CVPR 2021 Less is More: CLIP BERT for Video-and-Language Learning via Sparse Sampling
动机
- 视频和语言学习(如视频问答)的规范方法要求神经模型从离线提取的密集视频特征和语言模型的文本特征中学习。
在这个互动的动态视觉世界中,人类通过语言、符号和图形相互交流。共同理解视觉和本线索是智能主体解读物理世界中多模态信号的必备能力。为了测试这种能力,已经设计了一系列基于真实视频的任务,包括文本到视频的重审、视频字幕、视频问题回答和视频时刻重复。处理这些跨模态任务的实际范例是首先从预训练的视觉模型中提取密集的视频特征,从预训练的语言模型中提取文本特征,然后应用多模态融合将这些固定的表征在共享的嵌入空间中拼凑在一起。 - 这些特征提取器是独立训练的,并且通常是在不同于目标领域的任务上训练的,使得这些固定的特征对于下游任务来说是次优的。此外,由于密集视频特征的计算量过大,直接将特征提取器插入到现有的方法中进行简单的微调往往是困难的(或不可行的)。
基于此范式的现有方法取得了很大的成功,但存在两个主要缺陷:
(1)任务/领域中的Disconnection:离线特征提取器通常是针对不同于目标任务的任务和任务进行训练的。例如,从人类活动视频中学习的动作识别的特征不协调地应用于在通用域GIF视频上的下游视频问题回答。
(2)多模态特征的Disconnection:从不同模态学到的特征是相互独立的。例如,动作识别模型是典型地从纯视频数据中训练出来的,没有文本输入,但却被应用于视频和语言任务。端到端特定于任务的微调提供了一种减轻这些固有Disconnection的方法。然而,在现有的大多数工作中,从视频帧的完整序列中提取特征对内存和计算的要求过高,使得直接将特征提取器插入到视频+语言学习的框架中进行有效的端到端精细调整变得困难甚至不可行。
为了解决这一难题,本论文提出了通用框架CLIPBERT,通过使用稀疏采样,在每个训练步骤中只使用单个或几个稀疏采样的一个视频的简短的剪切片段,为视频和语言任务提供负担得起的端到端学习。
方法
简介
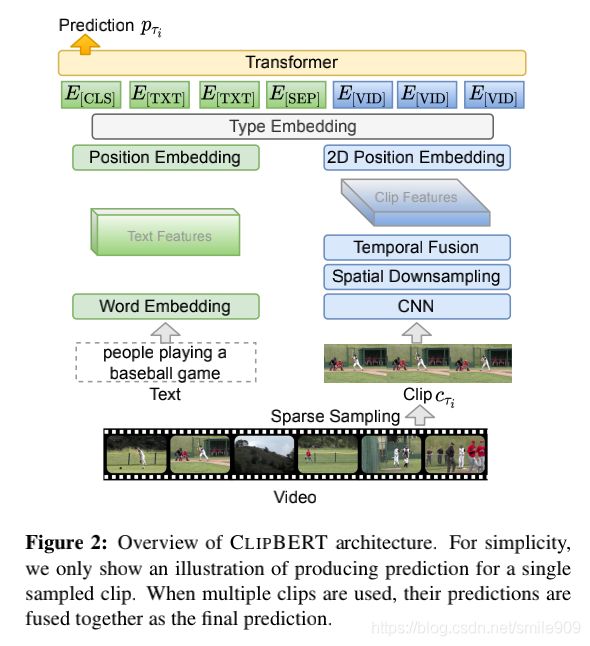
本论文提出了CLIPBERT,一个用于端到端视频和语言学习的通用且高效的框架。Clip-Bert从两个方面区别于以前的工作。首先,CLIPBERT在每一个训练步骤中只从完整的视频中稀疏地采样一个或几个短的剪切片段,这与现有的大多数方法所采用的密集的视频特征提取方法不同。假设是稀疏剪切片段的视觉特征已经捕获了视频中关键的视觉和语义信息,因为连续剪切片段通常包含来自连续场景的相似语义。因此,少量的剪切片段就足以进行训练,而不是使用完整的视频。然后对多个密集采样剪切片段的预测进行融合,得到最终的视频级预测,从而减少了计算量。这种先稀疏训练后密集推理的策略大大减少了内存需求和计算量,降低了从原始视频帧像素和语言标记进行端到端学习的经济性。
第二个区别在于模型权重的初始化(即通过预训练的传递)。在最近的文献中,图像-文本预训练(例如,使用COCO Captions或Visual Genome Captions)已经应用于图像-文本任务,并且视频-文本预训练(例如,使用HowTo100M)应用于视频相关任务。目前还没有研究对图文预训练对视频文本任务的影响进行交叉检验。从直观上看,从大规模图像数据集中通过预训练学习到的视觉特征也应该有助于在静态视频帧中依赖视觉线索的视频理解任务。为了研究这一点,本论文使用2D AR-chitecture(例如ResNet-50)代替3D特征作为视频编码的视觉主干,允许本论文利用图像-文本预训练来理解视频-文本,同时具有低内存开销和运行时效率的优点。通过实验,本论文观察到图文预训练中所学到的知识确实有助于视频文本任务;这个简单的策略帮助本论文在文本到视频检索和视频问题回答任务上实现更好的性能或与以前的技术水平相当的性能。
视频和语言理解。流行的视频和语言任务包括文本到视频检索,视频字幕,视频问答和Moment Retrieval。标准方法利用离线从动作识别模型、图像识别中提取视频和文本特征模型和语言模型。对齐基于transformer的语言预训练和图像-文本的预训练,视频-文本预训练在视频和语言任务方面显示了有希望的结果。除了使用固定特征和同域数据(即只针对视频文本任务进行视频文本预训练)外,本论文的工作重点是端到端训练和将图像文本预训练应用于视频文本任务。
动作识别。当前视频动作识别算法通常采用深度2D或3D卷积网络设计。这些系统的计算量和内存都很大,使得直接处理相当长的视频变得极其困难。之前的工作,为了缓解这一困难,不是对整个长视频进行训练,而是经常使用从视频中随机抽样的短剪切片段来训练模型。在推断时,来自多个单一采样剪切片段的预测被融合在一起作为最终的视频级预测。关于这些工作,本论文采用了类似的策略来执行稀疏训练和密集推理,以减少视频处理的开销,但与纯视频建模相比,本论文将重点放在视频和语言任务上,使用视频和语言的跨模态建模。在推断时,来自多个单一采样剪切片段的预测被融合在一起作为最终的视频级预测。在这些工作中,本论文采用了类似的策略来执行稀疏训练和密集推理,以减少视频处理的开销,但与纯视频建模相比,本论文将重点放在视频和语言任务上,使用视频和语言的跨模态建模。
稀疏采样CLIPBERT
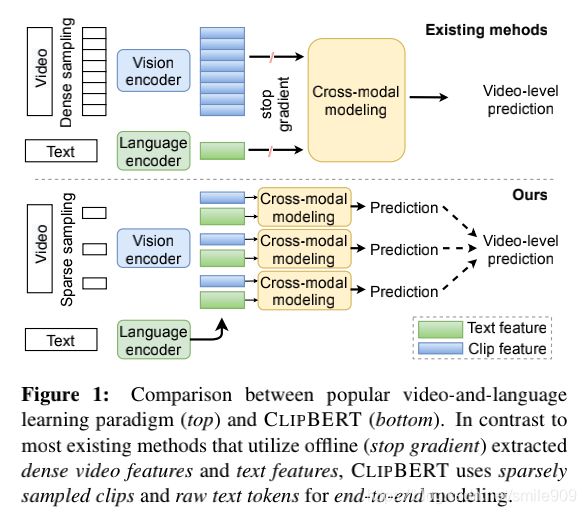
本论文提出了CLIPBERT,一个在视频和语言数据上实现端到端学习的通用框架,代替从离线提取的单模态特征,通过直接从视频帧像素和原始文本token学习联合表示。通过直接从视频帧像素和原始文本token学习联合表示。它采用稀疏采样策略,在每个训练步骤中只使用单个或几个采样剪切片段,而不是完整的视频。每个被采样的剪切片段用视觉主干模型独立地编码,视觉特征随后被反馈到跨模态模块,该跨模态模块提取剪切片段与其相关联的文本表示之间的关系。来自所有采样剪切片段的独立预测被融合在一起(例如,通过平均池化),以在视频级别上达成共识。在此基础上计算任务特定的损失以学习模型参数。在推理过程中,CLIPBERT从视频中密集地采样一系列剪切片段,并将它们的预测融合为最终预测。
现有的大多数工作对离线提取的密集视频特征和文本特征进行建模。在形式上,本论文将视频-文本对表示为V(对于视频)和S(对于视频文本序列)。视频V进一步表示为具有相等持续时间的N个剪切片段的列表[c1,c2,…,cN]。该标准范例可以表述为:
p=H([FvSG(c1), FvSG(c2), …, FvSG(cN)],FlSG(S)),
其中FvSG和FlSG分别是视觉和语言编码器。上标SG表示停止梯度,意味着梯度不能通过两个编码器反向传播。H是一个跨模态编码器和预测器,它对编码的视频/语言输入之间的关系建模并进行预测。p为视频级预测。然后应用任务特定的损失函数Ltask来计算基于该预测及其相应的真实值q的损失值ltask。ltask=Ltask(p, q)。
用于训练的稀疏抽样。CLIPBERT没有使用包含N个剪切片段的全长视频,而是从V稀疏地(并随机地)抽样Ntrain剪切视频{cτi}i=1Ntrain用作训练。Ntrain通常比N小得多。本论文建模同时一个抽样的剪切片段cτi和文本输入S,以产生一个预测pτi:
pτi=H(Fv(cτi), Fl(S)),
其中Fv和Fl是视觉/语言编码器。与使用离线视觉/语言编码器的方程式不同,CLIPBERT是端到端可训练的,允许利用特定任务的损失进一步调整编码器,学习更好的表征。来自所有采样剪切片段的独立预测被融合以达成共识。损失值ltask根据以下视频级共识计算:
ltask= Ltask(G(pτ1, pτ2 , …, pτN), q),N=Ntrain
G是预测/分数融合函数(例如,平均池化)。当Ntrain大于1时,这种形式可以看作是多实例学习(MIL)的一种形式。在推理时,本论文统一地采样与训练剪切片段相同持续时间的Ntest剪切片段,然后融合来自所有Ntest剪切片段的预测,形成本论文的最终预测。
CLIPBERT的稀疏训练策略可以解释为一种类型的数据增强:在不同的训练步骤使用来自同一视频的不同剪切片段子集,提高了模型的泛化能力。在这个意义上,它类似于图像分类任务中常用的随机裁剪。它还借鉴了动作识别方法,其中视频分类器是在采样剪切片段上是可训练的。
模型体系结构。对于视觉编码器Fv,对于视觉编码器F,由于二维模型通常消耗更少的内存,运行速度更快,并且2D CNN已被证明能很好地处理动作识别等视频任务,因此本论文使用一个2D CNN体系结构ResNet-50而不是3D体系结构(如C3D或I3D)。具体地,本论文取ResNet-50的前5个Conv块,增加一个额外的卷积层以减小其输出特征深度,并在Pixel-BERT之后增加一个用于空间下采样的2×2最大池化层。对于每个抽样的剪切片段,对T个帧进行均匀采样,得到T个特征映射。时间融合层M(例如,平均池化)用于将帧级特征映射融合成一个单一的片段级特征映射。然后基于它们的2D位置给各个特征向量添加一个基于行和一个基于列的位置嵌入。这些嵌入是与BERT中相同的可训练的位置嵌入。另一方面,这两个位置嵌入表示特征的2D空间位置,可以将其视为2D位置嵌入。得到的特征映射被flatten为一个嵌入序列,以表示剪切片段。
本论文使用一个可训练的单词嵌入层作为本论文的语言编码器Fl来编码语言token,并加入可训练的位置嵌入来编码token的位置信息。接下来,本论文将不同的类型嵌入添加到剪切片段和文本嵌入中,以指示它们的源类型。然后将这两个序列级联为12层transformer的输入,以进行跨模态融合。本方案在不同的类型嵌入之后增加了特殊token[CLS]和[SEP]。给定一个下游任务,本论文以最后一层[CLS]表示作为输入并添加一个任务特定的预测头(例如,使用带有softmax的一个两层的MLP以生成文本到视频检索的评分)。
权重初始化和预训练。本论文用grid-feat中的权重初始化ResNet-50层。它在Visual Genome上训练用于目标检测和属性分类,并为图像VQA任务产生有效的网格特征。输入帧的大小被调整为L的一个最大长边,同时保持AS-PECT比率,短边也被零填充为L。本论文从BERT-base模型中初始化transformer和词嵌入层,并在BookCorpus和英文维基百科上进行预训练。这些权重是针对其单个单模态任务单独训练的,因此简单地将它们组合在一个用于下游任务训练的单一框架中可能导致次优性能。虽然用大规模的视频文本数据集(如HowTo100M)对整个模型进行端到端的预训练是很有吸引力的,但是本论文受到了巨大的计算代价的限制。幸运的是,由于本论文使用了2D CNN作为本论文的视觉编码器,CLIPBERT能够直接将图像文本对作为训练的输入。因此,本论文利用大规模的图像-文本数据集(COCO Captions和Visual Genome Captions)来执行跨模态的预训练。具体地说,本论文使用掩码语言建模和图文匹配的目标是优化模型。默认情况下,本论文根据这个预训练好的权重来调整本论文的模型,用于下游的视频文本任务。
实现细节。本论文对COCO Captions和Visual Genome Captions进行图文预训练。这两个数据集包含了151K图像上的560万个训练图像-文本对。这是用于UNITER的领域内预训练的相同的数据。本论文使用输入图像大小L=768,从视觉编码器得到的特征映射包含144个像素。为了提高泛化率和降低计算量,在预训练过程中,本论文遵循Pixel-BERT的方法,采用像素随机抽样的方法,从编码后的特征映射中抽取100个像素作为输入,将其输入到transformer层中。注意,本论文只应用像素随机采样进行预训练,对于下游任务始终使用全特征图,以避免训练和推断中的不对齐。本论文使用WordPiece embedding并保留出自caption的最多20个token。然后本论文随机mask15%的token进行掩码语言建模。对于每个图像-caption对,在概率为0.5的情况下,本论文用从另一幅图像中随机采样的caption替换真实的caption,形成一个用于图文匹配的负对。本论文使用AadmW优化端到端模型训练,初始学习率为5e-5,在前10%的训练步骤中使用学习率预热,然后线性衰减到0。本论文的模型在PyTorch和Transform-ERS中实现。它在8个NVIDIA V100 GPU上以混合精度训练了40个epoch,批处理大小为每GPU 32个。整个训练过程需要4天时间才能完成。
对于下游精细调整,本论文使用相同的训练和优化器配置,只是默认输入图像大小设置为448(因为视频的分辨率通常低于图像)。由于下游数据集的规模和领域各不相同,本论文使用任务特定的学习率和基于验证性能的训练周期。
贡献
- 本论文提出了一个新的视频+语言任务端到端学习框架CLIPBERT。实验表明,CLIPBERT方法在视频文本任务中的平均视频长度从几秒到三分钟不等,均能获得优于现存方法的性能。
- 本论文的工作表明“少即是多”:提出的端到端训练策略使用单个或几个(较少)稀疏采样的剪切片段,通常比使用密集提取的视频特征的传统方法更精确。
- 本论文证明图像-文本预训练有利于视频-文本任务。本论文还提供了全面的消融研究,以揭示导致CLIPBERT成功的关键因素,希望对今后的工作有所启发。
实验
本论文将评估CLIPBERT在六个不同数据集中的两个流行的视频和语言任务:文本到视频检索和视频问题回答。本论文还提供广泛的消融研究来分析促成CLIPBERT成功的关键因素。
文本到视频检索。(i)MSRVTT包含10K个YouTube视频和200K个描述。本论文使用7K Train+Val视频进行训练,并在1K测试集上测试结果。本论文还通过从未使用的测试视频中采样1K个视频 Captions对来创建一个本地的val集,用于本论文的消融研究。(ii)DiDeMo提供10K Flickr视频,并附有40K句子。㈢ActivityNet Captions载有20K个YouTube视频,并附有100K个句子。训练集包含10K视频,本论文使用带有4.9K视频的val1集测试结果。对于MSRVTT,本论文评估了标准的句子到视频的检索。对于DiDeMo和ActivityNet caption,本论文评估段落到视频的检索,其中视频的所有句子描述都被concatenated形成一个段落以供检索。本论文使用平均召回在K(R@K)和中位秩(MdR)来衡量绩效。
视频问答。(i)TGIF-QA包含72K GIF视频上的165K QA对。本论文用3个TGIF-QA任务:多项选择QA的重复动作和状态转换,以及开放式QA的帧QA。本论文将计数任务留作以后的工作,因为它需要直接建模全长视频。(ii)MSRVTT-QA是根据MSRVTT中的视频和 Captions创建的,包含10K个视频和243K个开放式问题。(iii)MSRVTT多项选择测试是一种多项选择任务,以视频作为问题,以caption作为答案。每个视频包含5个 Captions,只有一个正匹配。对于所有的QA任务,本论文使用标准的Train/Val/Test splits并得出准确性来衡量性能。
本论文对CLIPBERT设计的各个方面进行了全面的烧蚀研究。如果没有另外说明,本论文从全长视频中随机采样单个帧(Ntrain=1和T=1)进行训练,并使用中间帧(Ntest=1)进行推断,输入图像大小为L=448。所有消融结果均在MSRVTT检索局部val和MSRVTT-QA val集上。
输入图像大小。本论文比较了不同输入图像大小L∈224、448、768、1000的模型,与L=224的模型相比,较大的输入分辨率提高了检索任务的性能,同时保持了QA任务的类似性能。最佳性能在L=448附近实现。进一步提高分辨率并不能显著提高性能。这可能是因为VQA图像通常比MSRVTT视频具有更高的原始分辨率(本论文只能获得240像素的最大高度的视频)。本论文期望更高分辨率的视频可以进一步提高模型的性能。
密集采样的帧。对于视频理解和视频+语言的理解,一个常见的实践是对原始视频中的密集采样帧进行建模(例如每秒25帧的采样帧)。为了了解使用密集采样帧的影响,本论文进行了一组对照实验。具体来说,本论文从视频中随机采样一个固定长度的1秒剪切片段,然后在这个剪切片段内均匀地采样T=1,2,4,8,16帧进行训练。为了推论,本论文使用视频的中间剪切片段。当使用多帧时(即T>1),本论文使用平均池化进行时间融合。
本论文还在平均池之前使用附加的3D卷积对变体进行了实验:(1)CONV3D:一个标准的3D卷积层,内核大小为3,步幅为1;(2)Conv(2+1)d:空间和时间上可分离三维卷积。在2D卷积中加入3D卷积本质上导致了类似于Top-Heavy的S3D AR-Chitecture的设计,在视频动作识别上表现出比全3D卷积更好的性能,运行速度也更快。总体而言,使用3D卷积的模型比采用简单平均池化的模型表现更差。对于平均池化,本论文观察到使用两个帧比使用单个帧有显著的改进。然而,与使用两个帧的模型相比,使用两个以上帧的模型执行类似,这表明两个帧已经表示为任务提供足够的本地时间信息。
推断剪切片段数。在推理时,本论文从多个密集采样剪切片段中融合预测得分作为最终得分。为了展示这种策略如何影响性能,本论文在推论中从一个视频中平均抽样Ntest∈{1,2,4,8,16}个剪切片段,并平均他们的单独预测。为了这个实验,本论文为每个剪切片段提供了两个采用不同数的训练帧:一个是单帧,另一个是两帧。两个模型都使用单个剪切片段进行训练。添加更多的剪切片段通常会提高性能,尤其是前几次添加,但在某个点之后性能就饱和了。
训练中的片段数。本论文随机抽取Ntrain个片段,并以融合函数G作为最终得分,对训练片段进行融合,计算训练损失。当使用多个剪切片段时,来自这些样本的信息通过多个实例学习融合,以最大化这些剪切片段的效用。为了了解这种策略如何影响模型性能,本论文评估了在训练时使用Ntrain∈ {1, 2, 4, 8, 16}的模型变体。本论文还考虑了3种常用的分数融合函数:平均池化、最大池化和LogSumExp。在平均池化和最大池化中,交叉剪切片段的池化是在logits上执行的,后面是一个softmax操作器。在LogSumExp中,首先反馈来自每个剪切片段的logit到一个按元素排列的指数运算符,然后是一个交叉剪切片段的平均池化。融合输出通过其自身的总和进一步规范化,使其符合概率分布的条件。为了简单起见,本论文总是使用相同的融合函数进行训练和推断。为了公平的比较,所有模型都使用每个剪切片段一个帧进行训练,16个剪切片段进行推断,即T=1和Ntest=16。大体上,添加更多剪切片段会产生增益,第二个添加的剪切片段提供了最大的性能增益。例如,对于具有LogSumExp的模型,Ntrain=2将Ntrain=1的检索R1分数提高了2.8%,而Ntrain=16相较于Ntrain=2仅提高了1.9,尽管它增加了更多的剪切片段。至于分数融合函数G,LogSumExp表现得最好。
稀疏随机抽样与稠密均匀抽样。在每一个训练步骤中,CLIPBERT只从全长视频中随机采样单个或几个短片段。这种稀疏随机抽样策略可以被理解为一种数据增强方法,其中视频的不同片段子集被用于计算不同训练步骤下的丢失。为了显示这种方法的有效性,本论文将CLIPBERT与使用均匀采样密集剪切片段的变体进行了比较。具体地说,本论文使用与之前相同的CLIPBERT架构,但始终使用16个统一采样的片段进行训练。在所有检索和QA任务中,仅有4个片段的稀疏随机抽样优于全部16个片段的密集均匀抽样。同时,使用4个剪切片段比使用16个剪切片段更节省内存和计算效率。对于这两种抽样方法,也可以使用基于内容的方法来选择剪切片段。然而,这需要额外的非琐碎的选择步骤,还可能移除随机抽样带来的部分数据增强效应。
内存与计算成本。注意到在训练时使用更多的剪切片段或更多的帧显著增加了内存需求和计算成本。例如,当Ntrain=2时,单个NVIDIA V100 GPU允许的最大批处理大小为190,而当Ntrain=16时,允许的最大批处理大小为16。时间开销几乎随Ntrain线性增加,而MSRVTT检索的性能改进不明显。这些比较证明了所提出的稀疏训练策略的效率和有效性。
图文预训练的影响。本论文的模型是通过对COCO和Visual Genome Captions的图像-文本预训练来初始的,以获得更好的对齐的视觉和文本表示。为了验证将图像-文本预训练用于权值初始化的有效性,本论文还评估了使用其他权值初始化策略的变体。具体而言,对于CNN,本论文使用来自随机初始化、在ImageNet上预训练的图像分类模型、在Kinetics-700上预训练的帧式动作识别模型TSN或在Visual Genome上预训练的检测模型grid-feat的权重。对于Transformer和单词嵌入层,本论文使用来自随机初始化或预先训练的BERTBASE模型的权重。对于随机初始化,本论文分别对CNN和Transformer层使用pytorch和Transformer库中的默认设置。本论文注意到随机初始化CNN会导致大的性能下降甚至训练失败,本论文假设这主要是因为在相对较小的数据集(例如,MSRVTT检索训练split:7K视频)上训练大模型是困难的。使用图像-文本预训练权值获得了最佳的性能,表明了使用图像-文本预训练给视频-文本任务带来了很大的帮助。
端到端训练的影响。视频和语言理解的标准范式是用离线提取的特征训练模型,其中任务目标不影响视频和文本编码过程。在这项工作中,本论文以端到端的方式训练本论文的模型,允许模型通过利用任务监督来优化特征表示。本论文将提出的模型与冻结部分参数的变体进行了比较。总体上,本论文的模型实现了最佳的性能,显示了端到端训练的重要性。通过对本论文的端到端图像-文本预训练模型进行微调,它部分地解决了多模态特征disconnection问题。因此,本论文期望从进一步的端到端微调中得到较小的改进。
主要结论:(1)较大的输入图像尺寸有助于提高模型的性能,但当图像尺寸大于448时,增益减小;(2)从每个剪切片段中稀疏采样2帧与密集采样16帧执行相同的操作,表明仅一个或两个帧就足以进行有效的视频和语言训练;在融合不同帧的信息时,平均池化比3D卷积更有效;(3)在推理时增加剪切片段有助于提高模型的性能;跨片段预测的融合策略影响最终性能;(4)稀疏(随机)抽样比密集均匀抽样更有效,同时具有更大的存储和计算效率;(5)图文预训练适用于图文任务;和(6)端到端训练改善了模型性能。
为了进行评估,本论文将CLIPBERT与现有的文本到视频检索和视频问答任务的方法进行了比较。本论文将在训练时使用不同采样方法的模型表示为CLIPBERT Ntrain× T,(随机采样Ntrain1秒的片段进行训练,每个片段包含T个大小为L=448的均匀采样帧)。本论文使用LogSumExp来融合来自多个剪切片段的分数。在推断时,如果没有另外说明,本论文从Ntest=16个均匀采样的片段中融合分数。为了公平的比较,本论文将使用外观和运动以外的特征的模型进行灰化处理,例如,CE使用了来自11个不同模型的外观、场景、运动、人脸、音频、OCR、ASR特征。对于文本到视频检索的任务,CLIPBERT在MSRVTT检索上相较于现存的方法取得了显著的性能增益,这些方法包括HT、ActBERT和HERO。类似地,在DiDeMo和ActivityNetCaptions段落到视频检索任务,本论文最好的CLIPBERT模型在R1上对CE的输出分别为4.3%和3.1%,在这个数据集中,CLIPBERT和现有的长时关系建模的方法相比更具竞争力。特别是,CLIPBERT获得的R1比HSE高0.8%,与使用extra的MMT相比具有竞争力。每个训练步骤只使用40秒的内容进行推理。CLIPBERT的性能通过在训练和推断过程中采样更多的片段得到进一步的提高。同时,本论文还鼓励未来的工作去探索将额外的输入信号(如音频)结合到Clip-Bert框架中,以获得更好的性能。对于视频问答,在所有三个任务中,CLIPBERT都实现了显著的性能增益。CLIPBERT 11分别在TGIF-QA Action、Transition和FrameQA任务上的性能比现有的最先进的QueST高6.9%、6.8%和0.6%。
贡献
(1)本论文提出了一个新的视频+语言任务端到端学习框架CLIPBERT。实验表明,CLIPBERT方法在视频文本任务中的平均视频长度从几秒到三分钟不等,均能获得优于Ex-isting方法的性能。
(2)本论文的工作表明“少即是多”:提出的端到端训练策略使用单个或几个(较少)稀疏采样的剪切片段,通常比使用密集提取的视频特征的传统方法更精确。
(3)本论文证明图像-文本预训练有利于视频-文本任务。本论文还提供了全面的消融研究,以揭示导致CLIPBERT成功的关键因素,为今后的工作提供启发。
小结
本论文提出了通用框架CLIPBERT,通过使用稀疏采样,在每个训练步骤中只使用单个或几个稀疏采样的一个视频的简短的剪切片段,为视频和语言任务提供负担得起的端到端学习。在六个数据集上进行的文本到视频检索和视频问答的实验表明,CLIPBERT的性能优于(或与之相当)现有的利用完整的长视频的方法,表明仅用少量稀疏采样的剪切片段进行端到端学习往往比使用从全长视频中密集提取的离线特征更准确,证明了谚语中“少即是多”的原理。数据集中的视频来自不同的领域和长度,从3秒的通用领域GIF视频到180秒的YouTube人类活动视频,显示了本论文方法的泛化能力。提供了全面的消融研究和彻底的分析,以剖析导致这一成功的因素。