SPARQL
一、简介
作为一种查询语言,SPARQL是“面向数据的”,因为它只查询模型中保存的信息;查询语言本身没有推理。SPARQL除了以查询的形式获取应用程序所需内容的描述,并以一组绑定或RDF图的形式返回该信息外,什么也不做。
执行sparql查询:
sparql.bat --data=../vc-db-1.rdf --query=q-bp1.rq

算术表达式必须在圆括号(圆括号)中。如(?number>30000)

二、字符串匹配
SPARQL提供了一个基于正则表达式测试字符串的操作。这包括请求SQL“LIKE”样式测试的能力,尽管正则表达式的语法不同于SQL。语法如下:
FILTER regex(?x, "pattern" [, "flags"])flags:可选的,标志“i”表示完成了不区分大小写的模式匹配。

三、BLANK NODE

PREFIX vcard:
SELECT ?y ?givenName
WHERE
{ ?y vcard:Family "Smith" .
?y vcard:Given ?givenName .
} 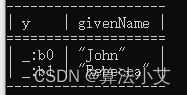
以_:开头的奇怪的qname。这不是空白节点的内部标签——是ARQ将它们打印出来,并分配了_:b0, _:b1来显示两个空白节点是否相同。在这里它们是不同的。它不会显示空白节点使用的内部标签,尽管在使用Java API时可以使用该标签。

四、可选信息(Optional Information)
4.1.简介
RDF是半结构化数据,因此SPARQL具有查询数据的能力,但在数据不存在时不会查询失败。查询使用可选部分来扩展在查询解决方案中找到的信息,但无论如何都会返回非可选信息。
John Smith
25
Smith
John
Becky Smith
23
Smith
Rebecca
Sarah Jones
Jones
Sarah
Matt Jones
这个查询获取一个人的名字,如果该信息可用,还可以获取他们的年龄。
PREFIX info:
PREFIX vcard:
SELECT ?name ?age
WHERE
{
?person vcard:FN ?name .
OPTIONAL { ?person info:age ?age }
} 查询结果:
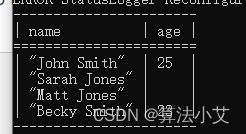
PREFIX info:
PREFIX vcard:
SELECT ?name ?age
WHERE
{
?person vcard:FN ?name .
?person info:age ?age .
} 查询结果:
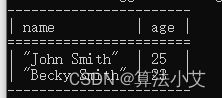
4.2. 可选过滤器(OPTIONALs with FILTERs)
OPTIONAL是一个组合两个图形模式的二进制运算符。可选模式是任何组模式,可能涉及任何SPARQL模式类型。如果组匹配,则扩展解,如果不匹配,则给出原始解
①
PREFIX info:
PREFIX vcard:
SELECT ?name ?age
WHERE
{
?person vcard:FN ?name .
OPTIONAL { ?person info:age ?age . FILTER ( ?age > 24 ) }
} 查询结果:
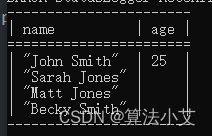
②如果将过滤条件移出可选部分,则它可能会影响解的数量,但可能需要使过滤器更复杂,以允许变量年龄被解除绑定
PREFIX info:
PREFIX vcard:
SELECT ?name ?age
WHERE
{
?person vcard:FN ?name .
OPTIONAL { ?person info:age ?age . }
FILTER ( !bound(?age) || ?age > 24 )
} 查询结果:

如果一个解有一个年龄变量,那么它必须大于24。它也包括非绑定的。
4.3. 可选项和顺序相关查询(OPTIONALs and Order Dependent Queries)
rdf文件:
John Smith
John Smith
Becky Smith
Rebecca Smith
Sarah Jones
Matthew Jones
PREFIX foaf:
SELECT ?name
WHERE
{
?x a foaf:Person .
OPTIONAL { ?x foaf:name ?name }
OPTIONAL { ?x vCard:FN ?name }
} 如果第一个optional将?name和?x绑定到某些值,那么第二个optional将尝试匹配基础三元组(?X和?name有值)。如果第一个可选选项与可选部分不匹配,那么第二个可选选项将尝试用两个变量匹配其三重变量。
查询结果:

五、模式中的备选方案(Alternatives in a Pattern)
5.1. UNION -访问相同数据的两种方式
以下为Turtle RDF格式的RDF文件,文件后缀为.ttl
@prefix foaf: .
_:a foaf:name "Matt Jones" .
_:b foaf:name "Sarah Jones" .
_:c vcard:FN "Becky Smith" .
_:d vcard:FN "John Smith" . PREFIX foaf:
SELECT ?name
WHERE
{
{ [] foaf:name ?name } UNION { [] vCard:FN ?name }
} 查询结果:

名称使用哪种形式的表达式并不重要,?name变量已经设置。这可以使用FILTER实现,如下查询所示:
PREFIX foaf:
SELECT ?name
WHERE
{
[] ?p ?name
FILTER ( ?p = foaf:name || ?p = vCard:FN )
} 5.2. UNION -记住在哪里找到数据
PREFIX foaf:
SELECT ?name1 ?name2
WHERE
{
{ [] foaf:name ?name1 } UNION { [] vCard:FN ?name2 }
}
---------------------------------
| name1 | name2 |
=================================
| "Matt Jones" | |
| "Sarah Jones" | |
| | "Becky Smith" |
| | "John Smith" |
--------------------------------- 5.3. OPTIONAL and UNION
在实践中,OPTIONAL比UNION更常见,但它们都有各自的用途。OPTIONAL用于扩展找到的解决方案,UNION用于连接来自两个可能性的解决方案。它们不一定以相同的方式返回信息:
PREFIX foaf:
SELECT ?name1 ?name2
WHERE
{
?x a foaf:Person
OPTIONAL { ?x foaf:name ?name1 }
OPTIONAL { ?x vCard:FN ?name2 }
}
---------------------------------
| name1 | name2 |
=================================
| "Matt Jones" | |
| "Sarah Jones" | |
| | "Becky Smith" |
| | "John Smith" |
--------------------------------- 六、datasets
6.1 入门案例
RDF数据集是SPARQL查询查询的单元。它由一个默认图和一些命名图组成。
图匹配操作(基本模式、可选选项和联合)在一个RDF图上工作。这开始是数据集的默认图,但它可以通过GRAPH关键字更改。
GRAPH uri { ... pattern ... }
GRAPH var { ... pattern ... }1.如果给出了URI,则模式将与数据集中具有该名称的图进行匹配——如果没有,则graph子句根本无法匹配。
2.如果给出了变量,则尝试所有已命名的图(不是默认图)。该变量可以在其他地方使用,以便在执行期间,如果某个解决方案已经知道它的值,则只尝试特定的命名图。
举例:
RDF数据集可以采用多种形式。两种常见的设置是将默认图作为所有已命名图的联合(RDF合并),或者将默认图作为已命名图的目录(它们来自哪里,何时读取等)。没有限制-一个图可以在不同的名称下包含两次,或者一些图可以与其他图共享三元组。
Default graph (ds-dft.ttl):
@prefix dc: .
dc:date "2005-07-14T03:18:56+0100"^^xsd:dateTime .
dc:date "2005-09-22T05:53:05+0100"^^xsd:dateTime . Named graph (ds-ng-1.ttl):
@prefix dc: Named graph (ds-ng-2.ttl):
@prefix dc: 也就是说,我们有两个描述一些书籍的小图,我们有一个默认图,它记录了这些图最后一次阅读的时间。
查询可以在命令行应用程序中运行:
java -cp ... arq.sparql
--graph ds-dft.ttl --namedgraph ds-ng-1.ttl --namedgraph ds-ng-2.ttl
--query query file
//在命令行中是一行,官网样例
//自己实测应该为
arq --graph ds-dft.ttl --namedgraph ds-ng-1.ttl --namedgraph ds-ng-2.ttl --query q-ds-1.rqPREFIX xsd:
PREFIX dc: (前缀:<.> 只是帮助格式化输出)
查询结果:

这只是默认的图-没有来自已命名图的任何内容,因为除非通过graph显式指示,否则不会查询它们
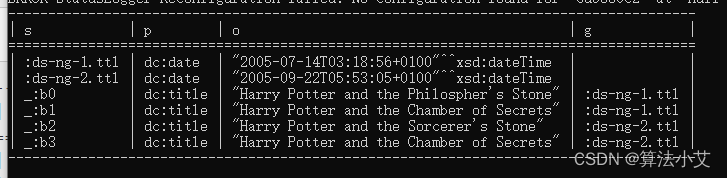
我们可以通过查询默认图和命名图来查询所有的三元组
PREFIX xsd:
PREFIX dc: 查询结果:
如果应用程序知道命名图,它可以直接进行查询,例如查找给定图中的所有标题
PREFIX dc: 查询结果:

6.2. Querying to find data from graphs that match a pattern
PREFIX xsd:
PREFIX dc: 查询结果:

6.3.Describing RDF Datasets - FROM and FROM NAMED
查询执行可以在构建执行对象时给出数据集,也可以在查询本身中描述查询执行。当详细信息在命令行上时,将创建一个临时数据集,但应用程序可以创建数据集,然后在许多查询中使用它们。
在查询中描述时,FROM
不要被默认图是由FROM子句中的一个或多个url描述的事实所迷惑。这是读取数据的地方,而不是图的名称。由于可以给出几个FROM子句,数据可以从多个地方读入,但它们都不会成为图名。
FROM NAMED
例如,在默认图和命名图中查找所有三元组的查询可以写成:
PREFIX xsd:
PREFIX dc:
FROM NAMED
FROM NAMED
{
{ ?s ?p ?o } UNION { GRAPH ?g { ?s ?p ?o } }
} 查询结果:

七、更多了解
7.1生产结果集(Producing Result Sets)
SPARQL有四种结果表单:
①SELECT:返回一个结果表。
②CONSTRUCT:根据查询中的模板返回一个RDF图。
③description:根据查询处理器被配置为返回的内容,返回一个RDF图。
④ASK:询问一个布尔查询。
SELECT表单直接返回一个解决方案表作为结果集,而DESCRIBE和CONSTRUCT使用匹配的结果来构建RDF图。
7.2解决方法修饰符(Solution Modifiers)
模式匹配产生一组解决方案。这个集合可以通过多种方式进行修改:
投影-只保留选定的变量
①OFFSET/LIMIT:切割数字解决方案(最好使用ORDER BY)
②ORDER BY:排序结果
③DISTINCT:对于变量和值的一个组合只产生一行。