Masked Autoencoders Are Scalable Vision Learners | MAE 阅读笔记&部分翻译
Masked Autoencoders Are Scalable Vision Learners
Author Unit: Facebook AI Research (FAIR)
Authors: Kaiming He ∗ , † ^{∗,†} ∗,† Xinlei Chen ∗ ^∗ ∗ Saining Xie Yanghao Li Piotr Dollár Ross Girshick
Conference: arXiv:2111.06377v1 [cs.CV] 11 Nov 2021
Paper address: https://arxiv.org/abs/2111.06377
bilibili_limu: https://www.bilibili.com/video/BV1sq4y1q77t
Notion 版本的笔记
假设你的算法特别快,就把标题里面放 efficient;假设你做的东西比较大,就叫 scalable。 —李沐
这里 Autoencoder 中的 Auto 不是指自动的意思,而是“自”,也就是训练样本 x 和标签 y 都是 x 本身。
写论文的时候可以考虑用类似的标题样式,即 ** 是 **,就像这篇文章的标题,很好的将自己的工作浓缩成了一句简短的话。
Abstract
本文表明,masked autoencoders (MAE) 是用于计算机视觉的可扩展自监督学习器。我们的 MAE 方法很 simple:我们屏蔽输入图像的随机块并重建丢失的像素。它基于两个核心设计。首先,我们开发了非对称的编码器 - 解码器架构,其中编码器仅对可见的补丁 patches 子集(没有掩码标记)进行操作,以及一个轻量级的解码器,可从潜在表征 latent representation 和掩码标记 mask tokens 重建原始图像。其次,我们发现屏蔽大部分输入图像(例如 75%)会产生重要且有意义的自监督任务。将这两种设计结合起来使我们能够高效地训练大型模型:我们加速了训练(3 倍或更快)并提高了准确性。我们的可扩展方法允许学习泛化性良好的高容量模型:例如,在仅使用 ImageNet-1K 数据的方法中,vanilla ViT-Huge 模型实现了最佳准确率 (87.8%)。下游任务中的迁移 transfer 性能优于有监督的预训练,并显示出有希望的扩展行为。
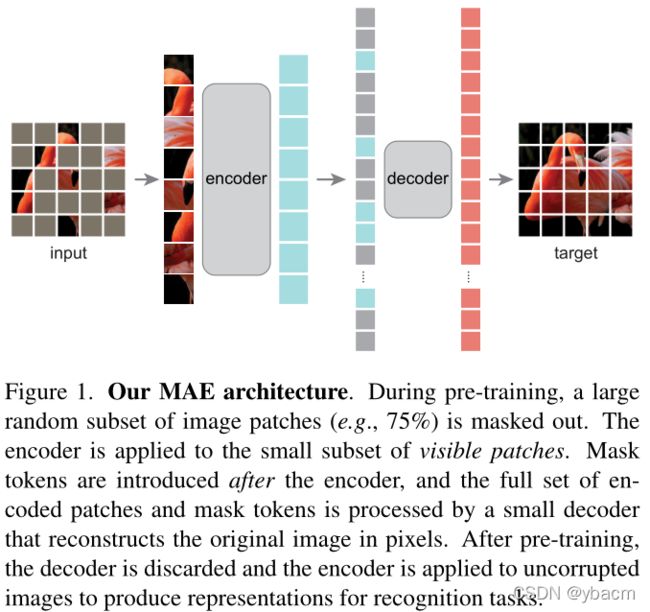
在做下游任务的时候,只用到编码器。
1. Introduction
掩码自动编码器的概念,即一种更通用的去噪自动编码器[48]的形式,是很自然的,并可以适用于计算机视觉。We ask: what makes masked autoencoding different between vision and language? 我们试图从以下几个方面来回答这个问题:
(i) 直到最近,架构还是不同的。在视觉上,卷积网络[29]在过去十年中占主导地位。卷积通常在规则网格上运行,并不是直接集成“指标”,如 mask tokens [14]或 positional embeddings[47]到卷积网络。然而,这种架构上的差距已经被 ViT [16] 解决了,应该不再是一个障碍。
Bert 里将一个单词做 mask,在网络中最后可以还原出这个 mask token,但是用卷积的话,将多个像素做 mask,卷积窗口一直滑动是无法分清楚 mask 边界的,最后也不太好还原,所以作者说不能将 mask tokens 用在卷积网络里。
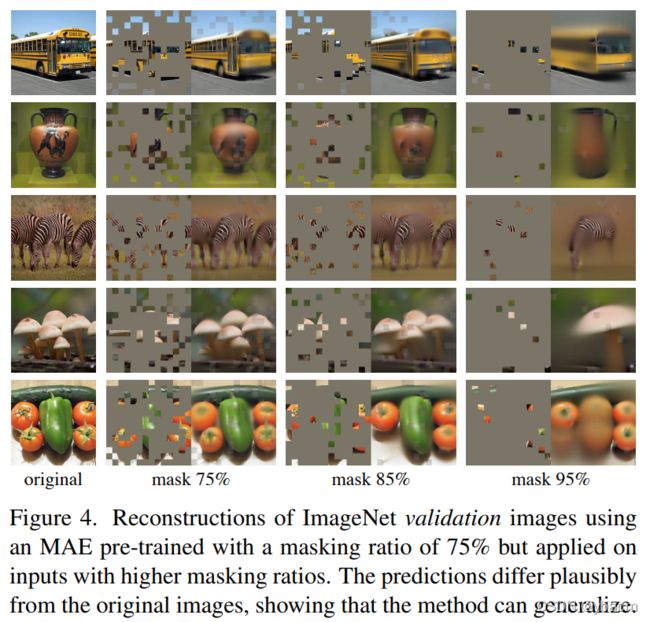
(ii) 语言和视觉之间的信息密度不同。 语言是人类生成的具有高度语义和信息密集度的信号。 当训练一个模型来预测每个句子的几个遗漏单词时,这个任务似乎会导致复杂的语言理解。 相反,图像是具有大量空间冗余的自然信号——例如,可以从相邻的补丁中恢复丢失的补丁,而对 parts、objects 和 scenes 的高级理解很少。 为了克服这种差异并鼓励学习有用的特征,我们展示了一个在计算机视觉中效果很好的简单策略: 屏蔽很大一部分的随机补丁。 这种策略在很大程度上减少了冗余,并创建了一项具有挑战性的自监督任务,其需要获得超越 low-level image statistics 的整体理解。 请参见图 2-4 来对我们的重建任务有一个定性的认识。
(iii) 自动编码器的解码器将潜在的表示映射回输入,在重构文本和图像之间扮演着不同的角色。在视觉中,解码器重建像素,因此其输出的语义水平低于普通识别任务。这与语言相反,在语言中,解码器预测包含丰富语义信息的遗漏单词。虽然在BERT中解码器可以是微不足道的 (一个MLP) [14],但我们发现,对于图像, 解码器的设计在确定学到的潜在表示的语义级别方面起着关键作用。
在此分析的推动下,我们提出了一种简单、有效且可扩展的掩码自编码器 (MAE) 形式,用于视觉表示学习。 我们的 MAE 从输入图像中屏蔽了随机补丁并重建像素空间中丢失的补丁。 它具有非对称编码器解码器设计。 我们的编码器仅对补丁的可见子集(没有掩码标记)进行操作,我们的解码器是轻量级的,可以从潜在表示和掩码标记中重建输入(图 1)。 在我们的非对称编码器-解码器中,将掩码标记转移到小型解码器会导致计算量大幅减少( 意指 encoder 并没有接收 masked token 为输入 )。 在这种设计下,非常高的掩码率(例如 75%)可以实现双赢:它优化了准确性,同时允许编码器仅处理一小部分(例如 25%)的补丁。 这可以将整体预训练时间减少 3 倍或更多,同样减少内存消耗,使我们能够轻松地将 MAE 扩展到大型模型。
我们的 MAE 学习了非常高容量的模型,可以很好地泛化。 通过 MAE 预训练,我们可以在 ImageNet-1K 上训练 ViT-Large/-Huge [16] 等需要大量数据的 data-hungry 模型,并提高泛化性能。 使用普通的 ViT-Huge 模型,我们在 ImageNet-1K 上微调时达到了 87.8% 的准确率。 这优于之前仅使用 ImageNet-1K 数据的所有结果。 我们还评估了对象检测、实例分割和语义分割的迁移学习。 在这些任务中,我们的预训练比其监督预训练获得了更好的结果,更重要的是,我们通过扩大模型观察到了显着的收益。 这些观察结果与 NLP 中自监督预训练 [14,40,41,4] 中的观察结果一致,我们希望它们能让我们的领域探索类似的轨迹。
作者用了两页来写了导言部分,一是因为用了几张图片(对于计算机视觉的论文亮出好结果是加分的),二是作者先提了问题,然后讲清楚了自己的动机,这很重要!
2. Related Work
Masked language modeling
Autoencoding
Masked image encoding
Self-supervised learning
写作的时候要将自己的工作与比较相关工作的不同点写出来,不要让别人去猜。
3. Approach
与传统的自动编码器不同,我们采用非对称设计,允许编码器只对部分观测信号 (没有掩码标记) 进行操作,并采用轻量级解码器从潜在表示和掩码标记重建完整信号。图1说明了接下来介绍的想法。
Masking. 与 ViT[16] 一样,我们将图像划分为 regular non-overlapping patches。然后我们采样一个 patches 的子集并将它们进行 mask 处理。我们的抽样策略很简单:随机抽样,不进行替换,遵循均匀分布。我们简单地称之为“随机抽样”。
具有高掩蔽率(即移除补丁的比率)的随机采样在很大程度上消除了冗余,从而创建了一项无法通过相邻像素来轻松的解决任务(见图 2-4)。 均匀分布可防止潜在的中心偏差(即,图像中心附近有更多的掩蔽补丁)。 最后,高度稀疏的输入为设计高效的编码器创造了机会,接下来介绍。
MAE encoder. 我们的编码器是一个 ViT[16],但只适用于可见的,未屏蔽的补丁。就像在标准 ViT 中一样,我们的编码器通过添加位置嵌入的线性投影来 embeds 补丁,然后通过一系列 Transformer 块处理结果集。然而,我们的编码器只操作 full set 中的一小部分(例如,25%)。掩码 patches 被移除了;没有使用掩码 token。这使我们能够训练非常大的编码器,只用一小部分的计算和内存。完整的集合由轻量级解码器处理,下面将介绍。
MAE decoder. MAE 解码器的输入是完整的 token 集,包括 (i) 编码的可见 patches 和 (ii) 掩码 tokens ,见图1。 每个掩码 token[14] 是一个共享的可学习向量,指示要预测的缺失补丁的存在。 我们为这个 full set 中的所有 tokens 添加了位置嵌入; 如果没有这个,掩码 tokens 将没有关于它们在图像中的位置的信息。 解码器是另一系列的 Transformer 模块。
MAE 解码器仅在预训练期间用于执行图像重构任务(仅使用编码器生成用于识别的图像表征)。 因此,可以以独立于编码器设计的方式灵活地设计解码器架构。 我们试验了非常小的解码器,比编码器更窄更浅。 例如,我们的默认解码器对每个 token 的计算量比编码器要小于 10%。通过这种非对称设计,the full set of tokens 仅由轻量级解码器处理,这显著减少了预训练时间。
Reconstruction target. 我们的 MAE 通过预测每个掩码块的像素值来重构输入。 解码器输出中的每个元素都是一个表征补丁的像素值向量。 解码器的最后一层是线性投影,其输出通道的数量等于补丁中像素值的数量。 解码器的输出被 reshape 以形成重构的图像。 我们的损失函数计算像素空间中重建图像和原始图像之间的均方误差 (MSE)。 我们仅在掩码补丁上计算损失,类似于 BERT [14]。
我们还研究了一个变量,其重构目标是每个 masked patch 的归一化像素值。具体来说,我们计算一个 patch 中所有像素的均值和标准差,并用它们来归一化这个 patch。在我们的实验中,使用归一化像素作为重建目标可以提高再现质量。
这里作者没提到预测的时候怎么办
Simple implementation. 我们的 MAE 预训练可以高效实施,重要的是,不需要任何专门的稀疏操作。 首先,我们为每个输入补丁生成一个 token(通过线性投影和添加的位置嵌入)。 接下来,我们根据掩蔽率 randomly shuffle tokens 列表并删除列表的最后一部分。 此过程是为编码器生成一小部分的 tokens ,相当于采样补丁而无需替换。 编码后,我们将掩码标记列表附加到编码补丁列表中,并 unshuffle 这个完整列表(inverting the random shuffle operation)以将所有 tokens 与其目标对齐。 解码器应用于此完整列表(添加了位置嵌入)。 如前所述,不需要稀疏操作。 这个简单的实现引入的开销可以忽略不计,因为 shuffling 和 unshuffling 操作很快。
4. ImageNet Experiments
我们在 ImageNet-1K (IN1K) [13] 训练集上进行自监督的预训练。 然后我们进行有监督的训练,以通过 (i) end-to-end 微调或 (ii) linear probing ( 意思就是只微调最后的线性输出层 )来评估表征。 我们报告了使用中心裁剪 224×224 的图片以及 top-1 验证精度。 详情见附录A.1。
Baseline: ViT-Large. 我们在消融研究中使用 ViT-Large (ViT-L/16) [16] 作为主干。 ViT-L 非常大(比 ResNet-50 [24] 大一个数量级)并且容易过拟合。 以下是从头开始训练的 ViT-L 与从我们的基线 MAE 微调的比较:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-GMirpXyB-1639292820503)(Masked%20Autoencoders%20Are%20Scalable%20Vision%20Learners%20e7d638a324c544c597f4204886384d88/MAE_table0.png)]
我们注意到从头开始训练有监督的 ViT-L 是 nontrivial,并且需要一个具有强正则化的良好配方(82.5%,参见附录 A.2)。 尽管如此,我们的 MAE 预训练还是有很大的改进。 此处微调仅训练了 50 个 epoch(而从头开始为 200 个),这意味着微调精度在很大程度上取决于预训练。
4.1. Main Properties

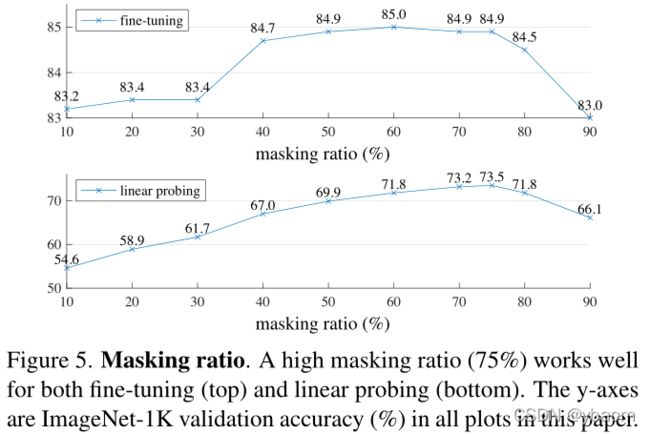
Masking ratio. Figure 5.

Decoder design. Table 1a and 1b. 一个足够深的解码器对于 linear probing 很重要。这可以用像素重建任务和识别任务之间的差距来解释:自编码器的最后几层更专门用于重构,而与识别不太相关。
有趣的是,使用 single-block 解码器的 MAE 可以通过微调(84.8%)实现强大的性能。请注意,单个 Transformer 块是将信息从 visible tokens 传播到 mask tokens 的最小要求。这样的小解码器可以进一步加快训练速度。
从 Table 1b 可以看出,一个 narrower 的 decoder 也可以很好的进行 fine-tuning。
总的来说,我们的 MAE decoder 是很轻量的。It only has 9% FLOPs per token vs. ViT-L (24 blocks, 1024-d).
Mask token. Table 1c. If the encoder uses mask tokens, it performs worse.
Reconstruction target. Table 1d.
Data augmentation. Table 1e.
Mask sampling strategy. Table 1f.
Training schedule. Figure 7.



4.2. Comparisons with Previous Results
Comparisons with self-supervised methods. Table 3.
Comparisons with supervised pre-training. Figure 8.
4.3. Partial Fine-tuning
Figure 9. 从图中可以看出, **顶部的几层还是跟具体任务比较相关,需要进行比较大的改动,**底部的可能不需要什么改动。
5. Transfer Learning Experiments



6. Discussion and Conclusion
Simple algorithms that scale well are the core of deep learning.
在自然语言处理中,简单的自监督学习方法 (如[40,14,41,4]) 可以从 exponentially scaling models 中获益。在计算机视觉中,尽管在自监督学习方面取得了进展,但实用的训练前范例主要是有监督的 (例如[28,44,24,16])。在这项研究中,我们观察到在 ImageNet 和迁移学习中,自动编码器(一种简单的自我监督的方法,类似于nlp中的技术)提供了可扩展的好处。视觉上的自监督学习现在可能正走上与NLP相似的轨迹。
另一方面,我们注意到图像和语言是不同性质的信号,这种差异必须小心处理。图像只是记录的光,没有语义化的分解成文字的视觉模拟。我们不是试图删除对象,而是删除那些最有可能不形成语义片段的随机补丁。同样地,我们的 MAE 重建像素,它们不是语义实体。然而,我们观察到 (例如,图4),我们的 MAE 可以预测出复杂的、整体的重构信息,表明它已经学习了许多视觉概念,即语义。我们假设这种行为是通过 MAE 中丰富的隐藏表现方式发生的。我们希望这一观点将激励未来的工作。
Broader impacts. 该方法基于训练数据集的学习统计来预测内容,因此将反映这些数据中的偏见,包括那些具有负面社会影响的数据。模型可能生成不存在的内容。这些问题值得在此基础上进一步研究和考虑。( 做科研的同时也要关心社会问题! )
总结:该文章就是在 ViT 的基础上做了一些改进 1)mask 了大部分的 patches,以减少图像的冗余信息 2)加入了基于 Transformer 架构的 Decoder 来还原像素 3)加入了 ViT 后续工作的一些训练技巧,来提升模型的鲁棒性。