OpenCV实践小项目(二) -文档ocr扫描识别
1. 写在前面
今天整理OpenCV入门的第二个实战小项目, 前一篇文章是信用卡数字识别, 主要运用了OpenCV基础图像处理操作里面的轮廓检测, 边缘检测,形态学操作, 今天的这个项目叫做文档ocr扫描识别,就是给定一个文档的图片,然后识别文档上的文字信息,这个在生活中也是非常常见的哟。 比如试卷扫描,文章扫描等等吧,其实原理都非常类似。
下面是给定了一个随意拍摄的购物小票的图片, 然后通过一顿图片处理等操作,得到的ocr扫描结果:

由于这个截图我进行了放缩,导致右边这个图片人眼看不太清楚字了,但是基本上还是都识别出来了。感觉还挺有意思的。 下面我们就来看下这次有什么新东西。
2. 处理逻辑
和之前一样,我们还是先分析,这个东西要做的话应该怎么去考虑,首先,我们拿到了右边的这样一张图片,然后想让计算机识别出里面的文字,那么应该需要对文档进行处理。
怎么处理呢? 操作如下:
- 首先,先通过边缘检测, 拿到图片中间的小票部分,去掉冗余的背景信息
- 接下来,轮廓检测,把中间小票部分给他弄个框框起来,这个才是我们的重点部分,即轮廓检测拿到对象
- 这次只拿到这个对象还没有完,因为在图片里面这个小票有些太小了, 接下来,需要进行透视变换操作,让整个小票横铺到图片大小,这个操作还是比较骚气的,在图像配准里面是一个非常经典的操作。也是这次学习任务的重点。
通过上面这个预处理操作,就能得到一个非常规整且突出的只有小票信息的图片, 接下来,就是利用这个图片进行ocr识别, 这个cv2里面就没有直接能用的函数了,而是借助第三方工具包tesseract-ocr, 这个东西也是非常强大, 给定图片之后,直接能识别图片里面的文字。 前提是如果识别的较为准确, 前期的这个图像处理也非常重要。 所以这次的任务就聚焦在前期的这个工作上。 至于识别,安装好包,python一键识别即可。
3. 图片预处理工作
根据上面的分析, 图片预处理操作主要是三步,边缘检测-> 轮廓检测->透视变换, 下面通过代码一一来看。
首先,先读入图片
# 读取图片
image = cv2.imread("images/receipt.jpg")
cv_show('img', image) # 原始图片是2448*3264, 太大了,下面需要进行resize操作
这个图片是很大的,接下来想resize成一个较小的图片,但这里要注意resize之前,需要保存变化的比例以及原始的图片。 之所以要保存变化的比例,是因为resize之后的图像,每个像素点的位置都发生了改变,我们后面处理的是resize图像,但是最终做透视变换的时候,我们需要用到原始图像以及原始图像中各像素点的位置,此时就需要通过这个比例去还原。 保存原始图像也是一样的道理。 后面就会看到。
# resize操作之前,需要保存resize的比例,以及原始图像
# 下面要按照500的比例对图像进行resize, 那么原始图像的每个像素点的位置都会改变,记住ratio是为了最终能还原到原始的位置上去
ratio = image.shape[0] / 500.0
orig = image.copy()
# 接下来,resize操作
image = resize(orig, height=500)
cv_show('img', image)
这个结果就是上图中右边小票的这个结果了。
3.1 边缘检测
接下来是边缘检测部分, 这个直接使用Canny边缘检测即可。
# 预处理 转成灰度图 -> 高斯滤波 -> Canny边缘检测
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
#gray = cv2.GaussianBlur(gray, (5, 5), 0) 边缘检测算法其实就是用的高斯滤波,所以这里这个不用发现更加清晰些
edged = cv2.Canny(gray, 75, 200)
这里尝试了先高斯滤波,然后在Canny和直接Canny,发现后者效果更清晰些,Canny算法里面也是用高斯滤波进行处理嘛。这样得到的结果如下:

这个图片,我们接下来需要用轮廓检测,把外围最大的这个框给找到,然后才能把小票给取出来。
3.2 轮廓检测
轮廓检测这里,依然是cv2的findContours函数一步查找, 这里要经过一个排序操作,根据轮廓的面积,选择出较大的几个来。
# 轮廓检测
cnts, hierarchy = cv2.findContours(edged.copy(), cv2.RETR_LIST, cv2.CHAIN_APPROX_SIMPLE)
cnts = sorted(cnts, key = cv2.contourArea, reverse=True)[:5]
其实需要的应该是最大的那个,但是为了保险起见,选择出5个候选的来。接下来,怎么找到外围的这个轮廓呢? 其实这个轮廓我们眼看着是长方形,但实际上并不是很规整,尤其是如果纸再稍微卷点,那么可能这个轮廓是锯齿形的这种。 所以,接下里,我们遍历这5个轮廓,对于每个轮廓,先做一个近似操作,也就是把这种锯齿形的尽量的弄成直的,然后对于最外面这个大的轮廓,还有个特点,就是长方形,只有4个顶点。
# 下面要获取到最外围的大轮廓, 因为我们只需要这个大轮廓里面的所有东西, 外面黑色的背景其实不需要
for c in cnts:
# 计算轮廓近似
peri = cv2.arcLength(c, True)
# C表示输入的点集
# epsilon表示从原始轮廓到近似轮廓的最大距离
# True表示封闭
approx = cv2.approxPolyDP(c, 0.02*peri, True)
# 4个点的时候,说明是最外面的大轮廓,此时把这个拿出来
if len(approx) == 4:
screenCnt = approx
break
这样,就找到了最外围的轮廓,我们可以可视化出来:
cv2.drawContours(image, [screenCnt], -1, (0, 255, 0), 2)
cv_show("Outline", image)
结果如下:

这个找的还是不错的,有了这个轮廓,我们就能拿到这个小票了,但是这个小票此时太小了,字迹也不是很清晰, 所以接下来,经过一步透视变换操作,让小票铺满这个图片,这个操作很骚气的。
3.3 透视变换
透视变换其实是这样,就是将图片投影到一个新的视平面,通用的变换公式如下:
[ x ′ , y ′ , w ′ ] = [ u , v , w ] [ a 11 a 12 a 13 a 21 a 22 a 23 a 31 a 32 a 33 ] \left[x^{\prime}, y^{\prime}, w^{\prime}\right]=[u, v, w]\left[\begin{array}{lll} a_{11} & a_{12} & a_{13} \\ a_{21} & a_{22} & a_{23} \\ a_{31} & a_{32} & a_{33} \end{array}\right] [x′,y′,w′]=[u,v,w]⎣⎡a11a21a31a12a22a32a13a23a33⎦⎤
u , v u,v u,v是原始图片, 对应得到的变换后的图片坐标 x , y x,y x,y,其中 x = x ′ w ′ , y = y ′ w ′ x=\frac{x'}{w'},y=\frac{y'}{w'} x=w′x′,y=w′y′, 变换矩阵是 [ a 11 a 12 a 13 a 21 a 22 a 23 a 31 a 32 a 33 ] \left[\begin{array}{lll}a_{11} & a_{12} & a_{13} \\ a_{21} & a_{22} & a_{23} \\ a_{31} & a_{32} & a_{33}\end{array}\right] ⎣⎡a11a21a31a12a22a32a13a23a33⎦⎤,可以拆分成4个部分, [ a 11 a 12 a 21 a 22 ] \left[\begin{array}{ll}a_{11} & a_{12} \\ a_{21} & a_{22}\end{array}\right] [a11a21a12a22]是线性变换,比如缩放,裁剪,旋转。 [ a 31 a 32 ] \left[\begin{array}{ll}a_{31} & a_{32}\end{array}\right] [a31a32]用于平移, [ a 13 a 23 ] T \left[\begin{array}{ll}a_{13} & a_{23}\end{array}\right]^{T} [a13a23]T产生透视变换。重写之前的变换公式可以得到:
x = x ′ w ′ = a 11 u + a 21 v + a 31 a 13 u + a 23 v + a 33 y = y ′ w ′ = a 12 u + a 22 v + a 32 a 13 u + a 23 v + a 33 \begin{aligned} &x=\frac{x^{\prime}}{w^{\prime}}=\frac{a_{11} u+a_{21} v+a_{31}}{a_{13} u+a_{23} v+a_{33}} \\ &y=\frac{y^{\prime}}{w^{\prime}}=\frac{a_{12} u+a_{22} v+a_{32}}{a_{13} u+a_{23} v+a_{33}} \end{aligned} x=w′x′=a13u+a23v+a33a11u+a21v+a31y=w′y′=a13u+a23v+a33a12u+a22v+a32
所以,已知变换对应的几个点就可以求取变换公式。反之,特定的变换公式也能新的变换后的图片。
再详细的数学理论这里就不介绍了,这里知道这点就够用, [ x ′ , y ′ , w ′ ] [x', y', w'] [x′,y′,w′]是变换后的坐标, [ u , v , w ] [u, v, w] [u,v,w]是变换前的坐标, a a a矩阵是 3 × 3 3\times3 3×3的矩阵。那这里就有个疑问了呀,我们图片每个像素点不是 ( x , y ) (x,y) (x,y)吗? 这怎么出现了3维了? 这是因为透视变换是从3维空间上进行的变换,但处理二维图形怎么办呢, 这里的 w w w默认是1, 所以对于图片里面的每个像素点,其坐标就成了这样 [ x , y , 1 ] [x, y, 1] [x,y,1], 这也就是为啥变换之后,得到的三维坐标点转二维的时候是 x = x ′ w ′ , y = y ′ w ′ x=\frac{x'}{w'},y=\frac{y'}{w'} x=w′x′,y=w′y′的原因。 后面OpenCV会帮助我们完成这个事情,所以不需要深究,只知道函数背后大致上干啥就行。 另外还有个问题,就是 a 33 a_{33} a33这也是恒等于1,我也不知道为啥, 那这样的话,这个 a a a矩阵我们需要求8个参数, 而根据上面这个方程来看, 如果我们知道一组输入坐标点 ( u , v ) (u,v) (u,v), 一组输出坐标点 ( x , y ) (x,y) (x,y),那么我们是能建立两个等式方程的。 但是我们有8个参数,需要的是8组这样的等式方程才可以解,所以我们需要四组输入坐标点,四组输出坐标点。
这样,就能把 a a a矩阵的各个参数给解出来,得到了 a a a,我们对于每个像素点,都能根据上面的公式进行透视变换得到在新平面下的坐标, 那么新图片就出来了。
这就是透视变换的原理, 那么我们这里该怎么用呢?
首先,根据上面的操作,我们已经得到矩形框的位置,其实这里面就是我们想要的东西了嘛,所以其实接下来就是针对这个矩形框里面的所有东西做透视变换。 而恰好,我们拿到了矩形框的四个顶点,正好四组坐标。
那么我们还需要透视后图片的四个顶点坐标,我们就能透视变换了,这个怎么得到呢? 透视后图片有一个顶点是知道的,就是左上角的[0,0],那么如果我们从原始的图片里面知道了矩形框的长和宽,我们其实就能得到四个顶点坐标。有了输入图片和输出图片的四组顶点坐标,通过调用OpenCV里面的cv2.getPerspectiveTransform(rect, dst),自动就给我们解8个方程组得到 a a a透视变换矩阵, 而有了这个矩阵,我们就能对框里面的每个像素做透视变换,得到最终的图片了。这里用的是cv2.warpPerspective(image, W, (maxWidth, maxHeight))。
整体思路介绍完了,我们下面看代码。 这里需要注意一个事情,接下来我们是要对原始的图片进行透视变换,为啥呢? 当然,我这里试过对resize后的那个图片做透视变换,但变换之后的结果及其不好,字不是很清晰。 我怀疑这里原因就是resize操作类似于一种压缩嘛,可能让图片变得模糊了,不如原图片效果好。 那么如果是用原图片,就要注意一个事情, 我们找到的那个矩形框的四个顶点坐标是基于resize后的图片找的,而这里如果要用原图,就必须找到这四个顶点坐标在原图中的坐标对应,这就是之前我们要记录缩放比例的原因。 操作如下:
# 下面需要做透视变换, 让整个框里面的对象铺满整个图片,其余的地方去掉
# 这个函数传入的是原始图片(resize之前的那个), resize之后的大轮廓坐标点乘以ratio,此时 轮廓坐标在resize之前图片里面的值
# 这里是这样的, resize操作之后,其实原始图片的每个点的坐标都相对于原来点的坐标变小了,于是乎需要乘以这个ratio,才是在原始图片里面的坐标
warped = four_point_transform(orig, screenCnt.reshape(4, 2)*ratio)
这里是原始图片,并且要拿到四个顶点坐标在resize之前原始图片里面坐标的真实位置。这里的核心是four_point_transform函数。
def four_point_transform(image, pts):
# 拿到正确的左上,右上, 右下,左下四个坐标点的位置
rect = order_points(pts)
(tl, tr, br, bl) = rect
# 计算输入的w和h值 这里就是宽度和高度,计算方式就是欧几里得距离,坐标对应位置相减平方和开根号
widthA = np.sqrt(((br[0] - bl[0]) ** 2) + ((br[1] - bl[1]) ** 2))
widthB = np.sqrt(((tr[0] - tl[0]) ** 2) + ((tr[1] - tl[1]) ** 2))
maxWidth = max(int(widthA), int(widthB))
heightA = np.sqrt(((tr[0] - br[0]) ** 2) + ((tr[1] - br[1]) ** 2))
heightB = np.sqrt(((tl[0] - bl[0]) ** 2) + ((tl[1] - bl[1]) ** 2))
maxHeight = max(int(heightA), int(heightB))
# 变换后对应坐标位置
dst = np.array([
[0, 0],
[maxWidth - 1, 0],
[maxWidth - 1, maxHeight - 1],
[0, maxHeight - 1]], dtype = "float32")
# 有了四组坐标,直接两个函数
W = cv2.getPerspectiveTransform(rect, dst) # 求透视变换矩阵
warped = cv2.warpPerspective(image, W, (maxWidth, maxHeight)) # 透视变换
# 返回变换后结果
return warped
这个函数里面第一个逻辑是,首先拿到矩形框左上,右上, 右下,左下四个点的具体坐标,注意下,我们传进去的是这四个点的坐标,但是究竟哪个对应哪个位置,这个不一定。并不是严格这么对应的,但后面我们需要这样的严格顺序,所以需要先进行这个操作。这里使用的方式很巧妙呀:
def order_points(pts):
# 一共4个坐标点
rect = np.zeros((4, 2), dtype="float32")
# 下面这个操作,是因为这四个点目前是乱序的,下面通过了一种巧妙的方式来找到对应位置
# 左上和右下, 对于左上的这个点,(x,y)坐标和会最小, 对于右下这个点,(x,y)坐标和会最大,所以坐标求和,然后找最小和最大位置就是了
# 按照顺序找到对应坐标0123分别是左上, 右上, 右下,左下
s = pts.sum(axis=1)
# 拿到左上和右下
rect[0] = pts[np.argmin(s)]
rect[2] = pts[np.argmax(s)]
# 右上和左下, 对于右上这个点,(x,y)坐标差会最小,因为x很大,y很小, 而左下这个点, x很小,y很大,所以坐标差会很大
# 拿到右上和左下
diff = np.diff(pts, axis=1)
rect[1] = pts[np.argmin(diff)]
rect[3] = pts[np.argmax(diff)]
return rect
这里加了注释了,就不再解释。 拿到这四个坐标点位置,并且按照左上,右上,右下,左下的顺序排列好之后, 原始输入图片四个坐标点就成了。 接下来就是计算这个框的宽度和高度。 有人可能说,为啥不直接通过轮廓检测时候的,矩形框函数获得呢? 首先,这里轮廓检测拿到最大框的时候,首先矩形不一定规整做过近似,另外是我们只保留了顶点信息,是无法拿到长宽的,所以这里用了坐标距离公式运算了下,就能知道长宽,这样就能得到新图片中的四个坐标点。 接下来的透视变换操作,就可以直接OpenCV来完成啦。效果如下:

当然这个并没有显示全哈,这个是原始图片做的透视变换,会发现自己非常清晰,且铺满了整个图片。 为了看清楚透视变换的功效,下面我用resize之后的图片进行了下。
warped = four_point_transform(image, screenCnt.reshape(4, 2))
如果是resize的那张图片,这里就不能乘以ratio了。对比结果:

透视变换可以让小票铺满整个图片,但这个图字迹清晰度不行,所以这里用的原始图片。
接下来,对透视变换的图片二值化处理:
# 二值处理
warped = cv2.cvtColor(warped, cv2.COLOR_BGR2GRAY)
ref = cv2.threshold(warped, 150, 255, cv2.THRESH_BINARY)[1]
效果如下:

这里由于图片是横着的,我下面想让他正过来。这里就又探索了一波OpenCV进行图像旋转, 这工具包太强大了。 上面图像需要顺时针旋转90度,可以这么操作:
rows, cols = ref.shape[:2]
center = (cols/2, rows/2) # 以图像中心为旋转中心
angle = 90 # 顺时针旋转90°
scale = 1 # 等比例旋转,即旋转后尺度不变
M = cv2.getRotationMatrix2D(center, angle, scale) # 这里得到了一个旋转矩阵
rotated_img = cv2.warpAffine(ref, M, (cols, rows))
# 图太大,我这里又resize了下
resize_img = resize(rotated_img, height=600)
这里其实也是做透视变换, 先得到旋转矩阵,然后进行旋转。

这样就清晰了很多了。这个也就是我们进行ocr识别的最终图片了。
4. OCR识别
OCR识别这部分就是借助第三方库了,叫做pytesseract,直接说这个东西怎么用吧, 首先需要先安装tesseract软件。普通的软件安装方法, 安装包放到了GitHub项目中。安装完了之后,配置环境变量
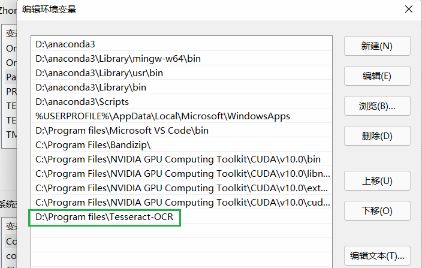
注意两点,第一点是用户变量和系统变量的path里面都配置一下,第二点是切记手敲, 不要用路径的粘贴复制。

这样直接复制过去,配置不成功, 我这里踩过坑的。
其次,还需要新建一个环境变量叫
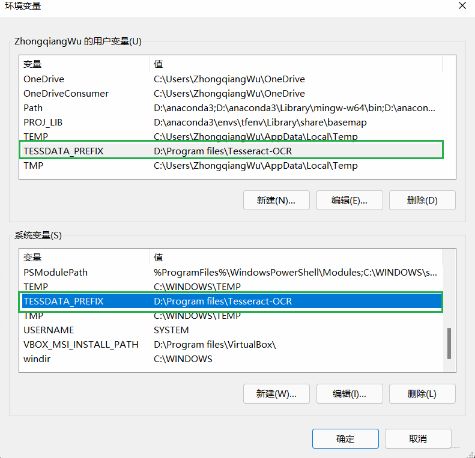
也是手敲,不要复制。
接下来, 在anaconda环境中,安装pytesseract包, 这个就直接pip install即可。
pip install pytesseract
然后, 在anaconda下面找到这个包的.py文件。 我的在anaconda3/envs/tfenv/Lib/site-packages/pytesseract/,由于我这里用的虚拟环境tfenv,不同虚拟环境下不一样,但后面的Lib及后面是一样的,在这里面修改一行代码:

这里对应安装的tesseract.exe。道理很简单,我们是想从python里面调用这个库进行ocr识别,但其实这背后调用的还是tesseract.exe这个应用程序。 所以我们就需要在这里指定下这个应用程序的位置。
准备工作做好,接下来,就是读入图片,一键识别了。
image = cv2.imread('images/scan.jpg')
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# 滤波或者二值化下,使得图片更加清楚
preprocess = 'thresh'
if preprocess == "thresh":
gray = cv2.threshold(gray, 0, 255,cv2.THRESH_BINARY | cv2.THRESH_OTSU)[1]
if preprocess == "blur":
gray = cv2.medianBlur(gray, 3)
filename = "{}.png".format(os.getpid())
cv2.imwrite(filename, gray)
text = pytesseract.image_to_string(img)
这个text里面的就是识别出的文字信息啦。
5. 小总
这里简单总结下,这个项目的核心操作我觉得是文档图片预处理,而这里面的核心就是图像的透视变换操作, 前面的边缘检测, 轮廓检测这些OpenCV里面都有现成的函数,虽然透视变换也有,但是背后的原理还是需要有一些了解的,因为后面处理图片的情景可能更复杂, 但这个操作是真的骚气。 在图像配准里面这也是基础操作,很多情况下都可以用到。至于后面的ocr识别,其实不是重点,轮子有现成的,到时候调就行了。 当然,ocr的这个工具包,目前这个只支持英文, 如果想支持中文,需要去网站看一些配置。 不过这里只是演示demo, 这一块又不是重点,所以到了后面真实有需求的话,我再去探索。
本次项目代码地址https://github.com/zhongqiangwu960812/OpenCVLearning, 感兴趣的可以玩一下啦。