[论文笔记]SDM: Sequential Deep Matching Model for Online Large-scale Recommender System
一.论文题目与作者
Lv F , Jin T , Yu C , et al. SDM: Sequential Deep Matching Model for Online Large-scale Recommender System[J]. 2019.
二.摘要
这是主要介绍推荐系统中召回技术的一篇文章。主要创新点包括:
1.在用户短期行为中通过multi-head self-attention捕获多种兴趣;
2.通过门控融合模块同时利用用户的短期行为和长期行为。
三.网络结构
线上结构:
![[论文笔记]SDM: Sequential Deep Matching Model for Online Large-scale Recommender System_第1张图片](http://img.e-com-net.com/image/info8/8144718d106c4ec38047ba899392c5e1.jpg)
网络结构:
![[论文笔记]SDM: Sequential Deep Matching Model for Online Large-scale Recommender System_第2张图片](http://img.e-com-net.com/image/info8/79c89295751c458da3fadb29340ea9f9.jpg)
3.1 Session定义
Session定义:
-
同一个session_id的交互行为
-
距离上一个行为小于10min的行为也可以划分到同一个session中
-
session中最长的行为序列为50个,排名超过50的行为划分到下一个session中
短期行为(short-term behavior):距离当前最近的一个session的行为
长期行为(long-term behavior):除了距离当前最近的一个session外,最近7天的用户行为。
3.2 特征
item:item id、叶子类目id、品牌id、店铺id
user:age、gender、life stage等
3.3 pipeline
概要:
1.分别输入短期行为S^u和长期行为L^u,通过编码得到短期行为的表示s_t^u和长期行为的表示p^u;
2.通过门控融合网络(fusion gate),得到预测的用户行为向量o_t^u,维度是dX1;
3.候选的item向量有l个,维度是dX|l|,每个向量用v_i表示,单个item向量的维度是dX1;
4.通过o_t^u与v_i的内积,得到最终的预测得分:

细节:
1.短期行为S^u通过LSTM处理,得到序列:
![[论文笔记]SDM: Sequential Deep Matching Model for Online Large-scale Recommender System_第3张图片](http://img.e-com-net.com/image/info8/8a97a8b70fb7482ca2669f4163273468.jpg)
2.multi-head self-attention:多头注意力机制让模型能够在不同的位置共同关注来自不同表示子空间的信息,为用户在不同方面的行为进行建模。
将序列X^u作为multi-head self-attention的输入。维度说明:
![[论文笔记]SDM: Sequential Deep Matching Model for Online Large-scale Recommender System_第4张图片](http://img.e-com-net.com/image/info8/043e0a3d3ffd4b6584b733756732dad5.jpg)
attention:
![[论文笔记]SDM: Sequential Deep Matching Model for Online Large-scale Recommender System_第5张图片](http://img.e-com-net.com/image/info8/9ad441fa1a6a439792b42dfefb04dd65.jpg)
最终得到:
![]()
3.user attention
不同的用户在相似的商品序列上会展示不同的商品偏好。因此,增加了 user attention模块,挖掘出更细粒度的个性化信息。类似于softmax的做法,将用户的embedding e^u作为query向量,与序列中的各个action相乘,得到每个action的权重。(Q:这种类似于softmax的attention的出处是哪里??经常看到这种方法的使用)
![[论文笔记]SDM: Sequential Deep Matching Model for Online Large-scale Recommender System_第6张图片](http://img.e-com-net.com/image/info8/b9221883f0b6445e9e091074e3b875fc.jpg)
4.long term behavior fusion
从长期来看,用户通常会在不同维度上积累不同层次的兴趣。用户可能经常访问一组类似的商店,并反复购买属于同一类别的商品。
这里将长期行为划分为不同的子集,包括长期的item id、叶子类目id、类目id、品牌id、店铺id等。对于每一个子集,将不同的稀疏向量分别转换成稠密向量。再使用user embedding作为query向量,计算user embedding和不同类别长期特征的attention的分数,最后得到不同类别长期特征的表示。最后再进行concat。
![[论文笔记]SDM: Sequential Deep Matching Model for Online Large-scale Recommender System_第7张图片](http://img.e-com-net.com/image/info8/a5ddf225621e4c20820c2463ee7e34b0.jpg)
![[论文笔记]SDM: Sequential Deep Matching Model for Online Large-scale Recommender System_第8张图片](http://img.e-com-net.com/image/info8/347a3bcd2a0b4d5eacf6f15d8cca4f85.jpg)
5.门控融合网络
同时将短期行为、长期行为和user embedding作为输入,得到门控向量G_t^u。将门控向量与1-门控向量分别与短期行为的表示和长期行为的表示做点乘。(这里作为一个突破点,但是在结构介绍的时候只用了非常短的篇幅?)


四.实验
4.1 评估标准
命中率:表示前K位中正确推荐的item占所有测试item的比例
![[论文笔记]SDM: Sequential Deep Matching Model for Online Large-scale Recommender System_第9张图片](http://img.e-com-net.com/image/info8/d128b200cf3c436480df91d9d8c7f0e2.jpg)
准确率:|P_u| = K
![[论文笔记]SDM: Sequential Deep Matching Model for Online Large-scale Recommender System_第10张图片](http://img.e-com-net.com/image/info8/1dc874e173e945d8977e1f14413774df.jpg)
召回率:
![[论文笔记]SDM: Sequential Deep Matching Model for Online Large-scale Recommender System_第11张图片](http://img.e-com-net.com/image/info8/cf6b41b12fdf4283b80f728befb5bd6e.jpg)
F1:
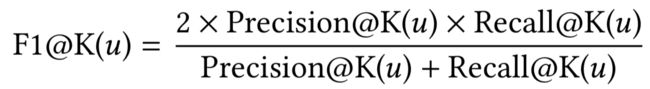
4.2 比较方法
1.item-based CF:工业界使用最多的生成候选集的方法。通过协调过滤方法生成item-item的相似矩阵。 2.DNN:Youtube提出,videos和users的向量连接在一起,送入到多层的全连接神经网络中。
3.GRU4REC:通过rnn解决基于session的推荐问题。
4.narm:GRU4REC的升级版,同时利用了global attention和local attention。
5.shan:融合了用户稳定的历史偏好和当前的购物偏好。
6.binn:编码消费动机和历史购物行为。
7.sdmma:本文的baseline+multi-head self-attention。
8.psdmma:本文的baseline+multi-head self-attention+user attention。
9.psdmmal:本文的baseline+multi-head self-attention+user attention+long term behaviors。
10.psdmmal-N:基于psdmmal,将多个item作为target,本实验中N=5。
11.psdmmal-noS:基于psdmmal,但是item和user都只有id信息,而没有其他的信息。
离线结果:
![[论文笔记]SDM: Sequential Deep Matching Model for Online Large-scale Recommender System_第12张图片](http://img.e-com-net.com/image/info8/d3c0180444fe407689d484c6349e0137.jpg)
4.3 比较不同的融合方式
元素的点乘、连接和相加方式都直接作用于未过滤的长期偏好,而忽略了只有少数长期偏好和当前的短期会话是有强相关性的。而门控融合网络可以捕捉多种层级的用户偏好,取得了最好的效果。
![[论文笔记]SDM: Sequential Deep Matching Model for Online Large-scale Recommender System_第13张图片](http://img.e-com-net.com/image/info8/6294f82ab5d84b449b54b8e1211cb0a5.jpg)
![[论文笔记]SDM: Sequential Deep Matching Model for Online Large-scale Recommender System_第14张图片](http://img.e-com-net.com/image/info8/691f6c975e314e1c8110bb2ffd100643.jpg)
五.总结
本文提出了两个创新点,应该都是平时会用到的一些trick总结成文的。