Hadoop家族系列文章,主要介绍Hadoop家族产品,常用的项目包括Hadoop, Hive, Pig, HBase, Sqoop, Mahout, Zookeeper, Avro, Ambari, Chukwa,新增加的项目包括,YARN, Hcatalog, Oozie, Cassandra, Hama, Whirr, Flume, Bigtop, Crunch, Hue等。
从2011年开始,中国进入大数据风起云涌的时代,以Hadoop为代表的家族软件,占据了大数据处理的广阔地盘。开源界及厂商,所有数据软件,无一不向Hadoop靠拢。Hadoop也从小众的高富帅领域,变成了大数据开发的标准。在Hadoop原有技术基础之上,出现了Hadoop家族产品,通过“大数据”概念不断创新,推出科技进步。
作为IT界的开发人员,我们也要跟上节奏,抓住机遇,跟着Hadoop一起雄起!
关于作者:
- 张丹(Conan), 程序员Java,R,PHP,Javascript
- weibo:@Conan_Z
- blog: http://blog.fens.me
- email: [email protected]
转载请注明出处:
http://blog.fens.me/hadoop-mahout-kmeans/

前言
Mahout是基于Hadoop用于机器学习的程序开发框架,Mahout封装了3大类的机器学习算法,其中包括聚类算法。kmeans是我们经常会提到用到的聚类算法之一,特别处理未知数据集的时,都会先聚类一下,看看数据集会有一些什么样的规则。
本文主要讲解,基于Mahout程序开发,实现分步式的kmeans算法。
目录
- 聚类算法kmeans
- Mahout开发环境介绍
- 用Mahout实现聚类算法kmeans
- 用R语言可视化结果
- 模板项目上传github
1. 聚类算法kmeans
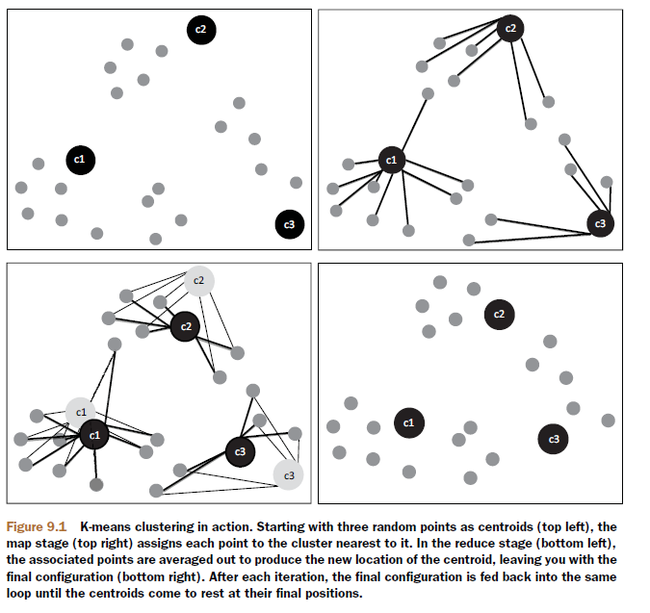
聚类分析是数据挖掘及机器学习领域内的重点问题之一,在数据挖掘、模式识别、决策支持、机器学习及图像分割等领域有广泛的应用,是最重要的数据分析方法之一。聚类是在给定的数据集合中寻找同类的数据子集合,每一个子集合形成一个类簇,同类簇中的数据具有更大的相似性。聚类算法大体上可分为基于划分的方法、基于层次的方法、基于密度的方法、基于网格的方法以及基于模型的方法。
k-means algorithm算法是一种得到最广泛使用的基于划分的聚类算法,把n个对象分为k个簇,以使簇内具有较高的相似度。相似度的计算根据一个簇中对象的平均值来进行。它与处理混合正态分布的最大期望算法很相似,因为他们都试图找到数据中自然聚类的中心。
算法首先随机地选择k个对象,每个对象初始地代表了一个簇的平均值或中心。对剩余的每个对象根据其与各个簇中心的距离,将它赋给最近的簇,然后重新计算每个簇的平均值。这个过程不断重复,直到准则函数收敛。
kmeans介绍摘自:http://zh.wikipedia.org/wiki/K平均算法
2. Mahout开发环境介绍
接上一篇文章:Mahout分步式程序开发 基于物品的协同过滤ItemCF
所有环境变量 和 系统配置 与上文一致!
3. 用Mahout实现聚类算法kmeans
实现步骤:
- 1. 准备数据文件: randomData.csv
- 2. Java程序:KmeansHadoop.java
- 3. 运行程序
- 4. 聚类结果解读
- 5. HDFS产生的目录
1). 准备数据文件: randomData.csv
数据文件randomData.csv,由R语言通过“随机正太分布函数”程序生成,单机内存实验请参考文章:
用Maven构建Mahout项目
原始数据文件:这里只截取了一部分数据。
~ vi datafile/randomData.csv
-0.883033363823402 -3.31967192630249
-2.39312626419456 3.34726861118871
2.66976353341256 1.85144276077058
-1.09922906899594 -6.06261735207489
-4.36361936997216 1.90509905380532
-0.00351835125495037 -0.610105996559153
-2.9962958796338 -3.60959839525735
-3.27529418132066 0.0230099799641799
2.17665594420569 6.77290756817957
-2.47862038335637 2.53431833167278
5.53654901906814 2.65089785582474
5.66257474538338 6.86783609641077
-0.558946883114376 1.22332819416237
5.11728525486132 3.74663871584768
1.91240516693351 2.95874731384062
-2.49747101306535 2.05006504756875
3.98781883213459 1.00780938946366
5.47470532716682 5.35084411045171
注:由于Mahout中kmeans算法,默认的分融符是” “(空格),因些我把逗号分隔的数据文件,改成以空格分隔。
2). Java程序:KmeansHadoop.java
kmeans的算法实现,请查看Mahout in Action。
package org.conan.mymahout.cluster08;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.mapred.JobConf;
import org.apache.mahout.clustering.conversion.InputDriver;
import org.apache.mahout.clustering.kmeans.KMeansDriver;
import org.apache.mahout.clustering.kmeans.RandomSeedGenerator;
import org.apache.mahout.common.distance.DistanceMeasure;
import org.apache.mahout.common.distance.EuclideanDistanceMeasure;
import org.apache.mahout.utils.clustering.ClusterDumper;
import org.conan.mymahout.hdfs.HdfsDAO;
import org.conan.mymahout.recommendation.ItemCFHadoop;
public class KmeansHadoop {
private static final String HDFS = "hdfs://192.168.1.210:9000";
public static void main(String[] args) throws Exception {
String localFile = "datafile/randomData.csv";
String inPath = HDFS + "/user/hdfs/mix_data";
String seqFile = inPath + "/seqfile";
String seeds = inPath + "/seeds";
String outPath = inPath + "/result/";
String clusteredPoints = outPath + "/clusteredPoints";
JobConf conf = config();
HdfsDAO hdfs = new HdfsDAO(HDFS, conf);
hdfs.rmr(inPath);
hdfs.mkdirs(inPath);
hdfs.copyFile(localFile, inPath);
hdfs.ls(inPath);
InputDriver.runJob(new Path(inPath), new Path(seqFile), "org.apache.mahout.math.RandomAccessSparseVector");
int k = 3;
Path seqFilePath = new Path(seqFile);
Path clustersSeeds = new Path(seeds);
DistanceMeasure measure = new EuclideanDistanceMeasure();
clustersSeeds = RandomSeedGenerator.buildRandom(conf, seqFilePath, clustersSeeds, k, measure);
KMeansDriver.run(conf, seqFilePath, clustersSeeds, new Path(outPath), measure, 0.01, 10, true, 0.01, false);
Path outGlobPath = new Path(outPath, "clusters-*-final");
Path clusteredPointsPath = new Path(clusteredPoints);
System.out.printf("Dumping out clusters from clusters: %s and clusteredPoints: %s\n", outGlobPath, clusteredPointsPath);
ClusterDumper clusterDumper = new ClusterDumper(outGlobPath, clusteredPointsPath);
clusterDumper.printClusters(null);
}
public static JobConf config() {
JobConf conf = new JobConf(ItemCFHadoop.class);
conf.setJobName("ItemCFHadoop");
conf.addResource("classpath:/hadoop/core-site.xml");
conf.addResource("classpath:/hadoop/hdfs-site.xml");
conf.addResource("classpath:/hadoop/mapred-site.xml");
return conf;
}
}
3). 运行程序
控制台输出:
Delete: hdfs://192.168.1.210:9000/user/hdfs/mix_data
Create: hdfs://192.168.1.210:9000/user/hdfs/mix_data
copy from: datafile/randomData.csv to hdfs://192.168.1.210:9000/user/hdfs/mix_data
ls: hdfs://192.168.1.210:9000/user/hdfs/mix_data
==========================================================
name: hdfs://192.168.1.210:9000/user/hdfs/mix_data/randomData.csv, folder: false, size: 36655
==========================================================
SLF4J: Failed to load class "org.slf4j.impl.StaticLoggerBinder".
SLF4J: Defaulting to no-operation (NOP) logger implementation
SLF4J: See http://www.slf4j.org/codes.html#StaticLoggerBinder for further details.
2013-10-14 15:39:31 org.apache.hadoop.util.NativeCodeLoader
警告: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
2013-10-14 15:39:31 org.apache.hadoop.mapred.JobClient copyAndConfigureFiles
警告: Use GenericOptionsParser for parsing the arguments. Applications should implement Tool for the same.
2013-10-14 15:39:31 org.apache.hadoop.mapreduce.lib.input.FileInputFormat listStatus
信息: Total input paths to process : 1
2013-10-14 15:39:31 org.apache.hadoop.io.compress.snappy.LoadSnappy
警告: Snappy native library not loaded
2013-10-14 15:39:31 org.apache.hadoop.mapred.JobClient monitorAndPrintJob
信息: Running job: job_local_0001
2013-10-14 15:39:31 org.apache.hadoop.mapred.Task initialize
信息: Using ResourceCalculatorPlugin : null
2013-10-14 15:39:31 org.apache.hadoop.mapred.Task done
信息: Task:attempt_local_0001_m_000000_0 is done. And is in the process of commiting
2013-10-14 15:39:31 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息:
2013-10-14 15:39:31 org.apache.hadoop.mapred.Task commit
信息: Task attempt_local_0001_m_000000_0 is allowed to commit now
2013-10-14 15:39:31 org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter commitTask
信息: Saved output of task 'attempt_local_0001_m_000000_0' to hdfs://192.168.1.210:9000/user/hdfs/mix_data/seqfile
2013-10-14 15:39:31 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息:
2013-10-14 15:39:31 org.apache.hadoop.mapred.Task sendDone
信息: Task 'attempt_local_0001_m_000000_0' done.
2013-10-14 15:39:32 org.apache.hadoop.mapred.JobClient monitorAndPrintJob
信息: map 100% reduce 0%
2013-10-14 15:39:32 org.apache.hadoop.mapred.JobClient monitorAndPrintJob
信息: Job complete: job_local_0001
2013-10-14 15:39:32 org.apache.hadoop.mapred.Counters log
信息: Counters: 11
2013-10-14 15:39:32 org.apache.hadoop.mapred.Counters log
信息: File Output Format Counters
2013-10-14 15:39:32 org.apache.hadoop.mapred.Counters log
信息: Bytes Written=31390
2013-10-14 15:39:32 org.apache.hadoop.mapred.Counters log
信息: File Input Format Counters
2013-10-14 15:39:32 org.apache.hadoop.mapred.Counters log
信息: Bytes Read=36655
2013-10-14 15:39:32 org.apache.hadoop.mapred.Counters log
信息: FileSystemCounters
2013-10-14 15:39:32 org.apache.hadoop.mapred.Counters log
信息: FILE_BYTES_READ=475910
2013-10-14 15:39:32 org.apache.hadoop.mapred.Counters log
信息: HDFS_BYTES_READ=36655
2013-10-14 15:39:32 org.apache.hadoop.mapred.Counters log
信息: FILE_BYTES_WRITTEN=506350
2013-10-14 15:39:32 org.apache.hadoop.mapred.Counters log
信息: HDFS_BYTES_WRITTEN=68045
2013-10-14 15:39:32 org.apache.hadoop.mapred.Counters log
信息: Map-Reduce Framework
2013-10-14 15:39:32 org.apache.hadoop.mapred.Counters log
信息: Map input records=1000
2013-10-14 15:39:32 org.apache.hadoop.mapred.Counters log
信息: Spilled Records=0
2013-10-14 15:39:32 org.apache.hadoop.mapred.Counters log
信息: Total committed heap usage (bytes)=188284928
2013-10-14 15:39:32 org.apache.hadoop.mapred.Counters log
信息: SPLIT_RAW_BYTES=124
2013-10-14 15:39:32 org.apache.hadoop.mapred.Counters log
信息: Map output records=1000
2013-10-14 15:39:32 org.apache.hadoop.io.compress.CodecPool getCompressor
信息: Got brand-new compressor
2013-10-14 15:39:32 org.apache.hadoop.io.compress.CodecPool getDecompressor
信息: Got brand-new decompressor
2013-10-14 15:39:32 org.apache.hadoop.mapred.JobClient copyAndConfigureFiles
警告: Use GenericOptionsParser for parsing the arguments. Applications should implement Tool for the same.
2013-10-14 15:39:32 org.apache.hadoop.mapreduce.lib.input.FileInputFormat listStatus
信息: Total input paths to process : 1
2013-10-14 15:39:32 org.apache.hadoop.mapred.JobClient monitorAndPrintJob
信息: Running job: job_local_0002
2013-10-14 15:39:32 org.apache.hadoop.mapred.Task initialize
信息: Using ResourceCalculatorPlugin : null
2013-10-14 15:39:32 org.apache.hadoop.mapred.MapTask$MapOutputBuffer
信息: io.sort.mb = 100
2013-10-14 15:39:32 org.apache.hadoop.mapred.MapTask$MapOutputBuffer
信息: data buffer = 79691776/99614720
2013-10-14 15:39:32 org.apache.hadoop.mapred.MapTask$MapOutputBuffer
信息: record buffer = 262144/327680
2013-10-14 15:39:33 org.apache.hadoop.mapred.MapTask$MapOutputBuffer flush
信息: Starting flush of map output
2013-10-14 15:39:33 org.apache.hadoop.mapred.MapTask$MapOutputBuffer sortAndSpill
信息: Finished spill 0
2013-10-14 15:39:33 org.apache.hadoop.mapred.Task done
信息: Task:attempt_local_0002_m_000000_0 is done. And is in the process of commiting
2013-10-14 15:39:33 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息:
2013-10-14 15:39:33 org.apache.hadoop.mapred.Task sendDone
信息: Task 'attempt_local_0002_m_000000_0' done.
2013-10-14 15:39:33 org.apache.hadoop.mapred.Task initialize
信息: Using ResourceCalculatorPlugin : null
2013-10-14 15:39:33 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息:
2013-10-14 15:39:33 org.apache.hadoop.mapred.Merger$MergeQueue merge
信息: Merging 1 sorted segments
2013-10-14 15:39:33 org.apache.hadoop.mapred.Merger$MergeQueue merge
信息: Down to the last merge-pass, with 1 segments left of total size: 623 bytes
2013-10-14 15:39:33 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息:
2013-10-14 15:39:33 org.apache.hadoop.mapred.Task done
信息: Task:attempt_local_0002_r_000000_0 is done. And is in the process of commiting
2013-10-14 15:39:33 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息:
2013-10-14 15:39:33 org.apache.hadoop.mapred.Task commit
信息: Task attempt_local_0002_r_000000_0 is allowed to commit now
2013-10-14 15:39:33 org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter commitTask
信息: Saved output of task 'attempt_local_0002_r_000000_0' to hdfs://192.168.1.210:9000/user/hdfs/mix_data/result/clusters-1
2013-10-14 15:39:33 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息: reduce > reduce
2013-10-14 15:39:33 org.apache.hadoop.mapred.Task sendDone
信息: Task 'attempt_local_0002_r_000000_0' done.
2013-10-14 15:39:33 org.apache.hadoop.mapred.JobClient monitorAndPrintJob
信息: map 100% reduce 100%
2013-10-14 15:39:33 org.apache.hadoop.mapred.JobClient monitorAndPrintJob
信息: Job complete: job_local_0002
2013-10-14 15:39:33 org.apache.hadoop.mapred.Counters log
信息: Counters: 19
2013-10-14 15:39:33 org.apache.hadoop.mapred.Counters log
信息: File Output Format Counters
2013-10-14 15:39:33 org.apache.hadoop.mapred.Counters log
信息: Bytes Written=695
2013-10-14 15:39:33 org.apache.hadoop.mapred.Counters log
信息: FileSystemCounters
2013-10-14 15:39:33 org.apache.hadoop.mapred.Counters log
信息: FILE_BYTES_READ=4239303
2013-10-14 15:39:33 org.apache.hadoop.mapred.Counters log
信息: HDFS_BYTES_READ=203963
2013-10-14 15:39:33 org.apache.hadoop.mapred.Counters log
信息: FILE_BYTES_WRITTEN=4457168
2013-10-14 15:39:33 org.apache.hadoop.mapred.Counters log
信息: HDFS_BYTES_WRITTEN=140321
2013-10-14 15:39:33 org.apache.hadoop.mapred.Counters log
信息: File Input Format Counters
2013-10-14 15:39:33 org.apache.hadoop.mapred.Counters log
信息: Bytes Read=31390
2013-10-14 15:39:33 org.apache.hadoop.mapred.Counters log
信息: Map-Reduce Framework
2013-10-14 15:39:33 org.apache.hadoop.mapred.Counters log
信息: Map output materialized bytes=627
2013-10-14 15:39:33 org.apache.hadoop.mapred.Counters log
信息: Map input records=1000
2013-10-14 15:39:33 org.apache.hadoop.mapred.Counters log
信息: Reduce shuffle bytes=0
2013-10-14 15:39:33 org.apache.hadoop.mapred.Counters log
信息: Spilled Records=6
2013-10-14 15:39:33 org.apache.hadoop.mapred.Counters log
信息: Map output bytes=612
2013-10-14 15:39:33 org.apache.hadoop.mapred.Counters log
信息: Total committed heap usage (bytes)=376569856
2013-10-14 15:39:33 org.apache.hadoop.mapred.Counters log
信息: SPLIT_RAW_BYTES=130
2013-10-14 15:39:33 org.apache.hadoop.mapred.Counters log
信息: Combine input records=0
2013-10-14 15:39:33 org.apache.hadoop.mapred.Counters log
信息: Reduce input records=3
2013-10-14 15:39:33 org.apache.hadoop.mapred.Counters log
信息: Reduce input groups=3
2013-10-14 15:39:33 org.apache.hadoop.mapred.Counters log
信息: Combine output records=0
2013-10-14 15:39:33 org.apache.hadoop.mapred.Counters log
信息: Reduce output records=3
2013-10-14 15:39:33 org.apache.hadoop.mapred.Counters log
信息: Map output records=3
2013-10-14 15:39:34 org.apache.hadoop.mapred.JobClient copyAndConfigureFiles
警告: Use GenericOptionsParser for parsing the arguments. Applications should implement Tool for the same.
2013-10-14 15:39:34 org.apache.hadoop.mapreduce.lib.input.FileInputFormat listStatus
信息: Total input paths to process : 1
2013-10-14 15:39:34 org.apache.hadoop.mapred.JobClient monitorAndPrintJob
信息: Running job: job_local_0003
2013-10-14 15:39:34 org.apache.hadoop.mapred.Task initialize
信息: Using ResourceCalculatorPlugin : null
2013-10-14 15:39:34 org.apache.hadoop.mapred.MapTask$MapOutputBuffer
信息: io.sort.mb = 100
2013-10-14 15:39:34 org.apache.hadoop.mapred.MapTask$MapOutputBuffer
信息: data buffer = 79691776/99614720
2013-10-14 15:39:34 org.apache.hadoop.mapred.MapTask$MapOutputBuffer
信息: record buffer = 262144/327680
2013-10-14 15:39:34 org.apache.hadoop.mapred.MapTask$MapOutputBuffer flush
信息: Starting flush of map output
2013-10-14 15:39:34 org.apache.hadoop.mapred.MapTask$MapOutputBuffer sortAndSpill
信息: Finished spill 0
2013-10-14 15:39:34 org.apache.hadoop.mapred.Task done
信息: Task:attempt_local_0003_m_000000_0 is done. And is in the process of commiting
2013-10-14 15:39:34 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息:
2013-10-14 15:39:34 org.apache.hadoop.mapred.Task sendDone
信息: Task 'attempt_local_0003_m_000000_0' done.
2013-10-14 15:39:34 org.apache.hadoop.mapred.Task initialize
信息: Using ResourceCalculatorPlugin : null
2013-10-14 15:39:34 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息:
2013-10-14 15:39:34 org.apache.hadoop.mapred.Merger$MergeQueue merge
信息: Merging 1 sorted segments
2013-10-14 15:39:34 org.apache.hadoop.mapred.Merger$MergeQueue merge
信息: Down to the last merge-pass, with 1 segments left of total size: 677 bytes
2013-10-14 15:39:34 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息:
2013-10-14 15:39:34 org.apache.hadoop.mapred.Task done
信息: Task:attempt_local_0003_r_000000_0 is done. And is in the process of commiting
2013-10-14 15:39:34 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息:
2013-10-14 15:39:34 org.apache.hadoop.mapred.Task commit
信息: Task attempt_local_0003_r_000000_0 is allowed to commit now
2013-10-14 15:39:34 org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter commitTask
信息: Saved output of task 'attempt_local_0003_r_000000_0' to hdfs://192.168.1.210:9000/user/hdfs/mix_data/result/clusters-2
2013-10-14 15:39:34 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息: reduce > reduce
2013-10-14 15:39:34 org.apache.hadoop.mapred.Task sendDone
信息: Task 'attempt_local_0003_r_000000_0' done.
2013-10-14 15:39:35 org.apache.hadoop.mapred.JobClient monitorAndPrintJob
信息: map 100% reduce 100%
2013-10-14 15:39:35 org.apache.hadoop.mapred.JobClient monitorAndPrintJob
信息: Job complete: job_local_0003
2013-10-14 15:39:35 org.apache.hadoop.mapred.Counters log
信息: Counters: 19
2013-10-14 15:39:35 org.apache.hadoop.mapred.Counters log
信息: File Output Format Counters
2013-10-14 15:39:35 org.apache.hadoop.mapred.Counters log
信息: Bytes Written=695
2013-10-14 15:39:35 org.apache.hadoop.mapred.Counters log
信息: FileSystemCounters
2013-10-14 15:39:35 org.apache.hadoop.mapred.Counters log
信息: FILE_BYTES_READ=7527467
2013-10-14 15:39:35 org.apache.hadoop.mapred.Counters log
信息: HDFS_BYTES_READ=271193
2013-10-14 15:39:35 org.apache.hadoop.mapred.Counters log
信息: FILE_BYTES_WRITTEN=7901744
2013-10-14 15:39:35 org.apache.hadoop.mapred.Counters log
信息: HDFS_BYTES_WRITTEN=142099
2013-10-14 15:39:35 org.apache.hadoop.mapred.Counters log
信息: File Input Format Counters
2013-10-14 15:39:35 org.apache.hadoop.mapred.Counters log
信息: Bytes Read=31390
2013-10-14 15:39:35 org.apache.hadoop.mapred.Counters log
信息: Map-Reduce Framework
2013-10-14 15:39:35 org.apache.hadoop.mapred.Counters log
信息: Map output materialized bytes=681
2013-10-14 15:39:35 org.apache.hadoop.mapred.Counters log
信息: Map input records=1000
2013-10-14 15:39:35 org.apache.hadoop.mapred.Counters log
信息: Reduce shuffle bytes=0
2013-10-14 15:39:35 org.apache.hadoop.mapred.Counters log
信息: Spilled Records=6
2013-10-14 15:39:35 org.apache.hadoop.mapred.Counters log
信息: Map output bytes=666
2013-10-14 15:39:35 org.apache.hadoop.mapred.Counters log
信息: Total committed heap usage (bytes)=575930368
2013-10-14 15:39:35 org.apache.hadoop.mapred.Counters log
信息: SPLIT_RAW_BYTES=130
2013-10-14 15:39:35 org.apache.hadoop.mapred.Counters log
信息: Combine input records=0
2013-10-14 15:39:35 org.apache.hadoop.mapred.Counters log
信息: Reduce input records=3
2013-10-14 15:39:35 org.apache.hadoop.mapred.Counters log
信息: Reduce input groups=3
2013-10-14 15:39:35 org.apache.hadoop.mapred.Counters log
信息: Combine output records=0
2013-10-14 15:39:35 org.apache.hadoop.mapred.Counters log
信息: Reduce output records=3
2013-10-14 15:39:35 org.apache.hadoop.mapred.Counters log
信息: Map output records=3
2013-10-14 15:39:35 org.apache.hadoop.mapred.JobClient copyAndConfigureFiles
警告: Use GenericOptionsParser for parsing the arguments. Applications should implement Tool for the same.
2013-10-14 15:39:35 org.apache.hadoop.mapreduce.lib.input.FileInputFormat listStatus
信息: Total input paths to process : 1
2013-10-14 15:39:35 org.apache.hadoop.mapred.JobClient monitorAndPrintJob
信息: Running job: job_local_0004
2013-10-14 15:39:35 org.apache.hadoop.mapred.Task initialize
信息: Using ResourceCalculatorPlugin : null
2013-10-14 15:39:35 org.apache.hadoop.mapred.MapTask$MapOutputBuffer
信息: io.sort.mb = 100
2013-10-14 15:39:35 org.apache.hadoop.mapred.MapTask$MapOutputBuffer
信息: data buffer = 79691776/99614720
2013-10-14 15:39:35 org.apache.hadoop.mapred.MapTask$MapOutputBuffer
信息: record buffer = 262144/327680
2013-10-14 15:39:35 org.apache.hadoop.mapred.MapTask$MapOutputBuffer flush
信息: Starting flush of map output
2013-10-14 15:39:35 org.apache.hadoop.mapred.MapTask$MapOutputBuffer sortAndSpill
信息: Finished spill 0
2013-10-14 15:39:35 org.apache.hadoop.mapred.Task done
信息: Task:attempt_local_0004_m_000000_0 is done. And is in the process of commiting
2013-10-14 15:39:35 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息:
2013-10-14 15:39:35 org.apache.hadoop.mapred.Task sendDone
信息: Task 'attempt_local_0004_m_000000_0' done.
2013-10-14 15:39:35 org.apache.hadoop.mapred.Task initialize
信息: Using ResourceCalculatorPlugin : null
2013-10-14 15:39:35 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息:
2013-10-14 15:39:35 org.apache.hadoop.mapred.Merger$MergeQueue merge
信息: Merging 1 sorted segments
2013-10-14 15:39:35 org.apache.hadoop.mapred.Merger$MergeQueue merge
信息: Down to the last merge-pass, with 1 segments left of total size: 677 bytes
2013-10-14 15:39:35 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息:
2013-10-14 15:39:35 org.apache.hadoop.mapred.Task done
信息: Task:attempt_local_0004_r_000000_0 is done. And is in the process of commiting
2013-10-14 15:39:35 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息:
2013-10-14 15:39:35 org.apache.hadoop.mapred.Task commit
信息: Task attempt_local_0004_r_000000_0 is allowed to commit now
2013-10-14 15:39:35 org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter commitTask
信息: Saved output of task 'attempt_local_0004_r_000000_0' to hdfs://192.168.1.210:9000/user/hdfs/mix_data/result/clusters-3
2013-10-14 15:39:35 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息: reduce > reduce
2013-10-14 15:39:35 org.apache.hadoop.mapred.Task sendDone
信息: Task 'attempt_local_0004_r_000000_0' done.
2013-10-14 15:39:36 org.apache.hadoop.mapred.JobClient monitorAndPrintJob
信息: map 100% reduce 100%
2013-10-14 15:39:36 org.apache.hadoop.mapred.JobClient monitorAndPrintJob
信息: Job complete: job_local_0004
2013-10-14 15:39:36 org.apache.hadoop.mapred.Counters log
信息: Counters: 19
2013-10-14 15:39:36 org.apache.hadoop.mapred.Counters log
信息: File Output Format Counters
2013-10-14 15:39:36 org.apache.hadoop.mapred.Counters log
信息: Bytes Written=695
2013-10-14 15:39:36 org.apache.hadoop.mapred.Counters log
信息: FileSystemCounters
2013-10-14 15:39:36 org.apache.hadoop.mapred.Counters log
信息: FILE_BYTES_READ=10815685
2013-10-14 15:39:36 org.apache.hadoop.mapred.Counters log
信息: HDFS_BYTES_READ=338143
2013-10-14 15:39:36 org.apache.hadoop.mapred.Counters log
信息: FILE_BYTES_WRITTEN=11346320
2013-10-14 15:39:36 org.apache.hadoop.mapred.Counters log
信息: HDFS_BYTES_WRITTEN=143877
2013-10-14 15:39:36 org.apache.hadoop.mapred.Counters log
信息: File Input Format Counters
2013-10-14 15:39:36 org.apache.hadoop.mapred.Counters log
信息: Bytes Read=31390
2013-10-14 15:39:36 org.apache.hadoop.mapred.Counters log
信息: Map-Reduce Framework
2013-10-14 15:39:36 org.apache.hadoop.mapred.Counters log
信息: Map output materialized bytes=681
2013-10-14 15:39:36 org.apache.hadoop.mapred.Counters log
信息: Map input records=1000
2013-10-14 15:39:36 org.apache.hadoop.mapred.Counters log
信息: Reduce shuffle bytes=0
2013-10-14 15:39:36 org.apache.hadoop.mapred.Counters log
信息: Spilled Records=6
2013-10-14 15:39:36 org.apache.hadoop.mapred.Counters log
信息: Map output bytes=666
2013-10-14 15:39:36 org.apache.hadoop.mapred.Counters log
信息: Total committed heap usage (bytes)=775290880
2013-10-14 15:39:36 org.apache.hadoop.mapred.Counters log
信息: SPLIT_RAW_BYTES=130
2013-10-14 15:39:36 org.apache.hadoop.mapred.Counters log
信息: Combine input records=0
2013-10-14 15:39:36 org.apache.hadoop.mapred.Counters log
信息: Reduce input records=3
2013-10-14 15:39:36 org.apache.hadoop.mapred.Counters log
信息: Reduce input groups=3
2013-10-14 15:39:36 org.apache.hadoop.mapred.Counters log
信息: Combine output records=0
2013-10-14 15:39:36 org.apache.hadoop.mapred.Counters log
信息: Reduce output records=3
2013-10-14 15:39:36 org.apache.hadoop.mapred.Counters log
信息: Map output records=3
2013-10-14 15:39:36 org.apache.hadoop.mapred.JobClient copyAndConfigureFiles
警告: Use GenericOptionsParser for parsing the arguments. Applications should implement Tool for the same.
2013-10-14 15:39:36 org.apache.hadoop.mapreduce.lib.input.FileInputFormat listStatus
信息: Total input paths to process : 1
2013-10-14 15:39:36 org.apache.hadoop.mapred.JobClient monitorAndPrintJob
信息: Running job: job_local_0005
2013-10-14 15:39:36 org.apache.hadoop.mapred.Task initialize
信息: Using ResourceCalculatorPlugin : null
2013-10-14 15:39:36 org.apache.hadoop.mapred.MapTask$MapOutputBuffer
信息: io.sort.mb = 100
2013-10-14 15:39:36 org.apache.hadoop.mapred.MapTask$MapOutputBuffer
信息: data buffer = 79691776/99614720
2013-10-14 15:39:36 org.apache.hadoop.mapred.MapTask$MapOutputBuffer
信息: record buffer = 262144/327680
2013-10-14 15:39:36 org.apache.hadoop.mapred.MapTask$MapOutputBuffer flush
信息: Starting flush of map output
2013-10-14 15:39:36 org.apache.hadoop.mapred.MapTask$MapOutputBuffer sortAndSpill
信息: Finished spill 0
2013-10-14 15:39:36 org.apache.hadoop.mapred.Task done
信息: Task:attempt_local_0005_m_000000_0 is done. And is in the process of commiting
2013-10-14 15:39:36 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息:
2013-10-14 15:39:36 org.apache.hadoop.mapred.Task sendDone
信息: Task 'attempt_local_0005_m_000000_0' done.
2013-10-14 15:39:36 org.apache.hadoop.mapred.Task initialize
信息: Using ResourceCalculatorPlugin : null
2013-10-14 15:39:36 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息:
2013-10-14 15:39:36 org.apache.hadoop.mapred.Merger$MergeQueue merge
信息: Merging 1 sorted segments
2013-10-14 15:39:36 org.apache.hadoop.mapred.Merger$MergeQueue merge
信息: Down to the last merge-pass, with 1 segments left of total size: 677 bytes
2013-10-14 15:39:36 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息:
2013-10-14 15:39:36 org.apache.hadoop.mapred.Task done
信息: Task:attempt_local_0005_r_000000_0 is done. And is in the process of commiting
2013-10-14 15:39:36 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息:
2013-10-14 15:39:36 org.apache.hadoop.mapred.Task commit
信息: Task attempt_local_0005_r_000000_0 is allowed to commit now
2013-10-14 15:39:36 org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter commitTask
信息: Saved output of task 'attempt_local_0005_r_000000_0' to hdfs://192.168.1.210:9000/user/hdfs/mix_data/result/clusters-4
2013-10-14 15:39:36 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息: reduce > reduce
2013-10-14 15:39:36 org.apache.hadoop.mapred.Task sendDone
信息: Task 'attempt_local_0005_r_000000_0' done.
2013-10-14 15:39:37 org.apache.hadoop.mapred.JobClient monitorAndPrintJob
信息: map 100% reduce 100%
2013-10-14 15:39:37 org.apache.hadoop.mapred.JobClient monitorAndPrintJob
信息: Job complete: job_local_0005
2013-10-14 15:39:37 org.apache.hadoop.mapred.Counters log
信息: Counters: 19
2013-10-14 15:39:37 org.apache.hadoop.mapred.Counters log
信息: File Output Format Counters
2013-10-14 15:39:37 org.apache.hadoop.mapred.Counters log
信息: Bytes Written=695
2013-10-14 15:39:37 org.apache.hadoop.mapred.Counters log
信息: FileSystemCounters
2013-10-14 15:39:37 org.apache.hadoop.mapred.Counters log
信息: FILE_BYTES_READ=14103903
2013-10-14 15:39:37 org.apache.hadoop.mapred.Counters log
信息: HDFS_BYTES_READ=405093
2013-10-14 15:39:37 org.apache.hadoop.mapred.Counters log
信息: FILE_BYTES_WRITTEN=14790888
2013-10-14 15:39:37 org.apache.hadoop.mapred.Counters log
信息: HDFS_BYTES_WRITTEN=145655
2013-10-14 15:39:37 org.apache.hadoop.mapred.Counters log
信息: File Input Format Counters
2013-10-14 15:39:37 org.apache.hadoop.mapred.Counters log
信息: Bytes Read=31390
2013-10-14 15:39:37 org.apache.hadoop.mapred.Counters log
信息: Map-Reduce Framework
2013-10-14 15:39:37 org.apache.hadoop.mapred.Counters log
信息: Map output materialized bytes=681
2013-10-14 15:39:37 org.apache.hadoop.mapred.Counters log
信息: Map input records=1000
2013-10-14 15:39:37 org.apache.hadoop.mapred.Counters log
信息: Reduce shuffle bytes=0
2013-10-14 15:39:37 org.apache.hadoop.mapred.Counters log
信息: Spilled Records=6
2013-10-14 15:39:37 org.apache.hadoop.mapred.Counters log
信息: Map output bytes=666
2013-10-14 15:39:37 org.apache.hadoop.mapred.Counters log
信息: Total committed heap usage (bytes)=974651392
2013-10-14 15:39:37 org.apache.hadoop.mapred.Counters log
信息: SPLIT_RAW_BYTES=130
2013-10-14 15:39:37 org.apache.hadoop.mapred.Counters log
信息: Combine input records=0
2013-10-14 15:39:37 org.apache.hadoop.mapred.Counters log
信息: Reduce input records=3
2013-10-14 15:39:37 org.apache.hadoop.mapred.Counters log
信息: Reduce input groups=3
2013-10-14 15:39:37 org.apache.hadoop.mapred.Counters log
信息: Combine output records=0
2013-10-14 15:39:37 org.apache.hadoop.mapred.Counters log
信息: Reduce output records=3
2013-10-14 15:39:37 org.apache.hadoop.mapred.Counters log
信息: Map output records=3
2013-10-14 15:39:37 org.apache.hadoop.mapred.JobClient copyAndConfigureFiles
警告: Use GenericOptionsParser for parsing the arguments. Applications should implement Tool for the same.
2013-10-14 15:39:37 org.apache.hadoop.mapreduce.lib.input.FileInputFormat listStatus
信息: Total input paths to process : 1
2013-10-14 15:39:37 org.apache.hadoop.mapred.JobClient monitorAndPrintJob
信息: Running job: job_local_0006
2013-10-14 15:39:37 org.apache.hadoop.mapred.Task initialize
信息: Using ResourceCalculatorPlugin : null
2013-10-14 15:39:37 org.apache.hadoop.mapred.MapTask$MapOutputBuffer
信息: io.sort.mb = 100
2013-10-14 15:39:37 org.apache.hadoop.mapred.MapTask$MapOutputBuffer
信息: data buffer = 79691776/99614720
2013-10-14 15:39:37 org.apache.hadoop.mapred.MapTask$MapOutputBuffer
信息: record buffer = 262144/327680
2013-10-14 15:39:37 org.apache.hadoop.mapred.MapTask$MapOutputBuffer flush
信息: Starting flush of map output
2013-10-14 15:39:37 org.apache.hadoop.mapred.MapTask$MapOutputBuffer sortAndSpill
信息: Finished spill 0
2013-10-14 15:39:37 org.apache.hadoop.mapred.Task done
信息: Task:attempt_local_0006_m_000000_0 is done. And is in the process of commiting
2013-10-14 15:39:37 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息:
2013-10-14 15:39:37 org.apache.hadoop.mapred.Task sendDone
信息: Task 'attempt_local_0006_m_000000_0' done.
2013-10-14 15:39:37 org.apache.hadoop.mapred.Task initialize
信息: Using ResourceCalculatorPlugin : null
2013-10-14 15:39:37 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息:
2013-10-14 15:39:37 org.apache.hadoop.mapred.Merger$MergeQueue merge
信息: Merging 1 sorted segments
2013-10-14 15:39:37 org.apache.hadoop.mapred.Merger$MergeQueue merge
信息: Down to the last merge-pass, with 1 segments left of total size: 677 bytes
2013-10-14 15:39:37 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息:
2013-10-14 15:39:37 org.apache.hadoop.mapred.Task done
信息: Task:attempt_local_0006_r_000000_0 is done. And is in the process of commiting
2013-10-14 15:39:37 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息:
2013-10-14 15:39:37 org.apache.hadoop.mapred.Task commit
信息: Task attempt_local_0006_r_000000_0 is allowed to commit now
2013-10-14 15:39:37 org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter commitTask
信息: Saved output of task 'attempt_local_0006_r_000000_0' to hdfs://192.168.1.210:9000/user/hdfs/mix_data/result/clusters-5
2013-10-14 15:39:37 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息: reduce > reduce
2013-10-14 15:39:37 org.apache.hadoop.mapred.Task sendDone
信息: Task 'attempt_local_0006_r_000000_0' done.
2013-10-14 15:39:38 org.apache.hadoop.mapred.JobClient monitorAndPrintJob
信息: map 100% reduce 100%
2013-10-14 15:39:38 org.apache.hadoop.mapred.JobClient monitorAndPrintJob
信息: Job complete: job_local_0006
2013-10-14 15:39:38 org.apache.hadoop.mapred.Counters log
信息: Counters: 19
2013-10-14 15:39:38 org.apache.hadoop.mapred.Counters log
信息: File Output Format Counters
2013-10-14 15:39:38 org.apache.hadoop.mapred.Counters log
信息: Bytes Written=695
2013-10-14 15:39:38 org.apache.hadoop.mapred.Counters log
信息: FileSystemCounters
2013-10-14 15:39:38 org.apache.hadoop.mapred.Counters log
信息: FILE_BYTES_READ=17392121
2013-10-14 15:39:38 org.apache.hadoop.mapred.Counters log
信息: HDFS_BYTES_READ=472043
2013-10-14 15:39:38 org.apache.hadoop.mapred.Counters log
信息: FILE_BYTES_WRITTEN=18235456
2013-10-14 15:39:38 org.apache.hadoop.mapred.Counters log
信息: HDFS_BYTES_WRITTEN=147433
2013-10-14 15:39:38 org.apache.hadoop.mapred.Counters log
信息: File Input Format Counters
2013-10-14 15:39:38 org.apache.hadoop.mapred.Counters log
信息: Bytes Read=31390
2013-10-14 15:39:38 org.apache.hadoop.mapred.Counters log
信息: Map-Reduce Framework
2013-10-14 15:39:38 org.apache.hadoop.mapred.Counters log
信息: Map output materialized bytes=681
2013-10-14 15:39:38 org.apache.hadoop.mapred.Counters log
信息: Map input records=1000
2013-10-14 15:39:38 org.apache.hadoop.mapred.Counters log
信息: Reduce shuffle bytes=0
2013-10-14 15:39:38 org.apache.hadoop.mapred.Counters log
信息: Spilled Records=6
2013-10-14 15:39:38 org.apache.hadoop.mapred.Counters log
信息: Map output bytes=666
2013-10-14 15:39:38 org.apache.hadoop.mapred.Counters log
信息: Total committed heap usage (bytes)=1174011904
2013-10-14 15:39:38 org.apache.hadoop.mapred.Counters log
信息: SPLIT_RAW_BYTES=130
2013-10-14 15:39:38 org.apache.hadoop.mapred.Counters log
信息: Combine input records=0
2013-10-14 15:39:38 org.apache.hadoop.mapred.Counters log
信息: Reduce input records=3
2013-10-14 15:39:38 org.apache.hadoop.mapred.Counters log
信息: Reduce input groups=3
2013-10-14 15:39:38 org.apache.hadoop.mapred.Counters log
信息: Combine output records=0
2013-10-14 15:39:38 org.apache.hadoop.mapred.Counters log
信息: Reduce output records=3
2013-10-14 15:39:38 org.apache.hadoop.mapred.Counters log
信息: Map output records=3
2013-10-14 15:39:38 org.apache.hadoop.mapred.JobClient copyAndConfigureFiles
警告: Use GenericOptionsParser for parsing the arguments. Applications should implement Tool for the same.
2013-10-14 15:39:38 org.apache.hadoop.mapreduce.lib.input.FileInputFormat listStatus
信息: Total input paths to process : 1
2013-10-14 15:39:38 org.apache.hadoop.mapred.JobClient monitorAndPrintJob
信息: Running job: job_local_0007
2013-10-14 15:39:38 org.apache.hadoop.mapred.Task initialize
信息: Using ResourceCalculatorPlugin : null
2013-10-14 15:39:38 org.apache.hadoop.mapred.MapTask$MapOutputBuffer
信息: io.sort.mb = 100
2013-10-14 15:39:38 org.apache.hadoop.mapred.MapTask$MapOutputBuffer
信息: data buffer = 79691776/99614720
2013-10-14 15:39:38 org.apache.hadoop.mapred.MapTask$MapOutputBuffer
信息: record buffer = 262144/327680
2013-10-14 15:39:38 org.apache.hadoop.mapred.MapTask$MapOutputBuffer flush
信息: Starting flush of map output
2013-10-14 15:39:38 org.apache.hadoop.mapred.MapTask$MapOutputBuffer sortAndSpill
信息: Finished spill 0
2013-10-14 15:39:38 org.apache.hadoop.mapred.Task done
信息: Task:attempt_local_0007_m_000000_0 is done. And is in the process of commiting
2013-10-14 15:39:38 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息:
2013-10-14 15:39:38 org.apache.hadoop.mapred.Task sendDone
信息: Task 'attempt_local_0007_m_000000_0' done.
2013-10-14 15:39:38 org.apache.hadoop.mapred.Task initialize
信息: Using ResourceCalculatorPlugin : null
2013-10-14 15:39:38 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息:
2013-10-14 15:39:38 org.apache.hadoop.mapred.Merger$MergeQueue merge
信息: Merging 1 sorted segments
2013-10-14 15:39:38 org.apache.hadoop.mapred.Merger$MergeQueue merge
信息: Down to the last merge-pass, with 1 segments left of total size: 677 bytes
2013-10-14 15:39:38 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息:
2013-10-14 15:39:38 org.apache.hadoop.mapred.Task done
信息: Task:attempt_local_0007_r_000000_0 is done. And is in the process of commiting
2013-10-14 15:39:38 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息:
2013-10-14 15:39:38 org.apache.hadoop.mapred.Task commit
信息: Task attempt_local_0007_r_000000_0 is allowed to commit now
2013-10-14 15:39:38 org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter commitTask
信息: Saved output of task 'attempt_local_0007_r_000000_0' to hdfs://192.168.1.210:9000/user/hdfs/mix_data/result/clusters-6
2013-10-14 15:39:38 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息: reduce > reduce
2013-10-14 15:39:38 org.apache.hadoop.mapred.Task sendDone
信息: Task 'attempt_local_0007_r_000000_0' done.
2013-10-14 15:39:39 org.apache.hadoop.mapred.JobClient monitorAndPrintJob
信息: map 100% reduce 100%
2013-10-14 15:39:39 org.apache.hadoop.mapred.JobClient monitorAndPrintJob
信息: Job complete: job_local_0007
2013-10-14 15:39:39 org.apache.hadoop.mapred.Counters log
信息: Counters: 19
2013-10-14 15:39:39 org.apache.hadoop.mapred.Counters log
信息: File Output Format Counters
2013-10-14 15:39:39 org.apache.hadoop.mapred.Counters log
信息: Bytes Written=695
2013-10-14 15:39:39 org.apache.hadoop.mapred.Counters log
信息: FileSystemCounters
2013-10-14 15:39:39 org.apache.hadoop.mapred.Counters log
信息: FILE_BYTES_READ=20680339
2013-10-14 15:39:39 org.apache.hadoop.mapred.Counters log
信息: HDFS_BYTES_READ=538993
2013-10-14 15:39:39 org.apache.hadoop.mapred.Counters log
信息: FILE_BYTES_WRITTEN=21680040
2013-10-14 15:39:39 org.apache.hadoop.mapred.Counters log
信息: HDFS_BYTES_WRITTEN=149211
2013-10-14 15:39:39 org.apache.hadoop.mapred.Counters log
信息: File Input Format Counters
2013-10-14 15:39:39 org.apache.hadoop.mapred.Counters log
信息: Bytes Read=31390
2013-10-14 15:39:39 org.apache.hadoop.mapred.Counters log
信息: Map-Reduce Framework
2013-10-14 15:39:39 org.apache.hadoop.mapred.Counters log
信息: Map output materialized bytes=681
2013-10-14 15:39:39 org.apache.hadoop.mapred.Counters log
信息: Map input records=1000
2013-10-14 15:39:39 org.apache.hadoop.mapred.Counters log
信息: Reduce shuffle bytes=0
2013-10-14 15:39:39 org.apache.hadoop.mapred.Counters log
信息: Spilled Records=6
2013-10-14 15:39:39 org.apache.hadoop.mapred.Counters log
信息: Map output bytes=666
2013-10-14 15:39:39 org.apache.hadoop.mapred.Counters log
信息: Total committed heap usage (bytes)=1373372416
2013-10-14 15:39:39 org.apache.hadoop.mapred.Counters log
信息: SPLIT_RAW_BYTES=130
2013-10-14 15:39:39 org.apache.hadoop.mapred.Counters log
信息: Combine input records=0
2013-10-14 15:39:39 org.apache.hadoop.mapred.Counters log
信息: Reduce input records=3
2013-10-14 15:39:39 org.apache.hadoop.mapred.Counters log
信息: Reduce input groups=3
2013-10-14 15:39:39 org.apache.hadoop.mapred.Counters log
信息: Combine output records=0
2013-10-14 15:39:39 org.apache.hadoop.mapred.Counters log
信息: Reduce output records=3
2013-10-14 15:39:39 org.apache.hadoop.mapred.Counters log
信息: Map output records=3
2013-10-14 15:39:39 org.apache.hadoop.mapred.JobClient copyAndConfigureFiles
警告: Use GenericOptionsParser for parsing the arguments. Applications should implement Tool for the same.
2013-10-14 15:39:39 org.apache.hadoop.mapreduce.lib.input.FileInputFormat listStatus
信息: Total input paths to process : 1
2013-10-14 15:39:39 org.apache.hadoop.mapred.JobClient monitorAndPrintJob
信息: Running job: job_local_0008
2013-10-14 15:39:39 org.apache.hadoop.mapred.Task initialize
信息: Using ResourceCalculatorPlugin : null
2013-10-14 15:39:39 org.apache.hadoop.mapred.MapTask$MapOutputBuffer
信息: io.sort.mb = 100
2013-10-14 15:39:39 org.apache.hadoop.mapred.MapTask$MapOutputBuffer
信息: data buffer = 79691776/99614720
2013-10-14 15:39:39 org.apache.hadoop.mapred.MapTask$MapOutputBuffer
信息: record buffer = 262144/327680
2013-10-14 15:39:39 org.apache.hadoop.mapred.MapTask$MapOutputBuffer flush
信息: Starting flush of map output
2013-10-14 15:39:40 org.apache.hadoop.mapred.MapTask$MapOutputBuffer sortAndSpill
信息: Finished spill 0
2013-10-14 15:39:40 org.apache.hadoop.mapred.Task done
信息: Task:attempt_local_0008_m_000000_0 is done. And is in the process of commiting
2013-10-14 15:39:40 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息:
2013-10-14 15:39:40 org.apache.hadoop.mapred.Task sendDone
信息: Task 'attempt_local_0008_m_000000_0' done.
2013-10-14 15:39:40 org.apache.hadoop.mapred.Task initialize
信息: Using ResourceCalculatorPlugin : null
2013-10-14 15:39:40 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息:
2013-10-14 15:39:40 org.apache.hadoop.mapred.Merger$MergeQueue merge
信息: Merging 1 sorted segments
2013-10-14 15:39:40 org.apache.hadoop.mapred.Merger$MergeQueue merge
信息: Down to the last merge-pass, with 1 segments left of total size: 677 bytes
2013-10-14 15:39:40 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息:
2013-10-14 15:39:40 org.apache.hadoop.mapred.Task done
信息: Task:attempt_local_0008_r_000000_0 is done. And is in the process of commiting
2013-10-14 15:39:40 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息:
2013-10-14 15:39:40 org.apache.hadoop.mapred.Task commit
信息: Task attempt_local_0008_r_000000_0 is allowed to commit now
2013-10-14 15:39:40 org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter commitTask
信息: Saved output of task 'attempt_local_0008_r_000000_0' to hdfs://192.168.1.210:9000/user/hdfs/mix_data/result/clusters-7
2013-10-14 15:39:40 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息: reduce > reduce
2013-10-14 15:39:40 org.apache.hadoop.mapred.Task sendDone
信息: Task 'attempt_local_0008_r_000000_0' done.
2013-10-14 15:39:40 org.apache.hadoop.mapred.JobClient monitorAndPrintJob
信息: map 100% reduce 100%
2013-10-14 15:39:40 org.apache.hadoop.mapred.JobClient monitorAndPrintJob
信息: Job complete: job_local_0008
2013-10-14 15:39:40 org.apache.hadoop.mapred.Counters log
信息: Counters: 19
2013-10-14 15:39:40 org.apache.hadoop.mapred.Counters log
信息: File Output Format Counters
2013-10-14 15:39:40 org.apache.hadoop.mapred.Counters log
信息: Bytes Written=695
2013-10-14 15:39:40 org.apache.hadoop.mapred.Counters log
信息: FileSystemCounters
2013-10-14 15:39:40 org.apache.hadoop.mapred.Counters log
信息: FILE_BYTES_READ=23968557
2013-10-14 15:39:40 org.apache.hadoop.mapred.Counters log
信息: HDFS_BYTES_READ=605943
2013-10-14 15:39:40 org.apache.hadoop.mapred.Counters log
信息: FILE_BYTES_WRITTEN=25124624
2013-10-14 15:39:40 org.apache.hadoop.mapred.Counters log
信息: HDFS_BYTES_WRITTEN=150989
2013-10-14 15:39:40 org.apache.hadoop.mapred.Counters log
信息: File Input Format Counters
2013-10-14 15:39:40 org.apache.hadoop.mapred.Counters log
信息: Bytes Read=31390
2013-10-14 15:39:40 org.apache.hadoop.mapred.Counters log
信息: Map-Reduce Framework
2013-10-14 15:39:40 org.apache.hadoop.mapred.Counters log
信息: Map output materialized bytes=681
2013-10-14 15:39:40 org.apache.hadoop.mapred.Counters log
信息: Map input records=1000
2013-10-14 15:39:40 org.apache.hadoop.mapred.Counters log
信息: Reduce shuffle bytes=0
2013-10-14 15:39:40 org.apache.hadoop.mapred.Counters log
信息: Spilled Records=6
2013-10-14 15:39:40 org.apache.hadoop.mapred.Counters log
信息: Map output bytes=666
2013-10-14 15:39:40 org.apache.hadoop.mapred.Counters log
信息: Total committed heap usage (bytes)=1572732928
2013-10-14 15:39:40 org.apache.hadoop.mapred.Counters log
信息: SPLIT_RAW_BYTES=130
2013-10-14 15:39:40 org.apache.hadoop.mapred.Counters log
信息: Combine input records=0
2013-10-14 15:39:40 org.apache.hadoop.mapred.Counters log
信息: Reduce input records=3
2013-10-14 15:39:40 org.apache.hadoop.mapred.Counters log
信息: Reduce input groups=3
2013-10-14 15:39:40 org.apache.hadoop.mapred.Counters log
信息: Combine output records=0
2013-10-14 15:39:40 org.apache.hadoop.mapred.Counters log
信息: Reduce output records=3
2013-10-14 15:39:40 org.apache.hadoop.mapred.Counters log
信息: Map output records=3
2013-10-14 15:39:41 org.apache.hadoop.mapred.JobClient copyAndConfigureFiles
警告: Use GenericOptionsParser for parsing the arguments. Applications should implement Tool for the same.
2013-10-14 15:39:41 org.apache.hadoop.mapreduce.lib.input.FileInputFormat listStatus
信息: Total input paths to process : 1
2013-10-14 15:39:41 org.apache.hadoop.mapred.JobClient monitorAndPrintJob
信息: Running job: job_local_0009
2013-10-14 15:39:41 org.apache.hadoop.mapred.Task initialize
信息: Using ResourceCalculatorPlugin : null
2013-10-14 15:39:41 org.apache.hadoop.mapred.MapTask$MapOutputBuffer
信息: io.sort.mb = 100
2013-10-14 15:39:41 org.apache.hadoop.mapred.MapTask$MapOutputBuffer
信息: data buffer = 79691776/99614720
2013-10-14 15:39:41 org.apache.hadoop.mapred.MapTask$MapOutputBuffer
信息: record buffer = 262144/327680
2013-10-14 15:39:41 org.apache.hadoop.mapred.MapTask$MapOutputBuffer flush
信息: Starting flush of map output
2013-10-14 15:39:41 org.apache.hadoop.mapred.MapTask$MapOutputBuffer sortAndSpill
信息: Finished spill 0
2013-10-14 15:39:41 org.apache.hadoop.mapred.Task done
信息: Task:attempt_local_0009_m_000000_0 is done. And is in the process of commiting
2013-10-14 15:39:41 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息:
2013-10-14 15:39:41 org.apache.hadoop.mapred.Task sendDone
信息: Task 'attempt_local_0009_m_000000_0' done.
2013-10-14 15:39:41 org.apache.hadoop.mapred.Task initialize
信息: Using ResourceCalculatorPlugin : null
2013-10-14 15:39:41 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息:
2013-10-14 15:39:41 org.apache.hadoop.mapred.Merger$MergeQueue merge
信息: Merging 1 sorted segments
2013-10-14 15:39:41 org.apache.hadoop.mapred.Merger$MergeQueue merge
信息: Down to the last merge-pass, with 1 segments left of total size: 677 bytes
2013-10-14 15:39:41 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息:
2013-10-14 15:39:41 org.apache.hadoop.mapred.Task done
信息: Task:attempt_local_0009_r_000000_0 is done. And is in the process of commiting
2013-10-14 15:39:41 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息:
2013-10-14 15:39:41 org.apache.hadoop.mapred.Task commit
信息: Task attempt_local_0009_r_000000_0 is allowed to commit now
2013-10-14 15:39:41 org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter commitTask
信息: Saved output of task 'attempt_local_0009_r_000000_0' to hdfs://192.168.1.210:9000/user/hdfs/mix_data/result/clusters-8
2013-10-14 15:39:41 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息: reduce > reduce
2013-10-14 15:39:41 org.apache.hadoop.mapred.Task sendDone
信息: Task 'attempt_local_0009_r_000000_0' done.
2013-10-14 15:39:42 org.apache.hadoop.mapred.JobClient monitorAndPrintJob
信息: map 100% reduce 100%
2013-10-14 15:39:42 org.apache.hadoop.mapred.JobClient monitorAndPrintJob
信息: Job complete: job_local_0009
2013-10-14 15:39:42 org.apache.hadoop.mapred.Counters log
信息: Counters: 19
2013-10-14 15:39:42 org.apache.hadoop.mapred.Counters log
信息: File Output Format Counters
2013-10-14 15:39:42 org.apache.hadoop.mapred.Counters log
信息: Bytes Written=695
2013-10-14 15:39:42 org.apache.hadoop.mapred.Counters log
信息: FileSystemCounters
2013-10-14 15:39:42 org.apache.hadoop.mapred.Counters log
信息: FILE_BYTES_READ=27256775
2013-10-14 15:39:42 org.apache.hadoop.mapred.Counters log
信息: HDFS_BYTES_READ=673669
2013-10-14 15:39:42 org.apache.hadoop.mapred.Counters log
信息: FILE_BYTES_WRITTEN=28569192
2013-10-14 15:39:42 org.apache.hadoop.mapred.Counters log
信息: HDFS_BYTES_WRITTEN=152767
2013-10-14 15:39:42 org.apache.hadoop.mapred.Counters log
信息: File Input Format Counters
2013-10-14 15:39:42 org.apache.hadoop.mapred.Counters log
信息: Bytes Read=31390
2013-10-14 15:39:42 org.apache.hadoop.mapred.Counters log
信息: Map-Reduce Framework
2013-10-14 15:39:42 org.apache.hadoop.mapred.Counters log
信息: Map output materialized bytes=681
2013-10-14 15:39:42 org.apache.hadoop.mapred.Counters log
信息: Map input records=1000
2013-10-14 15:39:42 org.apache.hadoop.mapred.Counters log
信息: Reduce shuffle bytes=0
2013-10-14 15:39:42 org.apache.hadoop.mapred.Counters log
信息: Spilled Records=6
2013-10-14 15:39:42 org.apache.hadoop.mapred.Counters log
信息: Map output bytes=666
2013-10-14 15:39:42 org.apache.hadoop.mapred.Counters log
信息: Total committed heap usage (bytes)=1772093440
2013-10-14 15:39:42 org.apache.hadoop.mapred.Counters log
信息: SPLIT_RAW_BYTES=130
2013-10-14 15:39:42 org.apache.hadoop.mapred.Counters log
信息: Combine input records=0
2013-10-14 15:39:42 org.apache.hadoop.mapred.Counters log
信息: Reduce input records=3
2013-10-14 15:39:42 org.apache.hadoop.mapred.Counters log
信息: Reduce input groups=3
2013-10-14 15:39:42 org.apache.hadoop.mapred.Counters log
信息: Combine output records=0
2013-10-14 15:39:42 org.apache.hadoop.mapred.Counters log
信息: Reduce output records=3
2013-10-14 15:39:42 org.apache.hadoop.mapred.Counters log
信息: Map output records=3
2013-10-14 15:39:42 org.apache.hadoop.mapred.JobClient copyAndConfigureFiles
警告: Use GenericOptionsParser for parsing the arguments. Applications should implement Tool for the same.
2013-10-14 15:39:42 org.apache.hadoop.mapreduce.lib.input.FileInputFormat listStatus
信息: Total input paths to process : 1
2013-10-14 15:39:42 org.apache.hadoop.mapred.JobClient monitorAndPrintJob
信息: Running job: job_local_0010
2013-10-14 15:39:42 org.apache.hadoop.mapred.Task initialize
信息: Using ResourceCalculatorPlugin : null
2013-10-14 15:39:42 org.apache.hadoop.mapred.MapTask$MapOutputBuffer
信息: io.sort.mb = 100
2013-10-14 15:39:42 org.apache.hadoop.mapred.MapTask$MapOutputBuffer
信息: data buffer = 79691776/99614720
2013-10-14 15:39:42 org.apache.hadoop.mapred.MapTask$MapOutputBuffer
信息: record buffer = 262144/327680
2013-10-14 15:39:42 org.apache.hadoop.mapred.MapTask$MapOutputBuffer flush
信息: Starting flush of map output
2013-10-14 15:39:42 org.apache.hadoop.mapred.MapTask$MapOutputBuffer sortAndSpill
信息: Finished spill 0
2013-10-14 15:39:42 org.apache.hadoop.mapred.Task done
信息: Task:attempt_local_0010_m_000000_0 is done. And is in the process of commiting
2013-10-14 15:39:42 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息:
2013-10-14 15:39:42 org.apache.hadoop.mapred.Task sendDone
信息: Task 'attempt_local_0010_m_000000_0' done.
2013-10-14 15:39:42 org.apache.hadoop.mapred.Task initialize
信息: Using ResourceCalculatorPlugin : null
2013-10-14 15:39:42 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息:
2013-10-14 15:39:42 org.apache.hadoop.mapred.Merger$MergeQueue merge
信息: Merging 1 sorted segments
2013-10-14 15:39:42 org.apache.hadoop.mapred.Merger$MergeQueue merge
信息: Down to the last merge-pass, with 1 segments left of total size: 677 bytes
2013-10-14 15:39:42 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息:
2013-10-14 15:39:42 org.apache.hadoop.mapred.Task done
信息: Task:attempt_local_0010_r_000000_0 is done. And is in the process of commiting
2013-10-14 15:39:42 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息:
2013-10-14 15:39:42 org.apache.hadoop.mapred.Task commit
信息: Task attempt_local_0010_r_000000_0 is allowed to commit now
2013-10-14 15:39:42 org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter commitTask
信息: Saved output of task 'attempt_local_0010_r_000000_0' to hdfs://192.168.1.210:9000/user/hdfs/mix_data/result/clusters-9
2013-10-14 15:39:42 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息: reduce > reduce
2013-10-14 15:39:42 org.apache.hadoop.mapred.Task sendDone
信息: Task 'attempt_local_0010_r_000000_0' done.
2013-10-14 15:39:43 org.apache.hadoop.mapred.JobClient monitorAndPrintJob
信息: map 100% reduce 100%
2013-10-14 15:39:43 org.apache.hadoop.mapred.JobClient monitorAndPrintJob
信息: Job complete: job_local_0010
2013-10-14 15:39:43 org.apache.hadoop.mapred.Counters log
信息: Counters: 19
2013-10-14 15:39:43 org.apache.hadoop.mapred.Counters log
信息: File Output Format Counters
2013-10-14 15:39:43 org.apache.hadoop.mapred.Counters log
信息: Bytes Written=695
2013-10-14 15:39:43 org.apache.hadoop.mapred.Counters log
信息: FileSystemCounters
2013-10-14 15:39:43 org.apache.hadoop.mapred.Counters log
信息: FILE_BYTES_READ=30544993
2013-10-14 15:39:43 org.apache.hadoop.mapred.Counters log
信息: HDFS_BYTES_READ=741007
2013-10-14 15:39:43 org.apache.hadoop.mapred.Counters log
信息: FILE_BYTES_WRITTEN=32013760
2013-10-14 15:39:43 org.apache.hadoop.mapred.Counters log
信息: HDFS_BYTES_WRITTEN=154545
2013-10-14 15:39:43 org.apache.hadoop.mapred.Counters log
信息: File Input Format Counters
2013-10-14 15:39:43 org.apache.hadoop.mapred.Counters log
信息: Bytes Read=31390
2013-10-14 15:39:43 org.apache.hadoop.mapred.Counters log
信息: Map-Reduce Framework
2013-10-14 15:39:43 org.apache.hadoop.mapred.Counters log
信息: Map output materialized bytes=681
2013-10-14 15:39:43 org.apache.hadoop.mapred.Counters log
信息: Map input records=1000
2013-10-14 15:39:43 org.apache.hadoop.mapred.Counters log
信息: Reduce shuffle bytes=0
2013-10-14 15:39:43 org.apache.hadoop.mapred.Counters log
信息: Spilled Records=6
2013-10-14 15:39:43 org.apache.hadoop.mapred.Counters log
信息: Map output bytes=666
2013-10-14 15:39:43 org.apache.hadoop.mapred.Counters log
信息: Total committed heap usage (bytes)=1966735360
2013-10-14 15:39:43 org.apache.hadoop.mapred.Counters log
信息: SPLIT_RAW_BYTES=130
2013-10-14 15:39:43 org.apache.hadoop.mapred.Counters log
信息: Combine input records=0
2013-10-14 15:39:43 org.apache.hadoop.mapred.Counters log
信息: Reduce input records=3
2013-10-14 15:39:43 org.apache.hadoop.mapred.Counters log
信息: Reduce input groups=3
2013-10-14 15:39:43 org.apache.hadoop.mapred.Counters log
信息: Combine output records=0
2013-10-14 15:39:43 org.apache.hadoop.mapred.Counters log
信息: Reduce output records=3
2013-10-14 15:39:43 org.apache.hadoop.mapred.Counters log
信息: Map output records=3
2013-10-14 15:39:43 org.apache.hadoop.mapred.JobClient copyAndConfigureFiles
警告: Use GenericOptionsParser for parsing the arguments. Applications should implement Tool for the same.
2013-10-14 15:39:43 org.apache.hadoop.mapreduce.lib.input.FileInputFormat listStatus
信息: Total input paths to process : 1
2013-10-14 15:39:43 org.apache.hadoop.mapred.JobClient monitorAndPrintJob
信息: Running job: job_local_0011
2013-10-14 15:39:43 org.apache.hadoop.mapred.Task initialize
信息: Using ResourceCalculatorPlugin : null
2013-10-14 15:39:43 org.apache.hadoop.mapred.MapTask$MapOutputBuffer
信息: io.sort.mb = 100
2013-10-14 15:39:43 org.apache.hadoop.mapred.MapTask$MapOutputBuffer
信息: data buffer = 79691776/99614720
2013-10-14 15:39:43 org.apache.hadoop.mapred.MapTask$MapOutputBuffer
信息: record buffer = 262144/327680
2013-10-14 15:39:43 org.apache.hadoop.mapred.MapTask$MapOutputBuffer flush
信息: Starting flush of map output
2013-10-14 15:39:43 org.apache.hadoop.mapred.MapTask$MapOutputBuffer sortAndSpill
信息: Finished spill 0
2013-10-14 15:39:43 org.apache.hadoop.mapred.Task done
信息: Task:attempt_local_0011_m_000000_0 is done. And is in the process of commiting
2013-10-14 15:39:43 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息:
2013-10-14 15:39:43 org.apache.hadoop.mapred.Task sendDone
信息: Task 'attempt_local_0011_m_000000_0' done.
2013-10-14 15:39:43 org.apache.hadoop.mapred.Task initialize
信息: Using ResourceCalculatorPlugin : null
2013-10-14 15:39:43 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息:
2013-10-14 15:39:43 org.apache.hadoop.mapred.Merger$MergeQueue merge
信息: Merging 1 sorted segments
2013-10-14 15:39:43 org.apache.hadoop.mapred.Merger$MergeQueue merge
信息: Down to the last merge-pass, with 1 segments left of total size: 677 bytes
2013-10-14 15:39:43 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息:
2013-10-14 15:39:43 org.apache.hadoop.mapred.Task done
信息: Task:attempt_local_0011_r_000000_0 is done. And is in the process of commiting
2013-10-14 15:39:43 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息:
2013-10-14 15:39:43 org.apache.hadoop.mapred.Task commit
信息: Task attempt_local_0011_r_000000_0 is allowed to commit now
2013-10-14 15:39:43 org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter commitTask
信息: Saved output of task 'attempt_local_0011_r_000000_0' to hdfs://192.168.1.210:9000/user/hdfs/mix_data/result/clusters-10
2013-10-14 15:39:43 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息: reduce > reduce
2013-10-14 15:39:43 org.apache.hadoop.mapred.Task sendDone
信息: Task 'attempt_local_0011_r_000000_0' done.
2013-10-14 15:39:44 org.apache.hadoop.mapred.JobClient monitorAndPrintJob
信息: map 100% reduce 100%
2013-10-14 15:39:44 org.apache.hadoop.mapred.JobClient monitorAndPrintJob
信息: Job complete: job_local_0011
2013-10-14 15:39:44 org.apache.hadoop.mapred.Counters log
信息: Counters: 19
2013-10-14 15:39:44 org.apache.hadoop.mapred.Counters log
信息: File Output Format Counters
2013-10-14 15:39:44 org.apache.hadoop.mapred.Counters log
信息: Bytes Written=695
2013-10-14 15:39:44 org.apache.hadoop.mapred.Counters log
信息: FileSystemCounters
2013-10-14 15:39:44 org.apache.hadoop.mapred.Counters log
信息: FILE_BYTES_READ=33833211
2013-10-14 15:39:44 org.apache.hadoop.mapred.Counters log
信息: HDFS_BYTES_READ=808345
2013-10-14 15:39:44 org.apache.hadoop.mapred.Counters log
信息: FILE_BYTES_WRITTEN=35458320
2013-10-14 15:39:44 org.apache.hadoop.mapred.Counters log
信息: HDFS_BYTES_WRITTEN=156323
2013-10-14 15:39:44 org.apache.hadoop.mapred.Counters log
信息: File Input Format Counters
2013-10-14 15:39:44 org.apache.hadoop.mapred.Counters log
信息: Bytes Read=31390
2013-10-14 15:39:44 org.apache.hadoop.mapred.Counters log
信息: Map-Reduce Framework
2013-10-14 15:39:44 org.apache.hadoop.mapred.Counters log
信息: Map output materialized bytes=681
2013-10-14 15:39:44 org.apache.hadoop.mapred.Counters log
信息: Map input records=1000
2013-10-14 15:39:44 org.apache.hadoop.mapred.Counters log
信息: Reduce shuffle bytes=0
2013-10-14 15:39:44 org.apache.hadoop.mapred.Counters log
信息: Spilled Records=6
2013-10-14 15:39:44 org.apache.hadoop.mapred.Counters log
信息: Map output bytes=666
2013-10-14 15:39:44 org.apache.hadoop.mapred.Counters log
信息: Total committed heap usage (bytes)=2166095872
2013-10-14 15:39:44 org.apache.hadoop.mapred.Counters log
信息: SPLIT_RAW_BYTES=130
2013-10-14 15:39:44 org.apache.hadoop.mapred.Counters log
信息: Combine input records=0
2013-10-14 15:39:44 org.apache.hadoop.mapred.Counters log
信息: Reduce input records=3
2013-10-14 15:39:44 org.apache.hadoop.mapred.Counters log
信息: Reduce input groups=3
2013-10-14 15:39:44 org.apache.hadoop.mapred.Counters log
信息: Combine output records=0
2013-10-14 15:39:44 org.apache.hadoop.mapred.Counters log
信息: Reduce output records=3
2013-10-14 15:39:44 org.apache.hadoop.mapred.Counters log
信息: Map output records=3
2013-10-14 15:39:44 org.apache.hadoop.mapred.JobClient copyAndConfigureFiles
警告: Use GenericOptionsParser for parsing the arguments. Applications should implement Tool for the same.
2013-10-14 15:39:44 org.apache.hadoop.mapreduce.lib.input.FileInputFormat listStatus
信息: Total input paths to process : 1
2013-10-14 15:39:44 org.apache.hadoop.mapred.JobClient monitorAndPrintJob
信息: Running job: job_local_0012
2013-10-14 15:39:44 org.apache.hadoop.mapred.Task initialize
信息: Using ResourceCalculatorPlugin : null
2013-10-14 15:39:44 org.apache.hadoop.mapred.Task done
信息: Task:attempt_local_0012_m_000000_0 is done. And is in the process of commiting
2013-10-14 15:39:44 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息:
2013-10-14 15:39:44 org.apache.hadoop.mapred.Task commit
信息: Task attempt_local_0012_m_000000_0 is allowed to commit now
2013-10-14 15:39:44 org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter commitTask
信息: Saved output of task 'attempt_local_0012_m_000000_0' to hdfs://192.168.1.210:9000/user/hdfs/mix_data/result/clusteredPoints
2013-10-14 15:39:44 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息:
2013-10-14 15:39:44 org.apache.hadoop.mapred.Task sendDone
信息: Task 'attempt_local_0012_m_000000_0' done.
2013-10-14 15:39:45 org.apache.hadoop.mapred.JobClient monitorAndPrintJob
信息: map 100% reduce 0%
2013-10-14 15:39:45 org.apache.hadoop.mapred.JobClient monitorAndPrintJob
信息: Job complete: job_local_0012
2013-10-14 15:39:45 org.apache.hadoop.mapred.Counters log
信息: Counters: 11
2013-10-14 15:39:45 org.apache.hadoop.mapred.Counters log
信息: File Output Format Counters
2013-10-14 15:39:45 org.apache.hadoop.mapred.Counters log
信息: Bytes Written=41520
2013-10-14 15:39:45 org.apache.hadoop.mapred.Counters log
信息: File Input Format Counters
2013-10-14 15:39:45 org.apache.hadoop.mapred.Counters log
信息: Bytes Read=31390
2013-10-14 15:39:45 org.apache.hadoop.mapred.Counters log
信息: FileSystemCounters
2013-10-14 15:39:45 org.apache.hadoop.mapred.Counters log
信息: FILE_BYTES_READ=18560374
2013-10-14 15:39:45 org.apache.hadoop.mapred.Counters log
信息: HDFS_BYTES_READ=437203
2013-10-14 15:39:45 org.apache.hadoop.mapred.Counters log
信息: FILE_BYTES_WRITTEN=19450325
2013-10-14 15:39:45 org.apache.hadoop.mapred.Counters log
信息: HDFS_BYTES_WRITTEN=120417
2013-10-14 15:39:45 org.apache.hadoop.mapred.Counters log
信息: Map-Reduce Framework
2013-10-14 15:39:45 org.apache.hadoop.mapred.Counters log
信息: Map input records=1000
2013-10-14 15:39:45 org.apache.hadoop.mapred.Counters log
信息: Spilled Records=0
2013-10-14 15:39:45 org.apache.hadoop.mapred.Counters log
信息: Total committed heap usage (bytes)=1083047936
2013-10-14 15:39:45 org.apache.hadoop.mapred.Counters log
信息: SPLIT_RAW_BYTES=130
2013-10-14 15:39:45 org.apache.hadoop.mapred.Counters log
信息: Map output records=1000
Dumping out clusters from clusters: hdfs://192.168.1.210:9000/user/hdfs/mix_data/result/clusters-*-final and clusteredPoints: hdfs://192.168.1.210:9000/user/hdfs/mix_data/result/clusteredPoints
CL-552{n=443 c=[1.631, -0.412] r=[1.563, 1.407]}
Weight : [props - optional]: Point:
1.0: [-2.393, 3.347]
1.0: [-4.364, 1.905]
1.0: [-3.275, 0.023]
1.0: [-2.479, 2.534]
1.0: [-0.559, 1.223]
...
CL-847{n=77 c=[-2.953, -0.971] r=[1.767, 2.189]}
Weight : [props - optional]: Point:
1.0: [-0.883, -3.320]
1.0: [-1.099, -6.063]
1.0: [-0.004, -0.610]
1.0: [-2.996, -3.610]
1.0: [3.988, 1.008]
...
CL-823{n=480 c=[0.219, 2.600] r=[1.479, 1.385]}
Weight : [props - optional]: Point:
1.0: [2.670, 1.851]
1.0: [2.177, 6.773]
1.0: [5.537, 2.651]
1.0: [5.663, 6.868]
1.0: [5.117, 3.747]
1.0: [1.912, 2.959]
...
4). 聚类结果解读
我们可以把上面的日志分解析成3个部分解读
- a. 初始化环境
- b. 算法执行
- c. 打印聚类结果
a. 初始化环境
出初HDFS的数据目录和工作目录,并上传数据文件。
Delete: hdfs://192.168.1.210:9000/user/hdfs/mix_data
Create: hdfs://192.168.1.210:9000/user/hdfs/mix_data
copy from: datafile/randomData.csv to hdfs://192.168.1.210:9000/user/hdfs/mix_data
ls: hdfs://192.168.1.210:9000/user/hdfs/mix_data
==========================================================
name: hdfs://192.168.1.210:9000/user/hdfs/mix_data/randomData.csv, folder: false, size: 36655
b. 算法执行
算法执行,有3个步骤。
- 1):把原始数据randomData.csv,转成Mahout sequence files of VectorWritable。
- 2):通过随机的方法,选中kmeans的3个中心,做为初始集群
- 3):根据迭代次数的设置,执行MapReduce,进行计算
1):把原始数据randomData.csv,转成Mahout sequence files of VectorWritable。
程序源代码:
InputDriver.runJob(new Path(inPath), new Path(seqFile), "org.apache.mahout.math.RandomAccessSparseVector");
日志输出:
Job complete: job_local_00012):通过随机的方法,选中kmeans的3个中心,做为初始集群
程序源代码:
int k = 3;
Path seqFilePath = new Path(seqFile);
Path clustersSeeds = new Path(seeds);
DistanceMeasure measure = new EuclideanDistanceMeasure();
clustersSeeds = RandomSeedGenerator.buildRandom(conf, seqFilePath, clustersSeeds, k, measure);
日志输出:
Job complete: job_local_00023):根据迭代次数的设置,执行MapReduce,进行计算
程序源代码:
KMeansDriver.run(conf, seqFilePath, clustersSeeds, new Path(outPath), measure, 0.01, 10, true, 0.01, false);
日志输出:
Job complete: job_local_0003
Job complete: job_local_0004
Job complete: job_local_0005
Job complete: job_local_0006
Job complete: job_local_0007
Job complete: job_local_0008
Job complete: job_local_0009
Job complete: job_local_0010
Job complete: job_local_0011
Job complete: job_local_0012
c. 打印聚类结果
Dumping out clusters from clusters: hdfs://192.168.1.210:9000/user/hdfs/mix_data/result/clusters-*-final and clusteredPoints: hdfs://192.168.1.210:9000/user/hdfs/mix_data/result/clusteredPoints
CL-552{n=443 c=[1.631, -0.412] r=[1.563, 1.407]}
CL-847{n=77 c=[-2.953, -0.971] r=[1.767, 2.189]}
CL-823{n=480 c=[0.219, 2.600] r=[1.479, 1.385]}
运行结果:有3个中心。
- Cluster1, 包括443个点,中心坐标[1.631, -0.412]
- Cluster2, 包括77个点,中心坐标[-2.953, -0.971]
- Cluster3, 包括480 个点,中心坐标[0.219, 2.600]
5). HDFS产生的目录
# 根目录
~ hadoop fs -ls /user/hdfs/mix_data
Found 4 items
-rw-r--r-- 3 Administrator supergroup 36655 2013-10-04 15:31 /user/hdfs/mix_data/randomData.csv
drwxr-xr-x - Administrator supergroup 0 2013-10-04 15:31 /user/hdfs/mix_data/result
drwxr-xr-x - Administrator supergroup 0 2013-10-04 15:31 /user/hdfs/mix_data/seeds
drwxr-xr-x - Administrator supergroup 0 2013-10-04 15:31 /user/hdfs/mix_data/seqfile
# 输出目录
~ hadoop fs -ls /user/hdfs/mix_data/result
Found 13 items
-rw-r--r-- 3 Administrator supergroup 194 2013-10-04 15:31 /user/hdfs/mix_data/result/_policy
drwxr-xr-x - Administrator supergroup 0 2013-10-04 15:31 /user/hdfs/mix_data/result/clusteredPoints
drwxr-xr-x - Administrator supergroup 0 2013-10-04 15:31 /user/hdfs/mix_data/result/clusters-0
drwxr-xr-x - Administrator supergroup 0 2013-10-04 15:31 /user/hdfs/mix_data/result/clusters-1
drwxr-xr-x - Administrator supergroup 0 2013-10-04 15:31 /user/hdfs/mix_data/result/clusters-10-final
drwxr-xr-x - Administrator supergroup 0 2013-10-04 15:31 /user/hdfs/mix_data/result/clusters-2
drwxr-xr-x - Administrator supergroup 0 2013-10-04 15:31 /user/hdfs/mix_data/result/clusters-3
drwxr-xr-x - Administrator supergroup 0 2013-10-04 15:31 /user/hdfs/mix_data/result/clusters-4
drwxr-xr-x - Administrator supergroup 0 2013-10-04 15:31 /user/hdfs/mix_data/result/clusters-5
drwxr-xr-x - Administrator supergroup 0 2013-10-04 15:31 /user/hdfs/mix_data/result/clusters-6
drwxr-xr-x - Administrator supergroup 0 2013-10-04 15:31 /user/hdfs/mix_data/result/clusters-7
drwxr-xr-x - Administrator supergroup 0 2013-10-04 15:31 /user/hdfs/mix_data/result/clusters-8
drwxr-xr-x - Administrator supergroup 0 2013-10-04 15:31 /user/hdfs/mix_data/result/clusters-9
# 产生的随机中心种子目录
~ hadoop fs -ls /user/hdfs/mix_data/seeds
Found 1 items
-rw-r--r-- 3 Administrator supergroup 599 2013-10-04 15:31 /user/hdfs/mix_data/seeds/part-randomSeed
# 输入文件换成Mahout格式文件的目录
~ hadoop fs -ls /user/hdfs/mix_data/seqfile
Found 2 items
-rw-r--r-- 3 Administrator supergroup 0 2013-10-04 15:31 /user/hdfs/mix_data/seqfile/_SUCCESS
-rw-r--r-- 3 Administrator supergroup 31390 2013-10-04 15:31 /user/hdfs/mix_data/seqfile/part-m-00000
4. 用R语言可视化结果
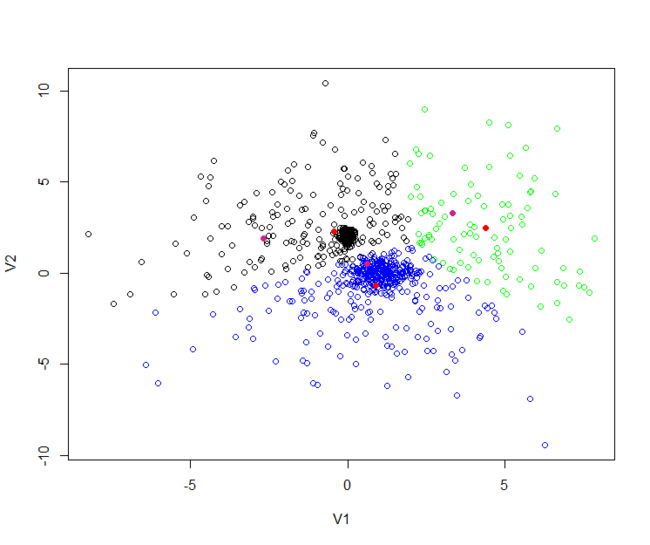
分别把聚类后的点,保存到不同的cluster*.csv文件,然后用R语言画图。
c1<-read.csv(file="cluster1.csv",sep=",",header=FALSE)
c2<-read.csv(file="cluster2.csv",sep=",",header=FALSE)
c3<-read.csv(file="cluster3.csv",sep=",",header=FALSE)
y<-rbind(c1,c2,c3)
cols<-c(rep(1,nrow(c1)),rep(2,nrow(c2)),rep(3,nrow(c3)))
plot(y, col=c("black","blue","green")[cols])
center<-matrix(c(1.631, -0.412,-2.953, -0.971,0.219, 2.600),ncol=2,byrow=TRUE)
points(center, col="violetred", pch = 19)
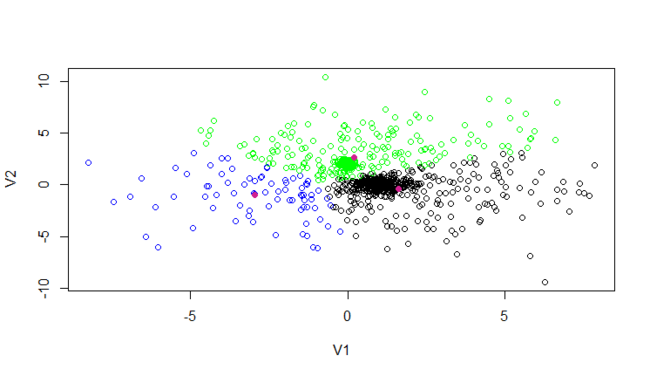
从上图中,我们看到有 黑,蓝,绿,三种颜色的空心点,这些点就是原始数据。
3个紫色实点,是Mahout的kmeans后生成的3个中心。
对比文章中用R语言实现的kmeans的分类和中心,都不太一样。 用Maven构建Mahout项目
简单总结一下,在使用kmeans时,根据距离算法,阈值,出始中心,迭代次数的不同,kmeans计算的结果是不相同的。因此,用kmeans算法,我们一般只能得到一个模糊的分类标准,这个标准对于我们认识未知领域的数据集是很有帮助的。不能做为精确衡量数据的指标。
5. 模板项目上传github
https://github.com/bsspirit/maven_mahout_template/tree/mahout-0.8
大家可以下载这个项目,做为开发的起点。
~ git clone https://github.com/bsspirit/maven_mahout_template
~ git checkout mahout-0.8
这样,我们完成了Mahout的聚类算法Kmeans的分步式实现。接下来,我们会继续做关于Mahout中分类的实验!
转载请注明出处:
http://blog.fens.me/hadoop-mahout-kmeans/