yolov3原理加代码的理解
这里是
要自信!以下内容是我参考了很多优秀博主优质视频和博客,做的自己对于学习yolov1-v3的总结,希望对于和我一样的小白有所理解和帮助吧!
前言
哈喽呀,好久没有写word了,这里是我记录学习心得的地方,希望自己写出来的东西有啥不对的地方欢迎批评指正哟!前一阵子,最开始作为啥也不会的小白的时候,我看了唐宇迪的课,然后建立了基础的yolov1到yolov3的理解,后来找了个yolov5的代码去理解,我突然发现自己的理论基础还是不牢固,并且代码太难读了,所以现在又重新从yolov1到yolov3建立基础理解。所以给大家的忠诚建议就是面对b站上的种种资源,一定要好好选择,比如唐宇迪的团队力量很大,几乎B站都是他的推销课,说实话,对于啥也不懂的小白或许有用,但对于想学懂目标检测或想深挖这个算法或原理或某个词的概念的小白来说,忠诚建议,他的课属实不适合。那究竟该如何选择视频跟着学呢?我的建议是去b站找播放量上万的那种,或者最少也得七八千播放量吧。再就是评论量偏高的那种(因为团队卖课的会互相评论视频而且评论量就几条,遇到这种就直接pass掉吧哈哈哈)。对于目标检测yolo算法这里,我的建议是先把pytorch基础环境配置搞懂(b站我是土堆),然后跟着视频读文章(b站同济子豪兄),再跟着视频先去理解别人用自己的代码去复现原理(b站Bubbliiiing),再就是去找源码的解读(b站我是土堆、霹雳吧啦Wz、薛定谔的AI,科科带你学,刘二大人、白老师的人工智能课堂)。以上是我作为接触目标检测两个月的小白,觉得不错的b站up主,这些都可以看看,大家加油哇!!!
一、yolov1是什么?
这一部分我就直接简单的说一说,如果有需要的话,就去看子豪兄的视频讲解,他的论文讲解会在他的视频下方提示你去哪里下载【精读AI论文】YOLO V1目标检测,看我就够了_哔哩哔哩_bilibili
1、总体框架
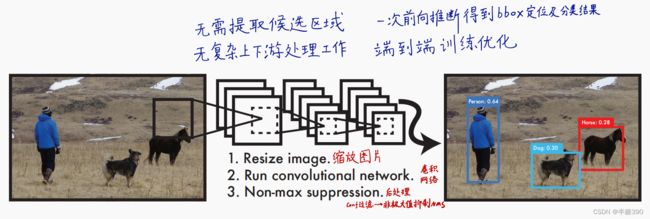
2、整体流程

训练阶段:标签Ground Truth框中心点落在哪个grid cell中就应由哪个grid cell预测这个物体,每个gride cell预测b个bounding boxes(译为先验框或者锚框)与Ground Truth框(译为人工标注框或者真实框)IOU最大的 bounding boxes负责预测这个物体。每个gride cell只检测一个物体。包含/不包含Ground Truth的grid cell/bounding box依损失函数分别处理。
测试阶段:直接获得S×S×(5×B+C)个向量进行非极大值抑制处理得到目标检测的结果,其中S×S是把这个图片划分为多少个网格,5是代表5个参数(x,y,w,h,confidence), B是代表一个种类会产生几个bounding boxes(译为先验框或者锚框),C代表要检测的种类的个数
3、网络结构vgg16
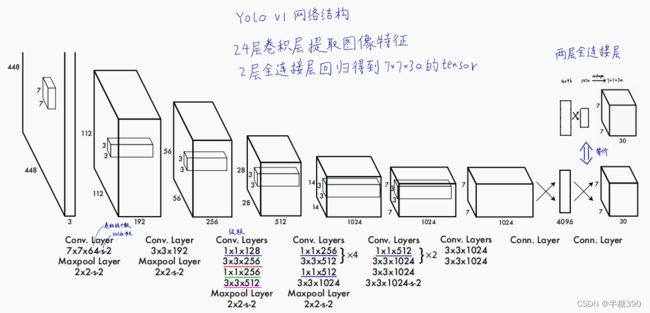
输入大小改为448 * 448,这是通过调整第一个卷积层的步长来实现的;网络使用了很多1*1的卷积层来进行特征降维;最后一个卷积层的输出为(7, 7, 1024),经过flatten后紧跟两个全连接层,形成一个线性回归,最后一个全连接层又被reshape成(7, 7, 30),形成对2个box坐标及20个物体类别的预测(PASCAL VOC)。
4、损失函数

二、yolov2是什么?
1、总体框架
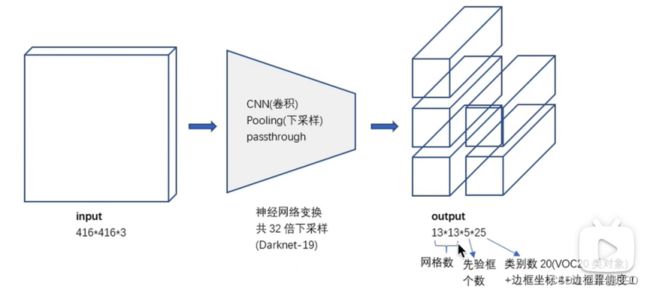
输入是416×416的图片,输出是13×13的图片。基本训练和测试的流程和yolov1一样,但它一个种类会产生5个先验框,所以S×S×(5×B+C)这里的B是5,S×S是13×13,C代表要检测的种类的个数。
2.网络结构

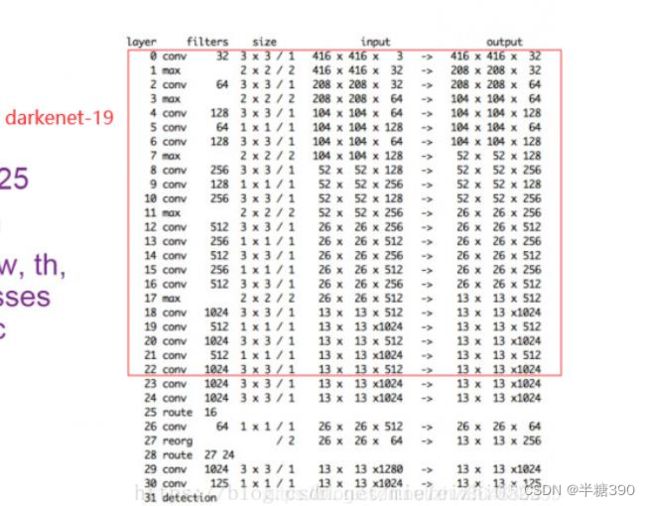
因为原文并没有给出具体这个网络是啥样的,所以我在网上搜了半天才找到这个网络结构,方便大家理解。要是想将网络和代码配合着看的话,可以根据我下面的两张图对应着看,有的时候多去思考去推,就会发现这个东西不难。
YOLOv2使用了一个新的分类网络DarkNet19作为特征提取部分,DarkNet19包含19个卷积层、5个最大值池化层。网络使用了较多的3 x 3卷积核,在每一次池化操作后把通道数翻倍。借鉴了network in network的思想,把1 x 1的卷积核置于3 x 3的卷积核之间,用来压缩特征。使用batch normalization稳定模型训练,加速收敛,正则化模型。
这里的layer表示的是第几层,filters是通道数,size是卷积核大小,input是输入大小,output是输出大小,输入和输出一定要对应上。睿智的目标检测6——yolo2详解及其预测代码复现_Bubbliiiing的博客-CSDN博客

其中融合这一处,是将26×26×512进行一个3×3的卷积之后,变成26×26×64,再将其通过passthrough细粒度特性变成13×13×256,最后经过融合,再进行一次卷积后,变成13×13×125(这里是用voc数据集20类,125=(20+5)×5,若用coco数据集80类,则425=(80+5)×5)
3、损失计算
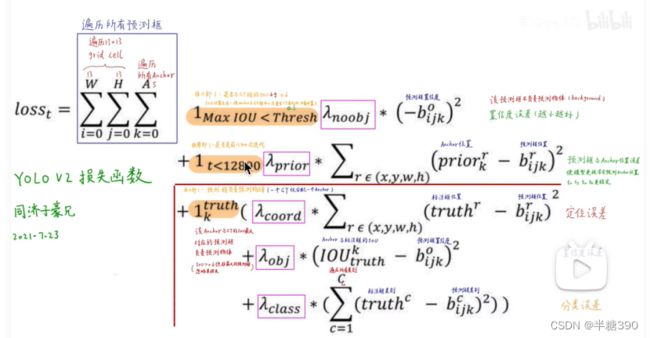
三、yolov3是什么
关于yolov3,我是跟着b站up主Bubbliiiing的视频学的,如果之前有接触一段时间yolo,没弄明白它的话,去看这个视频,就会有很大的收获。
Pytorch 搭建自己的YOLO3目标检测平台(Bubbliiiing 深度学习 教程)_哔哩哔哩_bilibili
1、网络结构
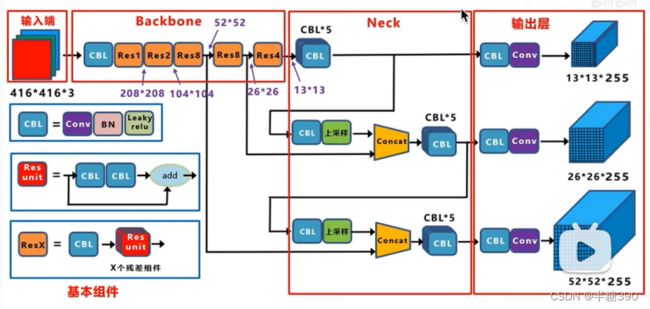
具体结构:
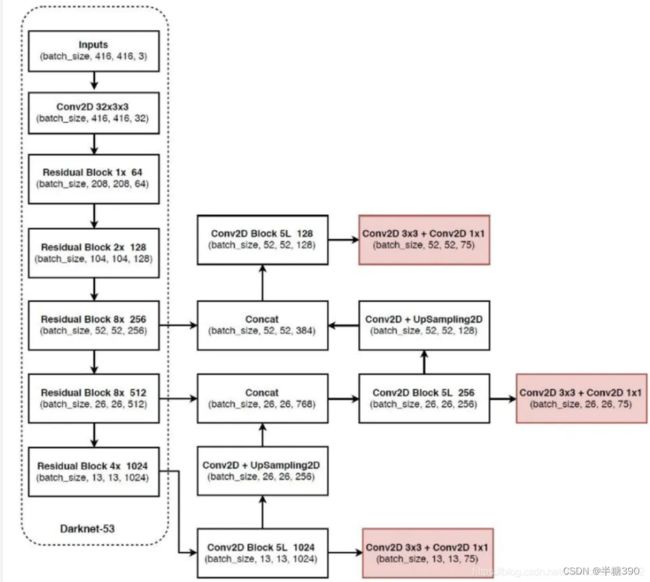
输出特征层及先验框大小

YoloV3所使用的主干特征提取网络为Darknet53,它具有两个重要特点:
a、Darknet53具有一个重要特点是使用了残差网络Residual,Darknet53中的残差卷积就是首先进行一次卷积核大小为3X3、步长为2的卷积,该卷积会压缩输入进来的特征层的宽和高,此时我们可以获得一个特征层,我们将该特征层命名为layer。之后我们再对该特征层进行一次1X1的卷积和一次3X3的卷积,并把这个结果加上layer,此时我们便构成了残差结构。通过不断的1X1卷积和3X3卷积以及残差边的叠加,我们便大幅度的加深了网络。残差网络的特点是容易优化,并且能够通过增加相当的深度来提高准确率。其内部的残差块使用了跳跃连接,缓解了在深度神经网络中增加深度带来的梯度消失问题。
b、Darknet53的每一个卷积部分使用了特有的DarknetConv2D结构,每一次卷积的时候进行l2正则化,完成卷积后进行BatchNormalization标准化与LeakyReLU。普通的ReLU是将所有的负值都设为零,Leaky ReLU则是给所有负值赋予一个非零斜率。
2、整体流程
整体流程包括了训练流程和测试流程。
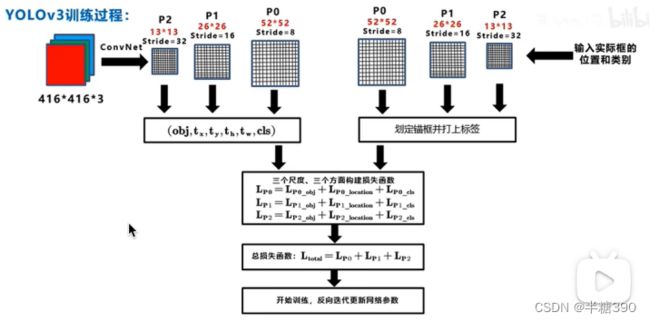

3、损失函数
拿到pred和target后,不可以简单的减一下作为对比,需要进行如下步骤。
A.判断真实框在图片中的位置,判断其属于哪一个网格点去检测。判断真实框和这个特征点的哪个先验框重合程度最高。计算该网格点应该有怎么样的预测结果才能获得真实框,与真实框重合度最高的先验框被用于作为正样本。
B.根据网络的预测结果获得预测框,计算预测框和所有真实框的重合程度,如果重合程度大于一定门限,则将该预测框对应的先验框忽略。其余作为负样本。
C.最终损失由三个部分组成:a、正样本,编码后的长宽与xy轴偏移量与预测值的差距。b、正样本,预测结果中置信度的值与1对比;负样本,预测结果中置信度的值与0对比。c、实际存在的框,种类预测结果与实际结果的对比。
aa.原文作者规定的损失函数计算如下【精读AI论文】YOLO V3目标检测(附YOLOV3代码复现)_哔哩哔哩_bilibili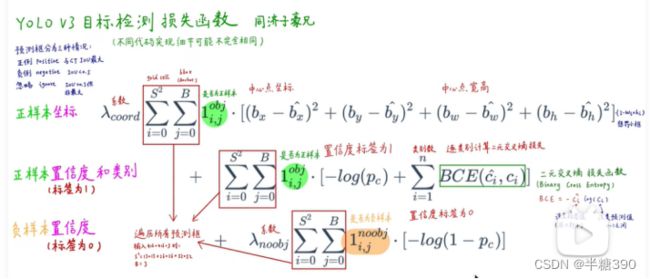
相应的计算损失的代码如下所示。Pytorch 搭建自己的YOLO3目标检测平台(Bubbliiiing 深度学习 教程)_哔哩哔哩_bilibili
import math
from functools import partial
import numpy as np
import torch
import torch.nn as nn
class YOLOLoss(nn.Module):
def __init__(self, anchors, num_classes, input_shape, cuda, anchors_mask = [[6,7,8], [3,4,5], [0,1,2]]):
super(YOLOLoss, self).__init__()
#-----------------------------------------------------------#
# 13x13的特征层对应的anchor是[116,90],[156,198],[373,326]
# 26x26的特征层对应的anchor是[30,61],[62,45],[59,119]
# 52x52的特征层对应的anchor是[10,13],[16,30],[33,23]
#-----------------------------------------------------------#
self.anchors = anchors
self.num_classes = num_classes
self.bbox_attrs = 5 + num_classes
self.input_shape = input_shape
self.anchors_mask = anchors_mask
self.giou = True
self.balance = [0.4, 1.0, 4]
self.box_ratio = 0.05
self.obj_ratio = 5 * (input_shape[0] * input_shape[1]) / (416 ** 2)
self.cls_ratio = 1 * (num_classes / 80)
self.ignore_threshold = 0.5
self.cuda = cuda
def clip_by_tensor(self, t, t_min, t_max):
t = t.float()
result = (t >= t_min).float() * t + (t < t_min).float() * t_min
result = (result <= t_max).float() * result + (result > t_max).float() * t_max
return result
def MSELoss(self, pred, target):
return torch.pow(pred - target, 2)
def BCELoss(self, pred, target):
epsilon = 1e-7
pred = self.clip_by_tensor(pred, epsilon, 1.0 - epsilon)
output = - target * torch.log(pred) - (1.0 - target) * torch.log(1.0 - pred)
return output
def box_giou(self, b1, b2):
"""
输入为:
----------
b1: tensor, shape=(batch, feat_w, feat_h, anchor_num, 4), xywh
b2: tensor, shape=(batch, feat_w, feat_h, anchor_num, 4), xywh
返回为:
-------
giou: tensor, shape=(batch, feat_w, feat_h, anchor_num, 1)
"""
#----------------------------------------------------#
# 求出预测框左上角右下角
#----------------------------------------------------#
b1_xy = b1[..., :2]
b1_wh = b1[..., 2:4]
b1_wh_half = b1_wh/2.
b1_mins = b1_xy - b1_wh_half
b1_maxes = b1_xy + b1_wh_half
#----------------------------------------------------#
# 求出真实框左上角右下角
#----------------------------------------------------#
b2_xy = b2[..., :2]
b2_wh = b2[..., 2:4]
b2_wh_half = b2_wh/2.
b2_mins = b2_xy - b2_wh_half
b2_maxes = b2_xy + b2_wh_half
#----------------------------------------------------#
# 求真实框和预测框所有的iou
#----------------------------------------------------#
intersect_mins = torch.max(b1_mins, b2_mins)
intersect_maxes = torch.min(b1_maxes, b2_maxes)
intersect_wh = torch.max(intersect_maxes - intersect_mins, torch.zeros_like(intersect_maxes))
intersect_area = intersect_wh[..., 0] * intersect_wh[..., 1]
b1_area = b1_wh[..., 0] * b1_wh[..., 1]
b2_area = b2_wh[..., 0] * b2_wh[..., 1]
union_area = b1_area + b2_area - intersect_area
iou = intersect_area / union_area
#----------------------------------------------------#
# 找到包裹两个框的最小框的左上角和右下角
#----------------------------------------------------#
enclose_mins = torch.min(b1_mins, b2_mins)
enclose_maxes = torch.max(b1_maxes, b2_maxes)
enclose_wh = torch.max(enclose_maxes - enclose_mins, torch.zeros_like(intersect_maxes))
#----------------------------------------------------#
# 计算对角线距离
#----------------------------------------------------#
enclose_area = enclose_wh[..., 0] * enclose_wh[..., 1]
giou = iou - (enclose_area - union_area) / enclose_area
return giou
def forward(self, l, input, targets=None):
#----------------------------------------------------#
# l代表的是,当前输入进来的有效特征层,是第几个有效特征层
# input的shape为 bs, 3*(5+num_classes), 13, 13
# bs, 3*(5+num_classes), 26, 26
# bs, 3*(5+num_classes), 52, 52
# targets代表的是真实框。
#----------------------------------------------------#
#--------------------------------#
# 获得图片数量,特征层的高和宽
# 13和13
#--------------------------------#
bs = input.size(0)
in_h = input.size(2)
in_w = input.size(3)
#-----------------------------------------------------------------------#
# 计算步长
# 每一个特征点对应原来的图片上多少个像素点
# 如果特征层为13x13的话,一个特征点就对应原来的图片上的32个像素点
# 如果特征层为26x26的话,一个特征点就对应原来的图片上的16个像素点
# 如果特征层为52x52的话,一个特征点就对应原来的图片上的8个像素点
# stride_h = stride_w = 32、16、8
# stride_h和stride_w都是32。
#-----------------------------------------------------------------------#
stride_h = self.input_shape[0] / in_h
stride_w = self.input_shape[1] / in_w
#-------------------------------------------------#
# 此时获得的scaled_anchors大小是相对于特征层的
#-------------------------------------------------#
scaled_anchors = [(a_w / stride_w, a_h / stride_h) for a_w, a_h in self.anchors]
#-----------------------------------------------#
# 输入的input一共有三个,他们的shape分别是
# bs, 3*(5+num_classes), 13, 13 => batch_size, 3, 13, 13, 5 + num_classes
# batch_size, 3, 26, 26, 5 + num_classes
# batch_size, 3, 52, 52, 5 + num_classes
#-----------------------------------------------#
prediction = input.view(bs, len(self.anchors_mask[l]), self.bbox_attrs, in_h, in_w).permute(0, 1, 3, 4, 2).contiguous()
#-----------------------------------------------#
# 先验框的中心位置的调整参数
#-----------------------------------------------#
x = torch.sigmoid(prediction[..., 0])
y = torch.sigmoid(prediction[..., 1])
#-----------------------------------------------#
# 先验框的宽高调整参数
#-----------------------------------------------#
w = prediction[..., 2]
h = prediction[..., 3]
#-----------------------------------------------#
# 获得置信度,是否有物体
#-----------------------------------------------#
conf = torch.sigmoid(prediction[..., 4])
#-----------------------------------------------#
# 种类置信度
#-----------------------------------------------#
pred_cls = torch.sigmoid(prediction[..., 5:])
#-----------------------------------------------#
# 获得网络应该有的预测结果
#-----------------------------------------------#
y_true, noobj_mask, box_loss_scale = self.get_target(l, targets, scaled_anchors, in_h, in_w)
#---------------------------------------------------------------#
# 将预测结果进行解码,判断预测结果和真实值的重合程度
# 如果重合程度过大则忽略,因为这些特征点属于预测比较准确的特征点
# 作为负样本不合适
#----------------------------------------------------------------#
noobj_mask, pred_boxes = self.get_ignore(l, x, y, h, w, targets, scaled_anchors, in_h, in_w, noobj_mask)
if self.cuda:
y_true = y_true.type_as(x)
noobj_mask = noobj_mask.type_as(x)
box_loss_scale = box_loss_scale.type_as(x)
#--------------------------------------------------------------------------#
# box_loss_scale是真实框宽高的乘积,宽高均在0-1之间,因此乘积也在0-1之间。
# 2-宽高的乘积代表真实框越大,比重越小,小框的比重更大。
#--------------------------------------------------------------------------#
box_loss_scale = 2 - box_loss_scale
loss = 0
obj_mask = y_true[..., 4] == 1
n = torch.sum(obj_mask)
if n != 0:
if self.giou:
#---------------------------------------------------------------#
# 计算预测结果和真实结果的giou
#----------------------------------------------------------------#
giou = self.box_giou(pred_boxes, y_true[..., :4]).type_as(x)
loss_loc = torch.mean((1 - giou)[obj_mask])
else:
#-----------------------------------------------------------#
# 计算中心偏移情况的loss,使用BCELoss效果好一些
#-----------------------------------------------------------#
loss_x = torch.mean(self.BCELoss(x[obj_mask], y_true[..., 0][obj_mask]) * box_loss_scale[obj_mask])
loss_y = torch.mean(self.BCELoss(y[obj_mask], y_true[..., 1][obj_mask]) * box_loss_scale[obj_mask])
#-----------------------------------------------------------#
# 计算宽高调整值的loss
#-----------------------------------------------------------#
loss_w = torch.mean(self.MSELoss(w[obj_mask], y_true[..., 2][obj_mask]) * box_loss_scale[obj_mask])
loss_h = torch.mean(self.MSELoss(h[obj_mask], y_true[..., 3][obj_mask]) * box_loss_scale[obj_mask])
loss_loc = (loss_x + loss_y + loss_h + loss_w) * 0.1
loss_cls = torch.mean(self.BCELoss(pred_cls[obj_mask], y_true[..., 5:][obj_mask]))
loss += loss_loc * self.box_ratio + loss_cls * self.cls_ratio
loss_conf = torch.mean(self.BCELoss(conf, obj_mask.type_as(conf))[noobj_mask.bool() | obj_mask])
loss += loss_conf * self.balance[l] * self.obj_ratio
# if n != 0:
# print(loss_loc * self.box_ratio, loss_cls * self.cls_ratio, loss_conf * self.balance[l] * self.obj_ratio)
return loss
def calculate_iou(self, _box_a, _box_b):
#-----------------------------------------------------------#
# 计算真实框的左上角和右下角
#-----------------------------------------------------------#
b1_x1, b1_x2 = _box_a[:, 0] - _box_a[:, 2] / 2, _box_a[:, 0] + _box_a[:, 2] / 2
b1_y1, b1_y2 = _box_a[:, 1] - _box_a[:, 3] / 2, _box_a[:, 1] + _box_a[:, 3] / 2
#-----------------------------------------------------------#
# 计算先验框获得的预测框的左上角和右下角
#-----------------------------------------------------------#
b2_x1, b2_x2 = _box_b[:, 0] - _box_b[:, 2] / 2, _box_b[:, 0] + _box_b[:, 2] / 2
b2_y1, b2_y2 = _box_b[:, 1] - _box_b[:, 3] / 2, _box_b[:, 1] + _box_b[:, 3] / 2
#-----------------------------------------------------------#
# 将真实框和预测框都转化成左上角右下角的形式
#-----------------------------------------------------------#
box_a = torch.zeros_like(_box_a)
box_b = torch.zeros_like(_box_b)
box_a[:, 0], box_a[:, 1], box_a[:, 2], box_a[:, 3] = b1_x1, b1_y1, b1_x2, b1_y2
box_b[:, 0], box_b[:, 1], box_b[:, 2], box_b[:, 3] = b2_x1, b2_y1, b2_x2, b2_y2
#-----------------------------------------------------------#
# A为真实框的数量,B为先验框的数量
#-----------------------------------------------------------#
A = box_a.size(0)
B = box_b.size(0)
#-----------------------------------------------------------#
# 计算交的面积
#-----------------------------------------------------------#
max_xy = torch.min(box_a[:, 2:].unsqueeze(1).expand(A, B, 2), box_b[:, 2:].unsqueeze(0).expand(A, B, 2))
min_xy = torch.max(box_a[:, :2].unsqueeze(1).expand(A, B, 2), box_b[:, :2].unsqueeze(0).expand(A, B, 2))
inter = torch.clamp((max_xy - min_xy), min=0)
inter = inter[:, :, 0] * inter[:, :, 1]
#-----------------------------------------------------------#
# 计算预测框和真实框各自的面积
#-----------------------------------------------------------#
area_a = ((box_a[:, 2]-box_a[:, 0]) * (box_a[:, 3]-box_a[:, 1])).unsqueeze(1).expand_as(inter) # [A,B]
area_b = ((box_b[:, 2]-box_b[:, 0]) * (box_b[:, 3]-box_b[:, 1])).unsqueeze(0).expand_as(inter) # [A,B]
#-----------------------------------------------------------#
# 求IOU
#-----------------------------------------------------------#
union = area_a + area_b - inter
return inter / union # [A,B]
def get_target(self, l, targets, anchors, in_h, in_w):
#-----------------------------------------------------#
# 计算一共有多少张图片
#-----------------------------------------------------#
bs = len(targets)
#-----------------------------------------------------#
# 用于选取哪些先验框不包含物体
#-----------------------------------------------------#
noobj_mask = torch.ones(bs, len(self.anchors_mask[l]), in_h, in_w, requires_grad = False)
#-----------------------------------------------------#
# 让网络更加去关注小目标
#-----------------------------------------------------#
box_loss_scale = torch.zeros(bs, len(self.anchors_mask[l]), in_h, in_w, requires_grad = False)
#-----------------------------------------------------#
# batch_size, 3, 13, 13, 5 + num_classes
#-----------------------------------------------------#
y_true = torch.zeros(bs, len(self.anchors_mask[l]), in_h, in_w, self.bbox_attrs, requires_grad = False)
for b in range(bs):
if len(targets[b])==0:
continue
batch_target = torch.zeros_like(targets[b])
#-------------------------------------------------------#
# 计算出正样本在特征层上的中心点
#-------------------------------------------------------#
batch_target[:, [0,2]] = targets[b][:, [0,2]] * in_w
batch_target[:, [1,3]] = targets[b][:, [1,3]] * in_h
batch_target[:, 4] = targets[b][:, 4]
batch_target = batch_target.cpu()
#-------------------------------------------------------#
# 将真实框转换一个形式
# num_true_box, 4
#-------------------------------------------------------#
gt_box = torch.FloatTensor(torch.cat((torch.zeros((batch_target.size(0), 2)), batch_target[:, 2:4]), 1))
#-------------------------------------------------------#
# 将先验框转换一个形式
# 9, 4
#-------------------------------------------------------#
anchor_shapes = torch.FloatTensor(torch.cat((torch.zeros((len(anchors), 2)), torch.FloatTensor(anchors)), 1))
#-------------------------------------------------------#
# 计算交并比
# self.calculate_iou(gt_box, anchor_shapes) = [num_true_box, 9]每一个真实框和9个先验框的重合情况
# best_ns:
# [每个真实框最大的重合度max_iou, 每一个真实框最重合的先验框的序号]
#-------------------------------------------------------#
best_ns = torch.argmax(self.calculate_iou(gt_box, anchor_shapes), dim=-1)
for t, best_n in enumerate(best_ns):
if best_n not in self.anchors_mask[l]:
continue
#----------------------------------------#
# 判断这个先验框是当前特征点的哪一个先验框
#----------------------------------------#
k = self.anchors_mask[l].index(best_n)
#----------------------------------------#
# 获得真实框属于哪个网格点
#----------------------------------------#
i = torch.floor(batch_target[t, 0]).long()
j = torch.floor(batch_target[t, 1]).long()
#----------------------------------------#
# 取出真实框的种类
#----------------------------------------#
c = batch_target[t, 4].long()
#----------------------------------------#
# noobj_mask代表无目标的特征点
#----------------------------------------#
noobj_mask[b, k, j, i] = 0
#----------------------------------------#
# tx、ty代表中心调整参数的真实值
#----------------------------------------#
if not self.giou:
#----------------------------------------#
# tx、ty代表中心调整参数的真实值
#----------------------------------------#
y_true[b, k, j, i, 0] = batch_target[t, 0] - i.float()
y_true[b, k, j, i, 1] = batch_target[t, 1] - j.float()
y_true[b, k, j, i, 2] = math.log(batch_target[t, 2] / anchors[best_n][0])
y_true[b, k, j, i, 3] = math.log(batch_target[t, 3] / anchors[best_n][1])
y_true[b, k, j, i, 4] = 1
y_true[b, k, j, i, c + 5] = 1
else:
#----------------------------------------#
# tx、ty代表中心调整参数的真实值
#----------------------------------------#
y_true[b, k, j, i, 0] = batch_target[t, 0]
y_true[b, k, j, i, 1] = batch_target[t, 1]
y_true[b, k, j, i, 2] = batch_target[t, 2]
y_true[b, k, j, i, 3] = batch_target[t, 3]
y_true[b, k, j, i, 4] = 1
y_true[b, k, j, i, c + 5] = 1
#----------------------------------------#
# 用于获得xywh的比例
# 大目标loss权重小,小目标loss权重大
#----------------------------------------#
box_loss_scale[b, k, j, i] = batch_target[t, 2] * batch_target[t, 3] / in_w / in_h
return y_true, noobj_mask, box_loss_scale
def get_ignore(self, l, x, y, h, w, targets, scaled_anchors, in_h, in_w, noobj_mask):
#-----------------------------------------------------#
# 计算一共有多少张图片
#-----------------------------------------------------#
bs = len(targets)
#-----------------------------------------------------#
# 生成网格,先验框中心,网格左上角
#-----------------------------------------------------#
grid_x = torch.linspace(0, in_w - 1, in_w).repeat(in_h, 1).repeat(
int(bs * len(self.anchors_mask[l])), 1, 1).view(x.shape).type_as(x)
grid_y = torch.linspace(0, in_h - 1, in_h).repeat(in_w, 1).t().repeat(
int(bs * len(self.anchors_mask[l])), 1, 1).view(y.shape).type_as(x)
# 生成先验框的宽高
scaled_anchors_l = np.array(scaled_anchors)[self.anchors_mask[l]]
anchor_w = torch.Tensor(scaled_anchors_l).index_select(1, torch.LongTensor([0])).type_as(x)
anchor_h = torch.Tensor(scaled_anchors_l).index_select(1, torch.LongTensor([1])).type_as(x)
anchor_w = anchor_w.repeat(bs, 1).repeat(1, 1, in_h * in_w).view(w.shape)
anchor_h = anchor_h.repeat(bs, 1).repeat(1, 1, in_h * in_w).view(h.shape)
#-------------------------------------------------------#
# 计算调整后的先验框中心与宽高
#-------------------------------------------------------#
pred_boxes_x = torch.unsqueeze(x + grid_x, -1)
pred_boxes_y = torch.unsqueeze(y + grid_y, -1)
pred_boxes_w = torch.unsqueeze(torch.exp(w) * anchor_w, -1)
pred_boxes_h = torch.unsqueeze(torch.exp(h) * anchor_h, -1)
pred_boxes = torch.cat([pred_boxes_x, pred_boxes_y, pred_boxes_w, pred_boxes_h], dim = -1)
for b in range(bs):
#-------------------------------------------------------#
# 将预测结果转换一个形式
# pred_boxes_for_ignore num_anchors, 4
#-------------------------------------------------------#
pred_boxes_for_ignore = pred_boxes[b].view(-1, 4)
#-------------------------------------------------------#
# 计算真实框,并把真实框转换成相对于特征层的大小
# gt_box num_true_box, 4
#-------------------------------------------------------#
if len(targets[b]) > 0:
batch_target = torch.zeros_like(targets[b])
#-------------------------------------------------------#
# 计算出正样本在特征层上的中心点
#-------------------------------------------------------#
batch_target[:, [0,2]] = targets[b][:, [0,2]] * in_w
batch_target[:, [1,3]] = targets[b][:, [1,3]] * in_h
batch_target = batch_target[:, :4].type_as(x)
#-------------------------------------------------------#
# 计算交并比
# anch_ious num_true_box, num_anchors
#-------------------------------------------------------#
anch_ious = self.calculate_iou(batch_target, pred_boxes_for_ignore)
#-------------------------------------------------------#
# 每个先验框对应真实框的最大重合度
# anch_ious_max num_anchors
#-------------------------------------------------------#
anch_ious_max, _ = torch.max(anch_ious, dim = 0)
anch_ious_max = anch_ious_max.view(pred_boxes[b].size()[:3])
noobj_mask[b][anch_ious_max > self.ignore_threshold] = 0
return noobj_mask, pred_boxes
def weights_init(net, init_type='normal', init_gain = 0.02):
def init_func(m):
classname = m.__class__.__name__
if hasattr(m, 'weight') and classname.find('Conv') != -1:
if init_type == 'normal':
torch.nn.init.normal_(m.weight.data, 0.0, init_gain)
elif init_type == 'xavier':
torch.nn.init.xavier_normal_(m.weight.data, gain=init_gain)
elif init_type == 'kaiming':
torch.nn.init.kaiming_normal_(m.weight.data, a=0, mode='fan_in')
elif init_type == 'orthogonal':
torch.nn.init.orthogonal_(m.weight.data, gain=init_gain)
else:
raise NotImplementedError('initialization method [%s] is not implemented' % init_type)
elif classname.find('BatchNorm2d') != -1:
torch.nn.init.normal_(m.weight.data, 1.0, 0.02)
torch.nn.init.constant_(m.bias.data, 0.0)
print('initialize network with %s type' % init_type)
net.apply(init_func)
def get_lr_scheduler(lr_decay_type, lr, min_lr, total_iters, warmup_iters_ratio = 0.05, warmup_lr_ratio = 0.1, no_aug_iter_ratio = 0.05, step_num = 10):
def yolox_warm_cos_lr(lr, min_lr, total_iters, warmup_total_iters, warmup_lr_start, no_aug_iter, iters):
if iters <= warmup_total_iters:
# lr = (lr - warmup_lr_start) * iters / float(warmup_total_iters) + warmup_lr_start
lr = (lr - warmup_lr_start) * pow(iters / float(warmup_total_iters), 2) + warmup_lr_start
elif iters >= total_iters - no_aug_iter:
lr = min_lr
else:
lr = min_lr + 0.5 * (lr - min_lr) * (
1.0 + math.cos(math.pi* (iters - warmup_total_iters) / (total_iters - warmup_total_iters - no_aug_iter))
)
return lr
def step_lr(lr, decay_rate, step_size, iters):
if step_size < 1:
raise ValueError("step_size must above 1.")
n = iters // step_size
out_lr = lr * decay_rate ** n
return out_lr
if lr_decay_type == "cos":
warmup_total_iters = min(max(warmup_iters_ratio * total_iters, 1), 3)
warmup_lr_start = max(warmup_lr_ratio * lr, 1e-6)
no_aug_iter = min(max(no_aug_iter_ratio * total_iters, 1), 15)
func = partial(yolox_warm_cos_lr ,lr, min_lr, total_iters, warmup_total_iters, warmup_lr_start, no_aug_iter)
else:
decay_rate = (min_lr / lr) ** (1 / (step_num - 1))
step_size = total_iters / step_num
func = partial(step_lr, lr, decay_rate, step_size)
return func
def set_optimizer_lr(optimizer, lr_scheduler_func, epoch):
lr = lr_scheduler_func(epoch)
for param_group in optimizer.param_groups:
param_group['lr'] = lr
以上yolov3原作者定义的损失函数公式及博主复现的损失函数的代码,在网上的各种资料中,可以看到各种损失计算,各不相同,但总体损失都是C中提到的。这里的某些数值量在下面的(4、损失函数中的参数计算及人工标注框、先验框、预测框之间计算关系)中有所介绍。
bb.网上的有关损失函数的不同计算,如下框所示,参考文章(最简单)深度理解YOLOV3损失函数及anchor box_恩泽君的博客-CSDN博客




4、损失函数中的参数计算及人工标注框、先验框、预测框之间计算关系
4.1、损失函数中x ^ , y ^ , w ^ , h ^ 参数的获取
在模型训练过程中,我们的ground truth往往是相对于原始图像的四个坐标值,表示bounding box的左上和右下点坐标,而这是肯定不能直接用于模型训练,通过前面边框预测公式我们可以知道,我们需要将ground truth转换成网络模型输出值相同的类型(即:包含标记框中心点相对于anchor box的偏移量和标记框相对于anchor box的尺度变换),因此我们需要经过以下步骤:
步骤一:将原始标记框按原始图像到416×416尺寸变换比例同比例缩放到符合416×416尺寸的大小(简单说就是因为网络输入是416×416大小,所以输入图像会先reshape到这个尺寸,这时要将标记框也同比例进行缩放),然后计算标记框中心点坐标和宽高值。
步骤二:计算标记框在feature map上的中心点坐标和宽高值。将上一步得到的标记框中心点坐标和宽高值都除以stride(比如feature map为13×13,此时stride=416/13=32),得到标记框在feature map上位置信息G x , G y , G w , G h
步骤三:计算标记框相对于anchor box的偏移量和尺度缩放大小。使用下面公式:
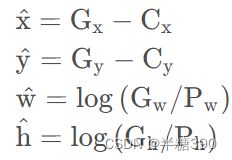
其中C x , C y 为feature map上grid cell左上角坐标,P w , P h 为anchor box在feature map上宽高大小,通过将标记框宽高与anchor box宽高比值的对数计算它们的缩放比例,通过取对数而不是直接预测相对形变G w / P w,是因为如果直接计算相对形变,那么要求预测w值要大于0,因为你的框的宽高不可能为负数,因此,该问题变成一个有不等式条件约束的优化问题,没法直接用SGD来做,所以先取一个对数变换将这个不等式约束去掉就可以了。
至此,我们对标记框的偏移量和尺度缩放大小就求出来了,损失函数里面就可以使用x ^ , y ^ , w ^ , h ^
4.2、损失函数中x , y , w , h 参数的获取
在边框预测公式中我们可以了解到网络的输出是可以代表预测框偏移量和尺度缩放大小的,但是这里还是要注意一下,网络输出t x , t y, 由于不在0-1范围内(网络输出层激活函数为线性激活函数),跟ground truth的范围不一致,这里就需要经过sigmoid函数使得其偏移量在0-1之间,因此损失函数中参数x , y , w , h由下列公式获得:

4.3、损失函数中的置信度C和P的获取
你也许会问置信度和类概率不是直接就是网络输出的参数吗?其实我们想一下,网络输出其实不是0-1的范围,所以我们还是需要将其归一化到0-1范围内,跟之前处理方法一样,使用一个sigmoid函数即可:

至于标记框的C ^ 就更简单,如果含有标记框则为1,否则直接等于0,同时对于P ^也一样,将标记框相应类别概率设为1,其他设置为0即可
4.4、损失函数中判断有无物体的参数
在损失函数定义时解释过, 表示该矩形框是否负责预测一个目标物体,如果该矩形框负责预测一个目标则其大小为1,否则等于0,
表示该矩形框是否负责预测一个目标物体,如果该矩形框负责预测一个目标则其大小为1,否则等于0, 则跟其相反。所以我们这里就需要确定一个预测框是否负责预测一个目标,怎么确定呢?
则跟其相反。所以我们这里就需要确定一个预测框是否负责预测一个目标,怎么确定呢?
首先对于feature map中那些grid cell上没有ground truth的预测框,我们直接就可以认定其为noobj,此时将![]() =0即可。而对于那些含有ground truth的grid cell,我们知道一个尺度的feature map有三个anchors,也就是说现在有三个备选预测框,YOLOV3假定每个cell至多含有一个ground truth,在实际情况中,其实基本也不会出现多于1个的情况,所以我们怎样确定选哪个预测框来预测这个物体呢?这需要在训练中确定,即由那个与ground truth标记框的IOU值最大的预测框预测它,此时
=0即可。而对于那些含有ground truth的grid cell,我们知道一个尺度的feature map有三个anchors,也就是说现在有三个备选预测框,YOLOV3假定每个cell至多含有一个ground truth,在实际情况中,其实基本也不会出现多于1个的情况,所以我们怎样确定选哪个预测框来预测这个物体呢?这需要在训练中确定,即由那个与ground truth标记框的IOU值最大的预测框预测它,此时![]() =1,而剩余的不与该grund truth匹配,此时
=1,而剩余的不与该grund truth匹配,此时![]() =0。
=0。
4.5边框预测公式

我们知道网络的输出值t x , t y , t w , t h并不能直接反应预测框的空间信息,而是需要通过一定变换得到,作者使用了下面公式来获取在特征图上预测矩形框,其实这也可以通过之前计算标记框相对偏移量和尺度变换公式中获得:
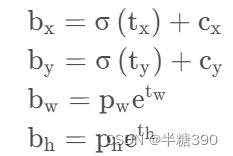
其中,( c x , c y )代表特征图中当前位置相对左上角网格偏移的网格数坐标,σ()是sigmoid函数,其作用是将坐标归一化到0~1之间,( p w , p h ) 是预设的anchor box映射到特征图中的宽高。所以b x、b y值是预测框在feature map上的中心点坐标,b w、b h是预测框在feature map上宽高值。所以,通过网络输出值t x , c y , t w , t h 。我们就可以得到预测框在feature map上的中心点坐标和宽高值c x , c y , p w , p h 。(这里再说明一点:网络输出值例如t x 由于其输出层使用的是线性激活函数,所以其大小范围并不在0-1之间,所以需要通过sigmoid函数将坐标归一化到0-1之间,使得预测框中心点始终在该网格内,而不至于落在其他网格中去)。
因此我们可以获得预测框在feature map上的中心点坐标和宽高大小,为了能够方便将预测框还原到原图尺寸,往往我们再对其进行归一化可以得到归一化的预测框:

其中W,H分别代表feature map的尺寸大小,比如最后输出feature map为13×13,则W=13,H=13。这样我们得到了正对于输入图片416×416的归一化预测框,但是我们原图往往不是416×416大小,是经过了reshape到416尺寸的操作,所以我们还需要将得到的归一化预测框reshape回去到符合原图尺寸比例的归一化预测框,然后直接乘以原图尺寸大小就可以得到最终的预测框。
五、总结
把理论和代码相结合是最好的学习方法,即使过程有些漫长,但搞懂了之后,真的十分开心!
参考:
【精读AI论文】YOLO V1目标检测,看我就够了_哔哩哔哩_bilibili
睿智的目标检测6——yolo2详解及其预测代码复现_Bubbliiiing的博客-CSDN博客
【精读AI论文】YOLO V3目标检测(附YOLOV3代码复现)_哔哩哔哩_bilibili
Pytorch 搭建自己的YOLO3目标检测平台(Bubbliiiing 深度学习 教程)_哔哩哔哩_bilibili
(最简单)深度理解YOLOV3损失函数及anchor box_恩泽君的博客-CSDN博客
睿智的目标检测26——Pytorch搭建yolo3目标检测平台_Bubbliiiing的博客-CSDN博客_睿智的目标检测26