知识图谱整理
知识图谱架构图
-
通过外部网站或者公开数据集获取,三方机构API获取,机构的业务相关数据。
-
将数据存储到MYSQL数据库中,供后续使用。
-
通过Binlog实时处理增量导入NEO4J图数据库,或者直接通过mysql+apoc将数据库数据批量导入到NEO4J图数据库。
-
通过RestfulAPI直接提供图数据应用接口。或者将图数据通过SparkGraphX上搭建的一些算法模型处理后,再提供RestfulAPI接口。

图数据库的数据存储形式

图数据的特点:
-
包含节点、属性和关系。
-
节点的属性以键值对形式存储,节点可以有多个类别标签,一个实体上可以拥有多个标签。
-
关系有方向也有属性,关系也可以有多个类别标签。
APOC将数据库写入NEO4J
直接同步数据库信息到neo4j中!!!
安装APOC
apoc-3.4.0.3-all.jar、mysql-connector-java-5.1.21.jar 两个jar包,放到NEO4J的plugins目录下。
APOC功能

APOC数据集成-JDBC
APOC JDBC概念
apoc.load.jdcb:可以访问提供JDBC驱动程序的数据库,并执行查询。其将结果变成以一行数据为单位的数据流,然后可以使用这些行来更新或创建图形数据结构。
APOC JDBC语法
call
apoc.load.jdbc("jdbc:mysql://{ip}:{port}/{dbname}?user={username}&password={password}","{tablename}") yield row
create
(b:Black{number:row.black_id, type:row.type})
这是一行代码,返回row后接着跟一个cypher语句创建Black实体。yield row语句返回的是数据库中每行的数据,使用 row. 来调用每一行中的具体字段。后面通过 create 创建实体,row. 来获取前面的数据库字段作为实体的属性。
NEO4J基本操作
## 新建
# 新建实体
create (p:person{name:'jason',age:30}) return p
# create不管有没有关系都会新增关系
MATCH (p:person),(d:dog) CREATE (p)-[l:love]->(d) return p,l,d # 实体之间新建关系,
# merge有则返回,无则新增
MATCH (p:person),(d:dog) merge (p)-[l:love]->(d) return p,l,d
删除
# 必须先删除关系后才能删除实体
match (n:person{name:'jason'})-[l:love]->(d:dog) delete l # 删除关系
match (n:person{name:'jason'}) delete n # 删除实体
修改
match (t:tiger) set t:labelA return t # 修改标签类别
match (n:person) set n.name='jason' # 修改实体属性
match (n:person{name:'jason'})-[l:love]->(m:person{name:'uk'}) set l.time='1989' return n,l,m # 修改关系的属性
查询
基本查询
普通查询:查询jason拥有的电话号码
match (n:person)-[:has_phone]->(p:phone) where n.name='jason' return n,p limit 20
查询关系:查询10个为call的关系
match p=()-[c:call]->() return p limit 10
正则查询:查询10个以jason开头的人名
match (n:person) where n.name=~'jason.*' return n limit 10
包含查询:查询10名字中包含“j”的人名
match (n:person) where n.name contains 'j' return n limit 10
复杂查询
三度内朋友关系实体查询:
match (p:person)-[:friend]-(p1:person)-[:friend]-(p2:person) where p.name='jason' return p,p1,p2
三度内所有有关系的实体查询:
match (p:person)-[]-(p1:person)-[]-(p2:person) where p.name='jason' return p,p1,p2
所有与jason通话的电话查询:
match (n:person)-[:has_phone]->(p:phone)-[:call]-(p1:phone) where n.name='jason' return n,p,p1
最短路径查询:10度范围内查询p1到p2最短路径
match (p1:person{name:'jason'}),(p2:person{name:'leo'}) p=shortestpath((p1)-[*..10]-(p2)) return p1,p2
# 所有最短路径查询!!!
match (p1:person{name:'jason'}),(p2:person{name:'leo'}) p=allshortestpaths((p1)-[*..10]-(p2)) return p1,p2
申请人之前有多少个逾期进件:
match (p:person)-[h:has_application]->(a:application) where a.status='over_due' and p.personid='23001' return count(a)
申请人的1度关系中有多少触碰黑名单:
match (p:person)-[]-(p1:person)-[h:has_phone]-(b:black) where p.personid='23001' return count(b)
申请人的2度关系中有多少个触碰黑名单:
match (p:person)-[]-(p1:person)-[]-(p2:person)-[:has_phone]-(b:black) where p.personid='23001' return count(b)
索引
所有索引都是建立在属性之上!!!
create index on <标签名称>(属性名称)
create index on :person(name) # 创建索引
drop index on :person(name) # 删除索引
添加唯一约束条件
create constraint on (p:person) assert p.name is unique # 创建唯一约束
drop constraint on (p:person) assert p.name is unique # 删除唯一约束
Orientdb 基本操作
连接数据库
from pyorient.ogm import Config, Gragph config = Config.from_url(server, user, pwd) g = Graph(config)
构造schema类
Node = declarative_node() # 节点 Relationship = declarative_relationship() # 边(关系) # 定义节点类,继承Node;定义关系时,继承Relationship class OrientdbFile(Node): element_type = 'file' # 表名 element_plural = 'files' # 复数形式 file_id = Integer(nullable=False, unique=True) emp_no = Integer(nullable=True, unique=False) file_type = String(nullable=True, unique=False)
-
初始化schema
g.create_all(Node.registry) # 创建节点 g.create_all(Relationship.registry) # 创建边 -
绑定schema
若orientdb中已存在表,则只需要绑定相应的表即可。
-
from class
g.include(Node.registry) # 绑定节点 g.include(Relationship.registry) # 绑定边 -
from schema
classes_from_schema = graph.build_mapping( Node, Relationship, auto_plural = True) # Initialize Schema in PyOrient graph.include(classes_from_schema)
-
插入数据
orientdb里,一条记录可以认为是表对象的一个实例。插入记录即新建一个对象实例。有两种方式实现。
-
使用broker
g.persons.create(id="1", name="张三")p = {"id": "2", "name": "李四"} Person.objects.create(**p) -
原生方式
p = {"id": "3", "name": "王五"} g.create_vertex(Person, **p)
查询数据
-
方式一
result = g.persons.query().all() for p in result: print(p.id, p.name)1 张三 2 李四 3 王五 -
方式二
result = g.query(Person).all() for p in result: print(p.id, p.name)1 张三 2 李四 3 王五 -
filter
result = g.persons.query(name='张三').all()result = g.query(Person).filter(Person.name == "'张三'").all() # 备注:张三内层同样需要用引号包裹起来,源代码的问题,所以建议使用上面方式。
修改数据
pyorient的ogm本身并没有实现update功能,可以简单通过删除后插入实现修改功能。
ps = g.persons.query(name='张三').all()
for p in ps:
g.delete_vertex(Person, {"name": "张三"})
p_dict = dict(name=p.name, id=p.id)
p_dict.update({"name": "张麻子"})
g.create_vertex(Person, **p_dict)
result = g.persons.query().all()
for p in result:
print(p.id, p.name)
2 李四
3 王五
1 张麻子
删除数据
p_dict = {"name": "张三"}
g.delete_vertex(Person, **p_dict)
batch批量处理
批量操作
batch = g.batch()
for i in range(5, 10):
batch['f' + str(i)] = batch.persons.create(name='name' + str(1), id=i)
batch.commit()
result = g.persons.query().all()
for r in result:
print(r.name, r.id)
李四 2
name1 5
王五 3
name1 6
张麻子 1
name1 7
name1 8
name1 9
备注:
-
batch的key不能为纯数字,例如batch[‘12’],当然,batch[12]更不行。报错timeout,不解释。
-
batch的key必需明确,否则会不提交到库。
batch = g.batch() for i in range(10, 11): batch.persons.create(name='name' + str(1), id=i) batch.commit() result = g.persons.query(id=10).all() for r in result: print(r.name, r.id)并没有任何输出,表明,记录并没有正确提交。
搭建风控算法
风控算法流程
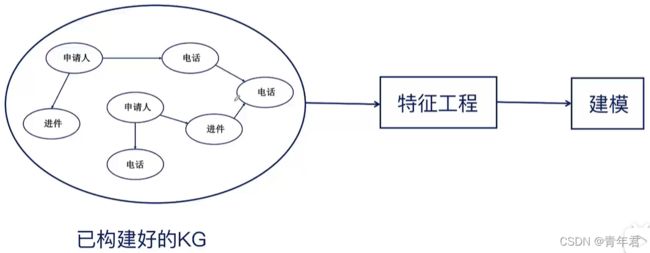
特征工程
-
申请人相关特征:年龄、收入、工作性质等等。
-
从知识图谱提取(与关系网络强相关):
(1)按照申请规则提取出来的特征,可以看做(2)提取出来特征的特例(规则结论只有两种,1或0)
a. 申请人是否第一次借款。
b. 申请人的朋友之前是否有过逾期。
(2)直接提取出来的特征(知识图谱提取的数据型特征)
a. 申请人2度关系内多少个黑名单节点。
b. 申请人电话记录里面12点到凌晨2点的记录占比。
模型搭建
逻辑回归、GBDT(最为常见)、SVM、神经网络
模型评估
准确率、AUC、ROC曲线、KS值
逻辑回归
主要用在二分类问题上!!!逻辑回归也是一个线性分类器!!!
线性分类器
逻辑回归做二分类时候,两种概率表示为:
p ( y = 1 ∣ x , w ) = 1 1 + e − w T x + b p ( y = 0 ∣ x , w ) = e − w T x + b 1 + e − w T x + b p(y=1|x,w) = \frac{1}{1+e^{-w^{T}x+b}} \\ p(y=0|x,w) = \frac{e^{-w^{T}x+b}}{1+e^{-w^{T}x+b}} p(y=1∣x,w)=1+e−wTx+b1p(y=0∣x,w)=1+e−wTx+be−wTx+b
逻辑回归的决策边界线,为两种概率相同的点的集合。可以推导出以下的式子:
p ( y = 0 ∣ x , w ) p ( y = 1 ∣ x , w ) = 1 e − w T x + b = 1 − w T x + b = l n 1 w T x + b = 0 \frac{p(y=0|x,w)}{p(y=1|x,w)} =1 \\ e^{-w^{T}x+b} =1 \\ -w^{T}x+b =ln1 \\ w^{T}x+b = 0 p(y=1∣x,w)p(y=0∣x,w)=1e−wTx+b=1−wTx+b=ln1wTx+b=0
所以逻辑回归的决策边界线为 w T x + b = 0 w^{T}x+b = 0 wTx+b=0,为线性决策边界线。所以逻辑回归是一个线性分类器。
目标函数
定义好的条件概率:
p ( y ∣ x , w ) = p ( y = 1 ∣ x , w ) y [ 1 − p ( y = 1 ∣ x , w ) ] 1 − y p(y|x,w)=p(y=1|x,w)^y[1-p(y=1|x,w)]^{1-y} p(y∣x,w)=p(y=1∣x,w)y[1−p(y=1∣x,w)]1−y
相当于越理想的模型,预测出来的条件概率值就会越大,完全拟合的最优模型的概率值为1。
假设拥有数据集: D = { ( x i , y i ) } , i ∈ ( 1 , n ) D={\{(x_i,y_i)\}},i\in(1,n) D={(xi,yi)},i∈(1,n), x i ∈ R d x_i\in R^d xi∈Rd特征值, y i ∈ { 0 , 1 } y_i \in \{0,1\} yi∈{0,1}
只需要求得每个数据的概率积最大,那么就是最优。所以目标函数定义为:
w ^ M L E , b ^ M L E = a r g m a x w , b ∏ i = 0 n p ( y i ∣ x i , w , b ) a r g m a x w , b 意 思 为 : 让 右 边 积 最 大 化 的 参 数 w , b \hat{w}_{MLE},\hat{b}_{MLE}=argmax_{w,b}\prod_{i=0}^np(y_i|x_i,w,b) \\ argmax_{w,b}意思为:让右边积最大化的参数w,b w^MLE,b^MLE=argmaxw,bi=0∏np(yi∣xi,w,b)argmaxw,b意思为:让右边积最大化的参数w,b
化简目标函数:求区间积最大,通过 l o g log log函数将其转化为求和最大!!!
w ^ M L E , b ^ M L E = a r g m a x w , b ∏ i = 0 n p ( y i ∣ x i , w , b ) → a r g m a x w , b ∑ i = 0 n l o g ( p ( y i ∣ x i , w , b ) ) → a r g m i n w , b − ∑ i = 0 n l o g p ( y i ∣ x i , w , b ) → a r g m i n w , b − ∑ i = 0 n l o g p ( y i = 1 ∣ x , w , b ) + ( 1 − y ) l o g ( 1 − p ( y i = 1 ∣ x , w , b ) ) \hat{w}_{MLE},\hat{b}_{MLE}=argmax_{w,b}\prod_{i=0}^np(y_i|x_i,w,b) \\ →argmax_{w,b}\sum_{i=0}^n log (p(y_i|x_i,w,b))→argmin_{w,b}-\sum_{i=0}^n log p(y_i|x_i,w,b) \\ →argmin_{w,b}-\sum_{i=0}^n log p(y_i=1|x,w,b)+(1-y)log (1-p(y_i=1|x,w,b)) w^MLE,b^MLE=argmaxw,bi=0∏np(yi∣xi,w,b)→argmaxw,bi=0∑nlog(p(yi∣xi,w,b))→argminw,b−i=0∑nlogp(yi∣xi,w,b)→argminw,b−i=0∑nlogp(yi=1∣x,w,b)+(1−y)log(1−p(yi=1∣x,w,b))
最优化问题
凸函数:凸函数有全局最优解。
非凸函数:只能求得局部最优解,但是可以通过多次训练来求得效果最好的一组解。
逻辑回归梯度下降法
一般通用
求使得 f ( w ) f(w) f(w)值最小的参数w:
- 初始化 w 1 w^1 w1;
- for t=1,2,3…:
- t+1时刻的w,等于t时刻的w- η \eta η*t时刻的导数值 ∇ f ( w t ) \nabla f(w^t) ∇f(wt) , w t + 1 = w t − η ∇ f ( w t ) w^{t+1}=w^t-\eta \nabla f(w^t) wt+1=wt−η∇f(wt)
逻辑回归梯度下降法:
- 初始化 w 1 w^1 w1, b 1 b^1 b1
- for t=1,2,3…:
- 目 标 函 数 对 w 求 导 后 得 : w t + 1 = w t − η ∑ i = 0 n [ σ ( w t x + b ) − y ] x , n 为 每 个 样 本 目标函数对w求导后得:w^{t+1}=w^t-\eta \sum_{i=0}^n[\sigma(w^tx+b)-y]x,n为每个样本 目标函数对w求导后得:wt+1=wt−η∑i=0n[σ(wtx+b)−y]x,n为每个样本
目 标 函 数 对 b 求 导 后 得 : b t + 1 = b t − η ∑ i = 0 n [ σ ( w t x + b ) − y ] , n 为 每 个 样 本 目标函数对b求导后得:b^{t+1}=b^t-\eta \sum_{i=0}^n[\sigma(w^tx+b)-y],n为每个样本 目标函数对b求导后得:bt+1=bt−η∑i=0n[σ(wtx+b)−y],n为每个样本
逻辑回归随机梯度下降法
随机梯度下降(SGD)多用用于支持向量机、逻辑回归等凸损失函数下的线性分类器的学习。并且SGD已成功应用于文本分类和自然语言处理中经常遇到的大规模和稀疏机器学习问题。
- 初始化 w 1 w^1 w1, b 1 b^1 b1
- for t=1,2,3…:
- 每次随机选定一个样本 ( x i , y i ) (x^i,y^i) (xi,yi)参数进行更新: w t + 1 = w t − η ∑ i = 0 n [ σ ( w t x i + b ) − y i ] x i w^{t+1}=w^t-\eta \sum_{i=0}^n[\sigma(w^tx^i+b)-y^i]x^i wt+1=wt−η∑i=0n[σ(wtxi+b)−yi]xi
b t + 1 = b t − η ∑ i = 0 n [ σ ( w t x i + b ) − y i ] b^{t+1}=b^t-\eta \sum_{i=0}^n[\sigma(w^tx^i+b)-y^i] bt+1=bt−η∑i=0n[σ(wtxi+b)−yi]
微服务
微服务架构是一种架构模式,提倡单一应用划分成一组小的服务,每个服务运行在其独立的进程中,服务间采用轻量级的通信机制互相沟通,通常是基于HTTP协议的RESTful API。
组件化:可将错误隔离,某一组件出现问题,不影响其他组件。
弹性架构:按需伸缩,根据不同的业务并发进行扩展。
去中心化:可以独立测试和部署。
快速响应:单一模块的BUG修复、打包、测试和上线的时间周期少。
规则存储
-
存储到数据库中
优点:更新规则的时候不需要修改代码。
缺点:每次规则读取都需要一次数据库交互。
-
写在程序的配置文件中
优点:读取的速度会比数据库快。
缺点:修改规则时候需要修改代码。
规则开发
将cypher语句存储到数据库中,每次需要的时候就去查询语句,然后执行。
-
申请人之前有多少个逾期的进件。
match (p:Person)-[h:HAS_APPLICATION]->(a:Application) where a.status="OVER_DUE" and p.personId="243001" return count(a) -
申请人的一度关系中有多少个触碰黑名单。
match (p:Person)-[]-(p1:Person)-[h:HAS_PHONE]-(b:Black) where p.personId="243010" return count(b)match (p:Person)-[]-(p1:Person)-[h:HAS_PHONE]-(b:Black) where p.personId=$personId return count(b) //用$personId进行传值 -
申请人的二度关系中有多少个触碰黑名单。
match (p:Person)-[]-(p1:Person)-[]-(p2:Person)-[h:HAS_PHONE]-(b:Black) where p.personId="243010" return count(b)
规则引擎开发
运用spring-bootj进行引擎开发。
pom文件配置
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0modelVersion>
<groupId>org.examplegroupId>
<artifactId>RuleEngineServerartifactId>
<version>1.0-SNAPSHOTversion>
<parent>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-parentartifactId>
<version>2.3.2.RELEASEversion>
parent>
<dependencies>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-webartifactId>
<version>2.3.2.RELEASEversion>
dependency>
<dependency>
<groupId>io.springfoxgroupId>
<artifactId>springfox-swagger2artifactId>
<version>3.0.0version>
dependency>
<dependency>
<groupId>io.springfoxgroupId>
<artifactId>springfox-swagger-uiartifactId>
<version>3.0.0version>
dependency>
<dependency>
<groupId>org.projectlombokgroupId>
<artifactId>lombokartifactId>
<version>1.18.12version>
dependency>
<dependency>
<groupId>mysqlgroupId>
<artifactId>mysql-connector-javaartifactId>
dependency>
<dependency>
<groupId>org.neo4j.drivergroupId>
<artifactId>neo4j-java-driverartifactId>
<version>4.4.5version>
dependency>
dependencies>
project>
入口文件
package com.jason.ai;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.scheduling.annotation.EnableScheduling;
@EnableScheduling // 这两个标签表明这是入口文件
@SpringBootApplication
public class Application {
public static void main(String[] args) {
SpringApplication.run(Application.class, args);
}
}
Swagger配置
package com.jason.ai.config;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import springfox.documentation.builders.ApiInfoBuilder;
import springfox.documentation.builders.PathSelectors;
import springfox.documentation.service.ApiInfo;
import springfox.documentation.service.Contact;
import springfox.documentation.spi.DocumentationType;
import springfox.documentation.spring.web.plugins.Docket;
import springfox.documentation.swagger2.annotations.EnableSwagger2;
@Configuration
@EnableSwagger2
public class SwaggerConfig {
// 明确接口的规范,定义哪些暴露在外面可以访问!
@Bean
public Docket api() {
return new Docket(DocumentationType.SWAGGER_2)
.apiInfo(apiInfo())
.pathMapping("/")
.select()
.paths(PathSelectors.regex("/.*"))
.build();
}
private ApiInfo apiInfo() {
return new ApiInfoBuilder().title("Knowledge Graph Rule Engine Service API.")
.contact(new Contact("ZhuJun", "", "[email protected]"))
.description("Knowledge Graph Rule Engine Service API.")
.version("1.0")
.build();
}
}
kafka消息队列
Producer API:允许应用程序发布的记录流至一个或多个kafka的Topic
Consumer API:允许应用程序订阅一个或多个Topic,并处理他们记录的数据流。
Streams API:允许应用程序充当流处理器,从一个或多个主题消费输入流,并产生一个输出流至一个或多个输出的主题,有效的变换输入流和输出流。
Connector API:可以构建和允许kafka Topic连接到现有的应用程序或数据系统中重用生产者或消费者。例如,关系数据库的连接器可能捕捉每个对表的更改。
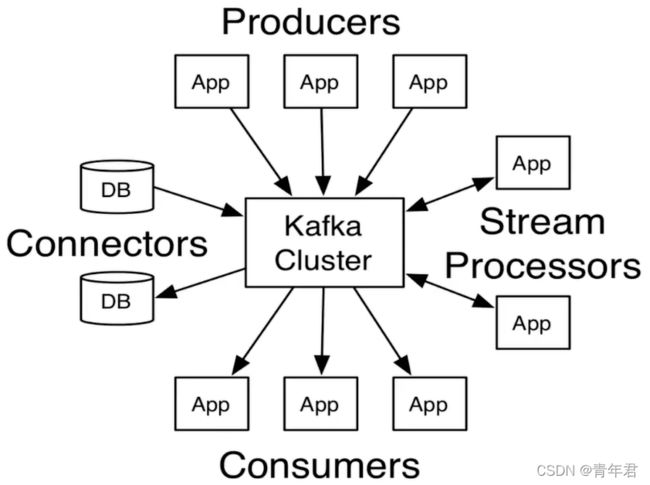
kafka单点环境部署
- 启动zookeeper服务,集群调度通过zookeeper管理。bin/zookeeper-server-start.sh config/zookeeper.properties
- 启动kafka服务。bin/kafka-server-start.sh config/server.properties
- 创建topic。bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic my_test
- 查看topic列表。bin/kafka-topics.sh --list --zookeeper localhost:2181
- 启动生产者。bin/kafka-console-producer.sh --broker-list localhost:9092 --topic my_test
- 启动消费者。bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic my_test --from-beginning
kafka集群环境部署
主要是进行多备份,当其中一些节点死掉后,也能保证消息不丢失。
-
启动zookeeper服务,集群调度通过zookeeper管理。bin/zookeeper-server-start.sh config/zookeeper.properties
-
设置zookeeper集群地址,以","为分割。zookeeper.connect=172.16.150.154:2181,172.16.150.155:2181,172.16.150.156:2181
-
拷贝config/server.properties配置文件,集群几个点就拷贝几份。cp config/server.properties config/server-1.properties
-
修改每个拷贝的文件server-1.properties,确保每个节点不一样。
(a)broker.id=0 改为 broker.id=1
(b)listeners=PLAINTEXT://:9092 改为 listeners=PLAINTEXT://:9093
(c)log.dirs=/tmp/kafka-logs 改为 log.dirs=/tmp/kafka-logs-1
-
启动拷贝出来的服务。bin/kafka-server-start.sh config/server-1.properties
-
创建一个topic,几个节点factor就是几。bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 2 --partitions 1 --topic jason-topic
-
查看topic介绍信息。bin/kafka-topic.sh --describe --zookeeper localhost:2181 --topic jason-topic
其中Leader:1,表示1号为leader,当leader被杀死后,zookeeper会自动维护换到其他节点作为leader;Replicas:1,2,0表明1位leader,总体是全部复制品服务节点;Isr:1,2,0表示
-
启动生产者。bin/kafka-console-producer.sh --broker-list localhost:9092 --topic jason-topic
-
启动消费者。bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic jason-topic --from-beginning
java API消费者
POM文件
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0modelVersion>
<groupId>org.examplegroupId>
<artifactId>kafkaDemoartifactId>
<version>1.0-SNAPSHOTversion>
<properties>
<maven.compiler.source>8maven.compiler.source>
<maven.compiler.target>8maven.compiler.target>
properties>
<dependencies>
<dependency>
<groupId>org.apache.kafkagroupId>
<artifactId>kafka-clientsartifactId>
<version>2.2.0version>
dependency>
dependencies>
project>
消费者
package com.jason.ai.kafka;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import java.time.Duration;
import java.util.Arrays;
import java.util.Properties;
public class ConsumerDemo {
public static void main(String[] args) {
Properties pros = new Properties();
pros.put("bootstrap.servers", "localhost:9092"); // 集群主服务地址!!!
pros.put("group.id", "test"); // 用来标识consumer进程所在组的字符串,如果设置同一个group id,表示这些进程属于同一个consumer group
pros.put("enable.auto.commit", "true"); //如果设置为true,consumer所接受到消息的offset将会自动同步到zookeeper中。
pros.put("auto.commit.interval.ms", "1000"); //消费者向zookeeper提交offset的频率,单位是秒
pros.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
pros.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(pros);
consumer.subscribe(Arrays.asList("my_test"));
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofSeconds(1));
for (ConsumerRecord<String, String> record : records) {
System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value());
}
}
}
}
生产者
package com.jason.ai.kafka;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.Producer;
import org.apache.kafka.clients.producer.ProducerRecord;
import java.util.Properties;
public class ProducerDemo {
public static void main(String[] args) {
Properties prop = new Properties();
prop.put("bootstrap.servers", "localhost:9092");
prop.put("acks", "all"); // 生产者需要server接收到数据之后,发出一个确认接收的信号。
// 0 producer不需要等待确认消息。 1 至少要等待leader已经成功将数据写入本地log,并不意味着所有节点已经写入。
// all 意味着leader需要等待所有的节点都已成功写入日志中。
prop.put("retries", 0); //重试次数,会改变消息的顺序。
prop.put("buffer.memory", 335544); // 消息内存大小
prop.put("batch.size", 16384); // 批处理消息,减少请求次数。如果为0,就是禁用批处理,如果太大,消息就会堆积在内存中,占用内存空间。
prop.put("linger.ms", 1);
prop.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
prop.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
Producer<String, String> producer = new KafkaProducer<String, String>(prop);
for (int i = 0; i < 100; i++) {
// 吃传输key,value值
producer.send(new ProducerRecord<String, String>("my_test", Integer.toString(i + 1), Integer.toString(i)));
}
producer.close();
}
}
canal将改变数据同步
canal可以很方便地同步数据库的增量数据到其他的存储应用。
链接:https://github.com/alibaba/canal/wiki/QuickStart
准备工作
对于自建 MySQL , 需要先开启 Binlog 写入功能,配置 binlog-format 为 ROW 模式,my.cnf 中配置如下
[mysqld]
log-bin=mysql-bin # 开启 binlog
binlog-format=ROW # 选择 ROW 模式
server_id=1 # 配置 MySQL replaction 需要定义,不要和 canal 的 slaveId 重复
授权 canal 链接 MySQL 账号具有作为 MySQL slave 的权限, 如果已有账户可直接 grant
CREATE USER canal IDENTIFIED BY 'canal';
GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'canal'@'%';
-- GRANT ALL PRIVILEGES ON *.* TO 'canal'@'%' ;
FLUSH PRIVILEGES;
下载canal:
wget https://github.com/alibaba/canal/releases/download/canal-1.1.5/canal.deployer-1.1.5.tar.gz
解压canal:
tar -zxvf canal.deployer-1.1.1.tar.gz -C canal // -C解压到指定目录里
修改配置:
vi conf/example/instance.properties
## mysql serverId
canal.instance.mysql.slaveId = 1234
#position info,需要改成自己的数据库信息
canal.instance.master.address = 127.0.0.1:3306 // ip信息
canal.instance.master.journal.name =
canal.instance.master.position =
canal.instance.master.timestamp =
#canal.instance.standby.address =
#canal.instance.standby.journal.name =
#canal.instance.standby.position =
#canal.instance.standby.timestamp =
#username/password,需要改成自己的数据库信息
canal.instance.dbUsername = jason // 改为自己的用户名
canal.instance.dbPassword = 112233 // 改为自己的密码
canal.instance.defaultDatabaseName = test //数据库名称
canal.instance.connectionCharset = UTF-8
#table regex
canal.instance.filter.regex = .\*\\\\..\* # 过滤哪些库和表能够被canal监听!!!
启动:
bin/startup.sh
java使用canal
导入canal依赖包
<dependency>
<groupId>com.alibaba.ottergroupId>
<artifactId>canal.clientartifactId>
<version>1.1.0version>
dependency>
连接池打开,然后进入bin目录后,重启canal服务:./restart.sh
canal.instance.parser.parallelThreadSize = 16 // 将这个取消注释!!!
java使用canal客户端代码
package com.alibaba.otter.canal.sample;
import java.net.InetSocketAddress;
import java.util.List;
import com.alibaba.otter.canal.client.CanalConnectors;
import com.alibaba.otter.canal.client.CanalConnector;
import com.alibaba.otter.canal.common.utils.AddressUtils;
import com.alibaba.otter.canal.protocol.Message;
import com.alibaba.otter.canal.protocol.CanalEntry.Column;
import com.alibaba.otter.canal.protocol.CanalEntry.Entry;
import com.alibaba.otter.canal.protocol.CanalEntry.EntryType;
import com.alibaba.otter.canal.protocol.CanalEntry.EventType;
import com.alibaba.otter.canal.protocol.CanalEntry.RowChange;
import com.alibaba.otter.canal.protocol.CanalEntry.RowData;
public class SimpleCanalClientExample {
public static void main(String args[]) {
// 创建链接
// 修改!!!加入自己的IP地址
CanalConnector connector = CanalConnectors.newSingleConnector(new InetSocketAddress("127.0.0.1",
11111), "example", "", "");
int batchSize = 1000;
int emptyCount = 0;
try {
connector.connect();
connector.subscribe(".*\\..*");
connector.rollback();
int totalEmptyCount = 120;
while (emptyCount < totalEmptyCount) {
Message message = connector.getWithoutAck(batchSize); // 获取指定数量的数据
long batchId = message.getId();
int size = message.getEntries().size();
if (batchId == -1 || size == 0) {
emptyCount++;
System.out.println("empty count : " + emptyCount);
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
}
} else {
emptyCount = 0;
// System.out.printf("message[batchId=%s,size=%s] \n", batchId, size);
printEntry(message.getEntries());
}
connector.ack(batchId); // 提交确认
// connector.rollback(batchId); // 处理失败, 回滚数据
}
System.out.println("empty too many times, exit");
} finally {
connector.disconnect();
}
}
private static void printEntry(List<Entry> entrys) {
for (Entry entry : entrys) {
if (entry.getEntryType() == EntryType.TRANSACTIONBEGIN || entry.getEntryType() == EntryType.TRANSACTIONEND) {
continue;
}
RowChange rowChage = null;
try {
rowChage = RowChange.parseFrom(entry.getStoreValue());
} catch (Exception e) {
throw new RuntimeException("ERROR ## parser of eromanga-event has an error , data:" + entry.toString(),
e);
}
EventType eventType = rowChage.getEventType();
System.out.println(String.format("================> binlog[%s:%s] , name[%s,%s] , eventType : %s",
entry.getHeader().getLogfileName(), entry.getHeader().getLogfileOffset(),
entry.getHeader().getSchemaName(), entry.getHeader().getTableName(),
eventType));
for (RowData rowData : rowChage.getRowDatasList()) {
if (eventType == EventType.DELETE) {
printColumn(rowData.getBeforeColumnsList());
} else if (eventType == EventType.INSERT) {
printColumn(rowData.getAfterColumnsList());
} else {
System.out.println("-------> before");
printColumn(rowData.getBeforeColumnsList());
System.out.println("-------> after");
printColumn(rowData.getAfterColumnsList());
}
}
}
}
private static void printColumn(List<Column> columns) {
for (Column column : columns) {
System.out.println(column.getName() + " : " + column.getValue() + " update=" + column.getUpdated());
}
}
}
canal消息发送到kafka中
修改canal配置文件
修改vi conf/example/instance.properties
# 按需修改成自己的数据库信息
#################################################
...
canal.instance.master.address=192.168.1.20:3306
# username/password,数据库的用户名和密码
...
canal.instance.dbUsername = canal
canal.instance.dbPassword = canal
...
# mq config
canal.mq.topic=example // 队列名字为example
# 针对库名或者表名发送动态topic
#canal.mq.dynamicTopic=mytest,.*,mytest.user,mytest\\..*,.*\\..*
canal.mq.partition=0 // 0才生效!!!
# hash partition config
#canal.mq.partitionsNum=3 // 多分区时候,就在这里改正!!!
#库名.表名: 唯一主键,多个表之间用逗号分隔
#canal.mq.partitionHash=mytest.person:id,mytest.role:id
#################################################
修改vi /usr/local/canal/conf/canal.properties
# ...
# 可选项: tcp(默认), kafka, RocketMQ
canal.serverMode = kafka // 改成kafka
# ...
修改集群信息
# kafka/rocketmq 集群配置: 192.168.1.117:9092,192.168.1.118:9092,192.168.1.119:9092
// mq.yml修改集群地址
canal.mq.servers = 127.0.0.1:6667 // 改成集群地址
canal.mq.retries = 0
# flagMessage模式下可以调大该值, 但不要超过MQ消息体大小上限
canal.mq.batchSize = 16384
canal.mq.maxRequestSize = 1048576
# flatMessage模式下请将该值改大, 建议50-200
canal.mq.lingerMs = 1
canal.mq.bufferMemory = 33554432
# Canal的batch size, 默认50K, 由于kafka最大消息体限制请勿超过1M(900K以下)
canal.mq.canalBatchSize = 50
# Canal get数据的超时时间, 单位: 毫秒, 空为不限超时
canal.mq.canalGetTimeout = 100
# 是否为flat json格式对象
canal.mq.flatMessage = false
canal.mq.compressionType = none
canal.mq.acks = all
# kafka消息投递是否使用事务
canal.mq.transaction = false
启动canal服务:bin/startup.sh;启动zookeeper服务:bin/zookeeper-server-start.sh config/zookeeper.properties;启动kafka服务:bin/kafka-server-start.sh config/server.properties;启动消费者:bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic example --from-beginning
拼写纠错
用户输入,生成编辑距离为1或者2的可能字符串,然后通过建立的词典库进行过滤,对过滤后的词用语言模型进行排序,最后选出最合适的单词。
编辑距离
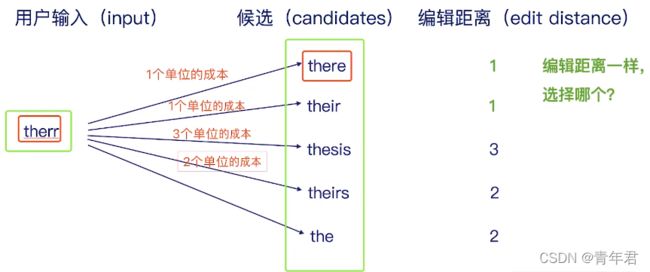
计算编辑距离
动态规划(DP):将一个大问题拆解成几个子问题,通过子问题的答案来回答大问题。
假设有字符串 S S S与字符串 T T T,长度分别为 M , N M,N M,N。 D P [ i , j ] DP[i,j] DP[i,j]表示计算S与T子串的编辑距离。
D P [ i , j ] DP[i,j] DP[i,j]分为以下情况:
-
最后字符相等情况,即 S i = T i S_i=T_i Si=Ti,这时 D P [ i , j ] = D P [ i − 1 , j − 1 ] DP[i,j]=DP[i-1,j-1] DP[i,j]=DP[i−1,j−1]。
-
最后字符串不相等情况,又分为:
(a) S i S_i Si比 T i T_i Ti短,那么就需要增加一个字符。
(b) S i S_i Si比 T i T_i Ti长,那么久减少一个字符。
(c) S i S_i Si与 T i T_i Ti同样长短,那么就需要进行一次替换。

实现代码如下:
def edit_distance(str1, str2):
"""
计算两个字符串之间的编辑距离
:param str1:字符串一
:param str2:字符串二
"""
m, n = len(str1), len(str2)
# base case多了一个维度,所以是n+1 * m+1
dp = [[0 for x in range(n + 1)] for x in range(m + 1)]
for i in range(m + 1):
for j in range(n + 1):
# 假设第一个字符串为空,那么编辑距离就是第二个字符串长度
if i == 0:
dp[i][j] = j
# 第二个字符串为空,那么编辑距离就是第一个字符串长度
elif j == 0:
dp[i][j] = i
# 如果两个字符串最后相同,那么编辑距离就等同于子穿的编辑距离
elif str1[i - 1] == str2[j - 1]:
dp[i][j] = dp[i - 1][j - 1]
# 如果最后一个字符不一样,那么就是添加、减少、修改这三种的最小编辑距离
else:
dp[i][j] = 1 + min(dp[i][j - 1], # 添加
dp[i - 1][j], # 减少
dp[i - 1][j - 1]) # 替换
return dp[m][n]
生成指定编辑距离的单词
输入一个字符串,将字符串分为左右两个部分,然后根据编辑距离的三种方式(添加、删除、修改)生成编辑距离为1的字符串。
def generate_edit_one(str1):
"""
生成编辑距离为1的所有字符串列表
:param str1:输入字符串
"""
letters = "abcdefghijklmnopqrstuvxyz"
splits = [(str1[:i], str1[i:]) for i in range(len(str1) + 1)]
# 添加
inserts = [L + letter + R for L, R in splits for letter in letters]
# 删除
deletes = [L + R[1:] for L, R in splits if R]
# 修改
replaces = [L + letter + R[1:] for L, R in splits if R for letter in letters]
return set(inserts + deletes + replaces)
def generate_edit_two(str1):
"""
生成编辑距离不大于2的字符串
:param str1:输入字符串
"""
return [etwo for eone in generate_edit_one(str1) for etwo in generate_edit_one(eone)]
拼写纠错数学建模
问题定义:给定一个输入字符串S,我们要找出最有可能的修改后的字符串C。
抽象从函数: c ^ = a r g m a x P ( c ∣ s ) \hat c=argmax P(c|s) c^=argmaxP(c∣s)。
对于任何修改后的字符串 C C C,分母 P ( s ) P(s) P(s)都是一样给定的S。
P ( s ∣ c ) P(s|c) P(s∣c)表示:正确的是“apple”,被错写成为“appl”的概率。
P ( c ) P(c) P(c)表示:文本中出现“apple”这个单词的概率值。
c ^ = a r g m a x P ( c ∣ s ) = a r g m a x P ( s ∣ c ) ∗ P ( c ) / P ( s ) = a r g m a x P ( s ∣ c ) ∗ P ( c ) \hat c=argmax P(c|s) \\ =argmax P(s|c)*P(c)/P(s) \\ =argmax P(s|c)*P(c) c^=argmaxP(c∣s)=argmaxP(s∣c)∗P(c)/P(s)=argmaxP(s∣c)∗P(c)
分词
jieba分词
import jieba
jieba.add_word("贪心学院")
seg_list = jieba.cut("贪心学院专注于人工智能教育", cut_all=False)
停用词过滤
停用词列表要考虑自己的应用场景。
stemming(英文中)
利用语法规则将不同时态、单复数等单词进行合并。但是算法处理后的单词不一定是词库存在的单词。
java实现PorterStemmer算法:https://tartarus.org/martin/PorterStemmer/java.txt
通过NLTK库实现stemming算法:
from nltk.stem.porter import *
stemmer = PorterStemmer()
test_strs = ["caresses","flies","dies","died","owned","sized","itemization"]
singles = [stemmer.stem(word) for work in test_strs]
文本的表示
词向量
Glove训练词向量,垂直领域的词向量需要大量的文档进行专门训练。
欧式距离
距离越小相似度越高。
余弦相似度
值越大相似度越高。
余弦相似度计算文本相识度,分子是两个向量内积,分母是每个向量模的乘积。内积表示向量之间的相关性,内积越大越相关。
余 弦 相 似 度 : d = ( s 1 ∗ s 2 ) / ∣ s 1 ∣ ∗ ∣ s 2 ∣ 余弦相似度:d=(s_1 * s_2)/|s_1|*|s_2| 余弦相似度:d=(s1∗s2)/∣s1∣∗∣s2∣
命名实体识别
评价分类器
contingency table
| 预测正例 | 预测反例 | |
|---|---|---|
| 真实正例 | TP(真正例) | FN(假反例) |
| 真实反例 | FP(假正例) | TN(真反例) |
基于规则的命名实体识别
-
正则表达式提取:电话号码
-
基于已知的词典库:公司名(通过定义的前缀或后缀丰富词库)。
(1)先建立好词典库
(2)匹配:精确匹配、模糊匹配(规则、相识度算法(还可以利用前后文信息来更好计算))
基于模型的命名实体识别
先分词,再特征提取
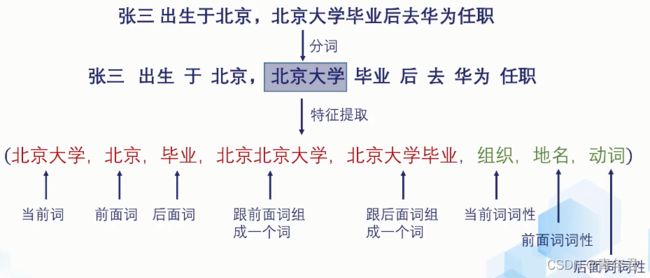
构造训练集

模型选择
时序模型:条件随机场、隐式马尔科夫模型、递归神经网络
时序无关模型:逻辑回归、支持向量机、最大熵模型
特征提取
步骤:文本——》提取特征:1.设计特征;2.转换成向量形式;3.特征选择。
- 当前词的特征:unigram单个词一组、bigram两个词一组。
- stemming:去除时态和前后缀等后的单词。
- 词性。
- 单词的前后缀。
- 当前词的特点:长度,是否大写,包含多少数字,是否包含大写字符。
- 句法、依存分析。
特征向量化
- 分类变量:独热编码。例子:小学、高中、大学(1,0,0)
- 数值变量:直接归一化(归一到[0,1],或者归一到正态分布中)处理,或者不做任何处理,然后作为特征向量。例子:身高、体重、气温。
- 顺序变量:四星好评(分等级)。处理方法与数值变量一样,或者独热编码处理。
MajorityVoting提取实体
- 统计每个单词最有可能被分成的实体类别。
- 给定一个新的单词时,把它分类成为这个类别。
import pandas as pd
from sklearn.base import BaseEstimator, TransformerMixin
from sklearn.metrics import classification_report
from sklearn.model_selection import cross_val_predict
data = pd.read_csv("./datas/ner_dataset.csv", encoding="latin1")
data = data.fillna(method="ffill")
class MajorityVotinTagger(BaseEstimator, TransformerMixin):
# 继承BaseEstimator, TransformerMixin,就能直接当做一个算法函数来使用。
def fit(self, x, y):
"""
:param x: list of words
:param y: list of tags
"""
self.tags = []
self.mjvote = {}
word2cnt = {}
for x, t in zip(x, y):
if t not in self.tags:
self.tags.append(t)
if x in word2cnt:
if t not in word2cnt[x]:
word2cnt[x][t] = 1
else:
word2cnt[x][t] += 1
else:
word2cnt[x] = {t: 1}
for k, v in word2cnt.items():
self.mjvote[k] = max(v, key=v.get)
def predict(self, x):
return [self.mjvote.get(w) for w in x]
words = data["Word"].values.tolist()
tags = data["Tag"].values.tolist()
assert len(words) == len(tags)
pred = cross_val_predict(estimator=MajorityVotinTagger(), X=words, y=tags, cv=5)
report = classification_report(y_pred=pred, y_true=tags)