Fourier Neural Operator(FNO)求解非线性偏微分方程
FNO的前世今生
继上次的DeepONet求解偏微分方程的文章,这次是介绍结合傅里叶算子和图神经网络的方法,也就是傅里叶神经算子方法,这篇创造性地引入了傅里叶算子,获得了可以与DeepONet扳手腕的速度和经度
Li, Zongyi, et al. "Fourier neural operator for parametric partial differential equations." International Conference on Learning Representing, 2021. (arXiv preprint arXiv:2010.08895).
DeepONet的作者陆路博士还将FNO与DeepONet进行了比较,也进行了一些拓展,有兴趣的读者可以参考以下的论文:
Lu, Lu, et al. "A comprehensive and fair comparison of two neural operators (with practical extensions) based on fair data." Computer Methods in Applied Mechanics and Engineering 393 (2022): 114778.
如果直接看FNO那篇论文,大部分一开始的感觉都是不知所云,我也是这样的。这里我推荐可以先看一下论文一作Zongyi Li博士的之前两篇文章,可以帮助更好地理解FNO这篇论文:
Li, Zongyi, et al. "Neural operator: Graph kernel network for partial differential equations." ICLR 2020 Workshop on Integration of Deep Neural Models and Differential Equations, 2020.
当然了,读者也可以忽略上面的简介,下面我尽量把FNO介绍地比较清楚。
图核函数网络
这里就直接叙述图核函数网络的想法,下面给出一个一般形式的偏微分方程的系统
$$ \begin{aligned} \left(\mathcal{L}_{a} u\right)(x) &=f(x), & & x \in D \\ u(x) &=0, & & x \in \partial D \end{aligned} $$
其中\( u(x)=u(x,t) \),作者在这里是忽略了时间这个维度\(t\),此外还默认\( u(x) \)是一个标量,这里的参数\(a\)可以是系统的不同参数或者控制输入,这里的\(f(x)\)是一个固定的函数,在训练和使用的时候都是不变(并不是控制输入,这里要理解)。
随后,作者就引入了Green函数这个概念,\(G: D \times D \rightarrow \mathbb{R}\)是下面这个方程的唯一解
$$ \mathcal{L}_{a} G(x, \cdot)=\delta_{x} $$
其中\(\delta_{x}\)就是复变中的狄利克雷函数,是一个定义在实数范围上、值域不连续的函数。狄利克雷函数的图像以Y轴为对称轴,是一个偶函数,它处处不连续,处处极限不存在,不可黎曼积分。
这个Green函数突然跳出来是很诡异的,但是其拥有很多良好的性质,可以表示偏微分方程的解
$$ u(x)=\int_{D} G_{a}(x, y) f(y) d y $$
上面的式子表示的意思,只要能够找到这样一个Green函数,那么在整个控制域内做积分就能得到偏微分方程的解\(u(x)\),这显然是不现实的,Green函数只在少数的情况下是解析的,这也就意味着解析的精确解是无法得到,但是可以利用神经网络的强大拟合能力对Green函数进行逼近,这也就是FNO方法的主要思想。
下面就是用核函数对Green函数进行逼近:
$$ v_{t+1}(x)=\sigma\left(W v_{t}(x)+\int_{D} \kappa_{\phi}(x, y, a(x), a(y)) v_{t}(y) \nu_{x}(d y)\right)\tag{1} $$
其中\(\kappa_{\phi}(x, y, a(x), a(y))\)就是核函数,\(\sigma\)是激活函数,\(\nu_{x}(d y)\)是测度(这里不用管),但是还是有问题,这个公式是要在整个控制域\( D\)上进行计算,其计算量是非常大,相当于是一个全连接的图网络,基本是偏微分方程的维度上来之后,这就是不可行的,这里\(v(x) \)是对\(u(x) \)的一个可逆变换,得到一个更高维的向量,具有更多的特征。
为了提高问题的一般性,作者随后就提出自己的算法用节点的邻域\(B(x,r)\)来代替\( D\),下面是对上面方法的一个近修正
$$ \begin{aligned} v_0(x)=&P\left( x,a(x),a_{\epsilon}(x),\nabla a_{\epsilon}(x) \right) +p\\ v_{t+1}(x)=&\sigma \left( Wv_t(x)+\int_{B(x,r)}{\kappa _{\phi}}(x,y,a(x),a(y))v_t(y)\mathrm{d}y \right)\\ u(x)=&Qv_T(x)+q\\ \end{aligned} $$
其中\( a_{\epsilon}(x)\)是对\( a(x)\)的高斯光滑版本,相当于提升对于不同参数\( a(x)\)的泛化性能,P是将低维投影到高维的矩阵,Q则是将高维向量投影到低维的矩阵,都是投影算子,为了增加神经网络的特征维度。
下面就是用神经网络对核函数\( \kappa _{\phi}(x,y,a(x),a(y)) \)进行毕竟,此外,还要注意到这是在邻域\(B(x,r)\)上的,我们很自然地就想到是消息传递图神经网络,就是下面的形式
$$ v_{t+1}(x)=\sigma\left(W v_{t}(x)+\frac{1}{|N(x)|} \sum_{y \in N(x)} \kappa_{\phi}(e(x, y)) v_{t}(y)\right) $$
需要指出的是,这里的边特征定义为\( e(x, y)=(x, y, a(x), a(y)) \),剩下的工作就是搭建合适的神经网络对核函数的\(\kappa _{\phi}\)进行逼近,这里的具体实现方式可以参考图网络里面的一些方法,也有一些创新点可以做。
如果本文中是考虑在整个控制域\( D\)上构建全连接神经网络,那么复杂度就是\( \mathcal{O}\left(K^{2}\right)\),作者这里提供了一个思路,就是采集\( l\)个子图,每个子图均匀随机采样\( m \ll K\)个节点,那么复杂度就是\( \mathcal{O}\left(lm^{2}\right)\),这里的复杂度就能有所下降,随后作者还给出了一个降低复杂度的准确度误差的上界,这就是FNO的没有引入傅里叶算子的版本,后面的FNO就是为了降低对核函数\(\kappa _{\phi}\)的逼近成本。
降低\(\kappa _{\phi}\)的逼近成本下面的论文给出了一个方法:
Li, Zongyi, et al. "Multipole graph neural operator for parametric partial differential equations." Advances in Neural Information Processing Systems 33 (2020): 6755-6766.
FNO的庐山真面目
通过上面的介绍Zongyi Li博士的两篇论文,FNO可以自然地被导出。
如果我们去掉对函数\(\kappa _{\phi}\)对 \(a \)的依赖并强加\(\kappa_{\phi}(x, y)=\kappa_{\phi}(x-y) \),可以得到(1)是一个卷积算子。
对于卷积算子,应用傅里叶变换可以得到如下的结果:
$$ \left(\mathcal{K}(a ; \phi) v_{t}\right)(x)=\mathcal{F}^{-1}\left(\mathcal{F}\left(\kappa_{\phi}\right) \cdot \mathcal{F}\left(v_{t}\right)\right)(x) $$
解除上述公式对\( a\)的依赖,我们可以得到
$$ \left(\mathcal{K}(\phi) v_{t}\right)(x)=\mathcal{F}^{-1}\left(R_{\phi} \cdot\left(\mathcal{F} v_{t}\right)\right)(x) \quad \forall x \in D $$
其中\( k\in D, \left( \mathcal{F} v_t \right) (k)\in \mathbb{C} ^{d_v},R_{\phi}(k)\in \mathbb{C} ^{d_v \times d_v}\),都是一个函数空间,因为图网络其实是对连续空间的一个离散化,这里我们也就考虑对这些参数进行离散化,并利用快速FFT进行变化。此外,由于傅里叶变换的频率是\( -\infty \rightarrow +\infty \),那么这里是对频率进行了一个限制,也就是说把傅里叶变换截断到上限频率\( k_{\max}=\left| Z_{k_{\max}} \right|\),\( R_{\phi} \)是一个\( \left( k_{\max}\times d_v\times d_v \right) \)维的三阶张量,下面就是运用图神经网络对\( R_{\phi} \)进行学习。后面还有介绍快速离散傅里叶变换的部分,主要是数学部分了,这里就不再赘述了。
下面给出了算法的具体实现流程图:
作者在实验部分进行了比较,与U-Net、TF-Net和ResNet等经典方法相比具有明显的优势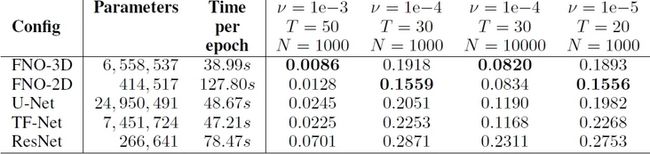
和DeepONet一样,算子学习方法主要解决这些问题
- 对于没有外源输入的情况,a(x)就是不同的输出条件和位置坐标,这样能处理不同的初始条件;
- 对于有外源输入的情况,a(x)就是外源输入和坐标位置,只能处理训练数据对应的初始条件;
- a(x)可以包括时间t,也可以不包括时间t(这样的话就按照\( \varDelta t \)的间隔滚动迭代求解)。
这里FNO-2D与FNP-3D的主要区别就是,FNO-2D利用了RNN结构,可以将解以固定间隔长度\(\varDelta t \) 的增量传播到任意时间\(T\),是一种自回归迭代的方法;FNP-3D直接将时间维度增广到控制维度上去,以Conv3D结构直接训练,可以直接得到任意离散时间点\(t\)上进行求解,不需要递推式的解法去求解,和DeepONet一样,是一种直接映射。FNO-3D方法更具表现力且更易于训练,但是实验里看出的是参数量更多且表现提升不多。
结论
傅里叶神经算子在噪声数据上的表现是超过DeepONet,我猜是因为傅里叶变换时把高频的噪声信号给滤去了,这样傅里叶神经算子就对噪声不敏感了。FNO算法也启发了后来的很多研究,大家有兴趣地可以深入阅读下面这篇的论文,也是使用了消息传递图神经网络,其基本思想是自回归求解器,是对传统方法的一个增强:
Johannes Brandstetter and Daniel E. Worrall and Max Welling. "Message passing neural PDE solvers." International Conference on Learning Representations (2022).