CUDA学习笔记(大白话入门课程)
CUDA的基本概念:
CUDA是NVIDIA公司推出的并行计算框架,只能基于自家GPU的硬件平台进行性能加速运算,所以使用CUDA编程的前提是必须要有NVIDIA的显卡。
主流的深度学习框架也都是基于CUDA进行GPU并行加速的,几乎无一例外。还有一个叫做cudnn,是针对深度卷积神经网络的加速库。
与之相类似的并行计算框架还有苹果公司推出的OpenCL,OpenCL其优势在于跨平台性和通用性,更像是一个开放标准,按理说OpenCL会更加受欢迎,但是由于NVIDIA公司在GPU显卡领域一家独大,市场份额独占鳌头,使得CUDA的生态支持等方面更加完善,因此在短期以及未来的相当一段时间,并行加速领域还是CUDA更受欢迎一些。
学习内容:
1.CUDA的组成:
1.1、CPU、GPU与kernel
虽然CUDA平台的并行计算是在GPU上完成的,但是并不仅仅依赖于GPU,还需要和CPU分工配合才能实现。在这里CPU是(Host)主机端,GPU属于(Device)设备端,两者通过kernel(核函数)连接,在CUDA程序构架中,主程序还是由CPU来执行,而当遇到数据并行处理的部分(即kernel),CUDA 就会将程序上传送到GPU端运行。kernel用__global__符号声明,在调用时需要用<<
__global__ void hello_world_from_gpu(void)
{
printf("Hello World from GPU\n");
return;
}
1.2、Grid、Block与Thread
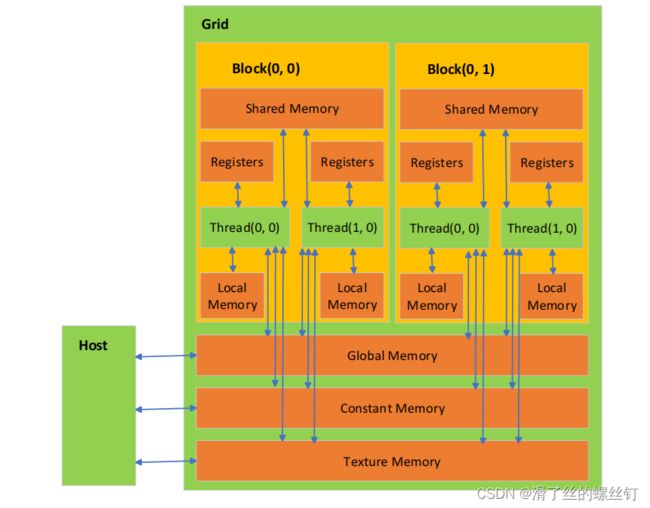
Grid、Block与Thread这些概念简单来说就是GPU在运算执行过程中计算资源分配的单位,大白话说就是你打算用多少GPU的资源去执行并行计算。所谓网格 (grid),其实就是线程块(Block)的组合体,而Block中又包含了很多的Thread线程,按包含关系来说Grid>Block>Thread,结构如下图。
体现在kerne函数中,就是指在CPU调用kernel函数时,在kernel函数后面紧跟着的<<
比如前面定义了一个kernel函数hello_world_from_gpu,在CPU调用时需要写成hello_world_from_gpu <<Grid和Block就是你要分配的资源线程数,具体怎么分配GPU的线程是很有讲究的,不是说随便制定一个数字都行的,下面会提到注意事项。
每个 thread 都有自己的一份 register 和 local memory 的空间。同一个 block 中的每个 thread 则有共享的一份 share memory。此外,所有的 thread (包括不同 block 的 thread) 都共享一份 global memory。不同的 grid 则有各自的 global memory。
1.3、SM与Warp
当一个 kernel 被执行时,grid 中的线程块被分配到 SM (多核处理器) 上,SM是GPU上真正的物理执行单元,一个线程块的 thread 只能在一个SM 上调度,SM 一般可以调度多个线程块,大量的 thread 可能被分到不同的 SM 上。
warp (线程束) 是最基本的执行单元。一个 warp 包含32个并行 thread,这些 thread 以不同数据资源执行相同的指令。所以warp 本质上是线程在 GPU 上运行的最小单元。由于warp的大小为32,所以block所含的thread的大小一般要设置为32的倍数。
2.CUDA程序的运行步骤:
2.1:从主机 (host) 端申请 device memory,把要拷贝的内容从 host memory 拷贝到申请的 device memory 里面。
在CPU上申请显存的函数 malloc():
float* a = (float*)malloc(sizeof(float) * size * size);
在Device端申请显存的函数 cudaMalloc():
cudaMalloc((void**)&a_cuda, sizeof(float) * size * size);
把要拷贝的内容从 host memory 拷贝到申请的 device memory 里面:
cudaMemcpy(a_cuda, a, sizeof(float) * size * size, cudaMemcpyHostToDevice);
2.2:设备端的核函数对拷贝进来的东西进行计算,来得到和实现运算的结果,Kernel 就是指在 GPU 上运行的函数。
//核函数
__global__ void kernel(int a, int b, int* c)
{
*c = a * (b+1);
}
2.3:把结果从 device memory 拷贝到申请的 host memory 里面,并且释放设备端的显存和内存
cudaMemcpy(&c, device_c, sizeof(int), cudaMemcpyDeviceToHost); //将设备端内存拷贝到主机端
因此一个完整的CUDA程序实例如下(.cu格式的文件):
#include 从上面完整的CUDA程序可以看出其格式结构和cpp文件基本一致,只不过这是一个.cu的格式,并且多了类似cuda_runtime.h这样的头文件。定义的kernel函数在main函数中进行调用。
kernel <<< 1, 1 >> > (2, 7, device_c);
注意核函数只能在主机端调用,调用时必须申明执行参数。调用形式如下:
Kernel<<<grid,block, Ns, S>>>(param list);
调用通过<<
参数 Ns 是一个可选参数,用于设置每个 block 除了静态分配的 shared Memory 以外,最多能动态分配的shared memory 大小,单位为 byte。不需要动态分配时该值为0或省略不写,一般可默认不写。
参数 S 是一个 cudaStream_t 类型的可选参数,初始值为零,表示该核函数处在哪个流之中,一般可默认不写。
由于Grid和Block都可以从1维定义到3维,那么在不同维度下Thread的索引ID怎么唯一确定呢?建议仔细阅读一下这篇文章,看完绝对豁然开朗!
【CUDA】grid、block、thread的关系及thread索引的计算
更多详情,请参考官方CUDA编程指南