ROS学习笔记17: ROS语音交互功能
ROS语音交互功能
- 一、科大讯飞开放平台sdk下载
- 二、语音转文字操作
-
- 1.编译SDK例程
- 2.运行语音转文字例程
- 三、文字转语音操作
- 四、ROS语音输入功能
-
- 1.任务介绍
- 2.创建工作空间
- 3.修改cpp功能文件
- 4.配置CMakeLists.txt文件
- 5.运行语音转文字
- 五、ROS文字转语音输出功能
-
- 1.任务介绍
- 2.创建工作空间
- 3.修改tts_subscribe.cpp
- 4.配置CMakeLists.txt文件
- 六、ROS同时实现语音输入和文字转语音输出
-
- 1.任务介绍
- 2.建立launch启动文件
- 七、ROS实现语音交互功能
-
- 1.任务介绍
- 2.修改CPP文件
- 3.修改配置文件
- 4.创建launch启动文件
一、科大讯飞开放平台sdk下载
到科大讯飞开放平台下载语音交互的功能包



二、语音转文字操作
1.编译SDK例程
在samples/iat_online_record_sample文件夹下执行编译命令编译source 64bit_make.sh ,如果出现以下报错:
linuxrec.c:12:28: fatal error: alsa/asoundlib.h: No such file or directory
#include 则执行如下命令安装:sudo apt-get install libasound2-dev,再次进行编译会出现如下警告,不必理会。
gcc -c -g -Wall -I../../include linuxrec.c -o linuxrec.o
linuxrec.c:529:12: warning: ‘list_pcm’ defined but not used [-Wunused-function]
static int list_pcm(snd_pcm_stream_t stream, char**name_out,
^
gcc -c -g -Wall -I../../include speech_recognizer.c -o speech_recognizer.o
gcc -c -g -Wall -I../../include iat_online_record_sample.c -o iat_online_record_sample.o
gcc -g -Wall -I../../include linuxrec.o speech_recognizer.o iat_online_record_sample.o -o ../../bin/iat_online_record_sample -L../../libs/x64 -lmsc -lrt -ldl -lpthread -lasound -lstdc++
2.运行语音转文字例程
在bin文件夹下会生成一个iat_online_record_sample,我们运行./iat_online_record_sample看看这个例程。
运行例程时会报错如下:
./iat_online_record_sample: error while loading shared libraries: libmsc.so: cannot open shared object file: No such file or directory
解决方法是把libmsc.so文件复制到usr/lib文件夹下:
sudo cp libs/x64/libmsc.so /usr/lib/
sudo ldconfig
复制完后重新运行./iat_online_record_sample会有两步配置,第一是是否上传用户自定义的字符库,这里选择no,第二个选项是选择语音从哪里来,我们选择从麦克风来。然后就可以对这麦克风说话,这里会自动将语音转换成文字。

三、文字转语音操作
到samples/tts_online_sample文件夹下执行编译命令source 64bit_make.sh ,然后到bin/文件夹下执行./tts_online_sample。

运行之后按任意键退出,在bin/文件夹下生成一个tts_sample.wav,可以双击运行播放。如果想要运行上述指令后自动播放wav文件,则需要修改源码,找到 samples/tts_online_sample/tts_online_sample.c文件,在第174行(printf("合成完毕\n");这句后面)添加如下代码,就可以在合成之后自动播放合成的文件。
popen("play tts_sample.wav","r");
添加完后要重新编译:source 64bit_make.sh ,然后到bin/下执行./tts_online_sample。

四、ROS语音输入功能
1.任务介绍
利用科大讯飞开放平台来实现ROS的语音输入功能。任务流程图如下,在终端中,通过/voiceWakeup话题发布一个唤醒词,开启语音转文字的功能。随后通过修改iat_publish.cpp实现语音转文字的功能,转化出来的文字送入到/voiceWords话题中发布出来。

2.创建工作空间
首先建立一个ROS工作空间ws/src,在ws/目录下执行catkin_make编译工作空间。在工作空间内建立一个robot_voice的功能包,添加依赖为roscpp std_msgs。
然后将科大讯飞开放平台下载的sdk包中include/*.h文件夹中的所有.h文件(共6个)复制到ws/src/robot_voice/include/robot_voice/中,如下:

将sdk中/samples/iat_online_record_sample/*.h文件夹中所有的.h文件(共3个)也复制到ws/src/robot_voice/include/robot_voice/中,如下:

将sdk中/samples/iat_online_record_sample/*.c文件夹中所有的.c文件(共3个)复制到ws/src/robot_voice/src/中,并将iat_online_record_sample.c改名为iat_publish.cpp,如下:

3.修改cpp功能文件
接下来我们修改iat_publish.cpp文件以实现语音转文字的功能。首先是修改头文件,将下面四个头文件进行修改。

#include "robot_voice/qisr.h"
#include "robot_voice/msp_cmn.h"
#include "robot_voice/msp_errors.h"
#include "robot_voice/speech_recognizer.h"
同样,在linuxrec.c和speech_recognizer.c当中我们也需要修改头文件(加上robot_voice/即可)。


继续回到iat_publish.cpp文件中,为其添加ROS的头文件,并定义两个标志,一个是唤醒标志,一个是转换标志:
#include "ros/ros.h"
#include "std_msgs/String.h"
int wakeupFlag = 0 ;
int resultFlag = 0 ;

在show_result函数中添加一行标志位:
resultFlag=1;

在main函数中的开头添加ROS初始化节点的程序,这里会有Wakep函数的报错,这是一个唤醒的回调函数,我们还没有编写,别急,马上就到。

// 初始化ROS
ros::init(argc, argv, "voiceRecognition");
ros::NodeHandle n;
ros::Rate loop_rate(10);
// 声明Publisher和Subscriber
// 订阅唤醒语音识别的信号
ros::Subscriber wakeUpSub = n.subscribe("voiceWakeup", 1000, WakeUp);
// 订阅唤醒语音识别的信号
ros::Publisher voiceWordsPub = n.advertise<std_msgs::String>("voiceWords", 1000);
ROS_INFO("Sleeping...");
int count=0;
在主函数中继续往下找,找到下面的这几行删掉,我们重新编写唤醒代码和语音转文字代码。

删除后的位置添加如下代码:
while(ros::ok())
{
// 语音识别唤醒
if(wakeupFlag)
{
printf("Demo recognizing the speech from microphone\n");
printf("Speak in 8 seconds\n");
demo_mic(session_begin_params);
printf("8 sec passed\n");
wakeupFlag=0;
}
// 语音识别完成
if(resultFlag){
resultFlag=0;
std_msgs::String msg;
msg.data = g_result;
voiceWordsPub.publish(msg);
}
ros::spinOnce();
loop_rate.sleep();
count++;
}
最后在main函数之前添加一个唤醒WakeUp()代码:
void WakeUp(const std_msgs::String::ConstPtr& msg)
{
printf("waking up\r\n");
usleep(700*1000);
wakeupFlag=1;
}
至此语音转文字的代码修改就完成了,可以实现15s的语音转文字,如果需要修改15s为其他,例如8s,需要修改三处(主要是一处,另外两处只是可视化):
在主函数刚刚写的while循环中修改两处:
printf("Demo recognizing the speech from microphone\n");
printf("Speak in 8 seconds\n");
demo_mic(session_begin_params);
printf("8 sec passed\n");
在demo_mic()函数中修改一处:
/* demo 8 seconds recording */
while(i++ < 8)
sleep(1);
4.配置CMakeLists.txt文件
接下来是配置CMakeLists.txt文件:
第5行注释打开。
add_compile_options(-std=c++11)
第117行include头文件路径注释打开
include_directories(
include
${catkin_INCLUDE_DIRS}
)
第135行添加可执行文件:
add_executable(iat_publish src/iat_publish.cpp src/speech_recognizer.c src/linuxrec.c)
第148行添加编译链接库
target_link_libraries(iat_publish
${catkin_LIBRARIES}
libmsc.so -ldl -lpthread -lm -lrt -lasound
)
5.运行语音转文字
至此配置完成,可以编译并运行功能包:
rosrun robot_voice iat_publish
出现如下说明需要唤醒词进行唤醒,然后方可用麦克风输入语音。
(base) chen@chen-GL62M-7RD:~/Downloads/ws$ rosrun robot_voice iat_publish
[ INFO] [1655621110.627786267]: Sleeping...
我们重新开启一个终端,查看当前话题rostopic list。
(base) chen@chen-GL62M-7RD:~$ rostopic list
/rosout
/rosout_agg
/voiceWakeup
/voiceWords
可以看到有一个/voiceWakeup话题,输入任意字符,运行这个话题即可。
(base) chen@chen-GL62M-7RD:~$ rostopic pub /voiceWakeup std_msgs/String "data: 'input any words'"
publishing and latching message. Press ctrl-C to terminate
(base) chen@chen-GL62M-7RD:~/Downloads/ws$ rosrun robot_voice iat_publish
[ INFO] [1655621110.627786267]: Sleeping...
waking up
Demo recognizing the speech from microphone
Speak in 8 seconds
Start Listening...
Result: [ 你好啊,这是一个测试案例。 ]
搞定!
五、ROS文字转语音输出功能
1.任务介绍
利用科大讯飞开放平台来实现ROS的语音输出功能。任务流程图如下,在终端中,通过终端往/voiceWords话题发布一个字符串,开启文字转语音的功能。随后通过修改tts_subscribe.cpp实现文字转语音的功能,转化出来的语音进行实时播报。

2.创建工作空间
工作空间仍采用上一小节建立好的工作空间,在此基础上进行添加相关功能。将科大讯飞的sdk中/samples/tts_online_sample/文件夹下的tts_online_sample.c文件复制到ws/src/robot_voice/src/中,并改名字为tts_subscribe.cpp。
3.修改tts_subscribe.cpp
首先还是头文件的修改:

#include "robot_voice/qtts.h"
#include "robot_voice/msp_cmn.h"
#include "robot_voice/msp_errors.h"
#include "ros/ros.h"
#include "std_msgs/String.h"```
接下来是主函数main的修改,我们首先删除以下语音合成的代码:

在删除的位置添加如下代码,包含ROS节点初始化,以及订阅文字话题进行文字转语音的回调函数。
```cpp
ros::init(argc,argv,"TextToSpeech");
ros::NodeHandle n;
ros::Subscriber sub =n.subscribe("voiceWords", 1000, voiceWordsCallback);
ros::spin();
文字转语音的回调函数如下:
void voiceWordsCallback(const std_msgs::String::ConstPtr& msg)
{
char cmd[2000];
const char* text;
int ret = MSP_SUCCESS;
const char* session_begin_params = "voice_name = xiaoyan, text_encoding = utf8, sample_rate = 16000, speed = 50, volume = 50, pitch = 50, rdn = 2";
const char* filename = "tts_sample.wav"; //合成的语音文件名称
std::cout<<"I heard :"<<msg->data.c_str()<<std::endl;
text = msg->data.c_str();
/* 文本合成 */
printf("开始合成 ...\n");
ret = text_to_speech(text, filename, session_begin_params);
if (MSP_SUCCESS != ret)
{
printf("text_to_speech failed, error code: %d.\n", ret);
}
printf("合成完毕\n");
popen("play tts_sample.wav","r");
sleep(1);
}
将主函数中这三行没用注释掉:
![]()
修复一个错误,将用户登陆中的goto exit删除,改为调用toExit()函数。

void toExit()
{
printf("按任意键退出 ...\n");
getchar();
MSPLogout(); //退出登录
}
4.配置CMakeLists.txt文件
下面进行配置文件,仍在上一节的CMakeLists.txt基础上添加下面两行。
add_executable(tts_subscribe src/tts_subscribe.cpp)
target_link_libraries(tts_subscribe
${catkin_LIBRARIES}
libmsc.so -ldl -pthread
)
rosrun robot_voice tts_subscribe

等待输入字符串进行文字转语音,运行rostopic list查看话题,然后往/voiceWords中发布一条字符串:这是一个测试案例。可以发现扬声器开始播报。
(base) chen@chen-GL62M-7RD:~$ rostopic list
/rosout
/rosout_agg
/voiceWords
(base) chen@chen-GL62M-7RD:~$ rostopic pub /voiceWords std_msgs/String "data: ' 这是一个测试案例'"
###########################################################################
## 语音合成(Text To Speech,TTS)技术能够自动将任意文字实时转换为连续的 ##
## 自然语音,是一种能够在任何时间、任何地点,向任何人提供语音信息服务的 ##
## 高效便捷手段,非常符合信息时代海量数据、动态更新和个性化查询的需求。 ##
###########################################################################
I heard :这是一个测试案例
开始合成 ...
正在合成 ...
>>
合成完毕
tts_sample.wav:
File Size: 48.0k Bit Rate: 256k
Encoding: Signed PCM
Channels: 1 @ 16-bit
Samplerate: 16000Hz
Replaygain: off
Duration: 00:00:01.50
In:100% 00:00:01.50 [00:00:00.00] Out:24.0k [ | ] Hd:5.0 Clip:0
搞定!
六、ROS同时实现语音输入和文字转语音输出
1.任务介绍
利用科大讯飞开放平台来实现ROS同时输入输出语音功能。任务流程图如下,其实就是将第四和第五两节的内容融合起来。首先在终端中,往/voiceWakeup话题发布唤醒词,开启语音转文字功能。接着开启文字转语音功能从/voiceWords话题中获取文字转化成语音播放出来。

2.建立launch启动文件
我们建立一个launch启动文件,将前面两节的功能包包含进来即可,repeat_voice.launch内容如下:
<launch>
<node name="iat_publish" pkg="robot_voice" type="iat_publish" output="screen"/>
<node name="tts_subscribe" pkg="robot_voice" type="tts_subscribe" output="screen"/>
launch>
运行roslaunch robot_voice repeat_voice.launch
发布唤醒词:
(base) chen@chen-GL62M-7RD:~$ rostopic pub /voiceWakeup std_msgs/String "data: 'any words'"
语音转文字and文字转语音:
(base) chen@chen-GL62M-7RD:~/Downloads/ws$ roslaunch robot_voice repeat_voice.launch
... logging to /home/chen/.ros/log/098c4190-efa1-11ec-a3dc-07c3dc4289df/roslaunch-chen-GL62M-7RD-221609.log
Checking log directory for disk usage. This may take a while.
Press Ctrl-C to interrupt
Done checking log file disk usage. Usage is <1GB.
started roslaunch server http://chen-GL62M-7RD:45243/
SUMMARY
========
PARAMETERS
* /rosdistro: noetic
* /rosversion: 1.15.11
NODES
/
iat_publish (robot_voice/iat_publish)
tts_subscribe (robot_voice/tts_subscribe)
ROS_MASTER_URI=http://localhost:11311
process[iat_publish-1]: started with pid [221642]
process[tts_subscribe-2]: started with pid [221643]
###########################################################################
## 语音合成(Text To Speech,TTS)技术能够自动将任意文字实时转换为连续的 ##
## 自然语音,是一种能够在任何时间、任何地点,向任何人提供语音信息服务的 ##
## 高效便捷手段,非常符合信息时代海量数据、动态更新和个性化查询的需求。 ##
###########################################################################
[ INFO] [1655624055.542878974]: Sleeping...
waking up
Demo recognizing the speech from microphone
Speak in 8 seconds
Start Listening...
Result: [ 你好啊,这是一个测试案例。 ]
Speaking done
Not started or already stopped.
8 sec passed
I heard :你好啊,这是一个测试案例。
开始合成 ...
正在合成 ...
>>>
合成完毕
tts_sample.wav:
File Size: 84.5k Bit Rate: 256k
Encoding: Signed PCM
Channels: 1 @ 16-bit
Samplerate: 16000Hz
Replaygain: off
Duration: 00:00:02.64
In:100% 00:00:02.64 [00:00:00.00] Out:42.2k [ ===|=== ] Clip:0
Done.
七、ROS实现语音交互功能
1.任务介绍
语音交互功能是前面案例的综合,通过唤醒词启动交互功能,语音输入一段音频后,根据输入的音频取执行响应的动作,例如返回另一端音频,或者发布一个指定的话题等等。
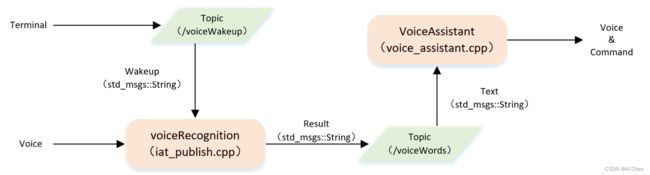
2.修改CPP文件
复制tts_subscribe.cpp文件并更名为voice_assistant.cpp。主要添加一个函数,修改一个函数。
添加to_string()函数。
std::string to_string(int val)
{
char buf[20];
sprintf(buf, "%d", val);
return std::string(buf);
}
修改voiceWordsCallback()函数。
void voiceWordsCallback(const std_msgs::String::ConstPtr& msg)
{
char cmd[2000];
const char* text;
int ret = MSP_SUCCESS;
const char* session_begin_params = "voice_name = xiaoyan, text_encoding = utf8, sample_rate = 16000, speed = 50, volume = 50, pitch = 50, rdn = 2";
const char* filename = "tts_sample.wav"; //合成的语音文件名称
std::cout<<"I heard :"<<msg->data.c_str()<<std::endl;
std::string dataString = msg->data;
if(dataString.find("你是谁") != std::string::npos
|| dataString.find("名字") != std::string::npos)
{
char nameString[100] = "我是你的语音小助手,你可以叫我小R";
text = nameString;
std::cout<<text<<std::endl;
}
else if(dataString.find("你几岁了") != std::string::npos
|| dataString.find("年龄") != std::string::npos)
{
char eageString[100] = "我已经四岁了,不再是两三岁的小孩子了";
text = eageString;
std::cout<<text<<std::endl;
}
else if(dataString.find("你可以做什么") != std::string::npos
|| dataString.find("干什么") != std::string::npos)
{
char helpString[100] = "你可以问我现在时间";
text = helpString;
std::cout<<text<<std::endl;
}
else if(dataString.find("时间") != std::string::npos)
{
//获取当前时间
struct tm *ptm;
long ts;
ts = time(NULL);
ptm = localtime(&ts);
std::string string = "现在时间" + to_string(ptm-> tm_hour) + "点" + to_string(ptm-> tm_min) + "分";
char timeString[40] = {0};
string.copy(timeString, sizeof(string), 0);
text = timeString;
std::cout<<text<<std::endl;
}
else
{
text = msg->data.c_str();
}
/* 文本合成 */
printf("开始合成 ...\n");
ret = text_to_speech(text, filename, session_begin_params);
if (MSP_SUCCESS != ret)
{
printf("text_to_speech failed, error code: %d.\n", ret);
}
printf("合成完毕\n");
popen("play tts_sample.wav","r");
sleep(1);
}
3.修改配置文件
在原有的基础上添加如下两行:
add_executable(voice_assistant src/voice_assistant.cpp)
target_link_libraries(
voice_assistant
${catkin_LIBRARIES}
libmsc.so -ldl -pthread
)
4.创建launch启动文件
voice_assistant.launch启动文件内容如下:
<launch>
<node name="iat_publish" pkg="robot_voice" type="iat_publish" output="screen"/>
<node name="voice_assistant" pkg="robot_voice" type="voice_assistant" output="screen"/>
launch>
启动roslaunch robot_voice voice_assistant.launch
在终端输入唤醒词:
(base) chen@chen-GL62M-7RD:~$ rostopic pub /voiceWakeup std_msgs/String "data: 'any words'"
然后可以进行:你是谁?你会干什么?等关键词的交互对话。如下:
(base) chen@chen-GL62M-7RD:~/Downloads/ws$ roslaunch robot_voice voice_assistant.launch
... logging to /home/chen/.ros/log/14f60494-efa6-11ec-ac12-99bf7dab2f5e/roslaunch-chen-GL62M-7RD-16071.log
Checking log directory for disk usage. This may take a while.
Press Ctrl-C to interrupt
Done checking log file disk usage. Usage is <1GB.
started roslaunch server http://chen-GL62M-7RD:38585/
SUMMARY
========
PARAMETERS
* /rosdistro: noetic
* /rosversion: 1.15.11
NODES
/
iat_publish (robot_voice/iat_publish)
voice_assistant (robot_voice/voice_assistant)
ROS_MASTER_URI=http://localhost:11311
process[iat_publish-1]: started with pid [16092]
process[voice_assistant-2]: started with pid [16093]
###########################################################################
## 语音合成(Text To Speech,TTS)技术能够自动将任意文字实时转换为连续的 ##
## 自然语音,是一种能够在任何时间、任何地点,向任何人提供语音信息服务的 ##
## 高效便捷手段,非常符合信息时代海量数据、动态更新和个性化查询的需求。 ##
###########################################################################
[ INFO] [1655626374.490402348]: Sleeping...
waking up
Demo recognizing the speech from microphone
Speak in 8 seconds
Start Listening...
Result: [ 你是谁? ]
Speaking done
Not started or already stopped.
8 sec passed
I heard :你是谁?
我是你的语音小助手,你可以叫我小R
开始合成 ...
正在合成 ...
>>>>
合成完毕
tts_sample.wav:
File Size: 120k Bit Rate: 256k
Encoding: Signed PCM
Channels: 1 @ 16-bit
Samplerate: 16000Hz
Replaygain: off
Duration: 00:00:03.74
In:100% 00:00:03.74 [00:00:00.00] Out:59.8k [ | ] Hd:5.1 Clip:0
Done.
waking up
Demo recognizing the speech from microphone
Speak in 8 seconds
Start Listening...
Result: [ 你多大年龄了? ]
Speaking done
Not started or already stopped.
8 sec passed
I heard :你多大年龄了?
我已经四岁了,不再是两三岁的小孩子了
开始合成 ...
正在合成 ...
>>>>>
合成完毕
tts_sample.wav:
File Size: 129k Bit Rate: 256k
Encoding: Signed PCM
Channels: 1 @ 16-bit
Samplerate: 16000Hz
Replaygain: off
Duration: 00:00:04.04
In:100% 00:00:04.04 [00:00:00.00] Out:64.6k [ | ] Hd:5.6 Clip:0
Done.
至此利用科大讯飞开放平在在ROS中实现语音交互学习完成!