基于LBP和PCA的人脸性别识别方法
基于LBP和PCA的人脸性别识别方法
摘要
本文主要讲对于人脸图像的性别识别,关于人脸检测不再过多的描述。
目录
- 基于LBP和PCA的人脸性别识别方法
- 摘要
- 目录
- 图片的导入与预处理
- 导入图片
- 预处理
- LBP 特征的提取
- LBP的改进与优化
- 旋转不变的 LBP
- LBP特征提取
- 全局特征
- PCA 降维
- SVM 分类器
图片的导入与预处理
导入图片
预处理
直方图均衡化, 灰度值归一化( M×N 维).
LBP 特征的提取
LBP的基本思想是定义于像素的8邻域中, 以中心像素的灰度值为阈值, 将周围8 个像素的值与其比较, 如果周围的像素值小于中心像素的灰度值, 该像素位置就被标记为0, 否则标记为1. 每个像素得到一个二进制组合, 就像00010011. 每个像素有8个相邻的像素点,即有 28 种可能性组合. 如Fig 1

Fig 1 原始LBP8领域示意图
因此, LBP的操作可以被定义为
其中, (xc,yc) 是中心像素, 亮度为 Ic , 而 Ip(p=0,1,⋯,P−1) 是相邻像素的亮度. s(⋅) 是一个符号函数:
这种描述方法可以很好的捕捉到图像中的细节。
LBP的改进与优化
为了适应不同尺度的纹理特征, 并达到灰度和旋转不变性的要求, 相关学者对 LBP 算子进行了改进, 将 3×3 邻域扩展到任意邻域, 并用圆形邻域代替了正方形邻域. 改进后的 LBP 算子允许在半径为 R 的圆形邻域内有任意多 (P) 个像素点. Fig 2 给了三种情况.
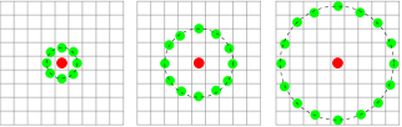
Fig2 改进的圆形领域LBP
对于给定的点 (xc,yc) , 其确定的圆上的某点 (xp,yp) 由下式计算:
其中, R 是圆的半径, P 是圆上的点的个数. 这个操作是对原始 LBP 算子的扩展, 所以有时被称为扩展LBP(又称为圆形LBP). 如果一个在圆上的点不在图像坐标上, 用它周围的像素值内插得到.
例如, 坐标为 (x,y) , 0≤x,y≤1 , f(x,y) 的函数值用周围的 4 个点的函数值内插如下:
旋转不变的 LBP
从 LBP 的定义可以看出, LBP 算子是灰度不变的, 但却不是旋转不变的. 图像的旋转就会得到不同的 LBP值.
有关学者将 LBP 算子进行了扩展, 提出了具有旋转不变性的 LBP 算子, 即不断旋转圆形邻域得到一系列初始定义的 LBP 值, 取其最小值作为该邻域的 LBP 值.
Fig 3 给出了求取旋转不变的 LBP 的过程示意图, 图中算子下方的数字表示该算子对应的 LBP值, 图中所示的 8 种 LBP 模式, 经过旋转不变的处理, 最终得到的具有旋转不变性的 LBP值为 15. 也就是说, 图中的 8种 LBP 模式对应的旋转不变的 LBP模式都是 00001111.

Fig3 旋转不变的圆形LBP
LBP特征提取
在性别识别的过程中,可以考虑分级提取LBP特征. 分级提取局部特征(每级提取的尺度不一样, 可以在不同的 LBP 图上进行):
- 首先, 先把每张预处理过的图片均匀分成 2m×2n (可人为调整)的子图, 对每个子图提取 LBP 特征(得到 num=M/m∗N/n 个子图,提取每个子图的 LBP值 的频数, 再归一化处理).
- 再把每张预处理过的图片均匀分成 m×n (可人为调整) 的子图, 对每个子图提取 LBP 特征.
- 然后, 对整个预处理的图片提取 LBP 特征.
- 把提取的特征(LBP 归一化后的频数)进行拼接, 得到 2P×(1+num+4num) 维的特征.
全局特征
把每张预处理过的图片压缩成 1×MN 维的向量. 此作为图片的全局特征. LBP特征和全局特征分别做PCA降维处理, 之后再拼接成最后的特征.
PCA 降维
分别对局部特征和全局特征进行 PCA 降维处理 (opencv 有现成的算法), 都取累计贡献率维前 90% 的特征向量. 再把降维后的局部与全局特征进行拼接最为最后要用的特征. 且保存特征矩阵, 预测时, 预测图片的特征需要该特征矩阵来投影.
C++ 调用 opencv 的函数
PCA& PCA::computeVar(InputArray data, InputArray mean, int flags, double retainedVariance)
Python 的借口
cv2.PCAComputeVar(data, retainedVariance[, mean[, eigenvectors]]) → mean, eigenvectors
参数:
- data – input samples stored as the matrix rows or as the matrix columns.
- mean – optional mean value; if the matrix is empty (noArray()), the mean is computed from the data.
flags – operation flags; currently the parameter is only used to specify the data layout.
- CV_PCA_DATA_AS_ROW indicates that the input samples are stored as matrix rows.
- CV_PCA_DATA_AS_COL indicates that the input samples are stored as matrix columns.
retainedVariance – Percentage of variance that PCA should retain. Using this parameter will let the PCA decided how many components to retain but it will always keep at least 2.
代码如下:
PCA& PCA::computeVar(InputArray _data, InputArray __mean, int flags, double retainedVariance)
{
Mat data = _data.getMat(), _mean = __mean.getMat();
int covar_flags = CV_COVAR_SCALE;
int i, len, in_count;
Size mean_sz;
CV_Assert( data.channels() == 1 );
if( flags & CV_PCA_DATA_AS_COL )
{
len = data.rows;
in_count = data.cols;
covar_flags |= CV_COVAR_COLS;
mean_sz = Size(1, len);
}
else
{
len = data.cols;
in_count = data.rows;
covar_flags |= CV_COVAR_ROWS;
mean_sz = Size(len, 1);
}
CV_Assert( retainedVariance > 0 && retainedVariance <= 1 );
int count = std::min(len, in_count);
// "scrambled" way to compute PCA (when cols(A)>rows(A)):
// B = A'A; B*x=b*x; C = AA'; C*y=c*y -> AA'*y=c*y -> A'A*(A'*y)=c*(A'*y) -> c = b, x=A'*y
if( len <= in_count )
covar_flags |= CV_COVAR_NORMAL;
int ctype = std::max(CV_32F, data.depth());
mean.create( mean_sz, ctype );
Mat covar( count, count, ctype );
if( _mean.data )
{
CV_Assert( _mean.size() == mean_sz );
_mean.convertTo(mean, ctype);
}
calcCovarMatrix( data, covar, mean, covar_flags, ctype );
eigen( covar, eigenvalues, eigenvectors );
if( !(covar_flags & CV_COVAR_NORMAL) )
{
// CV_PCA_DATA_AS_ROW: cols(A)>rows(A). x=A'*y -> x'=y'*A
// CV_PCA_DATA_AS_COL: rows(A)>cols(A). x=A''*y -> x'=y'*A'
Mat tmp_data, tmp_mean = repeat(mean, data.rows/mean.rows, data.cols/mean.cols);
if( data.type() != ctype || tmp_mean.data == mean.data )
{
data.convertTo( tmp_data, ctype );
subtract( tmp_data, tmp_mean, tmp_data );
}
else
{
subtract( data, tmp_mean, tmp_mean );
tmp_data = tmp_mean;
}
Mat evects1(count, len, ctype);
gemm( eigenvectors, tmp_data, 1, Mat(), 0, evects1,
(flags & CV_PCA_DATA_AS_COL) ? CV_GEMM_B_T : 0);
eigenvectors = evects1;
// normalize all eigenvectors
for( i = 0; i < eigenvectors.rows; i++ )
{
Mat vec = eigenvectors.row(i);
normalize(vec, vec);
}
}
// compute the cumulative energy content for each eigenvector
int L;
if (ctype == CV_32F)
L = computeCumulativeEnergy(eigenvalues, retainedVariance);
else
L = computeCumulativeEnergy(eigenvalues, retainedVariance);
// use clone() to physically copy the data and thus deallocate the original matrices
eigenvalues = eigenvalues.rowRange(0,L).clone();
eigenvectors = eigenvectors.rowRange(0,L).clone();
return *this;
} 需要保存的有特征矩阵: Eig=eigenvectors , 每个图像的特征向量 Featureface (1×m维) 关于 Eig 的投影为: Featurepca=Featureface⋅EigT . 做训练和测试的人脸特征向量都要做这样的投影降维.
SVM 分类器
用提取的特征用线性 SVM 分类器进行训练分类.
参考
http://blog.csdn.net/u010006643/article/details/46417091
http://docs.opencv.org/2.4/modules/refman.html