论文笔记(图像篡改检测)(四):Forensic Similarity for Digital Images
这篇论文主要提出了一种基于forensic similarity的数字图像检测方法。这个网络主要包含两个部分:CNN特征提取器和一个三层的神经网络,作者将其称之为相似性网络。这个网络输出一个score来指示两个图像patch是否:①由相同或不同的相机模式所捕获;②由相同或不同的篡改操作所修改;③给定篡改类型,是否由不同或相同的参数所篡改。
Motivation:
- 已存在的方法都是在固定的篡改方法进行的,当遇到新的篡改类型时,模型效果不太好。
- 许多已存在的方法不需要明确识别一种篡改类型,仅需要知道其经历过篡改即可。
因此,作者提出了一种新的取证方法,其可以在一open set of forensic traces上进行训练,并判断两个图像patch是否包含相同或不同的forensic traces。
这种方法的好处是不需要事先了解特定的篡改痕迹来做出判断。
How and why:
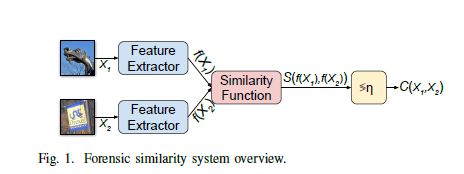
如上图所示,作者提出的网络结构主要包含两部分,第一部分是特征提取器,第二部分是相似网络。通过相似网络作者可以输出表示两个patch相关性的得分。
CNN特征提取器提取生成低维的forensic features(其编码了高级forensic information),接下来使用一个三层的网络来判断两个patch是否相似。
特征提取模块作者使用的是之前ON THE ROBUSTNESS OF CONSTRAINED CONVOLUTIONAL NEURAL NETWORKS TO JPEG POST-COMPRESSION FOR IMAGE RESAMPLING DETECTION2017中的方法。不同之处在于,这里作者使用了两个不同参的并行分支,一个用来处理256*256的patch,一个用来处理128*128的patch;还有一点就是之前只使用了RGB通道中的绿色通道,在这里作者使用了三个通道。此外,作者也放宽了第一层卷积中预测constrain卷积的限制,为了使网络可以学习更多的prediction error residual。第一层卷积和也从3变为6。

在本文中,作者使用的特征提取模块没有FC3和softmax,其他部分皆与上图中一致。
本文中,作者提出的网络框图具体为:

如上图所示,前半部分为两个并行的不同参的分支,一个使用256*256的patch训练,一个使用128*128的patch训练。
FC2的输出做为一个可以表示高级篡改信息的feature vector。
相似网络中,包含三个FC层,可以将这个网络视作把hierarchical feature映射到一个中间、相似特征空间,最后在输出一个score。
FCA:第一个FC层包含2048个neurons,将输入特征向量f(X)映射到新的、中间特征空间![]() ,在这里,作者使用了两个完全相同的FC层将之前两个分支的输出映射到新的feature vector。
,在这里,作者使用了两个完全相同的FC层将之前两个分支的输出映射到新的feature vector。

FCB:第二次包含64个neurons,这一层将输入向量映射到一个‘similarity’ feature space ![]() 。这个相似性特征空间编码了patch X1
。这个相似性特征空间编码了patch X1![]() 和X2
和X2![]() 之间相关的forensic信息。这一层的输入有三部分,分别是两个分支经过FA得到的输出以及这两个输出相乘得到的feature。具体为:
之间相关的forensic信息。这一层的输入有三部分,分别是两个分支经过FA得到的输出以及这两个输出相乘得到的feature。具体为:

最后一层作者使用sigmoid对![]() 输出一个score。在文中,作者选取的阈值为0.5,大于0.5则认为二者相关,否则不相关。
输出一个score。在文中,作者选取的阈值为0.5,大于0.5则认为二者相关,否则不相关。
此外,作者还介绍了一种基于熵值的方法来挑选patch去判断他们之间的相似性。这个方法仅使用在evaluation阶段,训练时不使用。这样做是因为作者将forensic trace是做编码在图像中的信息,一个image patch即为一个包含这种信息的channel。从这个channel中,可以提取forensic information,然后使用similarity network去判断他们是否包含相似的forensic trace。
熵值h的定义如下:

k为image patch中像素点的luminance value。实验时,作者选取了熵值在1.8~5.2 nats之间的patch。因为数据集中95%patch都集中在这个范围内。1.8和5.2两个阈值可以分别有利于消除一些平坦(例如饱和)的图像块(对于这样的patch来说,无论相机型号或处理历史如何,都会显得相同),同时也可以移除一些有很高熵值的patch(在这里,如果patch有很高像素的变化,会forensic trace造成混淆)。
结论 or 下一步:
作者针对三种不同类型的情况进行了实验,分别是:是否由相同的camera model捕获(patch size and re-cpmpression effects, other approaches, train methods);不同的edit操作;给定edit操作,不同的参数。针对这三种情况作者的模型都取得了很好的效果,并且作者一会在强调的一点是即使evaluation时,forensic trace在训练时未出现,模型也能很好的完成检测任务,这是其他方法所不具备的。
作者对提出的模型做了两方面应用的研究,分别是splicing detection(只选取了三张图片)、database consistency verification(感觉之前三种类型实验中的第一种有点像)。