卷积操作的过程、参数说明、用CNN实现分类任务的代码
* 因为自己初学时候混淆过CNN中图像尺寸变化与通道数变化,本文从理论=>使用,根据自己遇到的问题对相关概念作出说明
卷积-相关理论
笼统地说,卷积操作是通过滤波器对原图像进行特征提取的过程
其中涉及卷积核(kernel),步长(stride),填充(padding)等概念
最简例子
初次接触CNN时一般采用如下的例子来理解卷积操作的核心内容(即滤波器在图像上作用的过程)
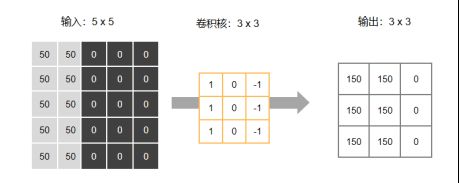
假设现在有一张像素为5x5的图像与一个卷积核为3x3的滤波器,并且我们先考虑stride = 1;padding = 0的情况

【第一步】:将滤波器”放到”图像左上角,将对应位置的值相乘后得到3x3的矩阵,再对矩阵内所有元素求和,得到第一个值【150】
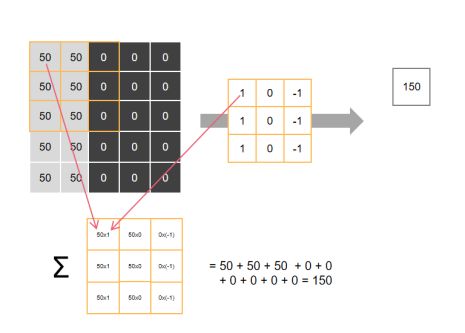
注:具体计算规则可以变化,此处相乘求和为常见处理方式
* 若先进行填充处理,如padding = 1,padding_mode = ‘zeros’,则如下图所示,从padding后图像的左上角处开始操作:
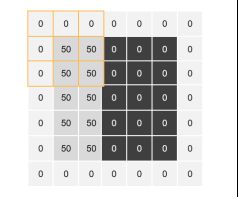
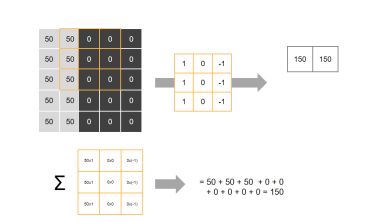
由于stride = 1,【第二步】我们将滤波器向右边移动一格,进行计算,得到第二个值【150】
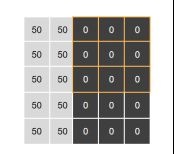
* 若stride = 2,则第二步为移动两格至下图再进行计算
【后续的步骤】以此规则依次移动、计算
注意,滤波器在横向执行完一行后,根据设置的stride值向下移动,本例stride = 1,向下移动1格继续进行操作(若stride = 2则向下移动2格)
处理完整张图像后得到3x3的矩阵
多通道情况
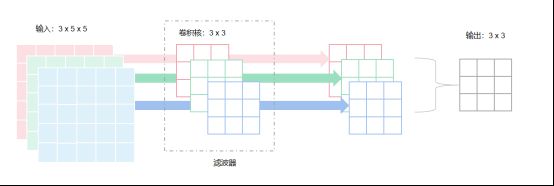
当输入的图片为多通道时,一个滤波器内将含有多个卷积核
例如:当输入图片为彩色图片时,包含RGB三个通道,为了对每个通道进行处理,滤波器内将含有3个3x3的卷积核,每个卷积核分别在对应通道上进行操作,从而得到3个3x3的矩阵,最终将3个矩阵进行叠加(加和),得到1个3x3的矩阵作为该滤波器特征提取的结果
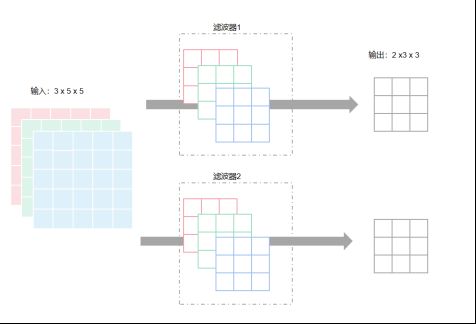
当我们需要从不同维度上进行特征提取时,我们可以增加滤波器的数量
例如我们使用两个滤波器,每个滤波器包含3个3x3的卷积核,最终可以得到2个3x3的矩阵,每个代表对原图像在某一维度上的特征提取结果
pytorch中nn.Conv2d主要参数说明
input_channels:输入通道数
output_channel:输出通道数
kernel_size:卷积核尺寸
stride:步长,滤波器每一步操作间隔的尺寸
padding:填充,当padding = 0时,不做填充处理,当padding = 1时,为图像在周围一圈进行尺寸为1的填充,图像从5x5变为7x7
* 以前学习最简例子时,我并未建立对通道的正确理解,混淆了输入通道&输出通道和输入图像&输出结果的概念;实际上通道的数量变化 与 图像->特征的尺寸变化是两回事
输入通道数(input_channels)取决于输入数据的通道数,且它决定了单个滤波器中卷积核的数量
输出通道数(output_channels)取决于我们想要从多少个维度提取特征,决定了滤波器的个数
输入图像的维度、填充、步长、卷积核尺寸共同决定了输出结果的维度,且有公式

注:实际使用中当计算结果为非整数时,将向下取整(即滤波器对图像进行处理时,直接忽略原图像的最下行与最右列)
卷积-使用
此处我们用mnist中的手写数字数据,用pytorch构建最简单的基于卷积神经网络的分类器
* 所有代码按顺序逐段贴入jupyter/colab可以直接运行
导入需要的包
import torch
from torch.utils.data import DataLoader
from torchvision.datasets import MNIST
from torch import nn
from torchvision import transforms用Dataloader加载mnist数据集
batch_size = 128
dataloader = DataLoader(
MNIST('.', download=True, transform=transforms.ToTensor()),
batch_size=batch_size,
shuffle=True)
device = 'cuda' # 也可以设置为'cpu'读取单条数据查看数据格式
# 图片的尺寸为[1,28,28];图片的label为数字
# 查看图像
import matplotlib.pyplot as plt
test_imgage = dataloader.dataset.__getitem__(0)[0].detach()
test_label = dataloader.dataset.__getitem__(0)[1]
print('image shape: ',test_imgage.shape,' label: ',test_label)
plt.imshow(test_imgage.squeeze())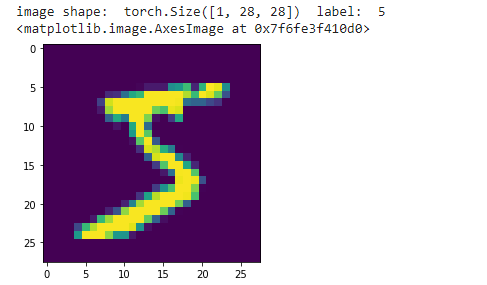
构建基于CNN的分类器
(此处为了方便展示只用了一个CNN层、一个线性层)
class CNN_classifier(nn.Module):
def __init__(self):
super(CNN_classifier, self).__init__()
# 由于使用的图像通道数为1,故设置输入通道数为1
# 定义输出通道数为3,卷积核尺寸为4,步长为2
self.CNN_layer = nn.Conv2d(1, 3, kernel_size = 4, stride = 2)
self.Linear_layer = nn.Linear(3*13*13, 10)
self.activation = nn.ReLU()
def forward(self, input_img):
CNN_result = self.CNN_layer(input_img)
# CNN输出结果为3维数据,此处需将其展平才能放入线性层
CNN_result_reshape = CNN_result.reshape(-1,3*13*13)
Linear_result = self.Linear_layer(CNN_result_reshape)
activated_result = self.activation(Linear_result)
return activated_result构建实例、定义损失函数、定义优化器
import torch.optim as optim
classifier = CNN_classifier()
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(classifier.parameters(), lr=0.00001)进行五个epoch的训练
# 进行五个epoch的循环
for epoch in range(5):
steps = 0
for image, label in dataloader:
optimizer.zero_grad()
# 由于原数据的label为数字0~9,在多分类任务上我们需要转成热编码
one_hot_label = torch.nn.functional.one_hot(label,10)*1.0
pred = classifier(image)
batch_loss = criterion(pred, one_hot_label)
# 每隔50个batch输出一次当前batch的loss
if steps % 50 == 0:
print('current epoch:', epoch,'current step: ',steps,'current batch loss: ',batch_loss)
batch_loss.backward()
optimizer.step()
batch_loss = 0
steps+=1
tips:对模型的输入、输出进行测试或debug时,可以在class外单独建立test_layer,用随机数据作为输入来测试维度变化是否正确
例如此处建立一个CNN层来测试数据经过该层前后的维度变化
test_input = torch.randn(1,28,28)
test_CNN_layer = nn.Conv2d(1, 3, kernel_size = 4, stride = 2)
test_result = test_CNN_layer(test_input)
print('size of input data: ',test_input.shape,' size after CNN layer: ',test_result.shape)![]()