论文阅读|XFormer
Lightweight Vision Transformer with Cross Feature Attention
Abstract
卷积神经网络 (CNN) 利用空间归纳偏差来学习视觉表示,但这些网络是空间局部的。 ViT 可以通过其自注意力机制来学习全局表示,但它们通常过大,不适合移动设备。在本文中,我们提出了交叉特征注意 cross feature attention (XFA) 以降低Transformer的计算成本,并结合高效的轻量 CNN 形成一种新颖的高效轻量级的CNN-ViT 混合模型 XFormer,可用作通用backbone学习全局和局部表示。实验结果表明,XFormer 在不同的任务和数据集上优于许多基于 CNN 和 ViT 的模型。在 ImageNet-1K 数据集上,XFormer 以 550 万个参数实现了 78.5% 的 top-1 准确率,在相似数量的参数下,比 EfficientNet-B0(基于 CNN)和 DeiT(基于 ViT)的准确率分别提高了 2.2% 和 6.3% 。我们的模型在转移到对象检测和语义分割任务时也表现良好。在 MS COCO 数据集上,XFormer 在 YOLOv3 框架中超过 MobileNetV2 10.5 AP(22.7 → 33.2 AP),只有 6.3M 参数和 3.8G FLOPs。在 Cityscapes 数据集上,只有一个简单的all-MLP 解码器,XFormer 实现了 78.5 的 mIoU 和 15.3 的 FPS,超过了最先进的轻量级分割网络。
Introduction
由于卷积神经网络(CNN)和大规模GPU计算的出现,现代计算机视觉在深度学习方面取得了巨大成功。 CNN 专注于处理空间局部信息以学习视觉表示,并已成为许多视觉任务的标准方法。 视觉转换器 (ViTs) 最近成为表示学习的替代方案,并已证明其在各种视觉识别任务中的普遍性能,例如图像分类 [17、51、38]、语义分割 [64、48、58、59 ] 和目标检测 [21, 35]。 ViT 将图像视为一系列的patches,并将它们拆分为image tokens,以使用自我注意对它们的远程交互进行建模。 与 CNN 相比,ViT 具有全局处理能力的优势,并且随着数据集大小的进一步增长而表现出出色的可扩展性,例如 JFT-300M [49]。
然而,在轻量级和移动网络的体系中,MobileNets [28, 46, 27] 和 EfficientNets [50] 仍然优于 ViTs。 例如,在 600 万的参数预算下,DeiT 在 ImageNet 分类任务上的准确率比 MobileNetV3低 3%,并且具有 6 倍以上的 FLOPs。 轻量级CNN已作为许多移动视觉任务的通用主干,而当前大多数基于 ViT 的模型都是重量级的,难以优化和缩小规模,下游任务需要昂贵的解码器。 最近的工作 [SegFormer, LVT] 已经证明了为特定任务(如语义分割)设计轻量级 ViT 模型的可能性,但基于 ViT 的模型远没有被认为是移动设备的实用选择。 因此,设计一个能够很好地泛化不同任务的高效、轻量级的 ViT 模型至关重要。
已经提出了几种方法 [MobileFormer,MobileViT,ReFormer] 来改进 ViT。 一个简单的想法是通过在早期阶段使用卷积或将卷积交织到每个transformer块中来组合卷积层和transformer。 这些方法 [MobileViT,MobileFormer] 旨在通过引入空间局部偏差来降低计算成本并使优化更容易。 另一种方法是优化transformer中的自注意力操作。 原来的self attention对于token数量的计算复杂度是二次方的,这给下游任务的转移造成了巨大的瓶颈。 以前的工作采用分解[9]、低秩近似[LinFormer]或散列[ReFormer]等方法来降低复杂性,但通常的trade-off 是显着的下降。
在本文中,我们首先通过提出一种新颖的交叉特征注意cross feature attention(XFA)模块来解决transformer的效率瓶颈。 XFA 不是通过token维度执行矩阵乘法,而是通过构建中间上下文和特征分数来通过特征维度处理注意力,这只会产生线性复杂度。 在XFA中,我们还消除了softmax操作并将其替换为可学习的参数,以动态调整不同transformer层的缩放因子。 然后,我们基于XFA提出了一种新的轻量级CNN-ViT混合模型 XFormer,它由XFA transformer block和高效CNN块组成,它利用了来自CNN的空间局部归纳偏置和来自transformer的全局信息。
我们的方法在三个标准的视觉识别任务上取得了稳定的表现。 在 ImageNet-1K 数据集上,XFormer 在1.7G FLOP 时产生 78.5% 的 top-1 分类准确率,明显优于 MobileNetV3和 MobileFormer。 我们进一步证明了我们的模型作为可靠骨干网络的普遍性。 在 MS COCO 数据集上,带有 XFormer 的 YOLOv3 将最先进的 CenterNet 的检测结果提高了 7.9 AP(25.3 → 33.2 AP),参数减少了 56%,FLOP 减少了 22%。 在 Cityscapes 数据集上,XFormer 在 SegFormer框架中的性能超过MobileViT 2.9 mIoU (75.6 → 78.5 mIoU),同时降低了计算成本。
Contributions
- 我们提出了一种新的自我注意方法,cross feature attention(XFA),它对特征维度进行操作,并产生关于token数的线性复杂度
- 基于我们提出的 XFA 模块,我们提出了一种新的轻量级CNN-ViT混合模型,称为XFormer,并验证了其在各种视觉数据集上的优越性
Method
标准VIT模型首先使用大小为h×w的patch将输入的X∈R(H×W×C)reshape为一系列平坦的patches X(F)∈R(N×PC),其中P=HW,N=HW/P表示token数目。然后将X(F)投影到固定的D维空间X(D)∈R(N×D),并使用一系列的transformer块来学习patch间表示。由于VITS忽略了空间感应偏向,通常需要更多的参数来学习视觉信息。此外,transformer中昂贵的自我注意计算导致了优化这类模型的瓶颈。
在本节中,我们提出了XFormer,这是我们高效、轻量级的 CNN-ViT 框架,以解决 ViT 中的上述问题。 我们首先介绍一种提高自注意力效率的新方法,然后说明我们新的 CNN-ViT 混合模型的架构设计。
3.1 Cross Feature Attention (XFA)
Attention Overview.
transformer的主要计算瓶颈之一在于self-attention层。在最初的自我注意过程中,X(D)首先被用来通过线性投影产生Q、K和V。它们都具有相同的维度N×D,其中N是图像token的数目,D的每个token的维度,然后计算注意分数为:
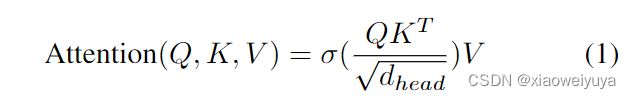
 是softmax操作,dhead代表头的维度。计算注意分数的计算复杂度为
是softmax操作,dhead代表头的维度。计算注意分数的计算复杂度为![]() 。自我注意的二次型复杂性导致了巨大的计算瓶颈,这使得VIT模型很难在移动设备上进行缩减。
。自我注意的二次型复杂性导致了巨大的计算瓶颈,这使得VIT模型很难在移动设备上进行缩减。
Efficient Attention.
为了解决自我注意中的二次复杂性问题,我们提出了一种新的注意模块结构,称为交叉特征注意(XFA)。参考XCiT,我们首先沿特征维度D对Q和K应用 L2 归一化:
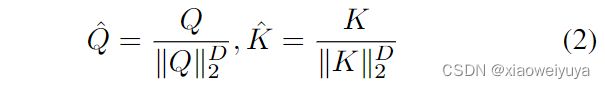
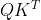 在原始的自我注意中的直觉是定位应该注意的重要image patches。但是直接计算会造成不必要的冗余和计算开销。相反,我们为K构造了两个中间分数:查询上下文分数 query context scores
在原始的自我注意中的直觉是定位应该注意的重要image patches。但是直接计算会造成不必要的冗余和计算开销。相反,我们为K构造了两个中间分数:查询上下文分数 query context scores ![]() 和查询要素分数 query feature scores
和查询要素分数 query feature scores ![]() 。使用两个卷积核矩阵
。使用两个卷积核矩阵![]() 和
和![]() 沿token的维度N来结算
沿token的维度N来结算![]() ,沿特征维度D来计算
,沿特征维度D来计算![]() 。在卷积滤波器的帮助下,我们的中间分数向量可以代表更紧凑的表示来计算注意图,同时也降低了计算成本。
。在卷积滤波器的帮助下,我们的中间分数向量可以代表更紧凑的表示来计算注意图,同时也降低了计算成本。![]() 和
和![]() 表示为:
表示为:

最后,将交叉功能注意(XFA)定义为:

λ是一个温度参数,用于动态调整不同transformer层中的比例因数,从而实现更高的训练稳定性。 注意到归一化将关注值限制在一定范围内,因此我们放弃了冗余且昂贵的Softmax操作。与原有的具有二次复杂度的自我注意不同,该模块将计算量从![]() 降低到
降低到![]() ,后者仅随N线性扩展。
,后者仅随N线性扩展。
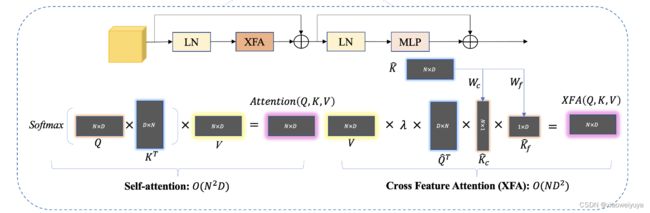
Comparison with Self-attention.
我们提出的 XFA 模块与原始注意力的主要区别在于:
- XFA 通过构建中间查询上下文和特征分数,沿着特征维度 D 计算注意力图,这大大降低了计算成本;
- XFA 使用可学习的温度缩放参数来调整归一化,并且不受 softmax 操作的影响。
我们的方法为二次复杂度问题提供了解决方案,并且对于资源受限的设备更有效且对移动设备更友好。
3.2 Building XFormer
MobileNetV3 Block.


XF Block.

Patch Size Choice.

XFormer.

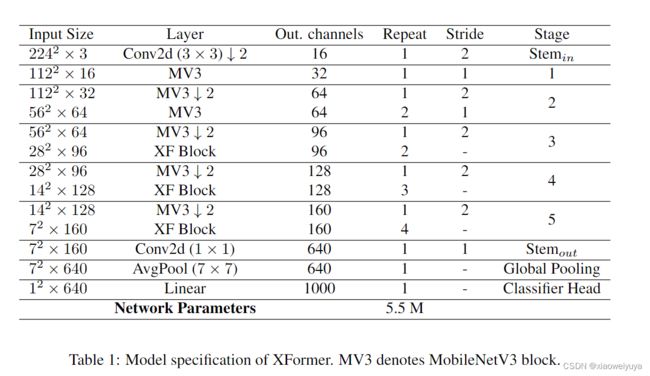


Model efficiency.
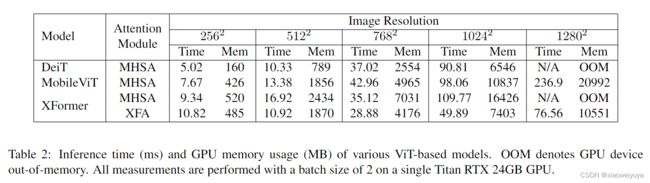
我们模型的总参数大小只有 550 万。 与类似大小的基于 ViT 的模型相比,我们的模型可以更有效地处理高分辨率图像并避免潜在的内存瓶颈(见表 2)。 例如,当输入分辨率为 1024 × 1024 时,与使用原始自注意力的 MobileViT 相比,XFormer 的推理速度提高了近 2 倍,GPU 内存使用量减少了 32%。 我们的模型可以轻松处理高分辨率吞吐量,而不会出现内存瓶颈。 最重要的是,XFormer 提供了更好的准确度(参见表 3),在模型大小和性能之间实现了很好的平衡。
4.Experiments
4.1 Image Classification
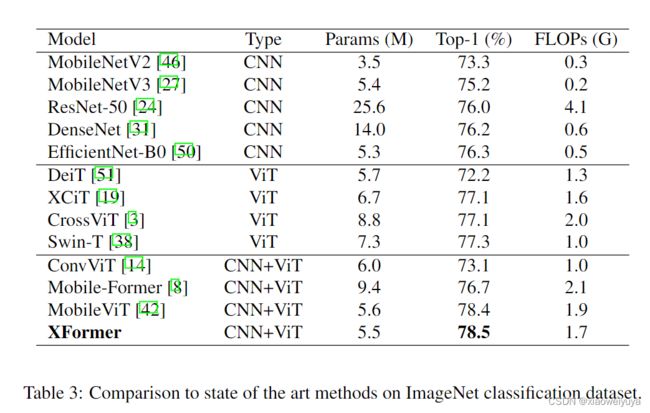
表 3 显示 XFormer 在不同模型大小上优于其他基于 CNN 的轻量级模型。 XFormer 将 MobileNetV2 提高了 5.2%,MobileNetV3 提高了 3.3%,EfficientNet-B0 提高了 2.2%。 与重量级 CNN 模型相比,我们的模型比 ResNet-50 [24] 和 DenseNet [31] 产生更好的 top-1 精度,而且参数少得多。
与在 ImageNet-1K 数据集上从头开始训练的 ViT 变体相比,XFormer 在相似或更少的参数上提供比 DeiT (+6.3%)、ConvViT (+5.4%) 和 CrossViT (+1.4%) 更好的性能。 我们的模型还优于两个最先进的轻量级 CNN-ViT 混合模型 MobileFormer 和 MobileViT,具有更少的 FLOPS 和参数。 这表明我们提出的 XFormer 能够有效地学习表示。
4.2 Object Detection
我们在 ImageNet-1K 数据集上预训练编码器并随机初始化检测器。 我们选择 YOLOv3 [44] 作为我们的检测器网络,广泛用于移动设备。 我们使用随机裁剪、调整大小、随机翻转和光度失真来增强数据。 我们使用 SGD 优化器来训练模型 300 个 epoch,初始学习率为 0.0001,并在第 24 和 28 个 epoch 期间使用线性步进 scheduler 。 权重衰减为0.0005,最大梯度范数设置为35。在推理过程中,我们采用320×320尺度的多尺度翻转增强测试。 我们使用平均精度 (mAP) 指标和推理速度 (FPS) 报告对象检测性能。
 表 4 显示在 YOLOv3 框架内,XFormer 始终优于以前的移动对象检测方法。 YOLOv3 的性能比 MobileNetV2 基线大幅提高了 46% (22.7 → 33.2 AP),并且比最先进的检测模型更准确,例如 CenterNet [18] (+7.9 AP)、YOLOX [22] ( +4.7 AP),同时保持相对轻量级(6.4M 参数,3.8G FLOPs)。 在推理速度方面,尤其是对于高分辨率输入,XFormer 的计算速度快于基于 ViT 的检测网络,例如 YOLOS [21] (+17 FPS) 和 MobileViT [42] (+3 FPS),这表明我们的方法确实是得益于我们的 XFA 模块,计算效率更高。 这表明我们提出的 XFormer 模型可以为目标检测任务学习有效的表示。 定性结果见图 2。
表 4 显示在 YOLOv3 框架内,XFormer 始终优于以前的移动对象检测方法。 YOLOv3 的性能比 MobileNetV2 基线大幅提高了 46% (22.7 → 33.2 AP),并且比最先进的检测模型更准确,例如 CenterNet [18] (+7.9 AP)、YOLOX [22] ( +4.7 AP),同时保持相对轻量级(6.4M 参数,3.8G FLOPs)。 在推理速度方面,尤其是对于高分辨率输入,XFormer 的计算速度快于基于 ViT 的检测网络,例如 YOLOS [21] (+17 FPS) 和 MobileViT [42] (+3 FPS),这表明我们的方法确实是得益于我们的 XFA 模块,计算效率更高。 这表明我们提出的 XFormer 模型可以为目标检测任务学习有效的表示。 定性结果见图 2。
4.3 Semantic Segmentation
 表 5 显示 XFormer 在 Cityscapes 数据集上取得了与用于语义分割的最先进的移动方法相媲美的结果。 与基于 CNN 的模型相比,我们的方法提供了比 MobileNetV2 更好的性能,而无需大量解码器。 此外,XFormer 通过 MobileViT 将 SegFormer 提高了 3.8%(75.6 → 78.5 mIoU),并且优于最先进的轻量级 LVT [59](+3.6 mIoU)和 SegFormer [58](+2.0 mIoU)。 最重要的是,XFormer 比以前的 ViT 主干实现了更快的推理速度,验证了我们的模型在处理高分辨率输入方面的效率。 这表明我们提出的 XFormer 模型可以作为语义分割任务的有效骨干。 定性结果见图 3。
表 5 显示 XFormer 在 Cityscapes 数据集上取得了与用于语义分割的最先进的移动方法相媲美的结果。 与基于 CNN 的模型相比,我们的方法提供了比 MobileNetV2 更好的性能,而无需大量解码器。 此外,XFormer 通过 MobileViT 将 SegFormer 提高了 3.8%(75.6 → 78.5 mIoU),并且优于最先进的轻量级 LVT [59](+3.6 mIoU)和 SegFormer [58](+2.0 mIoU)。 最重要的是,XFormer 比以前的 ViT 主干实现了更快的推理速度,验证了我们的模型在处理高分辨率输入方面的效率。 这表明我们提出的 XFormer 模型可以作为语义分割任务的有效骨干。 定性结果见图 3。
5 Conclusion and Future Work
在本文中,我们提出了交叉特征注意力(XFA),它通过特征维度处理注意力来降低transformer的计算成本,并且只产生线性复杂度。 我们还提出了 XFormer,一种轻量级 CNN-ViT 混合模型,建立在交叉特征注意 (XFA) 转换器和高效 CNN 块的基础上。 它利用了高效卷积层的局部处理能力和轻量级转换器的全局编码能力。 在各种数据集和任务上的实验结果证明,我们的高效设计不仅可以提高性能相对于以前的方法,而且可以保持低计算成本和高效率。 在我们未来的工作中,我们计划探索其他方法,例如 NAS [7],以继续在 FLOP 和推理速度方面优化我们的模型。 自监督预训练是另一个研究方向,以帮助我们的模型更好地泛化到看不见的数据集上。