2019-BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
文章目录
- 1. Title
- 2. Summary
- 3. Problem Statement
- 4. Method(s)
-
- 4.1 BERT
-
- 4.1.1 Model Architecture
- 4.1.2 Input/Output Representations
- 4.2 Pre-Training BERT
-
- 4.2.1 Masked Language Model (MLM)
- 4.2.2 Next Sentence Prediction (NSP)
- 4.3 Fine-tuning BERT
- 5. Evaluation
- 6. Conclusion
1. Title
文章链接:BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
2. Summary
BERT模型相较于Transformer来说,在模型结构上改动不大,主要在于其采用了额外的无监督预训练任务,去捕获了双向的上下文信息,同时对输入输出也进行了改造,使得其能够适用于多种NLP任务。
通过一个预训练的BERT模型,只需要再进行简单微调,即可高质量地完成大部分NLP任务。
其采用的『CLS』Token也成为了后续Vision Transformer用于图像分类任务的基础。
3. Problem Statement
之前的语言表示模型通常只考虑到了左侧的上下文关系,也就是说当前的预测结果只与之前的输入信息有关,这对于很多语言任务来说,显然是不够充分的。
不同于之前的语言表示模型,BERT通过基于无标签文本的预训练,同时考虑左侧和右侧的上下文信息,以得到一个双向特征,随后经过预训练的BERT模型仅需要额外加入一个输出层,即可应用于大量语言任务,并且取得SOTA。
4. Method(s)
目前主要有两种将预训练的语言表示模型应用于下游任务的方法:
- feature-based
使用某个任务特定的模型结构,预训练特征作为额外的输入送入该模型中,以完成特定任务。 - fine-tuning
尽可能少地引入特定任务相关的参数,将基于下游任务进行所有参数的fine-tuning。
但目前这两种方式都只使用了left-to-right的上下文信息,或者是将left-to-right和right-to-left的上下文信息进行拼接,没能混合两个方向的上下文信息同时进行学习。
为了提升基于Fine-Tuning的方法,本文提出了BERT: Bidirectional Encoder Representations from Transformers。
- BERT通过使用一个“Masked Language Model”(MLM)预训练方法,缓解了之前模型中对于双向信息的缺失。
- 除此之外,BERT还引入了一个“Next Sentence Prediction”的任务,该任务可用于同时对Text-Pari Presentation的训练,从而使得BERT尽可能地适用于大部分NLP任务。
4.1 BERT
BERT总共包含两个步骤:
- Pre-training
模型将基于不同的预训练任务,使用没有标签的数据进行预训练。 - Fine-tuning
BERT模型首先使用预训练参数进行初始化,然后基于特定下游数据集以及任务进行微调,每个特定任务具有各自的微调模型。但不同任务中,BERT模型具有统一的结构,仅在输出等部分存在微小的不同。

4.1.1 Model Architecture
BERT模型就是经典的Transformer结构,根据不同的参数,得到两个模型 B E R T B A S E BERT_{BASE} BERTBASE、 B E R T L A R G E BERT_{LARGE} BERTLARGE,其中BASE模型的大小与OpenAI GPT相当。
4.1.2 Input/Output Representations
为了使得BERT能够处理多种下游任务,BERT的输入的一个序列能够表示一个单独的句子或是一对句子例如<问题,答案>。因此,BERT的“sentence”可以是一个句子,也可能是打包在一起的两个句子。
除此之外,考虑到很多任务中需要进行分类,因此,每个Sequence的第一个token都是一个特殊的分类token『CLS』,这个token的最终输出的hidden state vector将用于分类任务。
打包在一起的两个句子sentence A和sentence B主要通过以下两种方法进行区分:
- 使用一个特殊的token『SEP』将两个句子进行分割
- 为每个token添加一个可学习的embeddings,用于指示其属于A还是B
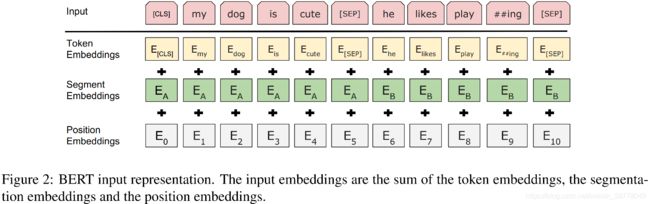
对于每个token,其对应的BERT的input有三个来源:token,segment和position embeddings,这三个embeddings求和,即为该token对应的representation,具体见下图:
4.2 Pre-Training BERT
4.2.1 Masked Language Model (MLM)
按照一定百分比,随机mask某些input tokens,并且预测这些masked tokens=>Masked LM。
这些masked tokens对应的final hidden vectors会被送入一个softmax层,用于对masked token的进行分类。
在预训练时,这些masked token会被替换为一个『MASK』token,但是这个token在微调时并不存在,由此会引入预训练和微调之间的不匹配,为了解决这个问题,对于这些masked tokens,不是所有情况下都会被替换为『MASK』token,而是在80%的情况下替换为『MASK』,10%替换为任意的token,10%则不发生替换。
4.2.2 Next Sentence Prediction (NSP)
很多下游任务例如问题回答、自然语言推理等,都是基于两个句子之间的关系而得到的,而这种关系是无法直接通过语言建模来得到。
因此,BERT还预训练了一个二分类的next sentence prediction任务。对于送入BERT的sentence A和sentence B,其中B有50%的概率是A的下一句,50%的概率是来自语料库的随机的一个句子,BERT的输出C将用于分类。
4.3 Fine-tuning BERT
基于不同下游任务,送入不同的sentence A和sentence B,『CLS』特征将送入一个输出层,用于调整输出的维数,以完成特定的分类任务。
5. Evaluation
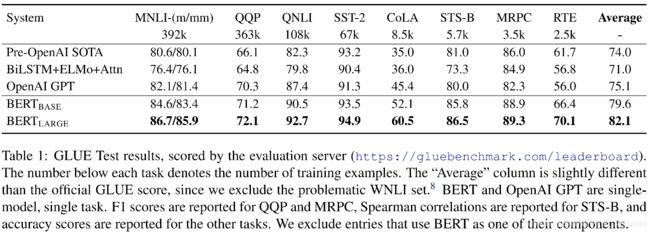
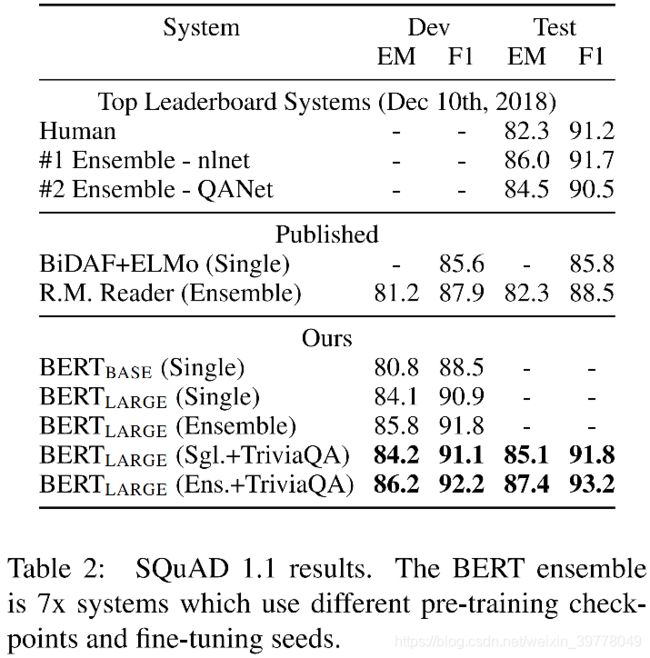
BERT通过一个模型架构进行微调,在多个NLP任务上均取得了当时最好的结果。


6. Conclusion
通过引入双向信息,BERT可以使用同一个预训练模型在多个NLP任务上均取得优异的成绩,使得其成为了NLP领域最流行的模型。