1.推荐最多的歧视软化生物识别学,用于特定具有挑战性的条件。 2.集结基准数据集和检索方法进行客观性能评估。 3.基于功能,分类器,软生物识别属性数,深度神经网络类型的完整快照,以及深度神经网络的类型和性能测量。 4.基于自然语言描述的基于手工特征的方法,人员检索的全面覆盖范围是基于自然语言描述结束的。 |
| Handwritten Mathematical Expression Recognition with Bidirectionally Trained Transformer Authors Wenqi Zhao, Liangcai Gao, Zuoyu Yan, Shuai Peng, Lin Du, Ziyin Zhang 编码器解码器模型最近在手写的数学表达式识别方面取得了很大进展。但是,对于准确地分配对图像特征的现有方法仍然是一个挑战。此外,那些编码器解码器模型通常在其解码器部分中采用基于RNN的模型,这使得它们在处理长乳胶序列中的低效。在本文中,采用基于变压器的解码器来替换基于RNN的解码器,这使得整个模型架构非常简洁。此外,引入了一种新的培训策略来充分利用双向语言建模中变压器的潜力。与几种不使用数据增强的方法相比,实验表明,我们的模型提高了2.23克罗欧2014上现有技术的现状现状。同样,在2016年克罗欧2016年和克罗欧2019上,我们将分别改善1.92和2.28的表现。 |
| Spatio-Temporal Matching for Siamese Visual Tracking Authors Jinpu Zhang, Yuehuan Wang 相似性匹配是暹罗跟踪器中的核心操作。大多数暹罗跟踪器通过源自图像匹配字段的交叉相关性进行相似性学习。但是,与2D图像匹配不同,对象跟踪中的匹配网络需要4 D信息高度,宽度,通道和时间。互相关忽略了来自频道和时间尺寸的信息,从而产生了模糊的匹配。本文提出了一种时空匹配过程,以彻底探讨空间高度,宽度和通道和时间在空间高度,宽度和通道中的4 D匹配的能力。在空间匹配中,我们引入了空间变型通道引导相关SVC曲线,用于重新校准每个空间位置的信道明智的特征响应,这可以指导目标意识匹配特征的生成。在时间匹配中,我们研究了目标和背景的时域上下文关系,并开发了像差压抑模块臂。通过限制帧间响应图中的突发变更,我们的臂可以清楚地抑制飞行,从而实现更强大和准确的对象跟踪。此外,提出了一种新颖的锚定跟踪框架以适应这些创新。在包括OTB100,VOT2018,VOT2020,GOT 10K的具有挑战性基准的实验证明了该方法的最新性能的状态。 |
| In the Danger Zone: U-Net Driven Quantile Regression can Predict High-risk SARS-CoV-2 Regions via Pollutant Particulate Matter and Satellite Imagery Authors Jacquelyn Shelton, Przemyslaw Polewski, Wei Yao 自Covid 19爆发以来,政策制定者一直依赖于非药理学干预来控制爆发。随着空气污染作为潜在的传输载体,需要在干预策略中将其包含。我们提出了一种U净驱动量级回归模型,以基于易于获得的卫星图像来预测PM 2.5空气污染。我们证明我们的方法可以在地面真理数据上重建PM 2.5浓度,并通过其空间分布预测合理的PM 2.5值,即使对于污染数据不可用的位置,也是如此。此类预测2.5特征可以大致意识到为减少Covid 19的传播而导致的公共政策策略。 |
| SIPSA-Net: Shift-Invariant Pan Sharpening with Moving Object Alignment for Satellite Imagery Authors Jaehyup Lee, Soomin Seo, Munchurl Kim PAN锐化是合并高分辨率HR Panchromatic PAN图像的过程及其相应的低分辨率LR多光谱MS图像,以创建HR MS和PAN锐化图像。然而,由于传感器的位置,特性和采集时间,PAN和MS图像对经常倾向于具有各种量的未对准。用这种未对准的PAN MS图像对训练的常规基于深度学习的方法患有不同的伪像,例如所得到的PAN锐化图像中的双边缘和模糊伪像。在本文中,我们提出了一种新颖的框架,称为Shift不变锅锐化与移动物体对齐Sipsa网,这是第一种考虑到PAN锐化的移动物体区域的这种大未对准的方法。 SISPA网具有特征对齐模块FAM,即使在两个不同的PAN和MS域之间也可以调整到另一个特征的一个要对齐的功能。为了更好地对准PAN锐化图像,新设计了换档不变频谱损耗,这忽略了原始MS输入中的固有未对准,从而具有与优化孔对准MS图像的频谱损耗相同的效果。广泛的实验结果表明,与现有技术相比,我们的Sipsa网可以在视觉质量和对准方面产生显着改善的泛锐图像。 |
| Exploring Explicit and Implicit Visual Relationships for Image Captioning Authors Zeliang Song, Xiaofei Zhou 图像标题是AI中最具挑战性的任务之一,旨在自动生成图像的文本句子。最近的图像标题方法遵循编码器解码器框架,将图像中的突出区域序列转换为自然语言描述。然而,这些模型通常缺乏对体内互动的全面理解,体现对象之间的各种视觉关系。在本文中,我们探讨了显式和隐式的视觉关系,以丰富图像标题的区域级表示。明确地,我们通过对象对构建语义图,并利用门控图卷积网络所设的GCN,以选择性地聚合本地邻居信息。隐含地,我们通过来自变压器区域BERT的基于区域的双向编码器表示在没有额外的关系注释的基于区域的双向编码器表示中绘制了检测到的对象之间的全局交互。为了评估我们所提出的方法的有效性和优势,我们对微软Coco基准进行了广泛的实验,与强基线相比实现了显着的改进。 |
| MODS -- A USV-oriented object detection and obstacle segmentation benchmark Authors Borja Bovcon, Jon Muhovi , Du ko Vranac, Dean Mozeti , Janez Per , Matej Kristan 小型无人驾驶场车辆USV是沿海水设备,具有广泛的应用等应用,如环境控制和监测。自主操作的关键能力是障碍物检测及时的反应和碰撞避免,最近在基于相机的视觉场景解释的背景下探讨了。由于策划数据集,在无人机地面车辆的相关领域取得了实际解释的实质性进展。然而,目前的海上数据集没有充分捕获现实世界USV场景的复杂性,评估协议不是标准化的,这使得不同方法的交叉纸比较困难并困扰着进度。为了解决这些问题,我们介绍了一种新的障碍检测基准模式,其考虑了两个主要的感知任务海事对象检测和更通用的海上障碍分割。我们提出了一个包含大约81K立体声图像的新多样化的海上评估数据集与船上的IMU同步,有超过60K的物体注释。我们提出了一种新的障碍分割性能评估协议,反映了对实际USV导航的方式的检测准确性。使用所提出的协议来评估十七次最近的最新状态的现有物体检测和障碍分割方法,从而创建基准以促进该领域的发展。 |
| Beyond Self-attention: External Attention using Two Linear Layers for Visual Tasks Authors Meng Hao Guo, Zheng Ning Liu, Tai Jiang Mu, Shi Min Hu 注意机制,尤其是自我关注,在视觉任务中的深度特征表示中起着越来越重要的作用。通过在所有位置计算使用对明智的亲缘性来计算加权特征和在单个样本内捕获长距离依赖性来自我注意通过计算加权特征在每个位置来更新每个位置的特征。然而,自我关注具有二次复杂性并忽略不同样品之间的潜在相关性。本文提出了一种新的注意机制,我们根据两个外部,小型,可读和共享的存储器调用外部注意力,这可以通过简单地使用两个级联的线性层和两个归一化层,方便地替换现有流行的自我关注来轻松实现建筑。外部注意力具有线性复杂性,隐含地考虑所有样本之间的相关性。对图像分类,语义分割,图像生成,点云分类和点云分割任务进行了广泛的实验,揭示了我们的方法为自我注意机制和其一些变体提供了可比或卓越的性能,计算和内存成本更低。 |
| Content4All Open Research Sign Language Translation Datasets Authors Necati Cihan Camgoz, Ben Saunders, Guillaume Rochette, Marco Giovanelli, Giacomo Inches, Robin Nachtrab Ribback, Richard Bowden 计算标志语言研究缺少大规模数据集,可以创建有用的Reallife应用程序。迄今为止,大多数研究一直限于话语小域的原型系统,例如,天气预报。要解决此问题并推送该字段,我们将释放六个包含190小时的新闻域名190小时的数据集。由此,由聋人专家和口译员注释20小时的镜头,并公开可用于研究目的。在本文中,我们共享数据集收集过程和工具,以实现手语录像和字幕的对齐,以及基准翻译结果为未来的研究。 |
| DeepSMOTE: Fusing Deep Learning and SMOTE for Imbalanced Data Authors Damien Dablain, Bartosz Krawczyk, Nitesh V. Chawla 尽管有超过二十多年的进步,但数据仍然被认为是当代机器学习模式的重大挑战。深度学习的现代进步夸大了不平衡数据问题的重要性。解决此问题的两种主要方法是基于丢失功能修改和实例重采样。实例采样通常基于生成的对抗网络GAN,其可能遭受模式崩溃。因此,需要一种针对深度学习模型量身定制的过采样方法,可以在保留其特性的同时对原始图像进行工作,并且能够产生高质量的人造图像,可以增强少数阶级和平衡训练集。我们提出了深度学习模型的新型过采样算法。它的设计很简单,但有效。它包括三个主要组件I,编码器解码器框架II基于过采样和III的专用损耗函数,其具有惩罚项增强。基于GaN的过采样的深度的一个重要优势在于,Deepsmote不需要鉴别者,并且它产生高质量的人造图像,这些图像既丰富,适合目视检查。 DeepSmote代码公开提供 |
| Iterative Human and Automated Identification of Wildlife Images Authors Zhongqi Miao, Ziwei Liu, Kaitlyn M. Gaynor, Meredith S. Palmer, Stella X. Yu, Wayne M. Getz 相机捕获越来越多地用于监控野生动物,但这种技术通常需要广泛的数据注释。最近,深度学习具有明显的自动野生动物认可。然而,当野生动物数据本质上动态并且涉及长尾部分布时,当前方法受到大量静态数据集的依赖性的阻碍。通过机器学习和循环中的人类的混合组合可以克服这两个缺点。我们建议的迭代人类和自动识别方法能够从尾尾分布的野生动物图像数据中学习。此外,它包括自我更新学习,便于捕获快速改变自然系统的社区动态。广泛的实验表明,我们的方法可以实现90种准确性,只有20个现有方法的20个人。我们对人类和机器的协同协作将深入的学习从一个相对效率的注释工具转变为展出的展示工具的协作,以大大缓解人类注释的负担,并实现高效和恒定的模型更新。 |
| Magnifying Subtle Facial Motions for Effective 4D Expression Recognition Authors Qingkai Zhen, Di Huang, Yunhong Wang, Hassen Drira, Boulbaba Ben Amor, Mohamed Daoudi 在本文中,提出了一种自动4D面部表情识别4DFER的有效管道。它结合了两个成长,但在计算机视觉中使用来自Riemannian几何的工具计算空间面部变形并使用时间过滤放大它们。首先分析3D面的流动以捕获基于最近开发的Riemannian方法的空间变形,其中相邻3D面的配准和比较是联合LED的。然后,将这些变形的所得的时间演变被送入倍率方法,以便随时扩增面部活动。后者是本文的主要贡献,允许揭示微妙的隐藏变形,增强了情绪分类性能。我们在放大后提取几何特征变形之后,我们在Bu 4DFE数据集中评估了我们对BU 4DFE数据集的方法,94.18在放大器提取的几何特征变形之后的分类准确度超过10的平均性能和改进。 |
| A Step Toward More Inclusive People Annotations for Fairness Authors Candice Schumann, Susanna Ricco, Utsav Prabhu, Vittorio Ferrari, Caroline Pantofaru 打开的图像数据集包含大约900万个图像,是一个广泛接受的计算机视觉研究数据集。对于大型数据集的常见做法,注释并不穷举,其中边界框和属性标签仅用于每个图像中的类的子集。在本文中,我们在名为MIAP的开放图像数据集的子集上展示了一组新的注释,称为MIAP为人员子集提供更多包含界限,包含所有人员在这些图像中可见的所有人员的属性。 MIAP子集的属性和标记方法旨在使研究能够进行模型公平性。此外,我们还分析了人类类及其子类的原始注释方法,讨论了结果模式,以便通知未来的注释工作。通过考虑原始和详尽的注释集,研究人员现在也可以研究培训注释中系统模式如何影响建模。 |
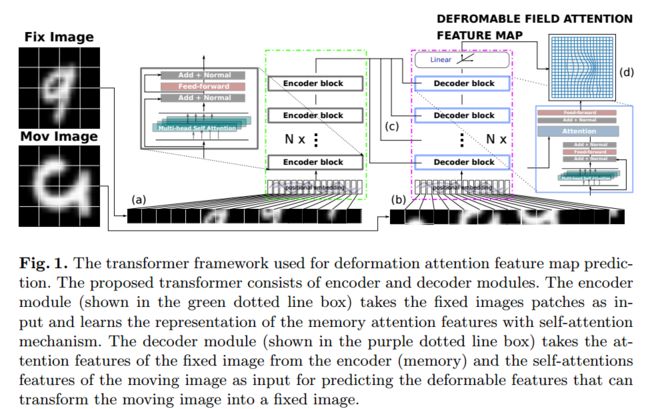
| Attention for Image Registration (AiR): an unsupervised Transformer approach Authors Zihao Wang, Herv Delingette 图像登记作为信号处理任务中的重要基础经常遇到稳定性和效率的问题。非学习登记方法依赖于修复和运动图像之间的相似度量的优化。然而,这些方法通常在时间和空间复杂性中昂贵。当图像的大小大或图像之间的变形严重时,问题可能更差。最近,深度学习,或精确地说,基于卷积神经网络CNN的图像配准方法已被广泛研究在研究界中,并且表现出克服基于非学习方法的弱点的有希望的有效性。为了探讨图像登记问题中的高级学习方法,以解决实际问题,我们在本文中展示了一种在可变形图像登记问题中引入关注机制的方法。所提出的方法是基于学习变形领域的变形领域,该变压器框架空气不依赖于CNN,而是可以在GPGPU器件上有效地训练。在更生动的解释中,我们将图像登记问题与语言翻译任务相同并引入变压器来解决问题。我们的方法了解一个无监督的生成的变形图,并在两个基准数据集中进行测试。空气的源代码将在Gitlab释放。 |
| Deep Learning based Multi-modal Computing with Feature Disentanglement for MRI Image Synthesis Authors Yuchen Fei, Bo Zhan, Mei Hong, Xi Wu, Jiliu Zhou, Yan Wang 目的,需要不同的磁共振成像MRI模式,所以需要从物理水平呈现不同的病理信息以进行诊断需求。然而,由于时间消耗和高成本,通常难以获得患者的全序列MRI图像。这项工作的目的是开发一种以高精度的目标MRI序列预测的算法,并提供更多信息临床诊断。方法提出了一种基于深度学习的多模态计算模型,用于MRI合成与特征解剖策略。为了充分利用不同方式提供的互补信息,多模态MRI序列用作输入。值得注意的是,所提出的方法将每个输入模型与具有特定信息的共享信息和模态特定空间分解为模态不变空间,从而单独提取特征以有效地处理输入数据。随后,它们都通过解码器中的自适应实例归一化Adain层融合。另外,为了在测试阶段解决目标模型的缺失的特定信息,采用局部自适应融合LAF模块来生成像伪目标的模态,具体信息类似于基础事实。结果评估合成性能,我们验证了我们在164个科目的Brats2015数据集上的方法。实验结果表明,我们的方法显着优于基准方法和其他艺术医学图像合成方法的基准方法和定性措施。与PIX2PIXGANS方法相比,PSNR从23.68增加到24.8。结论所提出的方法可以有效地预测靶MRI序列,可用于临床诊断和治疗。 |
| Two4Two: Evaluating Interpretable Machine Learning - A Synthetic Dataset For Controlled Experiments Authors Martin Schuessler, Philipp Wei , Leon Sixt 存在越来越多的方法,以生成图像分类的解释。然而,这些方法中的一些部分受到人类主题评估,部分原因是设计与自然图像数据集的控制实验有挑战性,因为它们将基本因素留出研究人员控制。通过我们的方法,研究人员可以仅用几个参数描述所需的数据集。基于这些,我们的图书馆产生两个3D抽象动物的合成图像数据。得到的数据适用于算法以及人类对象评估。我们的用户学习结果表明,我们的方法可以为分类器和微妙创造足够的偏差,足以仅针对视觉检查数据的每个第二参与者。我们的方法显着降低了进行人类对象评估的障碍,从而促进了更严格的调查进入可解释的机器学习。对于我们的图书馆和数据集, |
| Dynamic Defense Approach for Adversarial Robustness in Deep Neural Networks via Stochastic Ensemble Smoothed Model Authors Ruoxi Qin, Linyuan Wang, Xingyuan Chen, Xuehui Du, Bin Yan 深度神经网络已被证明在对抗攻击下患有关键漏洞。这种现象刺激了与网络空间安全采用的不同攻击和防御策略的创建。此类策略对攻击和防御机制的依赖性使得双方的相关算法与往复相互作用。在这些过程中,辩方策略特别被动,加强这些策略的倡议可以是摆脱这一军备竞赛的有效途径。通过网络空间中的动态防御方法的启发,本文基于随机平滑和模型集合的防御方法进行了随机合奏平滑。所提出的方法使用网络架构和平滑参数作为集合属性,并在每次推理预测请求之前动态地改变基于属性的集合模型。该方法处理白盒攻击下集合模型的极端转移性和脆弱性。具有不同攻击场景的ASR VS失真曲线的实验比较表明,即使是攻击能力最高的攻击者也不能容易地超越与集合平滑模型相关的攻击成功率,特别是在未确定的攻击下。 |
| Saliency-Guided Deep Learning Network for Automatic Tumor Bed Volume Delineation in Post-operative Breast Irradiation Authors Mahdieh Kazemimoghadam, Weicheng Chi, Asal Rahimi, Nathan Kim, Prasanna Alluri, Chika Nwachukwu, Weiguo Lu, Xuejun Gu 高效,可靠和可重复的目标体积描绘是有效规划乳房放射治疗的关键步骤。然而,由于肿瘤床体积TBV和正常乳腺组织之间的对比度在CT图像中相对较低,术后乳房靶描射是挑战性的。在这项研究中,我们建议模仿手动目标描绘中的标记指导程序。我们开发了一种基于显着的深度学习分割SDL SEG算法,用于术后乳房辐射中的精确TBV分段。 SDL SEG算法将标记位置提示的形式包含显着信息,进入U净模型。该设计强制模型编码位置相关的特征,其下划线具有高显着水平的区域并抑制低显着区域。通过识别CT图像上的标记来生成显着性图。然后使用与高斯滤波器耦合的距离变换将标记位置转换为概率图。随后,CT图像和相应的显着性图形成了SDL SEG网络的多通道输入。我们的房屋数据集由来自29个患者乳腺癌患者的145级易于CT图像组成,他们在伽马波省接受了5分部分乳腺辐射PBI方案。将所提出的方法的性能与基本U网进行比较。我们的模型分别实现了DSC,HD95和1.9 mm的平均标准偏差,分别在测试设置的测试集中,每个CT音量低于11秒的计算时间。 SDL SEG在保留低计算成本的同时显示相对于所有评估指标的基本U净的性能。研究结果表明,SDL SEG是提高PBI的线路治疗计划程序的效率和准确性的有希望的方法,例如基于GammaPod的PBI。 |
| Uncertainty-aware INVASE: Enhanced Breast Cancer Diagnosis Feature Selection Authors Jia Xing Zhong, Hongbo Zhang 在本文中,我们提出了一个不确定的意识的唤醒,以量化预测性的医疗问题的置信度。通过引入被动高斯的高斯分布,我们可以使用差异来测量不确定性程度。基于Vanilla envase,提出了两个附加模块,即预测器中的不确定量化模块,以及选择器中的奖励整形模块。我们对UCI WDBC数据集进行了广泛的实验。值得注意的是,我们的方法几乎消除了几乎所有关于20个查询的预测偏差,而不确定的不可逆结对应物需要近100个查询。具有详细教程的开源实现可用 |
| A 2.5D Vehicle Odometry Estimation for Vision Applications Authors Paul Moran, Leroy Francisco Periera, Anbuchezhiyan Selvaraju, Tejash Prakash, Pantelis Ermilios, John McDonald, Jonathan Horgan, Ciar n Eising 本文提出了一种方法来估计随着车辆通过世界的移动,其在车辆上安装在车辆上的传感器的姿势,这是自主驱动系统的重要课题。基于一组常用的车辆测量传感器,在汽车通信总线上提供输出。可以或FlexRay,我们描述了一组步骤,将基于轮式传感器的平面内径术与基于线性悬架传感器的悬架模型相结合。目的是确定相机姿势的更准确的估计。我们概述了它在可视化和计算机视觉中的应用程序的用法。 |
| SS-CADA: A Semi-Supervised Cross-Anatomy Domain Adaptation for Coronary Artery Segmentation Authors Jingyang Zhang, Ran Gu, Guotai Wang, Hongzhi Xie, Lixu Gu 卷积神经网络的冠状动脉的分割很有希望需要大量的劳动密集型手动注释。从视网膜血管的广泛可用的公众标记的眼底图像转移知识有可能降低由于它们的常见管状结构引起的X射线血管造影XA中的冠状动脉细分的注释要求。然而,由于甚至不同的成像协议下的不同解剖区域中的本质上不同的血管特性,它受到横向解剖结构域的挑战。为了解决这个问题,我们提出了一个半监督横向解剖结构域适应SS CADA,只需要XA中的冠状动脉有限的注释。随着少数标记的XAS和公开可用的FIS监督,我们提出了一种血管特定批量标准化VSBN,以考虑其不同的交叉解剖血管特性,单独归一化特征图。此外,为了进一步促进注释效率,我们采用了一个自组合的均衡教师SEMT来利用富有预测的一致性约束来利用丰富的未标记的XAS。广泛的实验表明,我们的SS CADA能够解决挑战性的交叉解剖结构域移位,仅为少数标记的XAS实现冠状动脉的准确细分。 |
| Quantification of pulmonary involvement in COVID-19 pneumonia by means of a cascade oftwo U-nets: training and assessment on multipledatasets using different annotation criteria Authors Francesca Lizzi, Abramo Agosti, Francesca Brero, Raffaella Fiamma Cabini, Maria Evelina Fantacci, Silvia Figini, Alessandro Lascialfari, Francesco Laruina, Piernicola Oliva, Stefano Piffer, Ian Postuma, Lisa Rinaldi, Cinzia Talamonti, Alessandra Retico 严重程度的自动分配到受Covid 19肺炎影响的患者的CT扫描可以减少放射学部门的工作量。本研究旨在利用人工智能AI,用于Covid 19肺病变的鉴定,分割和定量。我们调查了使用多个数据集的影响,根据不同的标准使用多种数据集,异构地填充和注释。我们开发了一个自动分析管道,leung quant系统,基于两个U网的级联。第一个U Net 1致力于鉴定肺实质,第二个U净2作用于封闭细分肺部的边界盒,以鉴定受Covid 19病变影响的区域。使用不同的公共数据集用于培训U网并评估它们的分割性能,这些表现已经在骰子指数方面被量化。还评估了预测CT严重程度CT SS的准确性。骰子和准确性都显示了对可用数据样本的注释质量的依赖性。在独立和公开的基准数据集上,施用系统预测的面罩和参考文件之间测量的骰子值分别为0.95μm01和0.66pm0.13,分别用于肺和covid 19病变的分割。实现了在该基准数据集上识别CT SS时90的准确性。我们分析了利用数据样本在培训AI基于AI的量化系统中进行了不同的注释标准的影响。就骰子指数而言,U净分割质量强烈取决于病变注释的质量。然而,可以在独立的验证集上准确预测CT SS,证明了LUNGQUANT的令人满意的泛化能力。 |
| Learning Neighborhood Representation from Multi-Modal Multi-Graph: Image, Text, Mobility Graph and Beyond Authors Tianyuan Huang, Zhecheng Wang, Hao Sheng, Andrew Y. Ng, Ram Rajagopal 最近的城市化恰逢地理标记数据的丰富,如街景和兴趣点POI。浓郁的数据模型嵌入的区域使研究人员和城市管理人员能够了解建筑环境,社会经济和能力的动态。虽然已经进行了一些努力来同时使用多模态输入,但是通过在相同的嵌入空间中不仅在利用例如街道视图,本地企业模式的数据,而且还可以通过在相同的嵌入空间中的邻近度衡量所在的数据来提高现有方法。描绘地区之间的关系,例如,旅行,道路网络。为此,我们提出了一种基于与邻域区域的关系的多图的节点或边缘特征,提出了一种新的方法来将多模态地地理标记输入集成为多图的节点或边缘特征。瓷砖,人口普查块,邮政编码区域等。然后,我们基于来自多图的对比采样方案来学习邻域表示。具体而言,我们使用Street View Images和PoI功能来表征邻域节点并使用人类移动性来表征邻域定向边的关系。我们展示了所提出的方法具有定量下游任务的效力,以及对嵌入空间的定性分析,嵌入空间我们培训的嵌入越野优于使用单峰数据作为区域输入。 |
| Relative stability toward diffeomorphisms in deep nets indicates performance Authors Leonardo Petrini, Alessandro Favero, Mario Geiger, Matthieu Wyart 了解为什么深网络可以在大尺寸中对数据进行分类仍然是一个挑战。已经提出了它们通过变得稳定对扩散术来说,然而现有的经验测量支持,这通常不是这种情况。我们通过定义对散晶术的最大熵分布来重新审视这个问题,这允许研究给定规范的典型的扩散形式。我们确认对微小族的稳定性与四个基准数据集的性能没有强烈关联。相比之下,我们发现,对于通用变换的稳定性,R F与测试误差epsilon t显着地相关联。它在初始化时统一,但在艺术架构的培训期间,几十年来减少了数十年。对于CIFAR10和15名已知的架构,我们发现epsilon t约0.2 sqrt r f,表明获得小的r f很重要,无法实现良好的性能。我们研究R F如何取决于培训集的大小,并将其与一个简单的不变学习模型进行比较。 |
| Learning Skeletal Articulations with Neural Blend Shapes Authors Peizhuo Li, Kfir Aberman, Rana Hanocka, Libin Liu, Olga Sorkine Hornung, Baoquan Chen 使用运动捕获Mocap数据为新设计的字符进行动画,是计算机动画中的一个很长的问题。关键考虑是应该对应于可用的Mocap数据的骨架结构,以及关节区域中的形状变形,它们通常需要定制的姿态特定细化。在这项工作中,我们开发了一种用预定定义骨架结构的包围来铰接3D字符的神经技术,这产生了高质量的姿势依赖变形。我们的框架学会用于钻机和皮肤字符,具有相同的铰接结构,例如,Bipeds或Quadrupss,并将所需的骨架层次结构构建到网络架构中。此外,我们提出了一组矫正姿势依赖性形状的神经混合,这改善了联合区域中的变形质量,以解决由标准索具和剥皮产生的臭名昭着的伪影。我们的系统估计具有任意连接的输入网格的神经混合形状,以及在输入关节旋转上调节的加权系数。与近期监督网络的深度学习技术与地面真理索具和剥皮参数不同,我们的方法不认为训练数据具有特定的底层变形模型。相反,在训练期间,网络观察变形的形状,并学会使用间接监督推断相应的钻机,皮肤和混合形状。在推论期间,我们展示了我们的网络推广了具有任意网格连接的不均义字符,包括3D艺术家构建的未经过的字符。符合标准骨架动画模型,可以直接插入并播放标准动画软件,以及游戏引擎。 |
| Explainable Artificial Intelligence for Human Decision-Support System in Medical Domain Authors Samanta Knapi , Avleen Malhi, Rohit Salujaa, Kary Fr mling 在本文中,我们介绍了医学图像分析方案中决策支持的可解释的人工智能方法的潜力。应用于同一医学图像数据的三种可说明的方法,我们的目标是改善卷积神经网络CNN提供的决策的可理解性。在从视频胶囊内窥镜vce获得的体内胃膜图像中提供了视觉解释,其目的是增加卫生专业人员信任黑匣子预测。我们实施了两个后HOC可解释的机器学习方法石灰和Shap和替代解释方法CIU,以上下文值和实用程序CIU为中心。使用人类评估评估所产生的解释。我们根据石灰,Shap和CIU提供的解释进行了三次用户研究。来自不同非医学背景的用户在基于Web的调查环境中进行了一系列测试,并表示他们对给定解释的经验和理解。定量分析了具有三种不同形式的解释的三个用户组N 20,20,20。我们已经发现,如假设,CIU可说明的方法在对人类决策的增加以及更透明的情况下,比石灰和Shap方法更好地表现优于石灰和Shap方法,以及更透明,因此对用户理解。另外,CIU通过更快地产生解释来表现出石灰和形状。我们的研究结果表明,各种解释支持设置之间的人为决策有很大的差异。符合这一点,我们提出了三种潜在的可解释方法,可以在未来的实施方面的改进方面在不同的医疗数据集上推广,并可为医学专家提供伟大的决策支持。 |
| R2U3D: Recurrent Residual 3D U-Net for Lung Segmentation Authors Dhaval D. Kadia, Md Zahangir Alom, Ranga Burada, Tam V. Nguyen, Vijayan K. Asari 3D肺分割是必要的,因为它处理肺的容积信息,从而消除扫描的不必要区域,并在3D体积中区段肺的实际面积。最近,深度学习模型,如U Net优于生物医学图像分割的其他网络架构。在本文中,我们提出了一种新颖的模型,即复发性残余3D U Net R2U3D,用于3D肺分割任务。特别地,所提出的模型将3D卷积集成到基于U网的经常性残余神经网络。它有助于在3D中学习空间依赖性,并增加3D体积信息的传播。所提出的R2U3D网络培训在公开的DataSet Luna16上培训,它可以在Luna16测试集和船舶12数据集中实现最先进的性能。此外,我们表明,培训具有较少数量的CT扫描的R2U3D模型,即100扫描,无需应用数据增强,以09920的软骰子相似度系数软DSC实现了出色的结果。 |
| Chinese Abs From Machine Translation |
Papers from arxiv.org
更多精彩请移步主页
pic from pexels.com