关于yolov5训练后权重较大的原因及其解决方案
yolov5在官方预训练权重的基础之上再训练后权重较预训练权重大很多,为了大家更加直观的了解为什么及其解决方案,此篇简单介绍一下。
精度变化
官方给的预训练权重是FP16,而我们训练的时候是使用混合精度训练(支持CUDA才行),半精度训练只能在CUDA下进行,不支持CUDA默认是使用单精度训练,最终我们保存的权重是FP32,较FP16储存空间大了一倍。直接上代码视图:
import argparse
from models.common import *
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--weights', type=str, default='D:/py/test_FP/weights/yolov5s.pt', help='weights path')
opt = parser.parse_args()
# Load pytorch model
model = torch.load(opt.weights, map_location=torch.device('cpu'))['model']
for name, parameters in model.named_parameters():
# print(name,':',parameters.size())
print(parameters.dtype)
原始预训练权重
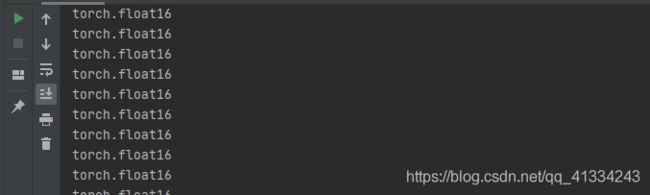
我们自己的训练权重

参数储存不同
预训练权重默认epoch=-1,不保存training_results,不保存optimizer,相当于只保存了模型和权重
ckpt = {'epoch': -1,
'best_fitness': model['best_fitness'],
'training_results': None,
'model': model['model'],
'optimizer': None}
可以用以下代码测试以下
import argparse
from models.common import *
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--weights', type=str, default='D:/py/test_FP/weights/yolov5s.pt', help='weights path')
opt = parser.parse_args()
# Load pytorch model
model = torch.load(opt.weights, map_location=torch.device('cpu'))
print(model)
![]()
![]()
我们训练的时候是默认都保存,源码设置的是在最后一个批次不保存optimizer,如果你是正常跑完所有epoch,最后的权重应该是不包含optimizer,否则会自动保存,以下是官方train.py的保存权重的部分代码
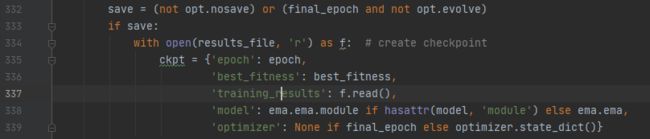
所以我们自己训练出来的模型权重文件比较大是必然的
那问题来了,如果想让权重文件变小怎么办
[注]小编此处使用的权重是基于yolov5s预训练权重训练后的结果,且未在批次执行完就停止,也就是这个权重默认是包含以下这么多信息,内容较多,暂且用省略号表示
ckpt = {'epoch': .....,
'best_fitness': ......,
'training_results': .......,
'model': ......,
'optimizer': ......}
初始大小为:57M
![]()
现在我一步步来让这个权重变小
step1
第一步按照以下内容进行,为什么epoch变成-1,官方权重设置的epoch为-1,作为预训练权重,批次从0开始,如果仅作为inference权重,这个不影响;接着是把training_results变为None
ckpt = {'epoch': -1,
'best_fitness': model['best_fitness'],
'training_results': None,
'model': model['model'],
'optimizer': model['optimizer']}
我们按照以上内容把权重文件重新保存以下看看大小变化多少,如下图所示,发现这个training_results占的内存很少,基本可以忽略不计:
![]()
step2
第二步按照以下内容执行,相比第一步,只是把optimizer参数变成None
ckpt = {'epoch': -1,
'best_fitness': model['best_fitness'],
'training_results': None,
'model': model['model'],
'optimizer': None}
这次权重又有多大变化呢,如下图所示,发现这个optimizer占的内存很多,大致占了权重文件的一般大小,说明优化器的参数是导致文件较大的主谋:
![]()
step3
可是权重文件还是很大,比原始的yolov3s大了一倍,这是因为目前的权重还是FP32,需要把FP32转为FP16,此处根据个人情况来决定是否转为FP16,小编不才,此处使用暴力方法直接把FP32转FP16(使用half函数),如下图,权重小了一倍,基本和yolov3s大小差不多。
![]()
以下把代码附上,很简单
import argparse
import numpy as np
import torch
from models.common import *
if __name__ == '__main__':
weights_path = 'D:/py/test_FP/weights/last.pt'
is_half = True
# Load pytorch model
model = torch.load(weights_path, map_location=torch.device('cpu'))
net = model['model']
if is_half:
net.half() # 把FP32转为FP16
# print(model)
ckpt = {'epoch': -1,
'best_fitness': model['best_fitness'],
'training_results': None,
'model': net,
'optimizer': None}
# Save .pt
torch.save(ckpt, 'weights/test.pt')
# for name, parameters in model.named_parameters():
# # print(name,':',parameters.size())
# print(parameters.dtype)
小编能力有限,在FP32转FP16时暂且使用最暴力的方法解决,以后有新的方法再及时更新,还有很多不足,希望大家多多指教。