TRANSFORMER TRANSDUCER: A STREAMABLE SPEECH RECOGNITION MODELWITH TRANSFORMER ENCODERS AND RNN-T
题目:
[ICASSP 2020 arXiv:2002.02562v2]
Motivation
1、基于transformer的模型使用解码器特征来处理编码器特征,这意味着解码必须以标签同步的方式完成,从而对流语音识别应用提出了挑战。
2、随着输入序列的大小,self-attention的计算次数会二次增加。
Method
A RNN/Transformer Transducer architecture

RNN-T体系结构是一种神经网络体系结构,可以通过RNN-T损失进行端到端训练,将输入序列(如音频特征向量)映射到目标序列。给定一个长度为T,x=(x1,x2,...,xT)的实值向量的输入序列,RNN-T模型试图预测长度为U的标签y=(y1,y2,...,yU)的目标序列。
RNN-T模型在每一个时间步给出了一个标签空间的概率分布,和输出标签空间包括一个额外的空标签。
RNN-T模型对所有可能的对齐都定义了一个条件分布P(z|x),其中:
![]()
是长度为U的(zi,ti)对序列,(zi,ti)表示输出标签zi和编码的ti特征之间的对齐。标签zi也可以是空白标签(空预测)。删除空白标签将得到实际的输出标签序列y,长度为U。可以在所有可能的对齐z上边缘P(z|x),以获得给定输入序列x的目标标签序列y的概率,
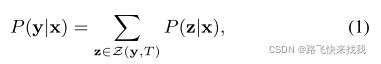
其中Z(y, T)是标签序列长度为T的有效对齐的集合。
B RNN-T Architecture and Loss
对齐的概率P(z|x)可以分解为:
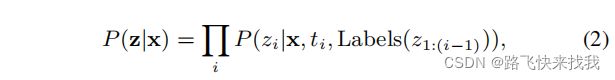
其中,label(z1:(i−1))是z1:(i−1)中的非空白标签序列。RNN-T架构通过音频编码器、标签编码器和联合网络参数化P(z|x)。编码器是两个神经网络,分别编码输入序列和目标输出序列。本文用transformer代替原来的LSTM编码器。


其中每个线性函数是一个不同的单层前馈神经网络,AudioEncoder(x)是时间ti时的音频编码器输出,LabelEncoder(labels(z1:(i−1)))是给定之前的非空白标签序列的标签编码器输出。其中下面式子中前向变量α(t,u)定义为在时间框架t处结束的所有路径和在标记位置u处结束的所有路径的概率之和。然后,使用前向算法来计算最后一个α变量α(T,U),模型的训练损失是等式中定义的负对数概率的和:

其中,Ti和Ui分别为第i个训练示例的输入序列和输出目标标签序列的长度。
C T-T模型中的transformer
Transformer由多个相同层的堆栈组成。每一层有两个子层,一个多头注意层和一个前馈层。多头注意层首先应用LayerNorm,然后为所有的头投影输入到q,k,v。注意机制对不同注意头分别应用。所有头部的权重平均值被连接并传递到一个密集层。然后在密集层的归一化输入和输出上使用残差连接,形成多头注意子层的最终输出(即LayerNorm(x) + AttentionLayer(LayerNorm(x)),其中x是多头注意子层的输入)。还对密集层的输出施加dropout,以防止过拟合。前馈子层首先在输入上应用LayerNorm,然后应用两个密集层。使用ReLu作为第一个致密层的激活。再次,dropout到两个密集层进行正则化,并应用一个归一化输入和第二层密集层(即LayerNorm(x) + FeedForwardLayer(LayerNorm(x))输出的残差连接,其中x是前馈子层的输入)。

此外,为了建模顺序,本文使用了相对位置编码,可以通过相对位置编码将复杂性从O(t2)降低到O(t)。
为了解决延迟随着时间的推移而增长的问题,将模型限制在一个移动的状态窗口W上,使一步推理复杂度为常数。
实验步骤
数据集:LibriSpeech ASR corpus
LibriSpeech数据集由970小时的音频数据和相应的文本文本(大约1000万个单词标记)和一个额外的800万个单词标记文本数据集组成。配对的音频/转录数据集用于训练T-T模型和基于LSTM的基线。完整的810M单词标记文本数据集用于独立语言模型(LM)训练。
实验结果

可以看到,T-T模型显著优于基于lstm的RNN-T基线。
为了与使用单独训练LM的浅融合系统进行比较,还使用完整的810M的数据集训练了一个基于transformer的LM,该LM与T-T中使用的标签编码器的架构相同。
使用该LM和训练的T-T系统以及训练的双向基于lstm的RNN-T基线进行浅融合。结果显示在“With LM”列的表2中。T-T系统的浅融合结果与高性能现有系统的相应结果具有竞争力。

为了使AudioEncoder的一步推断易于处理(即具有恒定的时间复杂度),进一步通过再次掩盖注意力分数,将AudioEncoder的注意力限制在先前状态的固定窗口。由于计算资源有限,对不同的Transformer层使用相同的mask,但是对不同的层使用不同的上下文(mask)是值得探索的。前两列中的N表示模型在当前帧的左边或右边使用的状态数。使用更多的音频历史记录会带来更低的WER,但考虑到一个具有合理时间复杂度的可流模型,尝试了每层10帧的左上下文。
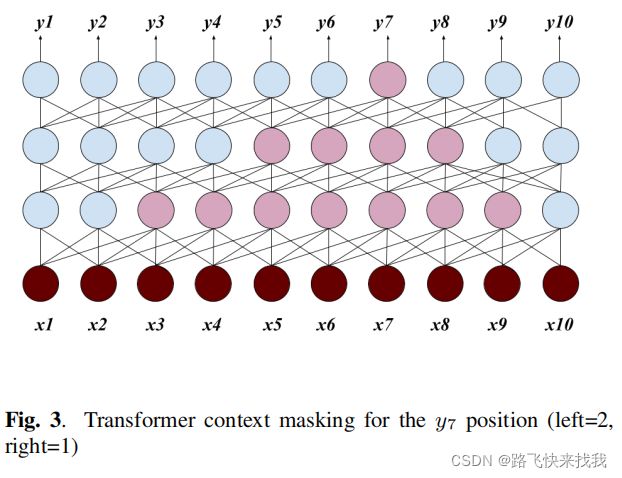
类似地,探索了使用有限的右上下文来允许模型看到一些未来的音频帧,希望能够弥合可流化的T-T模型(左=10,右=0)和全关注的T-T模型(左=512,右=512)之间的差距。由于对每个层应用相同的掩码,因此通过使用正确的上下文引入的延迟将聚合在所有层上。例如,在图3中,要从一个具有正确上下文的一帧的3层变压器中生成y7,它实际上需要等待x10到达,这是90ms的延迟。
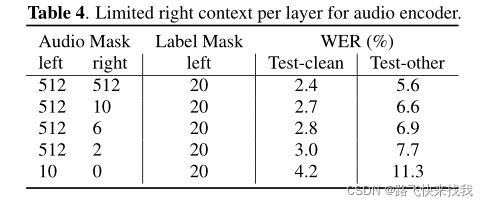
为了探索建模的右上下文影响,对每层固定的512帧的左上下文进行了比较,并与全注意力T-T模型进行了比较。从表4中可以看到,每层的正确上下文为6帧(约3.2秒的延迟),性能比全注意模型差16%左右。与可流媒体化的T-T模型相比,每层2帧的右上下文(大约1秒的延迟)带来了大约30%的改进。
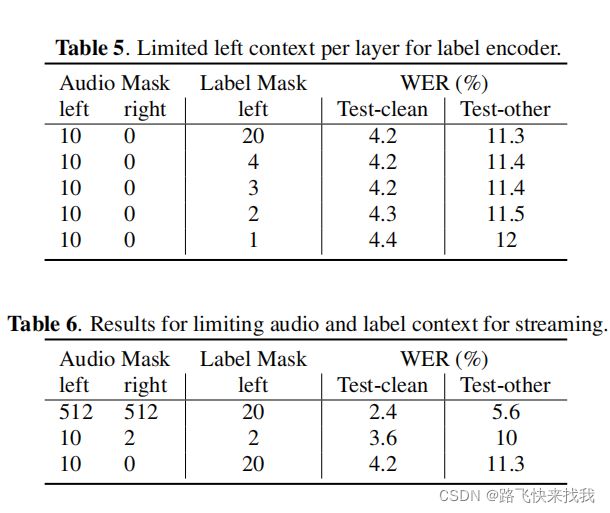
此外,还评估了在T-T标签编码器中使用的左上下文如何影响性能。在表5中,展示了限制每一层只使用三个以前的三个标签状态产生与每层使用20个状态的模型相似的精度。标签编码器的左上下文非常有限,很适合T-T模型。当使用全注意力T-T音频编码器时,当限制左标签状态时,看到了类似的趋势。最后,表6报告了使用有限的10帧左上下文时的结果,这将一步推断的时间复杂性降低到一个常数,展望未来框架,作为一种弥合左注意和全注意模型之间的差距的方法。
总结
在本文中,提出了Transformer Transducer模型,在RNN-T架构中嵌入基于Transformer的音频和标签编码,导致一个端到端模型,可以使用损失函数进行优化,有效地边缘化所有可能的对齐,非常适合时间同步解码。该模型实现了一种新的最先进的精度,并且通过限制在自我注意中使用的音频和标签上下文,可以很容易地用于流媒体语音识别。Transformer Transducer模型的训练速度比基于LSTM的RNN-T模型明显快,它们允许以一种灵活的方式交换识别精度和延迟。
2022.4.22