中文文本纠错论文
ACL2021论文收录列表:ACL-IJCNLP 2021
中文文本纠错paper&code列表:CTCResources/README_ZH.md (github.com)
中文处理文章集合:Special Interest Group on Chinese Language Processing (SIGHAN) - ACL Anthology
论文一:ACL2021
PLOME: Pre-training with Misspelled Knowledge for Chinese Spelling Correction
论文地址:https://aclanthology.org/2021.acl-long.233.pdf
仓库地址:https://github.com/liushulinle/PLOME
- 预训练过程中使用混淆集(近音、近形)中相似单词MASK选择的单词
- 通过使用拼音、笔画作为输入来预测单词
- 使用GRU网络根据字符的语音和笔画知识进行建模
中文错误(近音字、近形字)
词嵌入模块中,使用字符嵌入(character embedding)、位置嵌入(position embedding)、语音嵌入(phonic embedding)、字形嵌入(shape embedding)。
字符嵌入与位置嵌入与BERT的输入一致
使用语音嵌入以及字形嵌入预训练模型,并且应用于下游任务中
语音嵌入(Unihan数据库):Unihan Database Lookup
字形嵌入(Chaizi数据库):https://en.wikipedia.org/wiki/Stroke_order
预训练与微调过程中:使用的损失函数是 语音嵌入损失 与 字形嵌入损失的 联合预测
数据集:
预训练数据集:wiki2019zh数据集(100w中文wiki语料)和300w篇新闻文章
fine-tuning数据集:2013、2014、2015年的SIGHAN数据集构成
中文混淆集(近音字、近形字)
在预训练过程中,使用困惑集中的单词来对mask的单词进行替换
Chinese Spelling Check Evaluation at SIGHAN Bake-off 2013
论文地址:https://aclanthology.org/W13-4406.pdf

对比方法:
Spelling Error Correction with Soft-Masked BERT
https://aclanthology.org/2020.acl-main.82.pdf
SpellGCN: Incorporating Phonological and Visual Similarities into Language Models for Chinese Spelling Check
https://aclanthology.org/2020.acl-main.81.pdf
- 使用混淆集来进行模型的预训练
实验部分:
- 模型参数初始化策略有效性
- 语音、字形特征可视化
- 不同模型训练速度、收敛速度
论文二:ACL2021
PHMOSpell: Phonological and Morphological Knowledge Guided Chinese Spelling Check
论文地址:https://aclanthology.org/2021.acl-long.464.pdf
- 从多模态信息中获取汉字的语音知识和形态知识
- 设计一个新奇的自适应通道机制, 有效的结合多模态信息于预训练模型中
先前工作的不足:
- 语音和字形知识作为额外的知识,没有应用于端到端的框架中
- SpellGCN进行了预训练模型的训练,但是应用混淆集使得替换的单词信息受限,不能扩展到所有单词
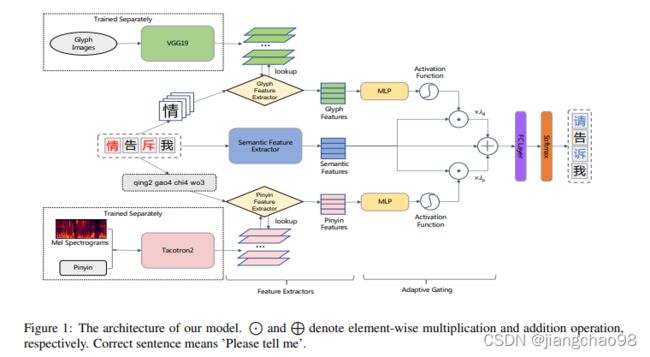
利用拼音特征、字形特征、语音特征做信息融合、预测最终错别字结果
拼音特征抽取器:
- Natural tts synthesis by conditioning wavenet on mel spectrogram predictions.
- https://github.com/Rayhane-mamah/Tacotron-2
- a recurrent sequenceto-sequence mel spectrograms prediction network, to help modeling the phonological representations since its location-sensitive attention can create effective time alignment between the character sequence and the acoustic sequence.
字形特征抽取器:
- VGG19:GitHub - pytorch/vision: Datasets, Transforms and Models specific to Computer Vision
- 参考论文:Glyce: Glyph-vectors for chinese character representations.
数据集:
训练数据集:2013、2014、2015年的SIGHAN数据集、271K训练样例自动生成使用(OCR、ASR)
自动生成训练数据集paper:
- A hybrid approach to automatic corpus generation for chinese spelling check.
测试数据集:2013、2014、2015年的SIGHAN数据集
中文繁体简体字转换工具:
OPENCC:GitHub - BYVoid/OpenCC: Conversion between Traditional and Simplified Chinese
对比方法:
Adaptable filtering using hierarchical embeddings for chinese spell check.
http://export.arxiv.org/pdf/2008.12281
SpellGCN: Incorporating Phonological and Visual Similarities into Language Models for Chinese Spelling Check
https://aclanthology.org/2020.acl-main.81.pdf
- 使用混淆集来进行模型的预训练
实验部分:
- 验证超参数的有效性
- 特征可视化
- 错误样例分析
特征维度大小分析(论文解读):
On the Dimensionality of Word Embedding
https://arxiv.org/pdf/1812.04224.pdf
论文三:ACL2021(findings)
Correcting Chinese Spelling Errors with Phonetic Pre-training
论文四:ACL2021(findings)
Global Attention Decoder for Chinese Spelling Error Correction
论文五:ACL2021(findings)
Dynamic Connected Networks for Chinese Spelling Check
论文六:ACL2021(short)
Exploration and Exploitation: Two Ways to Improve Chinese Spelling Correction Models
论文七:ACL2021(short)