3D点云(3D point cloud)及PointNet、PointNet++
文章目录
-
- 一、什么是3D点云
- 二、基于3D点云的一些任务
- 三、如何提取3D点云数据的特征:PointNet
-
- (1)在PointNet之前也有工作在做点云上的深度学习
- (2)PointNet
-
- (1)置换不变性(Permutation Invariance)
- (2)角度不变性(Transformation Invariance)
- 分类和分割网络
- PointNet的优势:占用内存小且速度快(高效)
- PointNet的优势:对数据丢失非常鲁棒
- 四、PointNet++
-
- PointNet的局限性
- 第二代网络:PointNet++
-
- (1)Hierarcgical feature learning(多级特征学习)
-
- 在多级特征学习网络中,是**如何选择PointNet++作用区域球的半径**的呢?
- 五、PointNet和PointNet++在三维场景理解中的应用
-
- 3D Object Detection
-
- Previous Work
- Frustum PointNets for 3D Object Detection
- key to success
- 六、Q&A
一、什么是3D点云
https://www.youtube.com/watch?v=Ew24Rac8eYE
传统图像数据是2维的
3D点云是3维的,可以表达更多信息
- 比如对化工厂进行违章识别、安全隐患的识别
- 城市管理


二、基于3D点云的一些任务
- 点云分割
- 点云补全
- 点云生成
- 点云物体检测(3D物体检测)
- 点云配准(后续任务的基础)


一般点云数据都是基于激光雷达扫描生成的。
三、如何提取3D点云数据的特征:PointNet
初始的点云数据仅仅包含了每个点的坐标信息(x,y,z),这些对我们要完成的后续任务远远不够,我们还需要知道每个点和周围的点的关系甚至是每个点和全局的关系。
(1)在PointNet之前也有工作在做点云上的深度学习
点云数据并不是定义在一个规则的网格上,空间上可以任意分布、数量也可以任意,是不规则数据。
一种解决方案:

- 栅格化(voxelization)将无规则的3点云变成一种规则的数据,均匀分布在一个3维网格中。
- 3d卷积处理处理成3维栅格的数据
这种方式的缺点:
- 如果为了降低时间复杂度和空间复杂度选择降低图片的分辨率,会使学习效果大打折扣;
- 如果不计时间和空间复杂度,将大分辨率的图像输入3D卷积网络。其实3D点云仅仅扫描的是表面信息,这样做栅格内部有大片空白,造成了算力资源的大量浪费。
(2)PointNet
那么如何构造一个backbone来提取3D点云的这些特征呢?


点云数据的特点
(1)置换不变性(Permutation Invariance)
点云数据是一个inordered set,每个点出现的顺序不影响集合的本身

N表示点云中的有N个点,D代表每个点拥有D维的特征。D中可以包含点的坐标信息(x,y,z),也可以包含颜色、法向量…
因为点集是无序的,一共有N!种排列组合。这要求我们设计的backbone对所有置换都具有不变性。
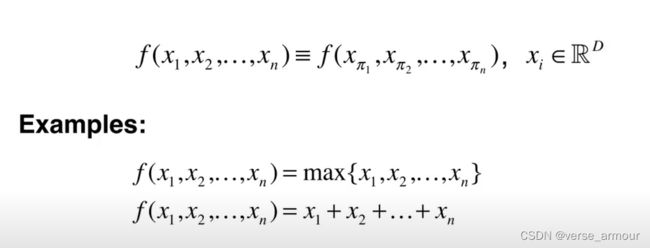

最简单的最大池化和平均池化函数虽然具有置换不变性,但是无疑会丢失有意义的几何信息。
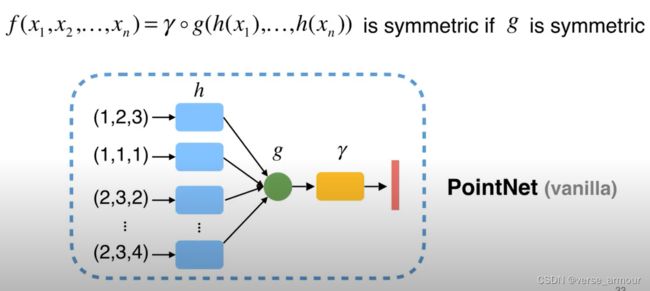
- 因为直接对点云做对称性的操作会丢失重要的几何信息;
- 我们可以先将3D点云映射到高维空间h,与此同时就产生了很多冗余信息;
- 此时,我们再在高维空间中进行对称操作g,我们依然会得到充足的几何信息,这样会避免过多的几何信息的丢失。
- 最后我们再通过另一个网络 γ \gamma γ来进一步消化这个信息,得到一个点云的特征。

这是什么?不太理解。
(2)角度不变性(Transformation Invariance)
比如说一辆车,在不同的角度观察,点云中的每个点的坐标会有所变化,但表示的都是同一辆车。
如何设计网络能使得网络能够适应这种视角的变化呢?
增加基于点云数据本身的变换函数模块:


通过一个神经网络T-Net生成变换的参数,再用生成的变换函数对输入数据进行变换。使得这个变换函数能够自动对准对齐我们的输入,后面的网络能够适应不同角度的输入数据,处理任务变得更加简单。
对点云数据进行变换操作非常简单,只需要进行一个矩阵乘法。
做一些扩展:不仅可以对输入数据进行变换处理,也可以对点的中间特征进行特征空间的变换。
比如,一开始已经将点的特征变成K维,那么现在有一个N * K的矩阵。我们可以设计一个K * K的矩阵进行矩阵乘法对这些中间特征进行特征空间的变换。这样可以得到另一组特征。

对于以上涉及的这些高维的变换,优化的难度也更高,可能会需要一些regularization:比如会尽可能希望这个矩阵接近于正交矩阵。
分类和分割网络
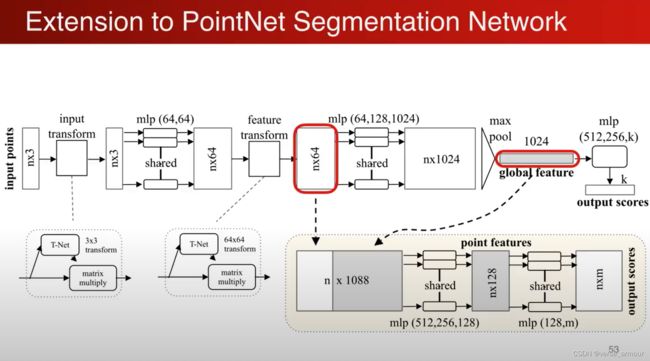
单个点的特征和全局的坐标结合起来实现分割的功能。
最简单的就是:将全局的特征重复n遍,每一个和原来的单个点的特征连接在一起,相当于单个点在全局特征中进行了一次检索,“我在全局特征中处于哪一个位置,我大概属于哪一个类”

PointNet的优势:占用内存小且速度快(高效)
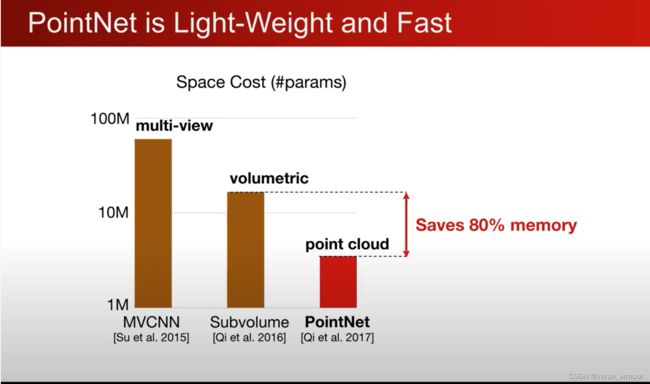
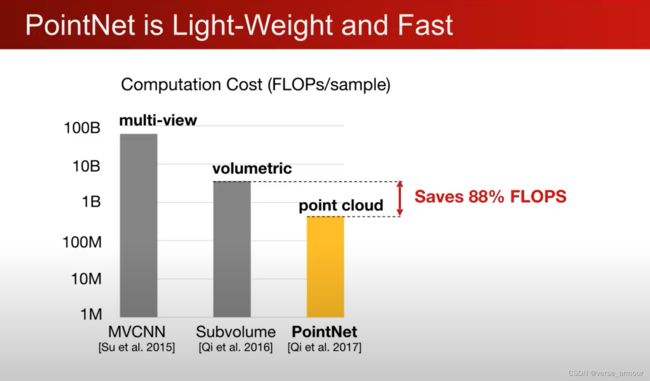
FLOPs:计算量,floating point operations的缩写(s表复数),意指浮点运算数,理解为计算量。可以用来衡量算法/模型的复杂度。
因为PointNet的高效性,其非常适用于移动设备和可穿戴设备。
PointNet的优势:对数据丢失非常鲁棒
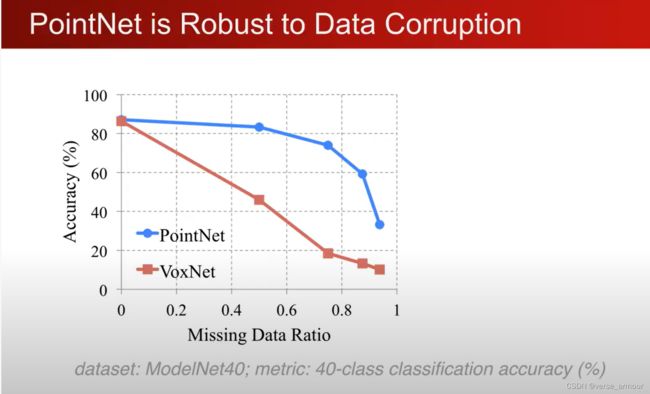
对数据的丢失都非常鲁棒
why?
解释这个可以通过一个可视化去理解:

最大池化使得模型只去关注critical points,这也使得模型对点的丢失具有较好的鲁棒性。
四、PointNet++
PointNet的局限性
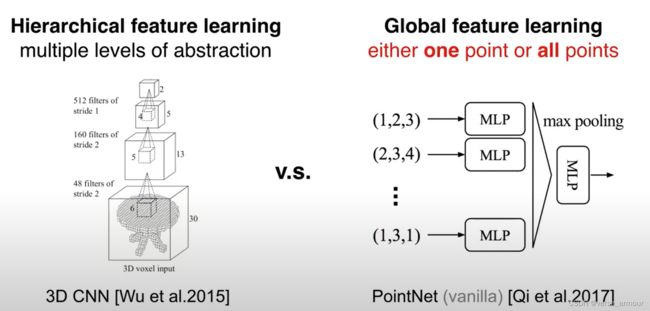
在PointNet中,先对每一个点通过MLP做一个从低维到高维的映射,再对高位的特征通过MLP结合到一起。所以PointNet要么是对一个点做操作,要么是对所有点全局的特征在做操作。所以PointNet和3D卷积相比缺少了一个局部的概念,比较难对一些精细的特征进行学习。此外,在平移不变性上也有一定的缺陷,如果对点云的每一个点进行一个平移操作,那么经过PointNet学习的特征也会完全不一样。
第二代网络:PointNet++
- Hierarcgical feature learning
- Translation invariant
- Permutation invariant
(1)Hierarcgical feature learning(多级特征学习)


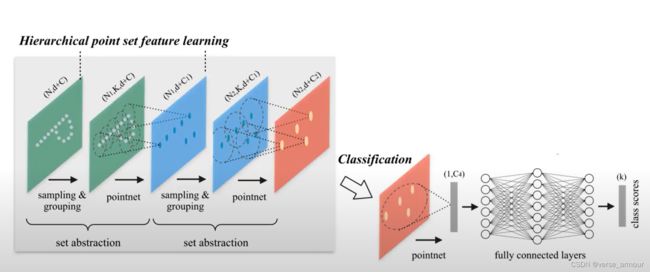
也可以通过一种“up-convolution”的方式将pointnet提取的特征点复原回去。

在多级特征学习网络中,是如何选择PointNet++作用区域球的半径的呢?
在CNN中现在越来越流行选择非常小的kernel,比如在VGG中大量应用3*3的kernel。
那么在PointNet++中是不是这样呢?其实这是不一定的。
在point cloud中非常常见的一种情况是采样率非常不均匀。比如一个depth camera采样到的point cloud,近的点会非常密集,远的点会非常稀疏。那么对于PointNet++的学习就会在稀疏的地方产生很大的问题。比如在某个地方我们的划定的作用区域中只有一个点,那么在那个区域中学到的特征就会非常不稳定。这是我们很想避免的。
为了量化这个问题,我们做了一个控制变量的实验,验证了点的疏密对PointNet++网络精确度的影响:小的kernel会受采样率不均匀影响较大。

针对这个问题,可以设计一些新的网络结构来避免这个问题。
- Muti-scale grouping(MSG)
- Muti-res gruoping(MRG)
- MRG的好处是可以节省一些计算。而MSG需要对不同的尺度分别计算。
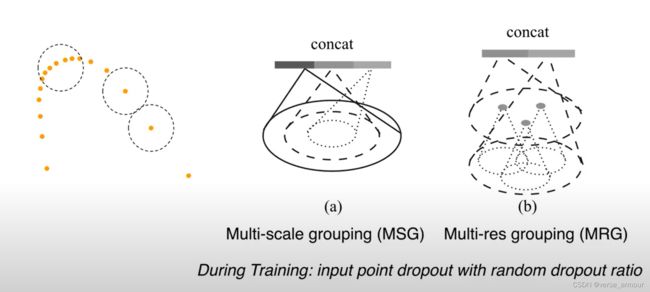
效果对比:


五、PointNet和PointNet++在三维场景理解中的应用
- 3D Object Detection
- 3D Scene Flow

3D Object Detection

Previous Work
- 3D region + classification
基于点云,在三维空间中做region proposal,然后投影到图片中,在图片中画出3D的box,再进行物体的识别;也可以用3D的CNN来做。

缺点:
- 3D空间的搜索量非常大,计算量也非常大。
- 点云的分辨率有限,比较难发现比较小的物体。
- RGB or RGB-D image based object detection
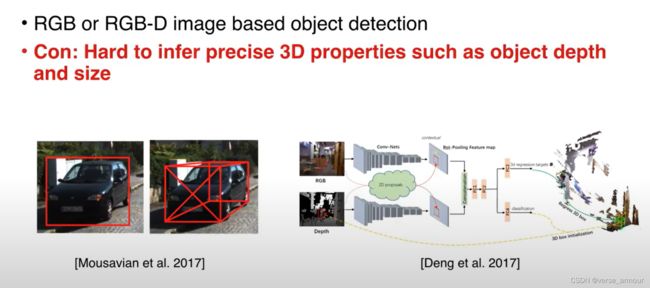
缺点:
RGB图像:依赖物体大小的先验知识,很难估计物体的精确位置。
RGB-D图像:两个实际距离很远的点投影到图像上的距离有可能非常近。
在图片这种表达形式下,用2D的CNN还是受到了很大的局限性。
很难精确地估计物体的深度和大小
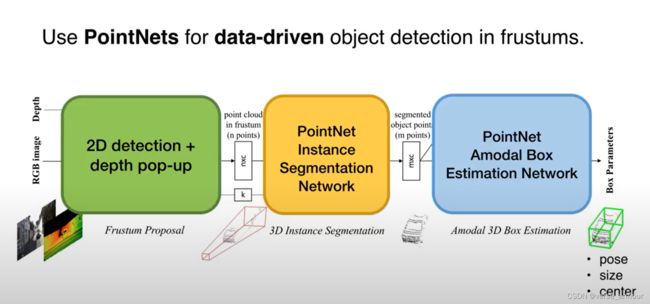
Frustum PointNets for 3D Object Detection
2D detectors for region proposal + 3D frustum + PointNets
整体思想:
- 在二维图像上检测划定初步的region proposal,用于减少3D空间搜索成本
- 在划定的region propoasl上生成相应的3D视锥(Frustum),在该视锥内对point cloud用PointNets进行深度学习得到精确的3D proposal
缺点:
occlusions and clutters are common in frustum point clouds

key to success
- 归一化:因为是点云数据,所以归一化只需对点做矩阵乘法就行了。

六、Q&A
- PointNet是不是没有考虑点之间的关系?
PointNet++考虑点之间的关系了 - STN的全称是什么?
special transformer network - 关键点是怎么选取的?
关键点不是选取的,是我们可视化的,可视化了这个网络选择了哪些关键点